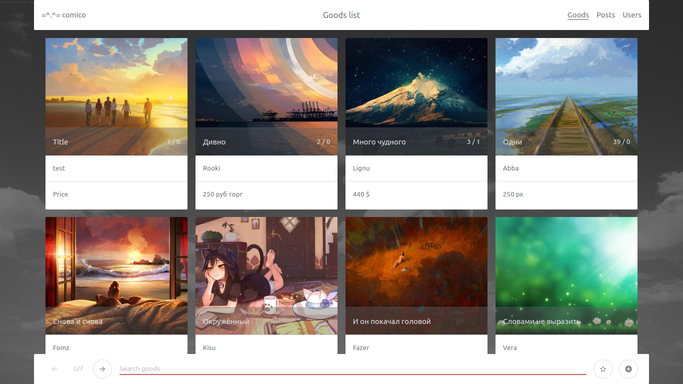
Olá a todos, quero compartilhar o resultado de meus pensamentos sobre o tópico sobre o que pode ser um aplicativo da web moderno. Como exemplo, considere criar um quadro de avisos para quadrinhos. De certa forma, o produto em questão foi projetado para um público de geeks e simpatizantes, o que permite mostrar liberdade na interface. No componente técnico, pelo contrário, é necessária atenção aos detalhes.
Na verdade, eu não entendo nada nos quadrinhos, mas eu amo mercados de pulgas, especialmente no formato de fórum, que eram populares no zero. Portanto, a suposição (possivelmente falsa), da qual decorrem as conclusões a seguir, é apenas uma - o principal tipo de interação com o aplicativo está sendo visualizado, os secundários estão publicando anúncios e discussões.
Nosso objetivo será criar um aplicativo simples, sem conhecimento técnico assobios extras, no entanto, consistentes com as realidades modernas. Os principais requisitos que eu gostaria de alcançar são:
Lado do servidor:
a) Executa as funções de armazenamento, validação e envio de dados do usuário para o cliente
b) As operações acima consomem uma quantidade aceitável de recursos (tempo, inclusive)
c) O aplicativo e os dados são protegidos contra vetores de ataque populares
d) Possui uma API simples para clientes de terceiros e interação entre servidores
e) Implementação simples entre plataformas
Lado do cliente:
a) Fornece a funcionalidade necessária para criar e consumir conteúdo
b) A interface é conveniente para uso regular, o caminho mínimo para qualquer ação, a quantidade máxima de dados por tela
c) Fora de comunicação com o servidor, todas as funções disponíveis nesta situação estão disponíveis
d) A interface exibe a versão atual do estado e do conteúdo, sem reiniciar e aguardar
d) Reiniciar o aplicativo não afeta seu estado
f) Se possível, reutilize elementos DOM e código JS
g) Não usaremos bibliotecas e estruturas de terceiros em tempo de execução
h) O layout é semântico para acessibilidade, analisadores, etc.
i) A navegação do conteúdo principal é acessível usando a URL e o teclado
Na minha opinião, os requisitos lógicos e as aplicações mais modernas, em um grau ou outro, atendem a essas condições. Vamos ver o que acontece conosco (link para fonte e demonstração no final do post).
Advertências:- Quero pedir desculpas aos autores desconhecidos das imagens usadas na demonstração sem permissão, bem como Gösse G., Prozorovskaya B. D. e a editora "Library of Florence Pavlenkov" por usar trechos da obra "Siddhartha".
- O autor não é um programador real, não recomendo usar o código ou as técnicas usadas neste projeto se você não souber o que está fazendo.
- Peço desculpas pelo estilo do código; ele poderia ter sido escrito de maneira mais fácil e óbvia, mas isso não é divertido. Um projeto para a alma e para um amigo, como é o que eles dizem.
- Também peço desculpas pela taxa de alfabetização, especialmente no texto em inglês. Anos Falam De Maio Hart.
- O desempenho do protótipo apresentado foi testado em [crómio 70; linux x86_64; 1366x768], serei extremamente grato aos usuários de outras plataformas e dispositivos por mensagens de erro.
- Este é um protótipo e um tópico proposto para discussão - abordagens e princípios, peço que todas as críticas à implementação e ao lado estético sejam acompanhadas de argumentos.
