Esta é a segunda parte dos meus
Kubernetes na série de postagens
Enterprise . Como mencionei na minha última postagem, é muito importante, ao passar para os
"Guias de design e implementação", que todos estejam no mesmo nível de entendimento dos Kubernetes (K8s).
Não quero usar a abordagem tradicional aqui para explicar a arquitetura e as tecnologias do Kubernetes, mas explicarei tudo por meio de uma comparação com a plataforma vSphere, com a qual você, como usuário do VMware, conhece. Isso permitirá que você supere a aparente confusão e o peso da compreensão do Kubernetes. Usei essa abordagem dentro da VMware para apresentar o Kubernetes a diferentes públicos de ouvintes, e provou que funciona muito bem e ajuda as pessoas a se acostumarem aos conceitos-chave mais rapidamente.
Nota importante antes de começarmos. Não uso essa comparação para provar semelhanças ou diferenças entre o vSphere e o Kubernetes. Tanto esse como outro, em essência, são sistemas distribuídos e, portanto, devem ter semelhanças com qualquer outro sistema semelhante. Portanto, no final, tento introduzir uma tecnologia maravilhosa como o Kubernetes em uma ampla comunidade de usuários.

Um pouco de história
A leitura deste post envolve conhecer os contêineres. Não descreverei os conceitos básicos de contêineres, pois há muitos recursos que falam sobre isso. Conversando com os clientes com muita frequência, vejo que eles não conseguem entender por que os contêineres conquistaram nossa indústria e se tornaram muito populares em tempo recorde. Para responder a essa pergunta, falarei sobre minha experiência prática no entendimento das mudanças que estão ocorrendo em nosso setor.
Antes de explorar o mundo das telecomunicações, fui desenvolvedor da Web (2003).
Este foi meu segundo trabalho remunerado depois que trabalhei como engenheiro / administrador de rede (eu sei que eu era o melhor de todos os negócios). Eu desenvolvi em PHP. Desenvolvi todos os tipos de aplicativos, começando pelos pequenos que meu empregador usava, terminando com um aplicativo de votação profissional para programas de televisão e até aplicativos de telecomunicações que interagem com hubs VSAT e sistemas de satélite. A vida foi ótima, com exceção de um grande obstáculo que todo desenvolvedor conhece: seus vícios.
No começo, desenvolvi o aplicativo no meu laptop, usando algo como a pilha LAMP, quando funcionou bem no meu laptop, baixei o código-fonte para os servidores host (todo mundo se lembra do RackShack?) Ou para os clientes privados. Você pode imaginar que, assim que eu fiz isso, o aplicativo travou e não funcionou nesses servidores. A razão para isso é o vício. Os servidores tinham outras versões do software (Apache, PHP, MySQL, etc.) além daquelas usadas por mim no laptop. Então, eu precisava encontrar uma maneira de atualizar as versões do software nos servidores remotos (má ideia) ou reescrever o código no meu laptop para corresponder às versões nos servidores remotos (pior idéia). Era um pesadelo, às vezes eu me odiava e me perguntava por que é assim que eu ganho a vida.
10 anos se passaram, a empresa Docker apareceu. Como consultor da VMware na Professional Services (2013), ouvi falar do Docker e deixe-me dizer que não conseguia entender essa tecnologia naquela época. Continuei dizendo algo como: por que usar contêineres se houver máquinas virtuais. Por que desistir de tecnologias importantes como o vSphere HA, DRS ou vMotion devido a vantagens estranhas como o lançamento instantâneo de contêineres ou a eliminação da sobrecarga do hipervisor. Afinal, todo mundo trabalha com máquinas virtuais e funciona perfeitamente. Em resumo, eu olhei para ele em termos de infraestrutura.
Mas então comecei a olhar de perto e me dei conta. Tudo relacionado ao Docker está relacionado aos desenvolvedores. Apenas começando a pensar como desenvolvedor, percebi imediatamente que, se tivesse essa tecnologia em 2003, poderia empacotar todas as minhas dependências. Meus aplicativos da Web podem funcionar independentemente do servidor usado. Além disso, não seria necessário fazer o download do código-fonte ou configurar algo. Você pode simplesmente "empacotar" meu aplicativo em uma imagem e solicitar aos clientes que baixem e executem essa imagem. Este é o sonho de qualquer desenvolvedor da Web!
