Muitos projetos enfrentam o problema dos testes esquisitos, e esse tópico foi levantado mais de uma vez em Habré. Os testes que não decidiram suas condições constantemente levam não apenas o tempo da máquina, mas também o tempo dos desenvolvedores e testadores. E se em uma empresa comercial você pode alocar um determinado recurso para resolver esse problema e nomear pessoas responsáveis, então na comunidade de código aberto não é tão simples. Especialmente quando se trata de grandes projetos - por exemplo, como o Apache Ignite, onde existem quase 60 mil testes diferentes.

De fato, neste post, mostraremos como resolver esse problema no Apache Ignite. Somos Dmitry Pavlov, engenheiro de software / gerente de comunidade da GridGain, e Nikolai Kulagin, engenheiro de TI da Sberbank Technologies.
Tudo escrito abaixo não representa a posição de nenhuma empresa, incluindo o Sberbank. Esta história é exclusivamente de membros da comunidade Apache Ignite.Apache Ignite e testes
A história do Apache Ignite começa em 2014, quando o GridGain doou a primeira versão do produto interno para a Apache Software Foundation. Mais de quatro anos se passaram desde então e, durante esse período, o número de testes chegou à marca de 60 mil.
Usamos o JetBrains TeamCity como servidor de integração contínua - obrigado aos funcionários do JetBrains por apoiar o movimento de código aberto. Todos os nossos testes são distribuídos entre as suítes, cujo número para a ramificação principal é próximo a 140. Nas suítes, os testes são agrupados por algum critério. Isso pode estar testando apenas a funcionalidade do Machine Learning [RunMl], apenas o cache [RunCache] ou todo o [RunAll]. No futuro, a execução dos testes significará exatamente [RunAll] - uma verificação completa. Demora aproximadamente 55 horas de tempo da máquina.
O Junit é usado como a biblioteca principal, mas existem poucos testes de unidade. Na maioria das vezes, todos os nossos testes são de integração, pois contêm o lançamento de um ou mais nós (e isso leva alguns segundos). Obviamente, os testes de integração são convenientes porque um desses testes abrange muitos aspectos e interações, o que é bastante difícil de obter com um único teste de unidade. Mas também há desvantagens: no nosso caso, esse é um lead time bastante longo, além da dificuldade de encontrar um problema.
Problemas com esquisito
Parte desses testes é escamosa. Agora, de acordo com a classificação do TeamCity, aproximadamente 1.700 testes são marcados como esquisitos - ou seja, com uma mudança de estado sem alterar o código ou a configuração. Esses testes não podem ser ignorados, pois existe o risco de ocorrer um erro na produção. Portanto, eles precisam ser verificados duas vezes e reiniciados, às vezes várias vezes, para analisar os resultados das quedas - e isso exige tempo e esforço preciosos. E se os membros existentes da comunidade lidam com essa tarefa, para novos colaboradores, isso pode se tornar uma barreira real. Você deve admitir que, ao fazer alterações no Java Doc, não espera encontrar uma falha, mas não uma, mas várias dezenas.

Quem é o culpado?
Metade dos problemas com testes escamosos surge devido à configuração do equipamento, devido ao tamanho da instalação. E a segunda metade está diretamente ligada às pessoas que erraram e não corrigiram o erro.
Convencionalmente, todos os membros da comunidade podem ser divididos em dois grupos:
- Entusiastas que entram na comunidade por vontade própria e contribuem para o seu tempo livre.
- Contribuidores em período integral que trabalham para empresas que de alguma forma usam ou estão associadas a este produto de código aberto.
Um colaborador do primeiro grupo pode muito bem fazer uma única edição e deixar a comunidade. E alcançá-lo em caso de detecção de um bug é quase impossível. É mais fácil interagir com pessoas do segundo grupo, é mais provável que elas respondam a um teste que fazem. Mas acontece que uma empresa que anteriormente estava interessada em um produto deixou de precisar dele. Ela está deixando a comunidade e seus funcionários contribuintes estão com ela. Ou é possível que o colaborador deixe a empresa e com ela a comunidade. Obviamente, após essas mudanças, alguns ainda continuam a participar da comunidade. Mas não todos.
Quem vai consertar?
