A maioria dos sistemas de armazenamento disponíveis no mercado não é muito diferente um do outro, porque muitos fornecedores solicitam equipamentos dos quase fabricantes dos mesmos ODM. Temos quase tudo, desde o chassi até os controladores, tecnologias como RAID 2.0+ e software.

Sob o corte, há alguns detalhes sobre o que pode ser tão incomum em cada um dos nós do sistema de armazenamento de dados.
O que é interessante no nível do módulo
Estruturalmente, todos os sistemas modernos de armazenamento de qualquer fabricante têm a mesma aparência: os controladores são instalados na parte frontal do chassi da caixa de aço e os módulos de interface na parte traseira. Há também fontes de alimentação e ventilação. Parece que tudo é familiar e padrão. Mas, de fato, introduzimos muitas coisas interessantes nesse paradigma.
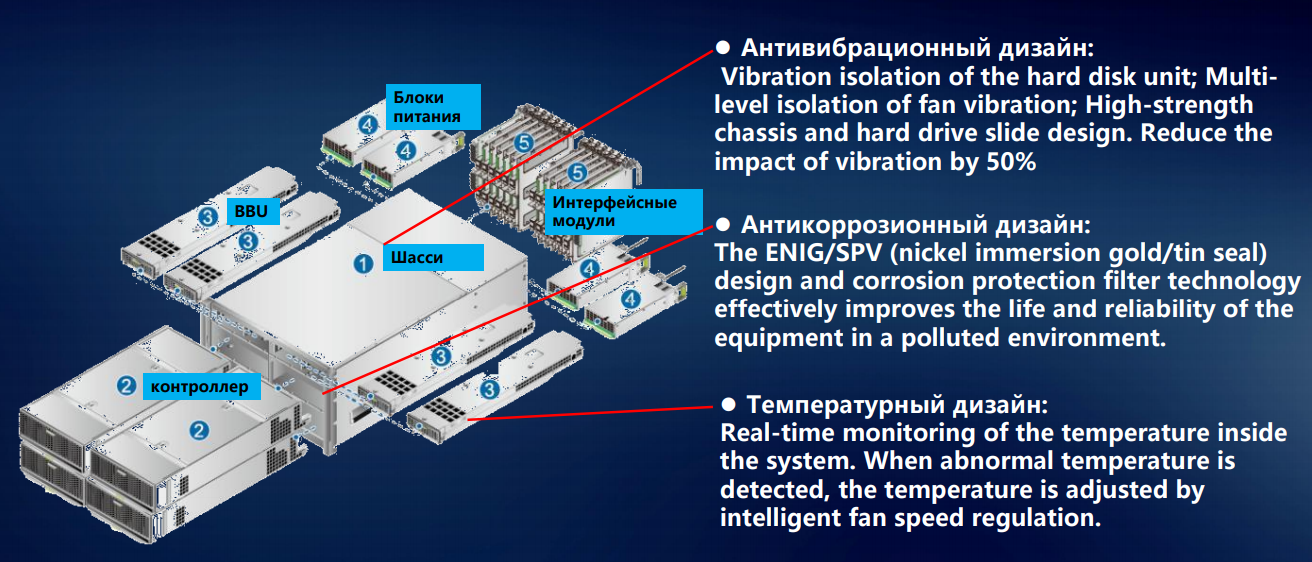
Vamos começar montando os elementos do sistema de armazenamento no chassi. Existem menos unidades magnéticas de 3,5 polegadas no sistema de armazenamento; sistemas híbridos e all-flash estão começando a dominar. Mas mesmo várias unidades de disco com uma velocidade de rotação de até 15 mil rotações por minuto criam uma vibração que não pode ser ignorada. Desenvolvemos um conjunto de recomendações para este caso - como distribuir unidades magnéticas com vários parâmetros entre prateleiras de discos.
Mesmo em uma fração de um por cento, mas isso afeta a confiabilidade. E na escala de um grande data center, as porcentagens por unidade se transformam em indicadores tangíveis de falhas e mau funcionamento. Para garantir que a vibração de discos individuais seja menos transmitida através da estrutura rígida do chassi, equipamos os discos embaixo dos discos com amortecedores de borracha ou metal. Para neutralizar outra fonte de vibração no sistema de armazenamento - módulos de ventilação - colocamos ventiladores bidirecionais e isolamos todos os elementos rotativos do chassi.
Para acionamentos de eixos, agitação mínima já é um problema: as cabeças começam a se perder, o desempenho cai significativamente. SSDs são outra questão; eles não têm medo de vibrações. Mas a fixação segura de componentes ainda é importante. Faça o processo de entrega: a caixa pode ser derrubada ou jogada casualmente, colocada de lado ou de cabeça para baixo. Portanto, todos os componentes do sistema de armazenamento são fixados estritamente em três dimensões. Isso elimina a possibilidade de deslocamento durante o transporte, protege os conectores de saltarem dos soquetes em caso de impacto acidental.