Tudo isso é ótimo. O Docker resolveu o enorme problema de interação e empacotamento, mas e agora? Como cliente corporativo, posso gerenciar esses aplicativos durante o dimensionamento? Ainda quero usar HA, DRS, vMotion e DR. O Docker resolveu os problemas dos meus desenvolvedores e criou vários problemas para os meus administradores (equipe do DevOps). Eles precisam de uma plataforma para o lançamento de contêineres, a mesma que para o lançamento de máquinas virtuais. E voltamos novamente ao começo.
Mas então o Google apareceu, dizendo ao mundo sobre o uso de contêineres por muitos anos (na verdade, os contêineres foram inventados pelo Google: cgroups) e o método correto de usá-los, por meio de uma plataforma que eles chamavam de Kubernetes. Então eles abriram o código fonte do Kubernetes. Apresentado à comunidade Kubernetes. E isso mudou tudo novamente.
Compreendendo o Kubernetes versus o vSphere
Então, o que é o Kubernetes? Simplificando, o Kubernetes para contêineres é o mesmo que o vSphere para máquinas virtuais em um datacenter moderno. Se você usou o VMware Workstation no início dos anos 2000, sabe que essa solução foi seriamente considerada uma solução para data centers. Quando o VI / vSphere com hosts vCenter e ESXi apareceu, o mundo das máquinas virtuais mudou drasticamente. Hoje, a Kubernetes está fazendo a mesma coisa com o mundo dos contêineres, trazendo a capacidade de lançar e gerenciar contêineres na produção. E é por isso que começaremos a comparar o vSphere lado a lado com o Kubernetes para explicar os detalhes desse sistema distribuído e entender suas funções e tecnologias.

Visão geral do sistema
Como no vSphere, existem hosts vCenter e ESXi no conceito de Kubernetes, existem Master e Node. Nesse contexto, o mestre em K8s é equivalente ao vCenter, no sentido de que é o plano de gerenciamento de um sistema distribuído. É também o ponto de entrada da API com a qual você interage ao gerenciar sua carga de trabalho. Da mesma forma, os nós do K8s funcionam como recursos de computação, semelhantes aos hosts ESXi. É neles que você executa cargas de trabalho (no caso dos K8s, os chamamos de Pods). Os nós podem ser máquinas virtuais ou servidores físicos. Obviamente, com o vSphere ESXi, os hosts sempre devem ser físicos.

Você pode ver que o K8s possui um armazenamento de valores-chave chamado “etcd”. Esse armazenamento é semelhante ao banco de dados do vCenter, onde você salva a configuração de cluster desejada à qual deseja aderir.
Quanto às diferenças: no Master K8s você também pode executar cargas de trabalho, mas no vCenter, não. O vCenter é um dispositivo virtual dedicado apenas ao gerenciamento. No caso dos K8s, o Master é considerado um recurso de computação, mas executar aplicativos Enterprise nele não é uma boa ideia.
Então, como será a realidade? Você usará principalmente a CLI para interagir com o Kubernetes (mas a GUI ainda é uma opção muito viável). A captura de tela abaixo mostra que estou usando uma máquina Windows para conectar-me ao meu cluster Kubernetes através da linha de comando (eu uso o cmder se você estiver interessado). Na captura de tela, tenho um nó mestre e 4 nós. Eles funcionam sob o controle do K8s v1.6.5, e o sistema operacional (SO) Ubuntu 16.04 é instalado nos nós. No momento em que escrevemos este post, vivíamos principalmente no mundo Linux, onde o Master e o Node sempre executavam uma distribuição Linux.
