
 Anton Chaynikov, desenvolvedor de ciência de dados, Redmadrobot
Anton Chaynikov, desenvolvedor de ciência de dados, Redmadrobot
Olá Habr! Hoje vou falar sobre as dificuldades no caminho para o chatbot, o que facilita o trabalho dos operadores de chat da companhia de seguros. Mais precisamente, como ensinamos o bot a distinguir solicitações um do outro usando o aprendizado de máquina. Quais modelos foram experimentados e quais obtiveram os resultados. Como quatro abordagens para limpar e enriquecer dados de qualidade decente e cinco tentativas para limpar dados de qualidade "indecentes".
Desafio
O bate-papo da companhia de seguros recebe +100500 chamadas de clientes por dia. A maioria das perguntas é simples e repetitiva, mas os operadores não são mais fáceis e os clientes ainda precisam esperar de cinco a dez minutos. Como melhorar a qualidade do serviço e otimizar os custos de mão-de-obra para que os operadores tenham menos rotina e os usuários tenham sensações mais agradáveis ao resolver rapidamente seus problemas?
E nós vamos fazer um chatbot. Deixe-o ler as mensagens do usuário, dar instruções para casos simples e fazer perguntas padrão para casos complexos, a fim de obter as informações de que o operador precisa. Um operador ativo possui uma árvore de scripts - um script (ou fluxograma) que diz quais perguntas os usuários podem fazer e como responder a elas. Adotaríamos esse esquema e o colocaríamos em um chatbot, mas é uma má sorte - o chatbot não entende humanamente e não sabe como relacionar a pergunta do usuário ao ramo de script.
Então, vamos ensiná-lo com a ajuda do bom e velho aprendizado de máquina. Mas você não pode simplesmente pegar um dado gerado pelos usuários e ensinar a ele um modelo de qualidade decente. Para fazer isso, você precisa experimentar a arquitetura do modelo, dados - para limpar e, às vezes, coletar novamente.
Como ensinar um bot:
- Considere as opções do modelo: como o tamanho do conjunto de dados, os detalhes da vetorização dos textos, a redução da dimensão, o classificador e a precisão final são combinados.
- Vamos limpar dados decentes: encontraremos classes que podem ser jogadas fora com segurança; descobriremos por que os últimos seis meses de marcação são melhores que os três anteriores; determine onde está o modelo e onde está a marcação; Descubra como erros de digitação podem ser úteis.
- Limparemos os dados "indecentes": descobriremos em que casos o agrupamento é útil e inútil, pois os usuários e operadores conversam quando é hora de parar de sofrer e coletar a marcação.
Textura
Tínhamos dois clientes - companhias de seguros com bate-papos on-line - e projetos de treinamento de chatbot (não vamos chamá-los, isso não é importante), com qualidade de dados muito diferente. Bem, se metade dos problemas do segundo projeto pudesse ser resolvida com manipulações do primeiro. Os detalhes estão abaixo.
Do ponto de vista técnico, nossa tarefa é classificar os textos. Isso é feito em duas etapas: primeiro os textos são vetorizados (usando tf-idf, doc2vec etc.), depois o modelo de classificação é treinado nos vetores (e classes) obtidos - floresta aleatória, SVM, rede neural etc. e assim por diante.
De onde vêm os dados:
- Sql-upload de histórico de chat. Campos de upload relevantes: texto da mensagem; autor (cliente ou operador); agrupar mensagens em diálogos; timestamp; categoria de contato do cliente (perguntas sobre seguro obrigatório de responsabilidade civil, seguro de casco, seguro médico voluntário; perguntas sobre o site; perguntas sobre programas de fidelidade; perguntas sobre alterações nas condições de seguro, etc.).
- Uma árvore de scripts ou sequências de perguntas e respostas de operadores para clientes com solicitações diferentes.
Sem validação, é claro, em lugar nenhum. Todos os modelos foram treinados em 70% dos dados e avaliados de acordo com os resultados dos 30% restantes.
Métricas de qualidade para os modelos que usamos:
- Em treinamento: logloss, por diferenciabilidade;
- Ao escrever relatórios: precisão de classificação em uma amostra de teste, por simplicidade e clareza (inclusive para o cliente);
- Ao escolher a direção para outras ações: a intuição de um cientista de dados que olha atentamente para os resultados.
Experiências modelo
É raro quando a tarefa deixa claro imediatamente qual modelo fornecerá os melhores resultados. Então aqui: sem experimentação, em lugar nenhum.