Se estamos falando de pessoas que deixaram a comunidade, seus bugs, é claro, vão para os colaboradores atuais. Vale ressaltar que, para a revisão que levou ao bug, o revisor também é responsável, mas também pode ser um entusiasta - ou seja, ele nem sempre estará disponível.
Acontece que acaba alcançando uma pessoa, diga-lhe: este é o problema. Mas ele diz: não, essa não é minha correção introduziu um bug. Como uma execução completa da ramificação principal é executada automaticamente com uma fila relativamente livre, isso geralmente ocorre à noite. Antes disso, vários commits podem ser despejados no ramo durante o dia inteiro.
No TeamCity, qualquer modificação de código é considerada um registro de alterações. Se depois de três trocadores tivermos uma nova queda, três pessoas dirão que isso não se deve ao seu comprometimento. Se houver cinco trocadores, ouviremos de cinco pessoas.
Outro problema: informar ao colaborador que os testes devem ser executados antes de cada revisão. Alguns não sabem onde, o que e como correr. Ou os testes foram executados, mas o colaborador não escreveu sobre isso no ticket. Também há problemas nesta fase.
Vá em frente. Suponha que os testes sejam executados e no ticket haja um link para os resultados. Mas, como se viu, isso não oferece nenhuma garantia da análise dos testes de execução. O colaborador pode olhar para sua corrida, ver alguns lançamentos lá, mas escrever "TeamCity Looks Good". O revisor - especialmente se ele estiver familiarizado com o colaborador ou o tiver revisado com sucesso antes - talvez não veja realmente o resultado. E nós temos esse "TeamCity Looks Good":
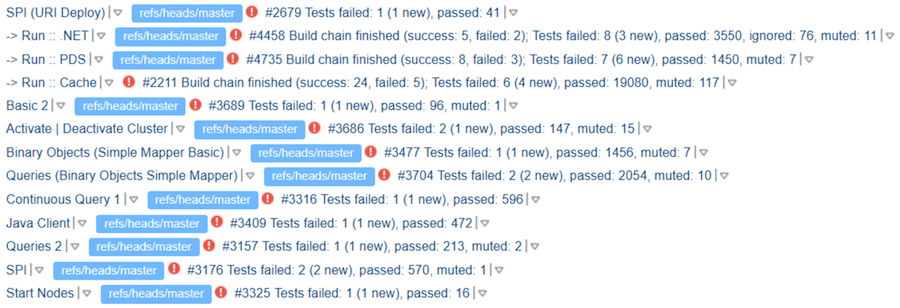
Onde "Bom" está aqui não está claro. Mas, aparentemente, os autores pelo menos sabem que os testes precisam ser executados.
Como lutamos contra isso
Método 1. Testes separados
Dividimos os testes em dois grupos. No primeiro, "limpo" - testes estáveis. No segundo - instável. A abordagem é bastante óbvia, mas não deu certo mesmo com duas tentativas. Porque Porque uma suíte com testes instáveis se transforma em um gueto onde algo começa necessariamente a expirar, trava etc. Como resultado, todo mundo começa a simplesmente ignorar esses testes sempre problemáticos. Em geral, não faz sentido dividir os testes por nota.
Método 2. Separação e notificação
A segunda opção é semelhante à primeira - para alocar testes mais estáveis e executar os demais testes de RP à noite. Se algo quebrar em um grupo estável, uma mensagem é enviada ao colaborador com as ferramentas padrão do TeamCity, informando que algo precisa ser corrigido.
... 0 pessoas reagiram a essas mensagens. Todos os ignoraram.
Método 3. Monitoramento Diário
Dividimos as suítes em vários "observadores", os membros mais responsáveis da comunidade, e os assinamos para receber alertas sobre quedas. Como resultado, foi confirmado na prática que o entusiasmo tende a acabar. Os colaboradores abandonam esse empreendimento e param de verificar regularmente. Então eu perdi, olhei para lá - e novamente algo se arrastou para o mestre.
