
Provavelmente, não existem tantos usuários no Habr que nunca ouviram falar do
“Internet Archive” , um serviço que pesquisa e armazena os dados digitais que são importantes para toda a humanidade, sejam páginas da Internet, livros, vídeos ou outro tipo de informação.
Quem gerencia o arquivo da Internet, quando ele apareceu e qual é a sua missão? Leia sobre isso no "inquérito" de hoje.
Por que precisamos de um "arquivo"?
Isso está longe de ser apenas entretenimento. A missão da organização é fornecer o acesso universal a todas as informações. O “arquivo da Internet” busca combater o monopólio do fornecimento de informações tanto pelas empresas de telecomunicações (Google, Facebook, etc.) quanto pelos governos.
Ao mesmo tempo, o "Arquivo" é uma organização cumpridora da lei. Se, de acordo com a lei dos EUA, alguma informação precisar ser removida, a organização o fará.
O “arquivo da Internet” também serve como uma ferramenta para cientistas, agências de segurança, historiadores (por exemplo, arqueólogos) e representantes de muitos outros campos, sem mencionar usuários individuais.
Quando o "arquivo da Internet" apareceu?
O criador do "Archive" é Brewster Cale, dos EUA, que criou a empresa Alexa Internet. Ambos os serviços dele se tornaram extremamente populares, e ainda são prósperos.
O “arquivo da Internet” começou a arquivar as informações dos sites e a manter as cópias das páginas da Web em 1996. A sede desta organização sem fins lucrativos está localizada em São Francisco, EUA.
No entanto, por cinco anos, os dados ficaram indisponíveis para acesso público - os dados foram armazenados nos servidores do "Arquivo", e é tudo, apenas a administração do serviço pôde visualizar as cópias antigas dos sites. Desde 2001, a administração do serviço decidiu fornecer acesso a todos os dados armazenados.
No começo, o “arquivo da Internet” era apenas um arquivo da web, mas a organização começou a salvar livros, arquivos de áudio, imagens em movimento, software. Agora, o “arquivo da Internet” funciona como um repositório de fotos e outras imagens da NASA, textos abertos da Biblioteca, etc.
Como a organização existe?
O "arquivo" existe em doações voluntárias - tanto das organizações quanto dos indivíduos. Você pode fornecer suporte em bitcoins, o número da carteira é 1Archive1n2C579dMsAu3iC6tWzuQJz8dN. A propósito, essa carteira recebeu 357.47245492 BTC durante sua existência, que é de cerca de US $ 2,25 milhões na taxa atual.
Como funciona o "arquivo morto"?
A maioria dos funcionários trabalha nos centros de digitalização de livros, realizando trabalhos rotineiros, mas demorados. A organização possui três data centers localizados na Califórnia, EUA. Um em San Francisco, um na cidade de Redwood, outro em Richmond. Para evitar o risco de perda de dados no caso de um desastre natural ou outras catástrofes, o "Arquivo" possui capacidade disponível no Egito e Amsterdã.
“Milhões de pessoas gastaram muito tempo e esforço para compartilhar com outras pessoas o que sabemos na forma da Internet. Queremos criar uma biblioteca para esta nova plataforma de publicação ”, disse Brewster Kahle, fundador do Internet Archive)
Qual o tamanho do "Arquivo" agora?
O "arquivo da Internet" possui várias divisões, e o que coleta informações dos sites tem seu próprio nome - Wayback Machine. No momento da redação do "Inquérito", o arquivo continha 339 bilhões de páginas da web salvas. Em 2017, o “Arquivo”
armazenou 30 petabytes de informações, que são cerca de 300 bilhões de páginas da web, 12 milhões de livros, 4 milhões de gravações de áudio, 3,3 milhões de vídeos, 1,5 milhão de fotos e 170 mil diferentes distribuições de software. Em apenas um ano, o serviço "aumentou significativamente". Agora, o "Arquivo" armazena 339 bilhões de páginas da web, 19 milhões de livros, 4,5 milhões de arquivos de vídeo, 4,7 milhões de arquivos de áudio, 3,2 milhões de imagens de vários tipos, 381 mil distribuições de software.
Como é organizado o armazenamento de dados?
As informações são armazenadas em discos rígidos nos chamados "nós de dados". Estes são os servidores. Cada um deles contém 36 unidades de disco rígido (mais duas unidades do sistema operacional). Os nós de dados são agrupados em matrizes de 10 máquinas e representam um armazenamento em cluster. Em 2016, o “Arquivo” usava HDD de 8 terabytes, agora a situação é a mesma. Acontece que um nó armazena cerca de 288 terabytes de dados. Em geral, também são utilizados discos rígidos de outros tamanhos: 2,3 e 4 TB.