Vamos tentar as opções de vetorização:
- tf-idf em palavras únicas;
- tf-idf em triplos caracteres (a seguir: 3 gramas);
- tf-idf em 2-, 3-, 4-, 5 gramas separadamente;
- tf-idf em 2-, 3-, 4-, 5 gramas tomados em conjunto;
- Tudo acima + redução de palavras no texto de origem para um formulário de dicionário;
- Todas as opções acima + diminuem de dimensão pelo método SVD truncado;
- Com o número de medições: 10, 30, 100, 300;
- doc2vec, treinado no corpo dos textos da tarefa.
As opções de classificação nesse cenário parecem bastante ruins: SVM, XGBoost, LSTM, florestas aleatórias, bayes ingênuos, florestas aleatórias sobre as previsões de SVM e XGB.
E embora tenhamos verificado a reprodutibilidade dos resultados em três conjuntos de dados montados independentemente e seus fragmentos, podemos apenas garantir a ampla aplicabilidade.
Os resultados dos experimentos:
- Na cadeia “pré-processamento-vetorização-redução de dimensão-classificação”, o efeito da escolha em cada etapa é quase independente das outras etapas. O que é muito conveniente, você não pode passar por uma dúzia de opções com cada nova idéia e usar a opção mais conhecida a cada passo.
- tf-idf em palavras perde para 3 gramas (precisão 0,72 vs 0,78). 2-, 4-, 5 gramas perdem para 3 gramas (0,75-0,76 vs 0,78). {2; 5} -grams todos juntos superam um pouco 3 gramas. Dado o aumento acentuado na memória necessária, decidimos negligenciar o treinamento com um ganho de precisão de 0,4%.
- Comparado ao tf-idf de todas as variedades, o doc2vec estava indefeso (precisão de 0,4 e abaixo). Valeria a pena tentar treiná-lo não no corpo da tarefa (~ 250.000 textos), mas em um número muito maior (2,5–25 milhões de textos), mas até agora, infelizmente, suas mãos ainda não chegaram.
- SVD truncado não ajudou. A precisão aumenta monotonicamente com o aumento da medição, atingindo suavemente a precisão sem TSVD.
- Entre os classificadores, o XGBoost vence por uma margem perceptível (+ 5–10%). Os concorrentes mais próximos são SVM e florestas aleatórias. Naive Bayes não é concorrente nem mesmo em florestas aleatórias.
- O sucesso do LSTM depende muito do tamanho do conjunto de dados: em uma amostra de 100.000 objetos, ele é capaz de competir com o XGB. Em uma amostra de 6000 - no atraso junto com Bayes.
- Uma floresta aleatória no topo do SVM e do XGB sempre concorda com o XGB ou se engana mais. Isso é muito triste, esperamos que o SVM encontre nos dados pelo menos alguns padrões que não estão disponíveis para o XGB, mas infelizmente.
- O XGBoost é complicado com estabilidade. Por exemplo, sua atualização da versão 0.72 para 0.80 inexplicavelmente reduziu a precisão dos modelos treinados em 5 a 10%. E mais uma coisa: o XGBoost suporta a alteração de parâmetros de treinamento durante o treinamento e a compatibilidade com a API padrão do scikit-learn, mas estritamente separadamente. Você não pode fazer as duas coisas juntos. Tinha que consertar isso.
- Se você trouxer palavras para um formulário de dicionário, isso melhora um pouco a qualidade, em combinação com tf-idf, mas é inútil em todos os outros casos. No final, a desativamos para economizar tempo.
Experiência 1. Limpeza de dados ou o que fazer com a marcação
Operadores de bate-papo são apenas pessoas. Ao definir as categorias de consultas do usuário, eles geralmente são confundidos e têm diferentes interpretações dos limites entre as categorias. Portanto, os dados de origem devem ser limpos de forma implacável e intensa.
Nossos dados sobre o treinamento do modelo no primeiro projeto:
- Um histórico de mensagens de bate-papo on-line ao longo de vários anos. São 250.000 postagens em 60.000 conversas. No final do diálogo, o operador selecionou a categoria à qual a chamada do usuário pertence. Existem cerca de 50 categorias neste conjunto de dados.
- Árvore de scripts. No nosso caso, os operadores não tinham scripts de trabalho.
O que exatamente os dados são ruins, formulamos como hipóteses, depois verificamos e, sempre que possível, corrigimos. Aqui está o que aconteceu:
A primeira abordagem. De toda a enorme lista de aulas, você pode sair com segurança de 5 a 10.