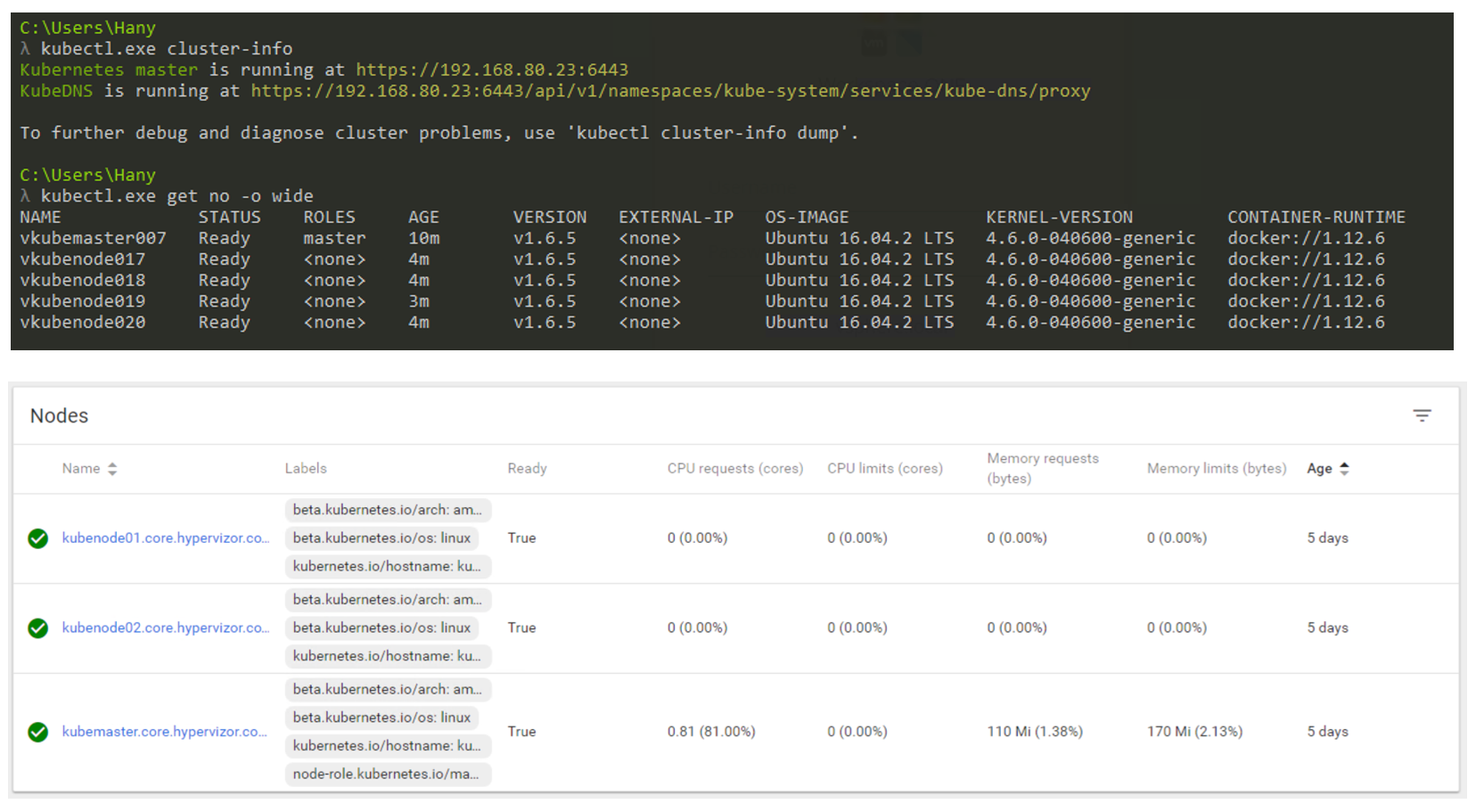 Gerenciamento de cluster K8s por meio de CLI e GUI.
Gerenciamento de cluster K8s por meio de CLI e GUI.Fator de forma da carga de trabalho
No vSphere, a máquina virtual é o limite lógico do sistema operacional. No Kubernetes, os Pods são limites de contêiner, assim como o host ESXi, que pode executar várias máquinas virtuais simultaneamente. Cada nó pode executar vários pods. Cada Pod recebe um endereço IP roteável, como máquinas virtuais, para que os Pods se comuniquem.
No vSphere, os aplicativos são executados dentro do sistema operacional e, no Kubernetes, os aplicativos são executados dentro de contêineres. Uma máquina virtual pode trabalhar apenas com um sistema operacional por vez e um Pod pode executar vários contêineres.