Em 2016, havia cerca de 20.000 discos rígidos. Os data centers do "Arquivo" são equipados com aparelhos de ar condicionado para controle climático com características constantes. Um armazenamento agrupado de 10 nós consome cerca de 5 quilowatts de energia.
A estrutura do Internet Archive é uma "biblioteca" virtual, dividida em seções como livros, filmes, músicas etc. Para cada elemento, há uma descrição no catálogo - geralmente o nome, o nome do autor e informações adicionais. Do ponto de vista técnico, os elementos são estruturados e localizados nos diretórios Linux.
A quantidade total de dados armazenados pelo "Archive" é 22 PB, e agora há espaço para outros 22 PB. "Porque somos paranóicos", afirmam os representantes do serviço.

Veja a captura de tela do conteúdo do diretório - há um arquivo com o nome terminado em "_files.xml". Este é um diretório com informações sobre todos os arquivos no diretório.
O que acontecerá com os dados se um ou mais servidores falharem?
Nada de ruim - os dados são duplicados. Assim que um novo item aparece na biblioteca "Arquivar", ele é
replicado imediatamente e colocado em diferentes discos rígidos em diferentes servidores. O processo de "espelhamento" do conteúdo ajuda a lidar com problemas como falta de energia e falhas no sistema de arquivos.
Se o disco rígido falhar, ele será substituído por um novo. Graças à estrutura de dados espelhada e reduplicada, ela é imediatamente preenchida com dados que estavam no disco rígido antigo que falharam.