Servidor
O idioma para o servidor é golang. Uma linguagem simples e rápida, com uma excelente biblioteca e documentação padrão ... um pouco irritante. A escolha inicial recaiu no elixir / erlang, mas como eu já sabia que era (relativamente), foi decidido não complicá-lo (e os pacotes necessários eram apenas para levar).
O uso de estruturas da web na comunidade go não é incentivado (justificadamente, vale a pena admitir), escolhemos um compromisso e usamos o microframework labstack / eco , reduzindo assim a quantidade de rotina e, para mim, sem perder muito desempenho.
Usamos tidwall / buntdb como banco de dados. Em primeiro lugar, a solução integrada é mais conveniente e reduz os custos indiretos e, em segundo lugar, na memória + chave / valor - elegante, elegante Rápido e sem cache necessário. Armazenamos e fornecemos dados em JSON, validando apenas ao alterar.
No i3 de segunda geração, o criador de logs incorporado mostra o tempo de execução para diferentes solicitações de 0,5 a 10ms. A execução de wrk na mesma máquina também mostra resultados suficientes para nossos propósitos:
➜ comico git:(master) wrk -t2 -c500 -d60s http://localhost:9001/pub/mtimes Running 1m test @ http://localhost:9001/pub/mtimes 2 threads and 500 connections Thread Stats Avg Stdev Max +/- Stdev Latency 20.74ms 16.68ms 236.16ms 72.69% Req/Sec 13.19k 627.43 15.62k 73.58% 1575522 requests in 1.00m, 449.26MB read Requests/sec: 26231.85 Transfer/sec: 7.48MB
➜ comico git:(master) wrk -t2 -c500 -d60s http://localhost:9001/pub/goods Running 1m test @ http://localhost:9001/pub/goods 2 threads and 500 connections Thread Stats Avg Stdev Max +/- Stdev Latency 61.79ms 65.96ms 643.73ms 86.48% Req/Sec 5.26k 705.24 7.88k 70.31% 628215 requests in 1.00m, 8.44GB read Requests/sec: 10454.44 Transfer/sec: 143.89MB
Estrutura do projeto
O pacote comico / model é dividido em três arquivos:
model.go - contém uma descrição dos tipos de dados e funções gerais: criação / atualização (o buntdb não faz distinção entre essas operações e verificamos a presença de um registro manualmente), validação, exclusão, obtenção de um registro e obtenção de uma lista;
rules.go - contém regras de validação para um tipo específico e função de registro;
files.go - trabalhe com imagens.
O tipo Mtimes armazena dados na última alteração dos tipos restantes no banco de dados, informando ao cliente quais dados foram alterados.
O pacote comico / bd contém funções generalizadas para interagir com o banco de dados: criação, exclusão, seleção, etc. O Buntdb salva todas as alterações em um arquivo (no nosso caso, uma vez por segundo), no formato de texto, o que é conveniente em algumas situações. O arquivo db não é editado; as alterações em caso de sucesso da transação são adicionadas ao final. Todas as minhas tentativas de violar a integridade dos dados foram malsucedidas; no pior dos casos, as alterações no último segundo foram perdidas.
Em nossa implementação, cada tipo corresponde a um banco de dados separado em um arquivo separado (exceto para logs armazenados exclusivamente na memória e redefinidos para zero após a reinicialização). Isso se deve em grande parte à conveniência de backup e administração, uma pequena vantagem - uma transação aberta para edição bloqueia o acesso a apenas um tipo de dados.
Este pacote pode ser facilmente substituído por um similar usando outro banco de dados, SQL, por exemplo. Para fazer isso, basta implementar as seguintes funções:
func Delete(db byte, key string) error func Exist(db byte, key string) bool func Insert(db byte, key, val string) error func ReadAll(db byte, pattern string) (str string, err error) func ReadOne(db byte, key string) (str string, err error) func Renew(db byte, key string) (err error, newId string)
O pacote comico / cnst contém algumas constantes necessárias em todos os pacotes (tipos de dados, tipos de ação, tipos de usuário). Além disso, este pacote contém todas as mensagens legíveis por humanos com as quais nosso servidor responderá ao mundo externo.