Método 4. Automação
Após outro método malsucedido, os caras do GridGain se lembraram de um utilitário desenvolvido anteriormente que adicionava a funcionalidade ausente naquele momento no TeamCity. Ou seja, a capacidade de visualizar estatísticas gerais sobre o número de quedas: quanto e o que caiu, deteriorou ou melhorou o resultado no dia seguinte. Esse utilitário foi desenvolvido gradualmente, os relatórios foram adicionados e renomeados. Em seguida, eles adicionaram notificações, renomeadas novamente. Então, descobriu-se o TeamCity Bot. Agora ele tem quase 500 confirmações e 7 contribuidores e está no repositório adicional do Apache.
O que o bot faz? Seus recursos podem ser combinados em dois grupos:
- Monitoramento do projeto - monitoramento visual, exibindo os resultados das execuções, bem como a notificação automática em mensageiros instantâneos (por exemplo, folga)
- Verificação de agência - análise de teste de RP, bem como emissão de visto em um bilhete.
Fluxo de trabalho do TeamCity Bot
Antes do Apache Ignite Teamcity Bot, o processo de "contribuição" para a comunidade era o seguinte:
- No JIRA, um dos tickets é selecionado e fixo;
- Uma solicitação de recebimento é criada;
- Executa testes que podem ser afetados pelas alterações feitas;
- Se os testes forem aprovados, a solicitação de recebimento poderá ser visualizada e moderada pelo responsável pela entrega.
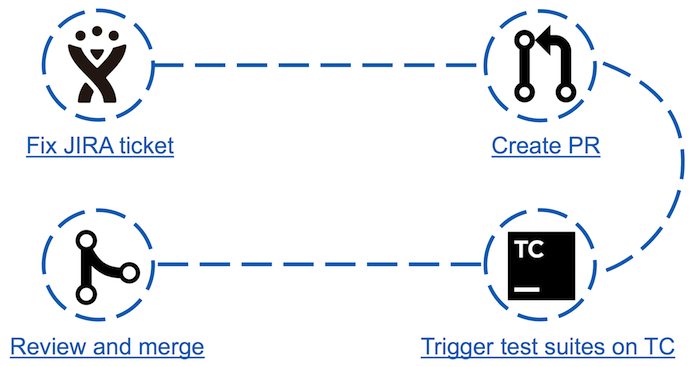
Parece simples, mas na verdade o terceiro ponto pode ser uma barreira para alguns colaboradores. Por exemplo: um recém-chegado à comunidade decide dar sua primeira contribuição escolhendo o ingresso mais simples. Isso pode estar editando um Java Doc ou atualizando versões de dependência automatizada. Analisando os resultados da corrida em sua pequena correção, ele de repente descobre que cerca de 30 testes caíram. De onde vem o número de testes com falha e como analisá-los - ele não sabe. Pode-se esperar que o colaborador nunca volte aqui.
Membros mais experientes da comunidade também sofrem de escamação - passam um tempo analisando testes que caíram por acaso e, portanto, dificultam o desenvolvimento do produto.
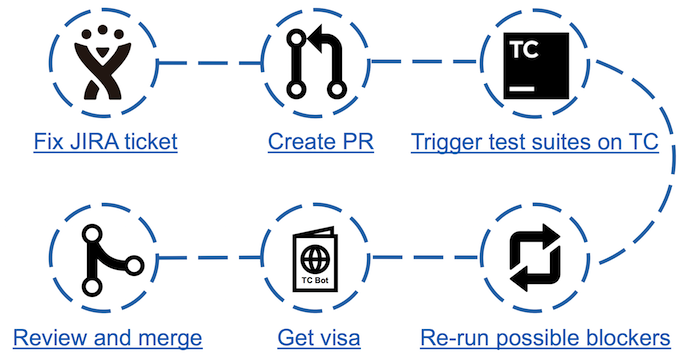 Esquema de contribuição com o TeamCity Bot
Esquema de contribuição com o TeamCity BotCom o advento do bot, as etapas na contra-ação aumentaram, mas o tempo gasto analisando os testes caídos diminuiu significativamente. Agora basta executar o teste e, depois de aprovado, observe a página do bot correspondente. Se houver bloqueadores possíveis (testes descartados que não são considerados inadequados), basta executar uma verificação dupla, após a qual você pode obter um visto na forma de um comentário no JIRA com os resultados do teste.