Era uma vez, começamos com o desenvolvimento de tecnologia de computadores para a indústria de telecomunicações, onde os padrões de operabilidade em temperatura e umidade são tradicionalmente altos. E as mudamos para outras direções: as partes metálicas dos sistemas de armazenamento não oxidam mesmo com alta umidade - devido ao uso de niquelagem e galvanização.
O design térmico de nossos sistemas de armazenamento foi desenvolvido com ênfase na distribuição uniforme de temperatura pelo chassi - para evitar superaquecimento ou resfriamento excessivo de qualquer canto da prateleira do disco. Caso contrário, a deformação física não pode ser evitada - mesmo que insignificante, mas ainda assim violando a geometria e capaz de reduzir a vida útil do equipamento. Assim, algumas frações de um por cento são obtidas, mas isso ainda afeta a confiabilidade geral do sistema.
Sutilezas de semicondutores
Duplicamos componentes importantes dos sistemas de armazenamento: se algo falhar, sempre haverá uma rede de segurança. Por exemplo, os módulos de energia para modelos mais novos funcionam de acordo com o esquema 1 + 1, para os mais sólidos - 2 + 1 e até 3 + 1.

Controladores, dos quais existem pelo menos dois no sistema de armazenamento (não fornecemos sistemas de controlador único) também são reservados. No sistema de armazenamento das séries 6800 e anteriores, a redundância é realizada de acordo com o esquema 3 + 1, nos modelos mais novos - 1 + 1.
Até um conselho de administração é reservado, o que não afeta diretamente a operação do sistema, mas é necessário apenas para alterações e monitoramento de configuração. Além disso, qualquer placa de expansão de interface para sistemas de armazenamento é vendida apenas em pares, para que o cliente tenha uma reserva.
Todos os componentes - PSUs, ventiladores, controladores, módulos de gerenciamento, etc. - equipado com microcontroladores capazes de responder a determinadas situações. Por exemplo, se o ventilador começar a desacelerar sozinho, um alarme será enviado ao módulo de controle. Como resultado, o cliente tem uma imagem completa do estado do sistema de armazenamento - e, se necessário, pode substituir alguns componentes por conta própria, sem aguardar a chegada de nosso engenheiro de serviço. E se a política de segurança do cliente permitir, configuramos os controladores para que eles transmitam informações sobre o estado do ferro ao nosso suporte técnico.
Seus chips são melhores e mais compreensíveis.
Somos a única empresa que desenvolve seus próprios processadores, chips e controladores de unidade de estado sólido para seus sistemas de armazenamento.

Portanto, em alguns modelos, como processador principal do sistema de armazenamento (Storage Controller Chip), usamos não o clássico Intel x86, mas o processador ARM HiSilicon, nossa subsidiária. O fato é que a arquitetura ARM no armazenamento - para calcular o mesmo RAID e desduplicação - se mostra melhor que o x86 padrão.
Nosso orgulho especial são os chips para controladores SSD. E se nossos servidores puderem ser equipados com unidades de semicondutores de terceiros (Intel, Samsung, Toshiba etc.), nos sistemas de armazenamento de dados instalaremos apenas SSDs de nosso próprio projeto.

O microcontrolador do módulo de entrada / saída (chip de E / S inteligente) nos sistemas de armazenamento também é um desenvolvimento HiSilicon, assim como o chip de gerenciamento inteligente para gerenciamento de armazenamento remoto. Usar nossos próprios microchips nos ajuda a entender melhor o que está acontecendo a cada momento no tempo com cada célula de memória. Foi isso que nos permitiu minimizar os atrasos ao acessar dados nos mesmos sistemas de armazenamento Dorado.