O pacote comico / server contém informações de roteamento. Além disso, apenas algumas linhas (graças aos desenvolvedores do Echo), autorização usando JWT, CORS, cabeçalhos CSP, criador de logs, distribuição estática, gzip, certificado automático ACME, etc.
Pontos de entrada da API
| URL | Dados | Descrição do produto |
|---|
| get / pub / (mercadorias | mensagens | usuários | cmnts | arquivos) | - | Obtendo uma variedade de anúncios, postagens, usuários, comentários, arquivos relevantes |
| get / pub / mtimes | - | Obtendo o horário da última alteração para cada tipo de dados |
| post / pub / login | {id *: login, passe *: senha} | Retorna o token JWT e sua duração |
| post / pub / passe | {id *, passe *} | Cria um novo usuário se os dados estiverem corretos |
| colocar / api / pass | {id *, passe *} | Atualização da senha |
| post | put / api / goods | {id *, auth *, título *, tipo *, preço *, texto *, imagens: [], Tabela: {key: value}} | Criar / atualizar anúncio |
| post | put / api / posts | {id *, auth *, título *, tipo *, texto *} | Criar / atualizar postagem do fórum |
| post | put / api / users | {id *, título, tipo, status, escribas: [], ignora: [], Tabela: {key: value}} | Criar / Atualizar Usuário |
| post / api / cmnts | {id *, auth *, owner *, digite *, para, texto *} | Criação de comentários |
| delete / api / (mercadorias | mensagens | usuários | cmnts) / [id] | - | Exclui uma entrada com o ID |
| get / api / activity | - | Atualiza o último tempo de leitura dos comentários recebidos para o usuário atual |
| get / api / (assine | ignore) / [tag] | - | Adiciona ou remove (se houver) marca ao usuário na lista de assinaturas / ignora |
| post / api / upload / (mercadorias | usuários) | multipart (nome, arquivo) | Carrega anúncios fotográficos / avatar do usuário |
* - campos obrigatórios
api - requer autorização, pub - não
Com uma solicitação get que não corresponde ao acima, o servidor procura por um arquivo no diretório para static (por exemplo, / img / * - images, /index.html - o cliente).
Qualquer ponto da API retornará um código de resposta 200 se for bem-sucedido, 400 ou 404 para um erro e uma mensagem curta, se necessário.
Os direitos de acesso são simples: a criação de uma entrada está disponível para um usuário autorizado, a edição para o autor e o moderador, o administrador pode editar e nomear moderadores.
A API está equipada com o anti-vandalismo mais simples: as ações são registradas junto com o ID do usuário e o IP e, em caso de acesso frequente, é retornado um erro pedindo que você espere um pouco (útil contra a adivinhação de senha).
Cliente
Gosto do conceito de web reativo, acho que a maioria dos sites / aplicativos modernos deve ser feita dentro da estrutura desse conceito ou completamente estática. Por outro lado, um site simples com megabytes de código JS não pode deixar de pressionar. Na minha opinião, este (e não apenas) problema pode ser resolvido por Svelte. Essa estrutura (ou melhor, a linguagem para a construção de interfaces reativas) não é inferior ao Vue na funcionalidade necessária, mas possui uma vantagem inegável - os componentes são compilados no vanilla JS, o que reduz o tamanho do pacote e a carga na máquina virtual (bundle.min.js.gz nosso mercado de pulgas é modesto, pelos padrões atuais, 24KB). Detalhes podem ser encontrados na documentação oficial.
Escolhemos o mercado de pulgas SvelteJS para o lado do cliente, desejamos tudo de melhor para Rich Harris e o desenvolvimento do projeto!
PS Eu não quero ofender ninguém. Estou certo de que cada especialista e cada projeto tem suas próprias ferramentas.
Cliente / Dados
URL
Usamos para navegação. Não simularemos um documento de várias páginas; em vez disso, usamos páginas de hash com parâmetros de consulta. Para transições, você pode usar o <a> usual sem js.
As seções correspondem aos tipos de dados: / # mercadorias , / # postagens , / # usuários .
Parâmetros :? Id = record_id ,? Page = page_number ,? Search = search_query .