Visão geral dos recursos
 Inspecionar contribuição - uma lista de todos os PRs não fechados com um resumo de cada informação: a data da última atualização, número do PR, nome, autor e ticket no JIRA
Inspecionar contribuição - uma lista de todos os PRs não fechados com um resumo de cada informação: a data da última atualização, número do PR, nome, autor e ticket no JIRA .
 Para cada solicitação de recebimento, uma guia com informações mais detalhadas está disponível: o nome correto do PR, sem o qual o bot não conseguirá encontrar o ticket desejado no JIRA; se os testes foram executados; se o resultado do teste está pronto; deixou um comentário no JIRA.
Para cada solicitação de recebimento, uma guia com informações mais detalhadas está disponível: o nome correto do PR, sem o qual o bot não conseguirá encontrar o ticket desejado no JIRA; se os testes foram executados; se o resultado do teste está pronto; deixou um comentário no JIRA.Análise dos resultados dos testes:


Aqui estão dois relatórios sobre o teste do mesmo PR. O primeiro é do bot. O segundo é um relatório padrão sobre o Teamcity. A diferença na quantidade de informações é óbvia, e isso não leva em conta o fato de que, para visualizar o histórico das execuções de teste do TC, também será necessário fazer várias transições para as páginas adjacentes.
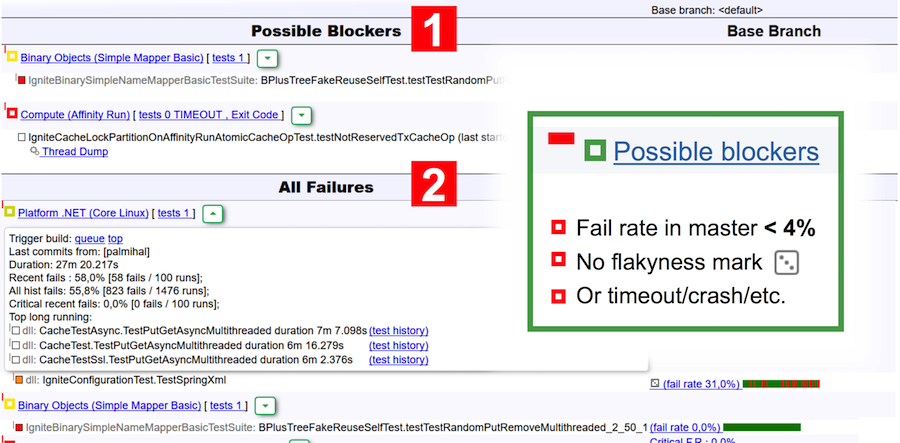
Vamos voltar ao relatório do bot. Este relatório é visualmente dividido em duas tabelas: possíveis bloqueadores e todas as falhas. Os bloqueadores incluem testes que:
- ter uma taxa de falhas no mestre inferior a 4% (menos de 4 partidas em 100 foram malsucedidas);
- não são escamosos de acordo com a classificação do TeamCity;
- caiu devido a um tempo limite, falta de memória, código de saída, falha na JVM.
Por exemplo, na captura de tela acima, duas suítes são indicadas como possíveis bloqueadores - no primeiro, o teste caiu e, no segundo, ocorreu um tempo limite.
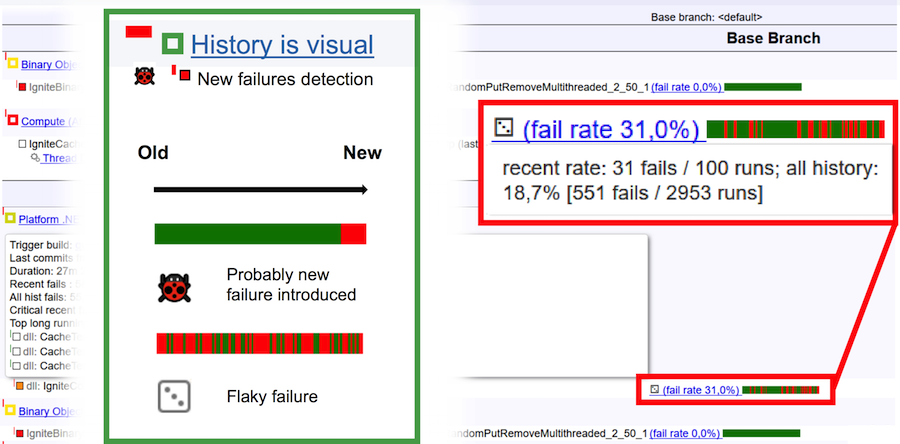
Para finalmente entender o que é um teste superficial e o que é um bug, considere a imagem acima. A barra horizontal é de 100 corridas. Barra verde vertical - aprovada com êxito no teste, gota vermelha. No caso de um bug, o histórico de corridas parece natural: uma barra verde simples no final muda de cor para vermelho. Isso significa que foi nesse local que um bug apareceu e o teste começou a cair constantemente. Se tivermos diante de nós um teste superficial, seu histórico de corridas é uma alternância contínua de cores verde e vermelho.