Descartamos classes pequenas (<1% da amostra): poucos dados + pequeno impacto. Unimos classes difíceis de distinguir, às quais os operadores ainda reagem da mesma maneira. Por exemplo:
'dms' + 'como marcar uma consulta com um médico' + 'pergunta sobre o preenchimento do programa'
'cancelamento' + 'status de cancelamento' + 'cancelamento de política paga'
'pergunta de renovação' + 'como renovar a política?'
Em seguida, lançamos classes como “other”, “other” e similares: para um chatbot, elas são inúteis (redirecionando para um operador de qualquer maneira) e, ao mesmo tempo, danificam bastante a precisão, pois 20% das solicitações (30, 50, 90) são classificadas pelos operadores de maneira inadequada e aqui Agora jogamos fora a classe com a qual o chatbot ainda não pode trabalhar.
Resultado: em um caso, crescimento de uma precisão de 0,40 a 0,69, em outro, de 0,66 a 0,77.
A segunda abordagem. No início do bate-papo, os próprios operadores entendem mal como escolher uma classe para o usuário entrar em contato, para que haja muitos "ruídos" e erros nos dados.
Experiência: tomamos apenas os últimos dois (três, seis, ...) meses de diálogos e treinamos o modelo em
eles.
Resultado: em um caso notável, a precisão aumentou de 0,40 para 0,60, em outro - de 0,69 para 0,78.
A terceira abordagem. Às vezes, uma precisão de 0,70 não significa "o modelo está errado em 30% dos casos", mas "em 30% dos casos a marcação está incorreta e o modelo a corrige de maneira bastante razoável".
Por métricas como precisão ou perda de log, essa hipótese não pode ser verificada. Para os propósitos do experimento, nos limitamos ao olhar de um cientista de dados, mas, no caso ideal, é necessário reorganizar qualitativamente o conjunto de dados, sem esquecer a validação cruzada.
Para trabalhar com essas amostras, criamos o processo de "enriquecimento iterativo":
- Divida o conjunto de dados em 3-4 fragmentos.
- Treine o modelo no primeiro fragmento.
- Preveja as classes da segunda pelo modelo treinado.
- Observe atentamente as classes previstas e o grau de confiança do modelo; escolha o valor limite da confiança.
- Remova os textos (objetos) previstos com confiança abaixo do limite do segundo fragmento, treine o modelo nisso.
- Repita até que os fragmentos se cansem ou acabem.
Por um lado, os resultados são excelentes: o primeiro modelo de iteração possui uma precisão de 70%, o segundo - 95%, o terceiro - 99 +%. Uma análise atenta dos resultados das previsões confirma totalmente essa precisão.
Por outro lado, como se pode verificar sistematicamente nesse processo que os modelos subsequentes não aprendem os erros dos anteriores? Existe uma idéia para testar o processo em um conjunto de dados "barulhento" manualmente com marcação inicial de alta qualidade, como MNIST. Mas, infelizmente, não havia tempo suficiente para isso. E sem verificação, não ousamos lançar o enriquecimento iterativo e os modelos resultantes na produção.
A quarta abordagem. O conjunto de dados pode ser expandido - aumentando a precisão e reduzindo a reciclagem, adicionando muitos erros de digitação aos textos existentes.
Os erros de digitação são erros de digitação - dobrando uma letra, pulando uma letra, reorganizando as letras vizinhas em alguns lugares, substituindo uma letra por uma letra adjacente no teclado.
Experiência: a proporção de p letras em que ocorrerá um erro de digitação: 2%, 4%, 6%, 8%, 10%, 12%. Aumento do conjunto de dados: geralmente até 60.000 réplicas. Dependendo do tamanho inicial (depois dos filtros), isso significava um aumento de 3 a 30 vezes.
Resultado: depende do conjunto de dados. Em um pequeno conjunto de dados (~ 300 réplicas), 4-6% dos erros de digitação fornecem um aumento estável e significativo na precisão (0,40 → 0,60). Em grandes conjuntos de dados, tudo é pior. Com uma proporção de erros de digitação de 8% ou mais, os textos se tornam absurdos e a precisão diminui. Com uma taxa de erro de 2 a 8%, a precisão varia na faixa de alguns por cento, muito raramente excede a precisão sem erros de digitação e, como parece, não há necessidade de aumentar o tempo de treinamento várias vezes.
Como resultado, obtemos um modelo que distingue 5 classes de chamadas com uma precisão de 0,86. Coordenamos com o cliente os textos das perguntas e respostas de cada um dos cinco garfos, fixamos os textos no chatbot e os enviamos ao controle de qualidade.