Alguns exemplos:
- / # posts? id = 1542309643 & page = 999 & search = {auth: anon} - postagens de seção, ID da postagem - 1542309643 , página de comentários - 999 , consulta de pesquisa - {auth: anon}
- / # goods? page = 2 & search = siddhartha - seção goods , seção page - 2 , consulta de pesquisa - siddhartha
- / # goods? search = wer {key: value} produtos da seção t , consulta de pesquisa - consiste em procurar a substring wert no cabeçalho ou no texto do anúncio e o valor do substring na propriedade key da parte tabular do anúncio
- / # goods? search = {model: 100, display: 256} - acho que tudo está claro aqui por analogia
As funções de análise e geração de URL em nossa implementação são assim:
window.addEventListener('hashchange', function() { const hash = location.hash.slice(1).split('?'), result = {} if (!!hash[1]) hash[1].split('&').forEach(str => { str = str.split('=') if (!!str[0] && !!str[1]) result[decodeURI(str[0]).toLowerCase()] = decodeURI(str[1]).toLowerCase() }) result.type = hash[0] || 'goods' store.set({ hash: result }) }) function goto({ type, id, page, search }) { const { hash } = store.get(), args = arguments[0], query = [] new Array('id', 'page', 'search').forEach(key => { const value = args[key] !== undefined ? args[key] : hash[key] || null if (value !== null) query.push(key + '=' + value) }) location.hash = (type || hash.type || 'goods') + (!!query.length ? '?' + query.join('&') : '') }
API
Para trocar dados com o servidor, usaremos a API de busca. Para baixar registros atualizados em intervalos curtos, solicitamos / pub / mtimes . Se a hora da última alteração de qualquer tipo for diferente da local, carregamos uma lista desse tipo. Sim, foi possível implementar a notificação de atualizações via SSE ou WebSockets e carregamento incremental, mas, neste caso, podemos fazer sem ele. O que conseguimos:
async function GET(type) { const response = await fetch(location.origin + '/pub/' + type) .catch(() => ({ ok: false })) if (type === 'mtimes') store.set({ online: response.ok }) return response.ok ? await response.json() : [] } async function checkUpdate(type, mtimes, updates = {}) { const local = store.get()._mtimes, net = mtimes || await GET('mtimes') if (!net[type] || local[type] === net[type]) return const value = updates['_' + type] = await GET(type) local[type] = net[type]; updates._mtimes = local if (!!value && !!value.sort) store.set(updates) } async function checkUpdates() { setTimeout(() => checkUpdates(), 30000) const mtimes = await store.GET('mtimes') new Array('users', 'goods', 'posts', 'cmnts', 'files') .forEach(type => checkUpdate(type, mtimes)) }
Para filtragem e paginação, usamos as propriedades calculadas do Svelte, com base nos dados de navegação. A direção dos valores calculados é: items (matrizes de registros provenientes do servidor) => ignoredItems (registros filtrados com base na lista de ignorados do usuário atual) => scribedItems (filtra os registros de acordo com a lista de assinaturas, se ativada) => curItem e curItems (calcula os registros atuais dependendo da seção) => filterItems (filtra os registros dependendo da consulta de pesquisa, se houver apenas um registro - filtra os comentários) => maxPage (calcula o número de páginas na taxa de 12 registros / comentários por página) => pagedItem (retorna a matriz final com postagens / comentários com base no número da página atual).
Comentários e imagens ( comentários e _images ) são calculados separadamente, agrupados por tipo e registro do proprietário.
Os cálculos ocorrem automaticamente e somente quando os dados associados são alterados, os dados intermediários estão constantemente na memória. Nesse sentido, fazemos uma conclusão desagradável - para uma grande quantidade de informações e / ou sua atualização frequente, uma grande quantidade de recursos pode ser gasta.