Análise dos Resultados do Teste
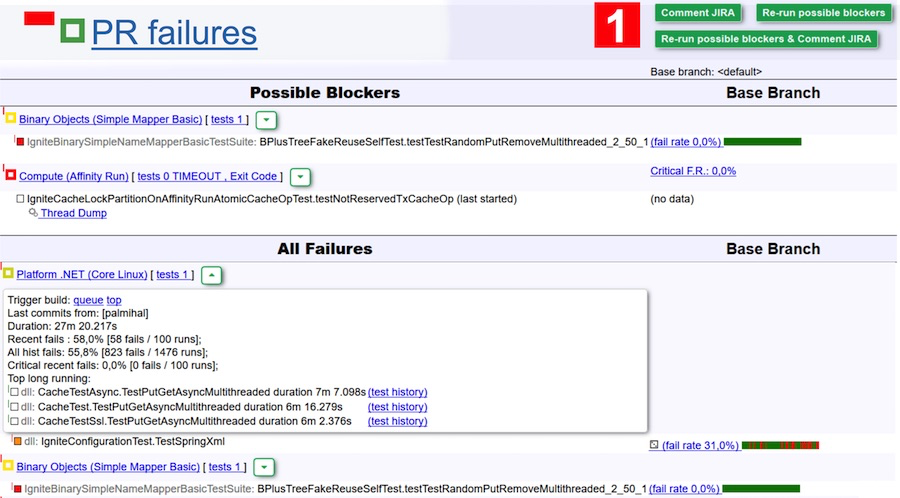
Por exemplo, analisamos os resultados da aprovação nos testes na captura de tela acima. De acordo com a versão do bot, pode haver duas falhas devido a um erro - elas estão listadas na tabela Bloqueadores possíveis. Mas pode muito bem ser testes esquisitos com uma baixa taxa de falhas. Para excluir esta opção, basta clicar no botão Executar novamente os possíveis bloqueadores, e esses dois conjuntos irão verificar novamente. Para tornar a tarefa ainda mais fácil, você pode clicar em Executar novamente os possíveis bloqueadores e comentar o JIRA e obter um comentário (e uma notificação por e-mail) do bot depois que a verificação for concluída. Então entre e veja se há um problema ou não.
Para os revisores, isso é muito legal. Você pode esquecer as edições que não foram aprovadas em nenhuma verificação, mas basta clicar em várias edições, clicar no grande botão verde Executar novamente e aguardar a letra.
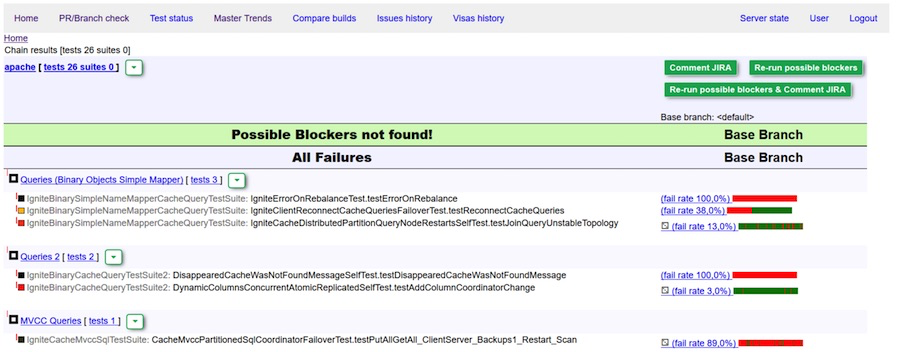 Relatório perfeito: nenhum bloqueador detectado
Relatório perfeito: nenhum bloqueador detectado

Visto verde (comentário) do bot. Nenhum bloqueador encontrado.