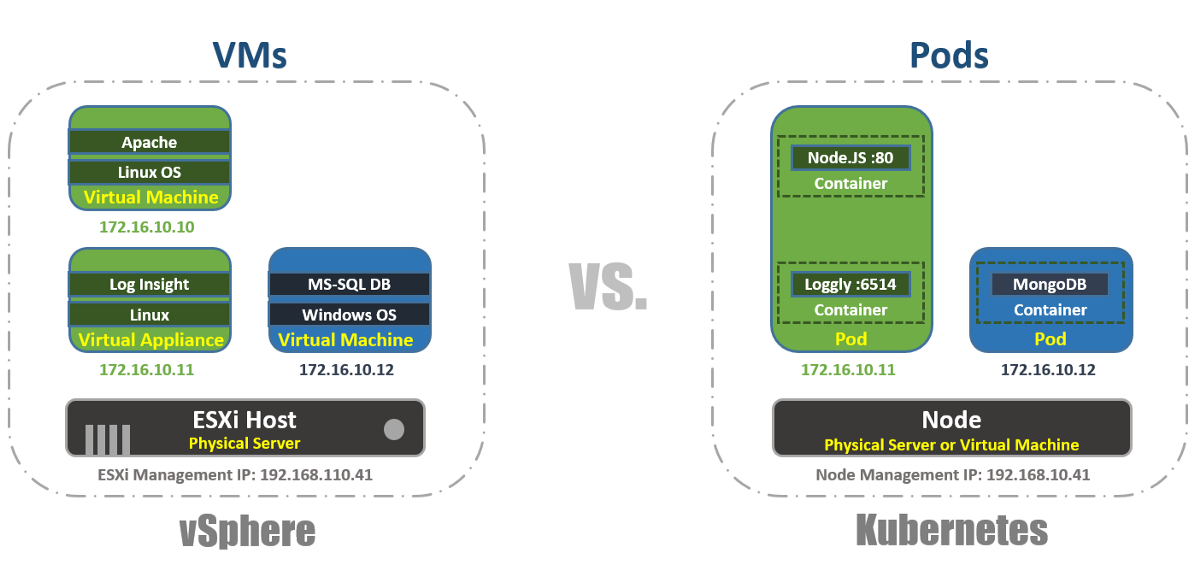
É assim que você pode listar os Pods dentro do cluster K8s usando a ferramenta kubectl por meio da CLI, verificar a capacidade de trabalho dos Pods, sua idade, endereço IP e Nós nos quais eles estão trabalhando atualmente.

Gerência
Então, como gerenciamos nossos mestres, nós e pods? No vSphere, usamos o cliente da Web para gerenciar a maioria (se não todos) os componentes de nossa infraestrutura virtual. Para o Kubernetes, da mesma forma, usando o Painel. Este é um bom portal da Web baseado em GUI que você pode acessar através do navegador da mesma maneira que no vSphere Web Client. Nas seções anteriores, você pode ver que é possível gerenciar seu cluster K8s usando o comando kubeclt da CLI. É sempre discutível onde você passará a maior parte do tempo na CLI ou no painel gráfico. Como o último está se tornando uma ferramenta cada vez mais poderosa todos os dias (você pode ver este vídeo, com certeza). Pessoalmente, acho que o Painel é muito conveniente para monitorar rapidamente o status ou exibir os detalhes de vários componentes do K8s, eliminando a necessidade de inserir comandos longos na CLI. Você encontrará um equilíbrio entre eles de uma maneira natural.