Para discos magnéticos, o monitoramento contínuo é extremamente importante em termos de confiabilidade. Nossos sistemas de armazenamento oferecem suporte ao DHA (Disk Health Analyzer): o próprio disco registra continuamente o que está acontecendo com ele, o quão bem ele se sente. Graças ao acúmulo de estatísticas e à construção de modelos preditivos inteligentes, é possível prever a transição do inversor para um estado crítico em 2-3 meses, e não em 5-10 dias. O disco ainda está "ativo", os dados estão completamente seguros - mas o cliente está pronto para substituí-lo ao primeiro sinal de uma possível falha.
RAID 2.0 ou superior
Projeto à prova de falhas em sistemas de armazenamento que pensamos no nível do sistema. Nossa tecnologia Smart Matrix é um complemento sobre o PCIe - esse barramento, com base no qual as conexões entre controladores são implementadas, é especialmente adequado para SSDs.
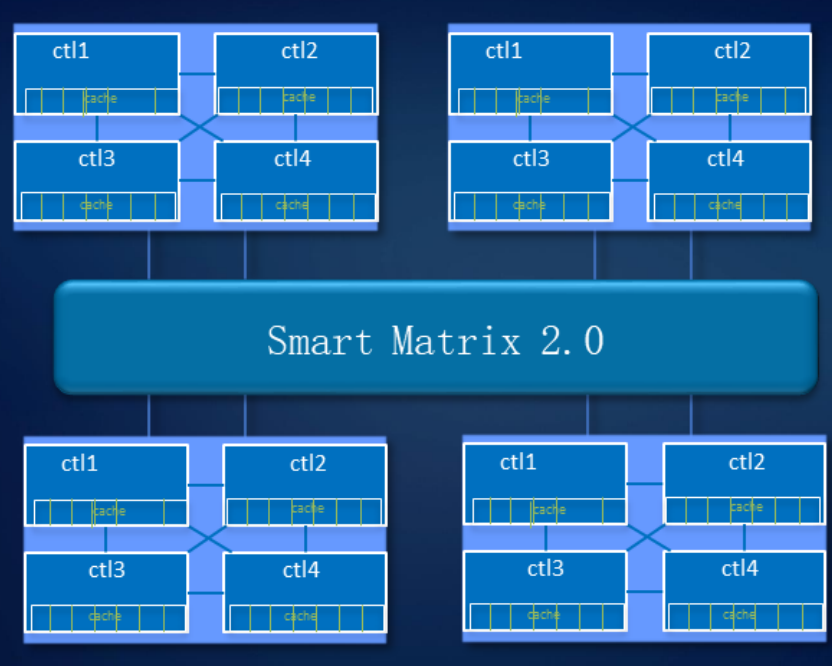
O Smart Matrix fornece, em particular, a malha completa de 4 controladores em nosso armazenamento Ocean Store 6800 v5. Para que cada controlador tenha acesso a todos os discos do sistema, desenvolvemos um back-end SAS especial. O cache, é claro, é espelhado entre todos os controladores ativos no momento.

Quando o controlador falha, os serviços dele mudam rapidamente para o controlador de espelho, e os controladores restantes restauram o relacionamento para espelhar um ao outro. Ao mesmo tempo, os dados gravados no cache têm uma reserva de espelhamento para garantir a confiabilidade do sistema.

O sistema suporta a falha de três controladores. Conforme mostrado na figura, se o controle A falhar, os dados do cache do controlador B selecionarão o controlador C ou D para espelhar o cache. Quando o controlador D falha, os controladores B e C espelham o cache.

O sistema de distribuição de dados RAID 2.0 é o padrão para nossos sistemas de armazenamento: a virtualização em nível de disco substituiu por muito tempo a cópia artless bloco a bloco de conteúdo de um meio para outro. Todos os discos são agrupados em blocos, eles são combinados em conglomerados maiores de uma estrutura de dois níveis e já acima do nível superior estão os volumes lógicos que compõem as matrizes RAID.