Experiência 2. Dados detalhados ou o que fazer sem marcação
Tendo obtido bons resultados no primeiro projeto, abordamos o segundo com toda confiança. Mas, felizmente, não esquecemos como ser surpreendidos.
O que encontramos:
- Uma árvore de scripts de cinco ramos concordou com o cliente há cerca de um ano.
- Uma amostra marcada de 500 mensagens e 11 classes de origem desconhecida.
- Marcados por operadores de bate-papo a partir de 220.000 mensagens, 21.000 conversas e 50 outras classes.
- O modelo SVM, treinado na primeira amostra, com uma precisão de 0,69, herdado da equipe anterior de cientistas de dados. Por que o SVM, a história é silenciosa.
Primeiramente, examinamos as classes: na árvore de scripts, na amostra do modelo SVM, na amostra principal. E aqui está o que vemos:
- As classes do modelo SVM correspondem aproximadamente às ramificações dos scripts, mas de nenhuma maneira correspondem às classes de uma amostra grande.
- A árvore de scripts foi escrita em processos de negócios há um ano e está desatualizada quase inútil. O modelo SVM foi descontinuado.
- As duas maiores classes da grande amostra são Vendas (50%) e Outras (45%).
- Das cinco maiores turmas, três são tão gerais quanto as vendas.
- As 45 classes restantes contêm menos de 30 caixas de diálogo cada. I.e. não temos uma árvore de scripts, não há lista de classes nem marcação.
O que fazer nesses casos? Arregaçamos as mangas e fomos por conta própria obter classes e marcação a partir dos dados.
A primeira tentativa. Vamos tentar agrupar perguntas do usuário, ou seja, As primeiras mensagens do diálogo, exceto as saudações.
Nós verificamos. Vetorizamos réplicas contando 3 gramas. Abaixamos a dimensão para as dez primeiras medidas do TSVD. Agrupamos por agrupamento aglomerativo com a distância euclidiana e a função Ward alvo. Abaixe a dimensão novamente usando t-SNE (até duas medições para que você possa ver os resultados com os olhos). Desenhamos pontos de réplica no avião, pintando nas cores dos aglomerados.
Resultado: medo e horror. Sane clusters, podemos assumir que não há:
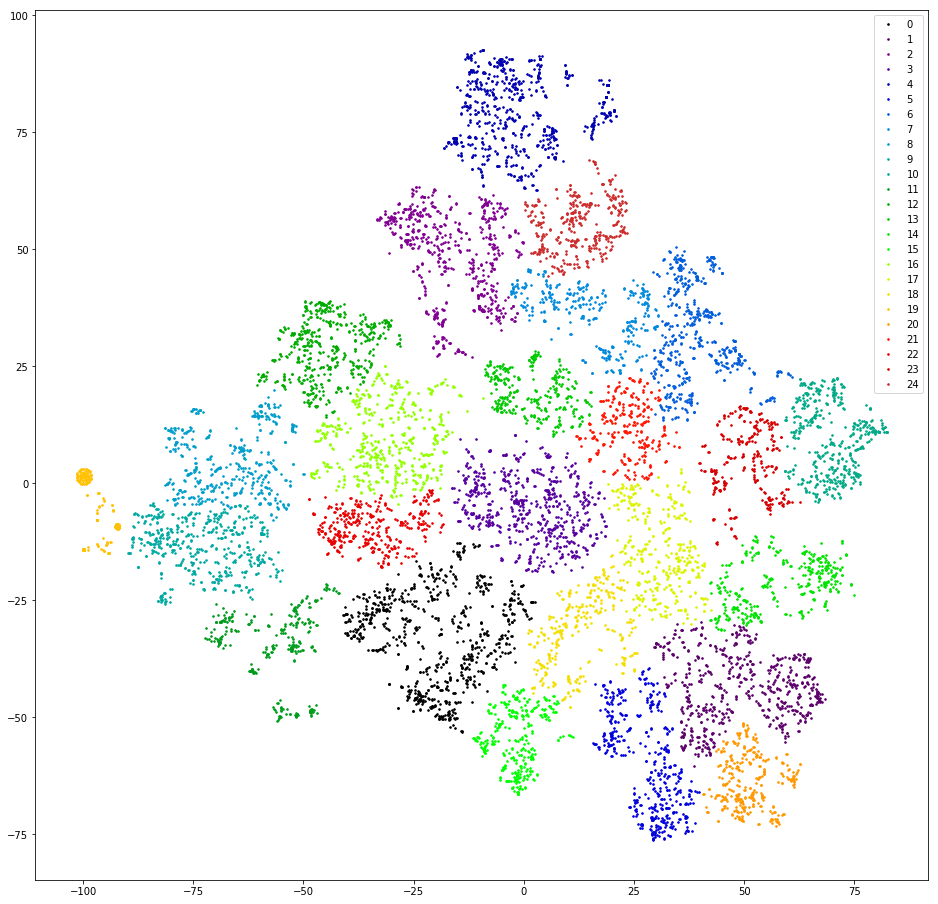
Quase não - há uma laranja à esquerda, porque todas as mensagens nela contêm o "@" de 3 gramas. Esses 3 gramas são um artefato de pré-processamento. Em algum lugar no processo de filtragem de sinais de pontuação, "@" não só não foi filtrado, mas também cheio de espaços. Mas o artefato é útil. Este cluster inclui usuários que primeiro escrevem seus emails. Infelizmente, somente pela disponibilidade de e-mail, não é totalmente claro qual é a solicitação do usuário. Nós seguimos em frente.