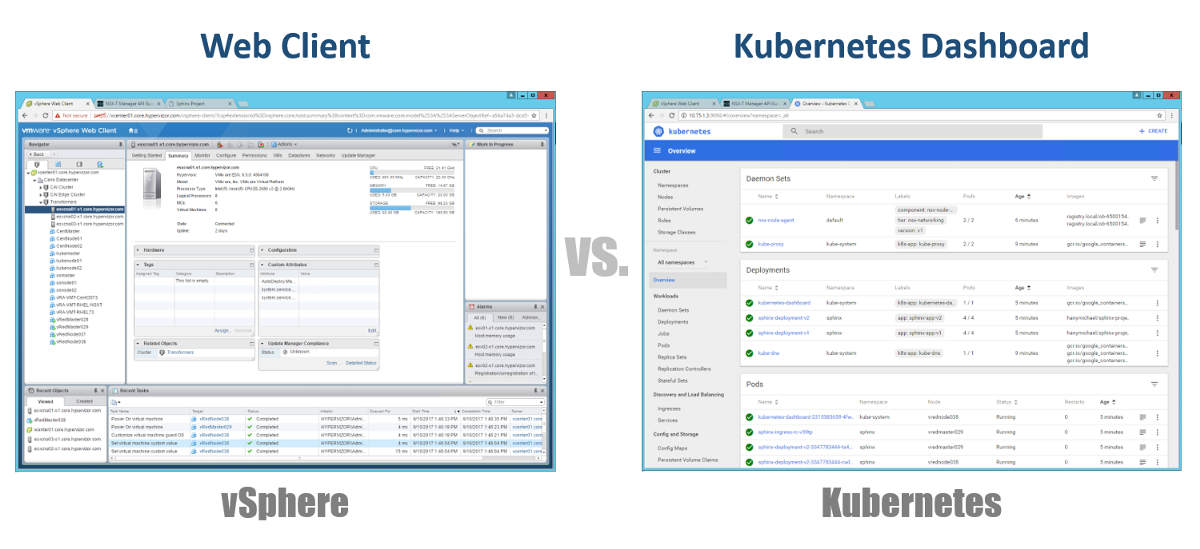
Configurações
Um dos conceitos muito importantes no Kubernetes é o estado desejado das configurações. Você declara o que deseja para quase qualquer componente do Kubernetes através de um arquivo YAML e cria tudo isso usando o kubectl (ou através de um painel gráfico) como o estado desejado. A partir de agora, o Kubernetes sempre se esforçará para manter o ambiente em um determinado estado operacional. Por exemplo, se você quiser ter 4 réplicas de um Pod, o K8s continuará monitorando esses Pods e, se um deles morrer ou o Nó no qual ele trabalhou tiver problemas, o K8s se recuperará automaticamente e criará automaticamente Pod em outro lugar.
Voltando aos nossos arquivos de configuração YAML, você pode considerá-los como um arquivo .VMX para uma máquina virtual ou um descritor .OVF para um dispositivo virtual que deseja implantar no vSphere. Esses arquivos definem a configuração da carga de trabalho / componente que você deseja executar. Ao contrário dos arquivos VMX / OVF, exclusivos das VMs / Appliances virtuais, os arquivos de configuração YAML são usados para definir qualquer componente do K8s, como ReplicaSets, Services, Deployments, etc. Considere isso nas seções a seguir.
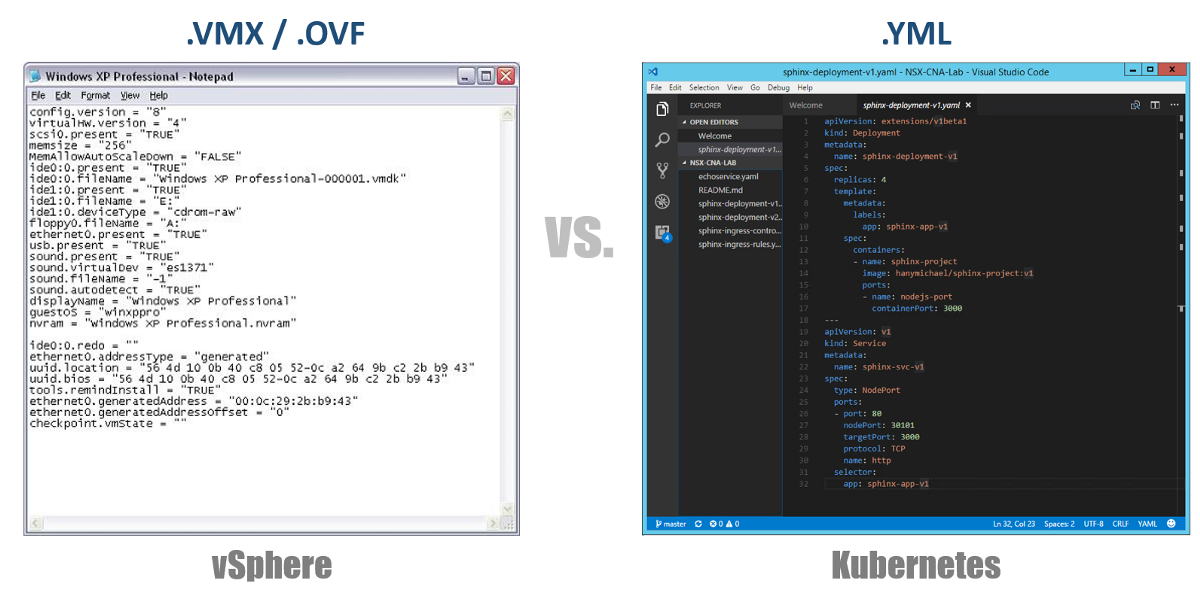
Clusters virtuais
No vSphere, temos hosts físicos do ESXi agrupados logicamente em clusters. Esses clusters podem ser divididos em outros clusters virtuais chamados "Pools de Recursos". Esses "pools" são usados principalmente para limitar recursos. No Kubernetes, temos algo muito semelhante. Nós os chamamos de "Namespaces", eles também podem ser usados para fornecer limites de recursos, que serão refletidos na próxima seção. No entanto, na maioria das vezes, “Namespaces” são usados como uma ferramenta de multilocação para aplicativos (ou usuários, se você usar clusters K8s comuns). Essa também é uma das opções com as quais você pode executar a segmentação de rede usando o NSX-T. Considere isso nas seguintes publicações.