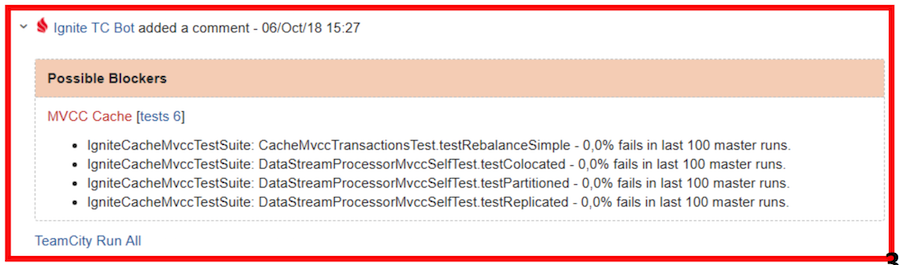
Visto vermelho - verificação dupla e / ou edição de bugs necessáriosAcontece que alguns bugs ainda vazam para o "mestre". Como dissemos, antes isso era combatido por meio de notificações pessoais. Ou alguma pessoa se certificou de que nada caísse. Agora estamos usando uma solução mais simples:

Quando um novo bug é detectado, uma mensagem é enviada para a lista de desenvolvedores, indicando os contribuidores e seus trocadores, que podem ser a causa do erro. Assim, toda a comunidade descobrirá quem fez tudo acontecer.
Dessa forma, conseguimos aumentar o número de hot fixes e reduzir bastante o tempo necessário para solucionar o problema.
Monitorando o Status do Assistente
Outra das funções do bot é monitorar o estado do assistente com as estatísticas dos lançamentos mais recentes.

Principais tendências

A página de tendências principais compara duas seleções "principais" para períodos específicos. Para cada item da tabela exibe o valor máximo, mínimo e mediana.

Além dos resultados gerais de toda a amostra, a tabela contém gráficos para cada indicador com a exibição dos valores de cada construção. Ao clicar em um ponto, você pode acessar os resultados da execução no TeamCity. Além disso, é possível remover o resultado das estatísticas. Isso é útil quando valores anormais ocorrem devido a falhas graves, às quais o colaborador provavelmente não é o culpado. Tais resultados devem ser excluídos para que não sejam levados em consideração no cálculo dos mesmos testes de falhas. Além disso, a construção também pode ser diferenciada para rastrear os resultados para cada indicador.
O Apache Ignite Teamcity Bot agora tem mais de 65 membros registrados. Durante todo o período de uso do bot, os vistos receberam mais de 400 solicitações pull e, em média, cinco vistos são emitidos por dia.
Estrutura de bot do TeamCity
O bot está hospedado em um servidor separado, acessa ignite.apache.org para obter dados, notifica publicamente todos na lista de desenvolvedores - esta é a nossa principal plataforma para desenvolvedores do Ignite - e grava vistos em tickets por meio da API do JIRA.