Cache
De acordo com a decisão de criar um aplicativo offline, implementamos o armazenamento de registros e alguns aspectos do estado no localStorage, arquivos de imagem no CacheStorage. Trabalhar com localStorage é extremamente simples, concordamos que as propriedades com o prefixo "_" são salvas e restauradas automaticamente após a reinicialização quando alteradas. Então, nossa solução pode ficar assim:
store.on('state', ({ changed, current }) => { Object.keys(changed).forEach(prop => { if (!prop.indexOf('_')) localStorage.setItem(prop, JSON.stringify(current[prop])) }) }) function loadState(state = {}) { for (let i = 0; i < localStorage.length; i++) { const prop = localStorage.key(i) const value = JSON.parse(localStorage.getItem(prop) || 'null') if (!!value && !prop.indexOf('_')) state[prop] = value } store.set(state) }
Os arquivos são um pouco mais complicados. Primeiro, usaremos a lista de todos os arquivos relevantes (com a hora da criação) provenientes do servidor. Ao atualizar esta lista, comparamos com os valores antigos, colocamos os novos arquivos no CacheStorage, excluímos os desatualizados de lá:
async function cacheImages(newFiles) { const oldFiles = JSON.parse(localStorage.getItem('_files') || '[]') const cache = await caches.open('comico') oldFiles.forEach(file => { if (!~newFiles.indexOf(file)) { const [ id, type ] = file.split(':') cache.delete(`/img/${type}_${id}_sm.jpg`) }}) newFiles.forEach(file => { if (!~oldFiles.indexOf(file)) { const [ id, type ] = file.split(':'), src = `/img/${type}_${id}_sm.jpg` cache.add(new Request(src, { cache: 'no-cache' })) }}) }
Em seguida, você precisa redefinir o comportamento de busca para que o arquivo seja retirado do CacheStorage sem conectar-se ao servidor. Para fazer isso, você precisa usar o ServiceWorker. Ao mesmo tempo, configuraremos outros arquivos para serem armazenados em cache para funcionarem fora da comunicação com o servidor:
const CACHE = 'comico', FILES = [ '/', '/bundle.css', '/bundle.js' ] self.addEventListener('install', (e) => { e.waitUntil(caches.open(CACHE).then(cache => cache.addAll(FILES)) .then(() => self.skipWaiting())) }) self.addEventListener('fetch', (e) => { const r = e.request if (r.method !== 'GET' || !!~r.url.indexOf('/pub/') || !!~r.url.indexOf('/api/')) return if (!!~r.url.lastIndexOf('_sm.jpg') && e.request.cache !== 'no-cache') return e.respondWith(fromCache(r)) e.respondWith(toCache(r)) }) async function fromCache(request) { return await (await caches.open(CACHE)).match(request) || new Response(null, { status: 404 }) } async function toCache(request) { const response = await fetch(request).catch(() => fromCache(request)) if (!!response && response.ok) (await caches.open(CACHE)).put(request, response.clone()) return response }
Parece um pouco desajeitado, mas executa suas funções.
Cliente / Interface
Estrutura do componente:
index.html | main.js
== header.html - contém um logotipo, barra de status, menu principal, menu inferior de navegação, formulário de envio de comentários
== apart.html - é um contêiner para todos os componentes modais
==== goodForm.html - formulário para adicionar e editar um anúncio
==== userForm.html - edita o formulário do usuário atual
====== tableForm.html - um fragmento do formulário para inserir dados tabulares
==== postForm.html - formulário para postagem no fórum
==== login.html - formulário de login / registro
==== activity.html - exibe comentários endereçados ao usuário atual
==== goodImage.html - veja os anúncios principais e adicionais de fotos
== main.html - contêiner para o conteúdo principal
==== goods.html - lista ou cartões de anúncio únicos
==== users.html - o mesmo para usuários
==== posts.html - acho claro
==== cmnts.html - lista de comentários na postagem atual
====== cmntsPager.html - paginação para comentários
- Em cada componente, tentamos minimizar o número de tags html.
- Nós usamos classes apenas como um indicador de estado.
- Desempenhamos funções semelhantes às da loja (as propriedades e métodos da loja sofisticada podem ser usados diretamente dos componentes, adicionando o prefixo '$' a eles).
- A maioria das funções espera um evento do usuário ou alteração de determinadas propriedades, manipula os dados do estado, salva o resultado de seu trabalho de volta ao estado e ao final. Assim, é alcançada uma pequena coerência e extensibilidade do código.