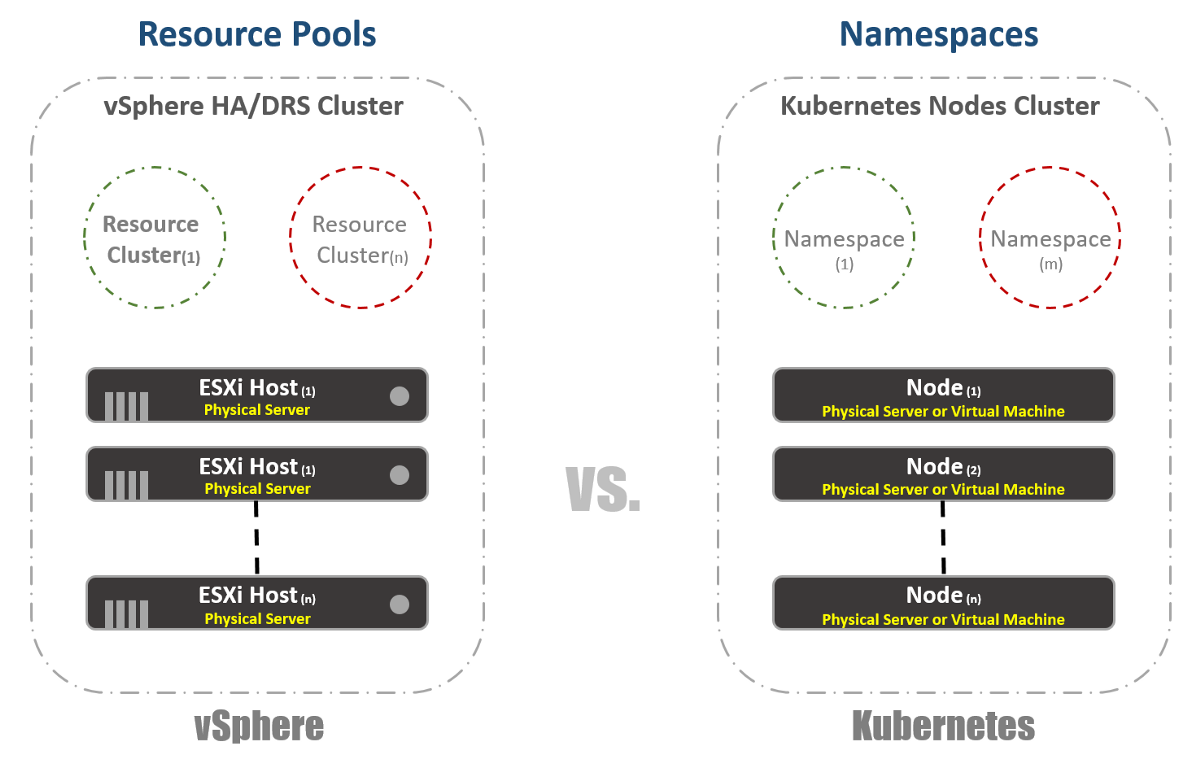
Gerenciamento de recursos
Como mencionei na seção anterior, os espaços para nome no Kubernetes são comumente usados como um meio de segmentação. Outro uso de namespaces é a alocação de recursos. Esta opção é chamada "Cotas de recursos". Como segue nas seções anteriores, a definição disso ocorre nos arquivos YAML de configuração, nos quais o estado desejado é declarado. No vSphere, como pode ser visto na captura de tela abaixo, determinamos isso nas configurações de pools de recursos.