A segunda tentativa. E se os operadores frequentemente responderem com mais ou menos links padrão?
Nós verificamos. Extraímos substrings semelhantes a links das mensagens do operador, editamos levemente os links, com ortografia diferente, mas com o mesmo significado (http / https, / search? City =% city%), considere as frequências do link.
Resultado: pouco promissor. Primeiro, os operadores respondem apenas a uma pequena fração das solicitações (<10%) com links. Em segundo lugar, mesmo após a limpeza e filtragem manual dos links que ocorreram uma vez, existem mais de trinta deles. Em terceiro lugar, no comportamento dos usuários que encerram o diálogo com um link, não há semelhança específica.
A terceira tentativa. Vamos procurar as respostas padrão dos operadores - e se eles forem indicadores de qualquer classificação de mensagens?
Nós verificamos. Em cada diálogo, pegamos a última réplica do operador (além das despedidas: "Eu posso ajudar outra coisa", etc.) e consideramos a frequência das réplicas exclusivas.
Resultado: promissor, mas inconveniente. 50% das respostas do operador são únicas, outros 10 a 20% são encontrados duas vezes, os 30 a 40% restantes são cobertos por um número relativamente pequeno de modelos populares. Relativamente pequeno - cerca de trezentos. Um exame mais atento desses modelos revela que muitos deles são variantes da mesma resposta em termos de significado - diferem onde por uma letra, onde por uma palavra, onde por um parágrafo. Eu gostaria de agrupar essas respostas que têm significado próximo.
A quarta tentativa. Agrupando as réplicas mais recentes de instruções. Estes são agrupados muito melhor:
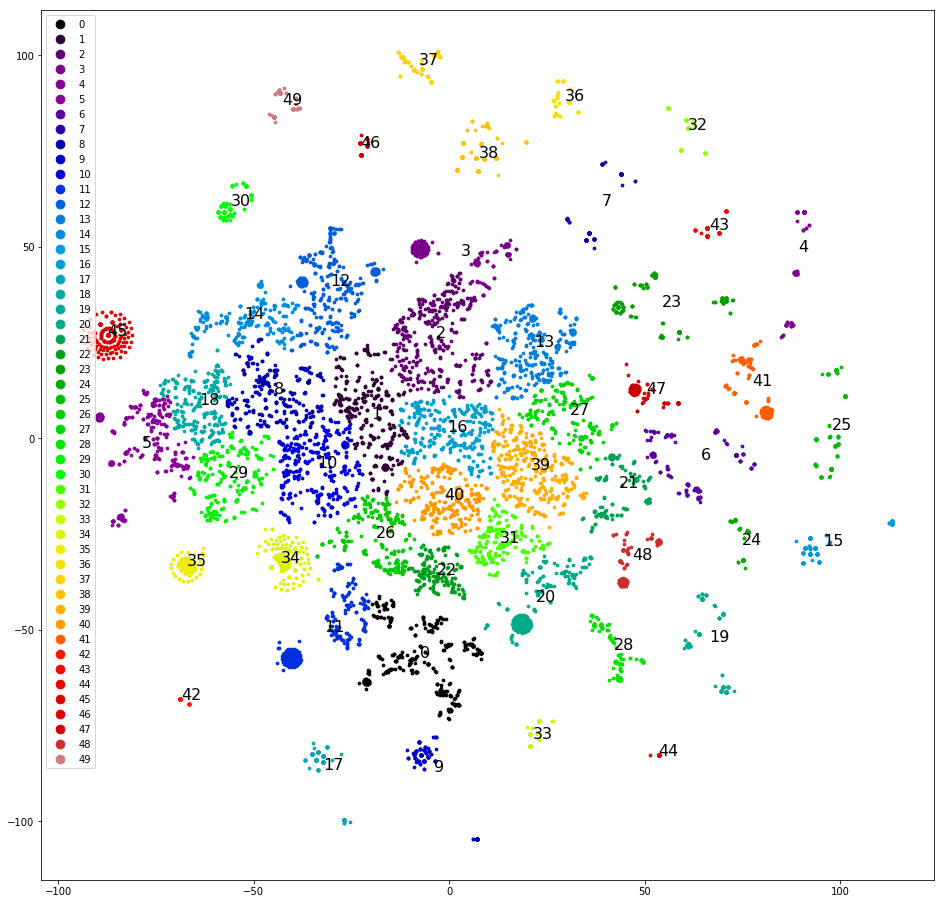
Você já pode trabalhar com isso.