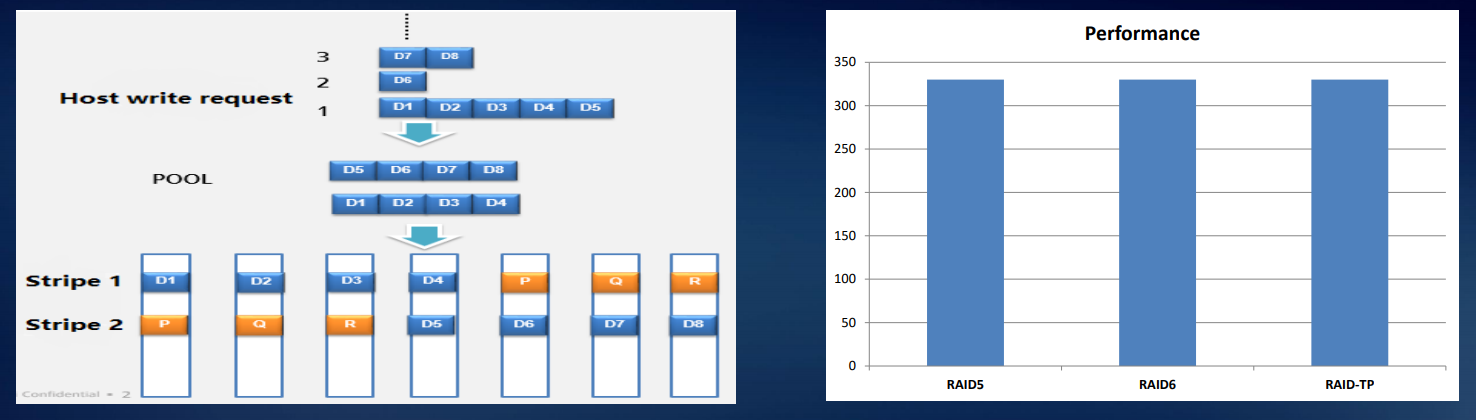
A principal vantagem dessa abordagem é o tempo de reconstrução reduzido da matriz. Além disso, no caso de uma falha no disco, a reconstrução é realizada não no disco sobressalente quente que esteve parado o tempo todo, mas no espaço livre em todos os discos usados. A figura abaixo mostra nove discos rígidos RAID5 como exemplo. Quando o disco rígido 1 falha, os dados CKG0 e CKG1 estão corrompidos. O sistema seleciona CK para reconstrução aleatoriamente.

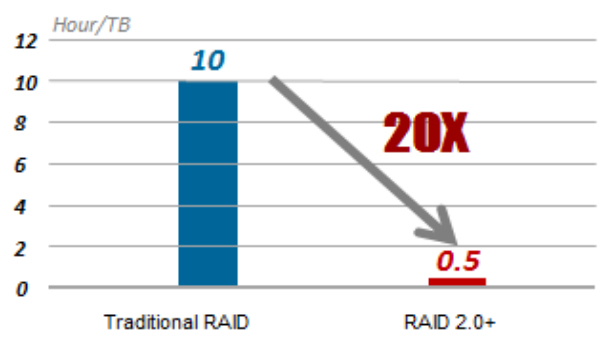
A velocidade normal de recuperação de RAID é de 30 MB / s, portanto, leva 10 horas para recuperar 1 TB de dados. O RAID 2.0+ reduz esse tempo para 30 minutos.
Nossos desenvolvedores conseguiram obter uma distribuição de carga uniforme entre todas as unidades de eixo e SSDs no sistema. Isso permite que você desbloqueie o potencial dos sistemas de armazenamento híbrido muito melhor do que o uso usual de unidades de estado sólido como cache.

Nos sistemas da classe Dorado, implementamos o chamado RAID-TP, um array com paridade tripla. Esse sistema continuará funcionando enquanto três unidades falharem. Isso aumenta a confiabilidade em comparação com o RAID 6 em duas ordens decimais, com o RAID 5 em três.
Recomendamos o RAID-TP para dados especialmente críticos, principalmente porque, devido ao RAID 2.0 e às unidades flash de alta velocidade, isso não afeta significativamente o desempenho. Você só precisa de mais espaço livre para reservar.