Identificação da carga de trabalho
Isso é bastante simples e quase o mesmo para vSphere e Kubernetes. No primeiro caso, usamos os conceitos de Tags para definir (ou agrupar) cargas de trabalho semelhantes e, no segundo, usamos o termo "Labels". No caso do Kubernetes, a identificação da carga de trabalho é obrigatória.

Reserva
Agora para se divertir de verdade. Se você era ou é um grande fã do vSphere FT, como eu, adorará esse recurso no Kubernetes, apesar de algumas diferenças nas duas tecnologias. No vSphere, é uma máquina virtual com uma instância de sombra em execução em um host diferente. Registramos instruções na máquina virtual principal e as reproduzimos na máquina virtual sombra. Se a máquina principal parar de funcionar, a máquina virtual sombra será ligada imediatamente. Em seguida, o vSphere tenta encontrar outro host ESXi para criar uma nova instância de sombra da máquina virtual para manter a mesma redundância. No Kubernetes, temos algo muito semelhante. ReplicaSets é a quantia especificada para executar várias instâncias dos Pods. Se um Pod falhar, outras instâncias estarão disponíveis para veicular tráfego. Ao mesmo tempo, o K8s tentará iniciar um novo Pod em qualquer nó disponível para manter o estado de configuração desejado. A principal diferença, como você já deve ter notado, é que, no caso dos K8s, os Pods sempre funcionam e atendem ao tráfego. Eles não são cargas de trabalho de sombra.

Balanceamento de carga
Embora isso possa não ser uma função interna do vSphere, é muito, muitas vezes necessário, executar balanceadores de carga na plataforma. No mundo do vSphere, existem balanceadores de carga físicos ou virtuais para distribuir o tráfego de rede entre várias máquinas virtuais. Pode haver muitos modos de configuração diferentes, mas vamos supor que queremos dizer configuração One-Armed. Nesse caso, você equilibra a carga do tráfego Leste-Oeste em suas máquinas virtuais.
Da mesma forma, o Kubernetes tem o conceito de "Serviços". O serviço no K8s também pode ser usado em diferentes modos de configuração. Vamos escolher a configuração “ClusterIP” para compará-la com o One-Armed Load Balancer. Nesse caso, o Serviço no K8s terá um endereço IP virtual (VIP), que é sempre estático e não muda. Este VIP distribuirá o tráfego entre vários Pods. Isso é especialmente importante no mundo Kubernetes, onde por natureza os Pods são efêmeros, você perde o endereço IP do Pod no momento em que morre ou é excluído. Portanto, você sempre deve fornecer um VIP estático.
Como já mencionei, o Serviço possui muitas outras configurações, por exemplo, "NodePort", nas quais você atribui uma porta no nível do Nó e executa a tradução de conversão de endereço de porta para os Pods. Há também um “LoadBalancer” em que você executa uma instância do Load Balancer de um provedor de terceiros ou na nuvem.

Kuberentes tem outro mecanismo de balanceamento de carga muito importante chamado "Controlador de ingresso". Você pode considerá-lo um balanceador de carga de aplicativos em linha. A idéia principal é que o Ingress Controller (na forma de um Pod) seja iniciado com um endereço IP visível de fora. Esse endereço IP pode ter algo como registros DNS curinga. Quando o tráfego chega ao Ingress Controller usando um endereço IP externo, ele verifica os cabeçalhos e determina o conjunto de regras que você definiu anteriormente a qual Pod esse nome pertence. Por exemplo: sphinx-v1.esxcloud.net será direcionado ao Serviço sphinx-svc-1 e sphinx-v2.esxcloud.net será direcionado ao Serviço sphinx-svc2, etc.

Armazenamento e Rede
Armazenamento e rede são tópicos muito, muito amplos, quando se trata do Kubernetes. É quase impossível falar brevemente sobre esses dois tópicos em um post introdutório, mas em breve irei falar detalhadamente sobre os diferentes conceitos e opções para cada um desses tópicos. Enquanto isso, vamos ver rapidamente como a pilha de rede funciona no Kubernetes, pois precisaremos dela na próxima seção.