O "Arquivo" possui um sistema especializado que monitora o status do disco rígido. Durante um dia, você deve substituir de 6 a 7 das unidades com falha.
O que é o Wayback Machine?
Este é apenas um dos serviços de "arquivo da Internet", especializado em salvar páginas da web. O serviço possui sua própria "aranha", que examina regularmente todos os sites disponíveis na rede e os armazena em servidores especializados. Quanto mais popular é um site, mais frequentemente o robô copia seu conteúdo. Se o administrador do recurso não quiser que as informações do site sejam copiadas pelo bot, basta registrar uma proibição no arquivo robots.txt.
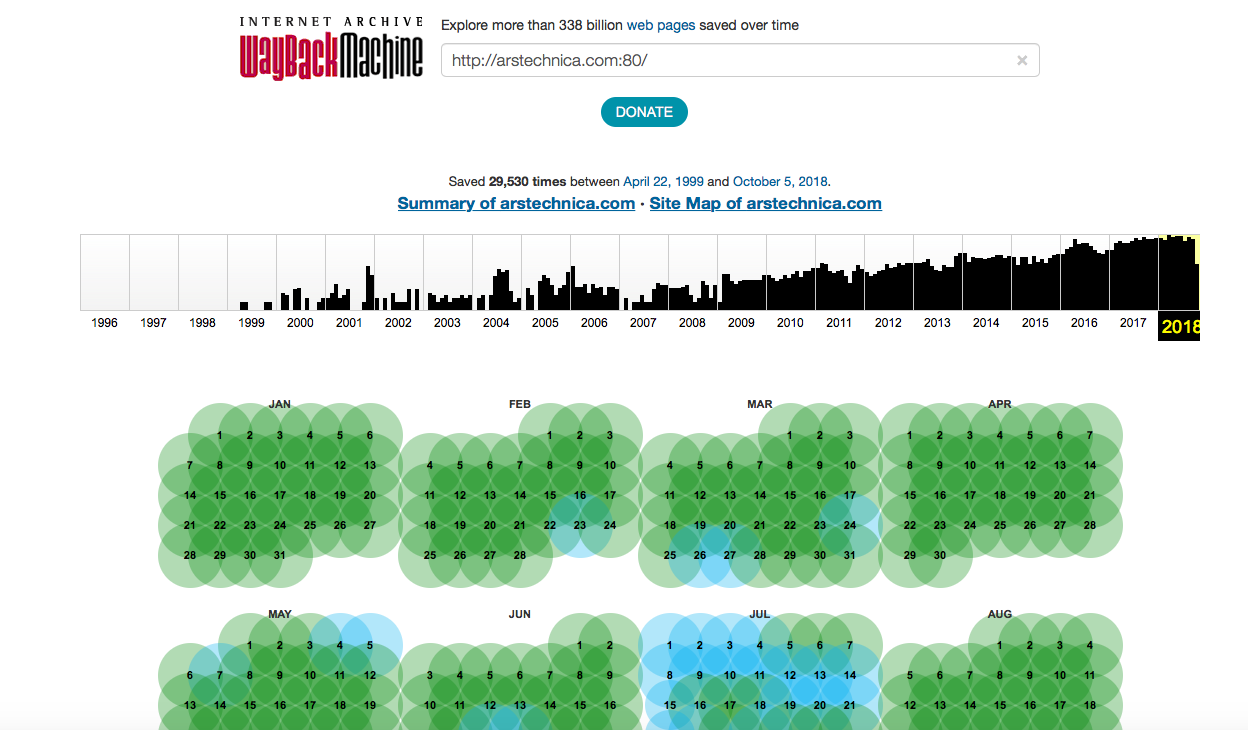 Os recursos populares são copiados com freqüência - quase diariamente. Wayback Machine indexa até as redes sociais, incluindo Twitter, Facebook
Os recursos populares são copiados com freqüência - quase diariamente. Wayback Machine indexa até as redes sociais, incluindo Twitter, Facebook
Em 2017, o “Arquivo” lançou a Wayback Machine atualizada, prometendo acesso mais conveniente às páginas da web salvas. O serviço foi muito reformulado, se não codificado do zero. Agora, ele suporta vários formatos de arquivo que anteriormente não podiam ser salvos. No mesmo 2017, a organização disse que toda semana seus servidores salvam cerca de 1 bilhão de páginas da web.
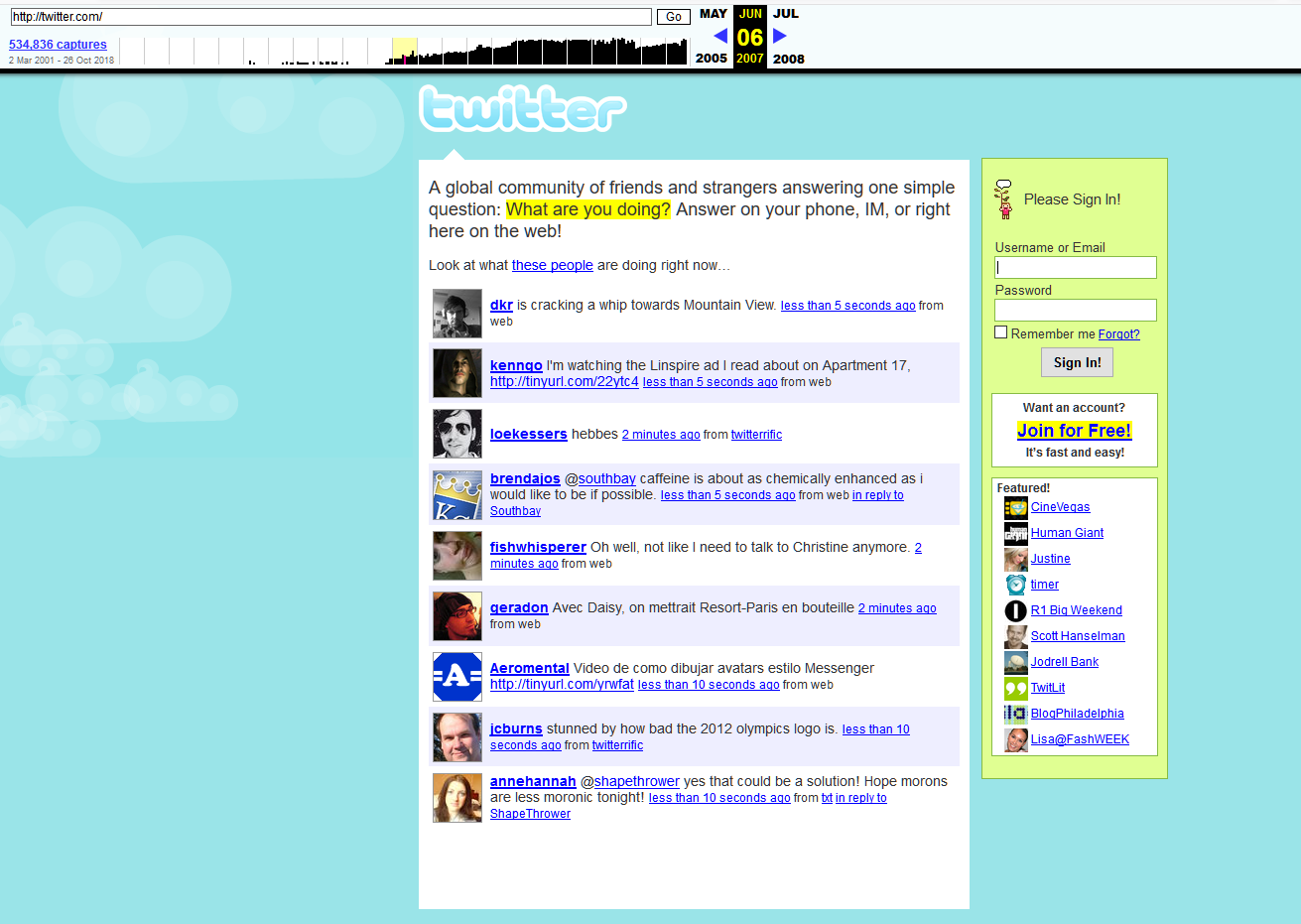 Era assim que o Twitter era em 2007
Era assim que o Twitter era em 2007O que mais pode ser encontrado no banco de dados "Internet archive"?