Como regra, os sistemas totalmente flash são usados para DBMSs com pequenos blocos de dados e IOPS alto. O último não é muito bom para SSDs: as células de memória NAND ficam rapidamente sem energia. Em nossa implementação, o sistema primeiro coleta um bloco de dados relativamente grande no cache da unidade e depois grava-o completamente nas células. Isso permite reduzir a carga nos discos e, em um modo mais poupador, "coleta de lixo" e liberar espaço no SSD.
Seis noves
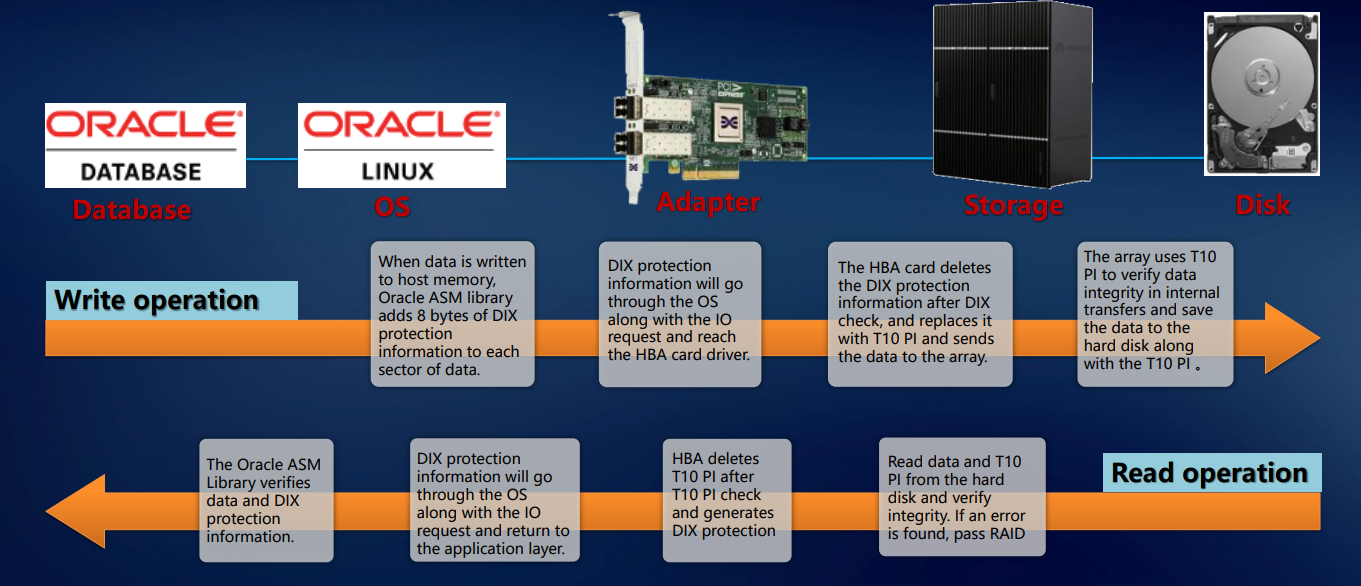
O exposto acima nos permite falar sobre a tolerância a falhas de nossos sistemas no nível de toda a solução. A validação é implementada no nível do aplicativo (por exemplo, Oracle DBMS), sistema operacional, adaptador, armazenamento - e assim por diante até o disco. Essa abordagem garante que exatamente o bloco de dados que chegou às portas externas seja gravado nos discos internos do sistema sem nenhum dano ou perda. Isso implica em um nível corporativo.
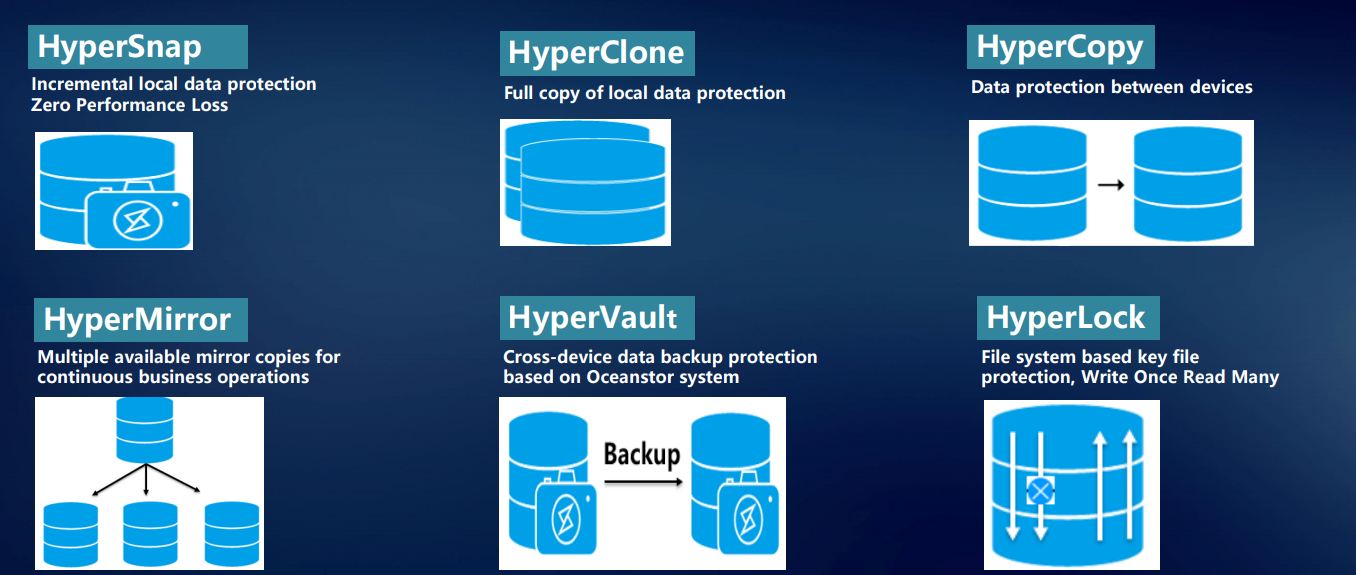
Para armazenamento, proteção e recuperação de dados confiáveis, bem como acesso rápido a eles, desenvolvemos diversas tecnologias proprietárias.