O Kubernetes possui vários "plug-ins" de rede que você pode usar para configurar a rede de seus nós e pods. Um plug-in comum é o “kubenet”, atualmente usado em mega-nuvens, como GCP e AWS. Aqui, falarei brevemente sobre a implementação do GCP e depois mostrarei um exemplo prático de implementação no GKE.

À primeira vista, isso pode parecer muito complicado, mas espero que você possa entender tudo isso até o final deste post. Primeiramente, vemos que temos dois nós Kubernetes: Nó 1 e Nó (m). Cada nó tem uma interface eth0, como qualquer máquina Linux. Essa interface possui um endereço IP para o mundo exterior, no nosso caso, na sub-rede 10.140.0.0/24. O dispositivo Upstream L3 atua como o Gateway padrão para rotear nosso tráfego. Pode ser um switch L3 no seu datacenter ou um roteador VPC na nuvem, como o GCP, como veremos mais adiante. Está tudo bem?
Além disso, vemos que temos a interface Bridge cbr0 dentro do nó. Essa interface é o Gateway Padrão da sub-rede IP 10.40.1.0/24 no caso do Nó 1. Essa sub-rede é atribuída pelo Kubernetes a cada Nó. Os nós geralmente obtêm uma sub-rede / 24, mas você pode alterar isso usando o NSX-T (abordaremos isso nas próximas postagens). No momento, é essa sub-rede a partir da qual emitiremos endereços IP para os Pods. Dessa forma, qualquer Pod dentro do Nó 1 obterá um endereço IP dessa sub-rede. No nosso caso, o Pod 1 tem um endereço IP 10.40.1.10. No entanto, você percebe que existem dois contêineres aninhados neste Pod. Já dissemos que em um Pod um ou vários contêineres podem ser lançados, que estão intimamente relacionados entre si em termos de funcionalidade. É o que vemos na figura. O contêiner 1 escuta na porta 80 e o contêiner 2 escuta na porta 90. Os dois contêineres têm o mesmo endereço IP 10.40.1.10, mas não possuem o Espaço de Nomes de Rede. OK, então quem é o dono dessa pilha de rede? Na verdade, existe um contêiner especial chamado "Pausar contêiner". O diagrama mostra que seu endereço IP é o endereço IP do Pod para comunicação com o mundo exterior. Portanto, o Pause Container possui essa pilha de rede, incluindo o próprio endereço IP 10.40.1.10 e, é claro, redireciona o tráfego para o contêiner 1 para a porta 80 e também redireciona o tráfego para o contêiner 2 para a porta 90.
Agora você precisa perguntar como o tráfego é redirecionado para o mundo exterior? Temos o encaminhamento de IP padrão do Linux habilitado para encaminhar o tráfego de cbr0 para eth0. Isso é ótimo, mas não está claro como o dispositivo L3 pode aprender a encaminhar o tráfego para o destino. Neste exemplo específico, não temos roteamento dinâmico para o anúncio desta rede. Portanto, devemos ter algum tipo de rota estática no dispositivo L3. Para alcançar a sub-rede 10.40.1.0/24, é necessário encaminhar o tráfego para o endereço IP do Nó 1 (10.140.0.11) e para alcançar a sub-rede 10.40.2.0/24 a próxima esperança - Nó (m) com o endereço IP 10.140.0.12.
Tudo isso é ótimo, mas é uma maneira muito impraticável de gerenciar suas redes. O suporte a todas essas rotas ao escalonar seu cluster será um pesadelo absoluto para os administradores de rede. É por isso que algumas soluções, como CNI (Container Network Interface) em Kuberentes, são necessárias para gerenciar a conectividade de rede. O NSX-T é uma dessas soluções com funcionalidade muito ampla para interação e segurança da rede.
Lembre-se de que analisamos o plugin kubenet, não a CNI. O plug-in kubenet é o que o Google Container Engine (GKE) usa, e a maneira como eles fazem isso é bastante divertida porque é totalmente definido por software e automatizado em sua nuvem. , GCP. .
O que vem a seguir?
Kuberentes. ,
.
A segunda parte.. .
.