Agrupamos e desenhamos réplicas no plano, como na primeira tentativa, determinamos manualmente os clusters mais claramente separados, os removemos do conjunto de dados e agrupamos novamente. Depois de separar cerca da metade do conjunto de dados, os clusters claros terminam e começamos a pensar em quais classes atribuir a eles. Nós dispersamos os clusters de acordo com as cinco classes originais - a amostra é "inclinada" e três das cinco classes originais não recebem um único cluster. Que pena. Nós dispersamos os clusters em cinco classes, que designamos aleatoriamente: "ligar", "vir", "esperar um dia por uma resposta", "problemas com captcha", "outros". A inclinação é menor, mas a precisão é de apenas 0,4-0,5. Ruim de novo. Atribua a cada um dos mais de 30 clusters sua própria classe. A amostra é novamente inclinada e a precisão é novamente 0,5, embora cerca de cinco classes selecionadas tenham precisão e integridade decentes (0,8 e superior). Mas o resultado ainda não é impressionante.
A quinta tentativa. Precisamos de todos os meandros do cluster. Recuperamos o dendrograma de cluster completo em vez dos trinta principais clusters. Nós o salvamos em um formato acessível aos analistas de clientes e os ajudamos a fazer a marcação - esboçamos a lista de classes.
Para cada mensagem, calculamos uma cadeia de clusters, que inclui cada mensagem, começando pela raiz. Construímos uma tabela com colunas: texto, identificação do primeiro cluster da cadeia, identificação do segundo cluster da cadeia, ..., identificação do cluster correspondente ao texto. Salvamos a tabela em csv / xls. Além disso, você pode trabalhar com ferramentas de escritório.
Fornecemos os dados e um esboço da lista de classes para marcação ao cliente. Os analistas de clientes remarcaram ~ 10.000 primeiras mensagens do usuário. Nós, já ensinados por experiência, pedimos para marcar cada mensagem pelo menos duas vezes. E não em vão - 4.000 desses 10.000 precisam ser jogados fora, porque os dois analistas se diferenciaram. Nos 6.000 restantes, repetimos rapidamente os sucessos do primeiro projeto:
- Linha de base: sem filtragem - precisão 0,66.
- Combinamos as classes iguais do ponto de vista do operador. Temos uma precisão de 0,73.
- Removemos a classe "Outros" - a precisão aumenta para 0,79.
O modelo está pronto, agora você precisa desenhar uma árvore de scripts. Por motivos que não podemos explicar, não tivemos acesso a scripts para respostas do operador. Não ficamos surpresos, fingimos ser usuários e, por algumas horas em campo, coletamos modelos de resposta e esclarecemos perguntas do operador para todas as ocasiões. Eles os decoraram em uma árvore, os embalaram em um bot e foram testar. Aprovado pelo cliente.
Conclusões ou que experiência demonstrou:
- Você pode experimentar partes do modelo (pré-processamento, vetorização, classificação etc.) individualmente.
- O XGBoost ainda domina a bola, embora, se você precisar de algo incomum, tenha problemas.
- O usuário é um dispositivo periférico de entrada caótica, portanto, você precisa limpar os dados do usuário.
- O enriquecimento iterativo é legal, embora perigoso.
- Às vezes, vale a pena devolver os dados ao cliente para marcação. Mas não se esqueça de ajudá-lo a obter um resultado de qualidade.
A ser concluído.