- Para a velocidade aparente das transições e outros eventos da interface do usuário, separamos, na medida do possível, as manipulações com os dados que ocorrem em segundo plano e as ações associadas à interface, que por sua vez usam o resultado do cálculo atual, reconstruindo se necessário, o restante do trabalho será gentilmente executado pela estrutura.
- Os dados do formulário a ser preenchido são armazenados em localStorage para cada entrada, a fim de evitar sua perda.
- Em todos os componentes, usamos o modo imutável no qual o objeto-propriedade é considerado alterado apenas quando um novo link é recebido, independentemente da alteração nos campos, acelerando um pouco nossos aplicativos, embora devido a um pequeno aumento na quantidade de código.
Cliente / Gerenciamento
Para controlar usando o teclado, usamos as seguintes combinações:
Alt + s / Alt + a - alterna a página de registros para frente / trás, pois um registro alterna a página de comentários.
Alt + w / Alt + q - move para o registro seguinte / anterior (se houver), funciona no modo de lista, registro único e visualização de imagem
Alt + x / Alt + z - rola a página para baixo / para cima. Na exibição de imagem, alterna as imagens para frente / trás
Escape - fecha a janela modal, se aberta, retorna à lista, se uma única entrada estiver aberta, cancela a consulta de pesquisa no modo de lista
Alt + c - foca no campo de pesquisa ou comentário, dependendo do modo atual
Alt + v - ativar / desativar o modo de visualização de fotos para um único anúncio
Alt + r - abre / fecha a lista de comentários recebidos para um usuário autorizado
Alt + t - alterna temas claros / escuros
Alt + g - Lista de anúncios
Alt + u - Usuários
Alt + p - fórum
Eu sei que em muitos navegadores essas combinações são usadas pelo próprio navegador, mas para o meu chrome não consegui encontrar algo mais conveniente. Ficarei feliz em suas sugestões.
Além do teclado, você também pode usar o console do navegador. Por exemplo, store.goBack () , store.nextPage () , store.prevPage () , store.nextItem () , store.prevItem () , store.search (stringValue) , store.checkUpdate ('goods' || ' users '||' posts '||' files '||' cmnts ') - faça o que o nome indica; store.get (). comments e store.get () ._ images - retorna arquivos e comentários agrupados; store.get (). ignororedItems e store.get (). scribedItems são listas de registros que você ignora e rastreia. Uma lista completa de todos os dados intermediários e calculados está disponível em store.get () . Não acho que alguém possa precisar disso seriamente, mas, por exemplo, filtrar registros por usuário e excluir me pareceu bastante conveniente no console.
Conclusão
É aqui que você pode encerrar seu conhecimento do projeto; você pode encontrar mais detalhes no código-fonte. Como resultado, obtivemos uma aplicação bastante rápida e compacta, na maioria dos validadores, segurança, velocidade, disponibilidade, etc. verificadores, ela mostra bons resultados sem otimização direcionada.
Gostaria de saber a opinião da comunidade sobre o quão justificadas são as abordagens para organizar os aplicativos usados no protótipo, quais podem ser as armadilhas, o que você implementaria de uma maneira completamente diferente?
Código fonte, instruções de instalação de amostra e demonstração aqui (por favor vandalizar para testar no âmbito do Código Penal).
Postscript. Um pouco mercantil em conclusão. Diga-me, com esse nível, posso realmente começar a programar por dinheiro? Se não, o que procurar antes de tudo, se sim, diga-me onde eles estão procurando um trabalho interessante em uma pilha semelhante agora. Obrigada
Postscript. Um pouco mais sobre dinheiro e trabalho. Como você gosta dessa idéia: suponha que uma pessoa esteja pronta para trabalhar em um projeto interessante por qualquer salário, no entanto, dados sobre tarefas e seu pagamento estarão disponíveis publicamente (disponibilidade e um código para avaliar a qualidade do desempenho são desejáveis), se o pagamento estiver significativamente abaixo do mercado, os concorrentes do empregador pode oferecer muito dinheiro pelo desempenho de suas tarefas, se superior - muitos artistas poderão oferecer seus serviços a um preço mais baixo. Esse esquema, em algumas situações, equilibrará o mercado de maneira mais otimizada e justa?