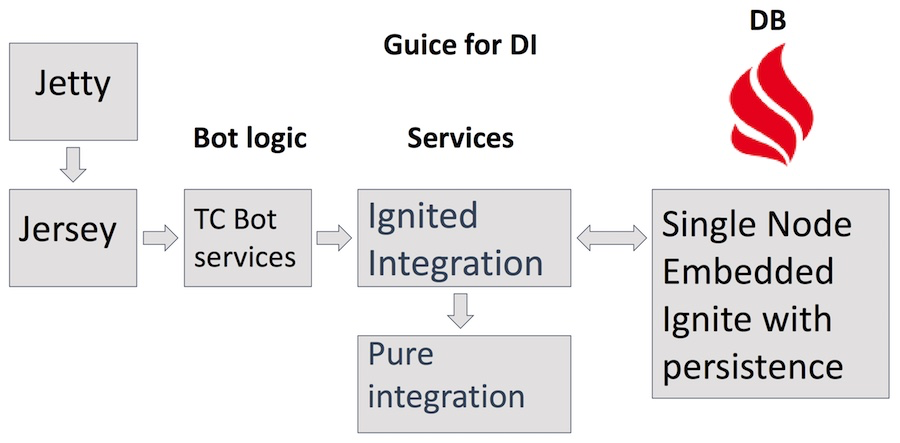
Ele usa o servidor Jetty, servlets de Jersey, vários serviços com lógica de negócios complexa do bot em si, incluindo serviços Teamcity, JIRA e GitHub que acessam o serviço Ignited Integration. Além disso, Pure Integration para solicitações http. Como armazenamento - o próprio produto do Apache Ignite no modo incorporado de configuração de nó único com persistência ativa. Além das vantagens óbvias de usar o Ignite como banco de dados, também nos ajuda a encontrar várias áreas de aplicação do Ignite e a entender o que é conveniente e o que não é.
A primeira versão da implementação do bot foi inspirada em um artigo sobre armazenamento em cache REST e era um cache REST e serviços GitHub e Teamcity. O Teamcity xml e o json retornados do servidor foram analisados pelo Pure Java Objects, que foram armazenados em cache. No começo, funcionou e muito rapidamente. Mas com o aumento da quantidade de dados, os resultados começaram a se deteriorar.
Vale a pena notar que o TeamCity exclui uma história com mais de ~ 2 semanas, mas o bot não. Por fim, com essa abordagem, surgiram toneladas de dados muito difíceis de gerenciar.
TeamCity Bot Development
A nova abordagem implementa uma opção compacta de armazenamento de dados e opta por um pequeno número de partições de cache. Um grande número de partições em um nó afeta negativamente a velocidade da sincronização de dados no disco e aumenta a hora de início do cluster.
Todas as principais atualizações de dados são executadas de forma assíncrona, pois, caso contrário, corremos o risco de obter um UX ruim devido ao lento retorno dos dados do TeamCity.
Para cadeias que raramente alteram seus valores (por exemplo, os nomes dos testes), um mapeamento simples é feito no id, gerado pela Sequência Atômica. Aqui está um exemplo dessa entrada:

O nome do teste longo corresponde ao número int, que é armazenado em todas as compilações. Isso economiza uma enorme quantidade de recursos. No topo dos métodos que retornam essa linha, está o interceptador de cache na memória Guava. Graças à anotação do cache, mesmo no heap, não selecionamos linhas lendo-as no Ignite by id. E por id, sempre obtemos a mesma linha, o que é bom para o desempenho.
Para linhas "imprevisíveis", por exemplo, logs de rastreamento de pilha, vários tipos de compactação são usados - compactação gzip, compactação instantânea ou descompactada, dependendo da melhor. Todos esses métodos ajudam a ajustar o máximo de dados na memória e dão uma resposta rápida ao cliente.
Por que TeamCity Bot é melhor
Isso não quer dizer que o TeamCity não tenha os recursos listados acima. Eles estão, mas espalhados por uma pilha de lugares diferentes. No bot, tudo é coletado em uma página e você pode entender rapidamente qual é o problema.
Uma boa adição é a carta que o bot envia na planilha de desenvolvimento quando detecta um problema. Imediatamente na comunidade, há uma ocasião para iniciar uma discussão: “Vamos, talvez, agora vamos reverter?”. Isso adiciona confiança aos revisores.
Com o bot, é muito mais fácil para novos colaboradores ingressar no processo de desenvolvimento. Ao fazer sua primeira correção, você nem sempre sabe o que as alterações feitas podem acarretar. E mergulhando de cabeça na análise dos resultados dos testes no TeamCity, você pode facilmente perder seu entusiasmo por um maior desenvolvimento. O Apache Ignite TeamCity Bot ajudará você a entender rapidamente se houver um problema e manter o entusiasmo.
Esperamos que o bot simplifique a vida dos colaboradores atuais e atraia novas pessoas para a comunidade. Finalmente, aconselhamos, é claro, a impedir o aparecimento de um grande número de testes inadequados, porque é difícil lidar com eles. E confie nos robôs - eles não têm preferências e não aceitam a palavra das pessoas.