Livros A coleção da organização é enorme, inclui livros digitalizados, edições comuns e muito raras. Os livros são salvos não apenas em inglês, mas também em muitos outros idiomas. O "Arquivo" possui centros especializados para digitalizar livros, 33 deles no total. Eles estão localizados em cinco países ao redor do mundo.
A equipe do centro digitaliza cerca de 1.000 livros por dia. O banco de dados do serviço contém milhões de publicações. O trabalho de digitalização é financiado por pessoas comuns e por várias organizações, incluindo bibliotecas e fundações.
Desde 2007, o “arquivo da Internet” armazena livros públicos da Pesquisa de Livros do Google em seu banco de dados. Após o lançamento, o banco de dados de livros cresceu rapidamente - em 2013, havia mais de 900 mil livros salvos no serviço do Google.
Um dos serviços do "Arquivo" também fornece acesso aos livros que estão totalmente abertos. Já existem mais de um milhão deles. Este serviço é chamado de Biblioteca Aberta.
Vídeo O serviço armazena 4,5 milhões de vídeos. Eles são divididos em tópicos e têm um foco muito diferente. Os servidores "Archive" armazenam filmes, documentários, eventos esportivos, programas de TV e muitos outros materiais.
Em 2015, o “Arquivo” deu origem a um
projeto em grande escala - a digitalização das fitas de vídeo. A princípio, eram cerca de 40 mil cassetes do arquivo de Marion Stokes, uma mulher que grava as notícias em fita há décadas. Em seguida, outras fitas de vídeo foram adicionadas. Eles foram enviados para o "Arquivo" pelos fãs da idéia de digitalizar dados importantes para a humanidade.
Arquivos de áudio. Da mesma forma que os vídeos, o "Archive" armazena arquivos de áudio, que também são divididos por assuntos. No ano passado, o “Archive” começou a implementar seu novo projeto - a decodificação de registros shellac, o formato mais antigo de gravações de áudio. O som foi preservado nas placas de goma-laca - uma resina natural, isolada pelos insetos da escala feminina. No total, o arquivo
Great 78 Project contém
várias centenas de milhares de registros .
De software Obviamente, é simplesmente impossível armazenar todo o software criado pela humanidade, mesmo para o "Arquivo". Os servidores armazenam vintage - por exemplo, os programas para Macintosh, software para DOS e outros softwares. Em 2016, os funcionários do “Archive” publicaram
mais de 1500 programas para o Windows 3.1. Você pode trabalhar diretamente no navegador. Em 2017, o Internet Archive lançou o
arquivo de software para o primeiro Macintosh .
Jogos Sim, o "Arquivo" fornece acesso a um grande número de jogos. Alguns deles podem ser reproduzidos no ambiente do emulador de navegador. Uma variedade de jogos é armazenada, incluindo o dos
consoles analógicos-digitais portáteis . Existem
jogos para MS-DOS e
jogos de console
para Atari e ColecoVision .

Pela primeira vez, o arquivo de jogos antigos foi
carregado pela organização em 2013. Estamos falando dos títulos de 30 a 40 anos atrás, que poderiam ser reproduzidos diretamente no navegador. Estes são os jogos para Atari 2600 (1977), Atari 7800 (1986), ColecoVision (1982), Philips Videopac G7000 (1978) e Astrocade (1983). O mais interessante é que o Internet Archive garantiu que você pode jogar legalmente. Agora, a coleção tem
mais de 3400 jogos e continua crescendo.