O HyperMetro é provavelmente o desenvolvimento mais interessante do ano e meio passado. Uma solução chave na mão, baseada em nossos sistemas de armazenamento para a construção de um cluster metropolitano à prova de falhas, está sendo implementada no nível do controlador; ela não requer gateways ou servidores adicionais, exceto o árbitro. É implementado simplesmente por uma licença: dois sistemas de armazenamento Huawei mais uma licença - e funciona.

A tecnologia HyperSnap fornece proteção contínua de dados sem perda de desempenho. O sistema suporta RoW. Para evitar a perda de dados no armazenamento a qualquer momento, muitas tecnologias são usadas: vários instantâneos, clones, cópias.
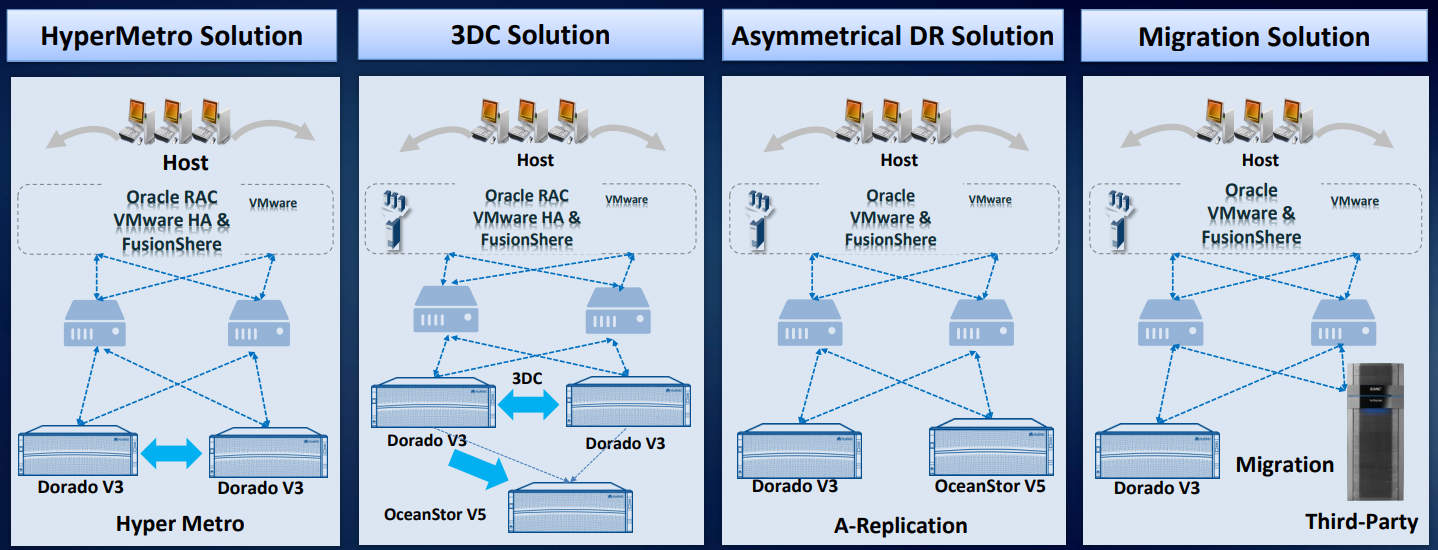
Com base em nossos sistemas de armazenamento, pelo menos quatro soluções de recuperação de desastres foram desenvolvidas e testadas na prática.
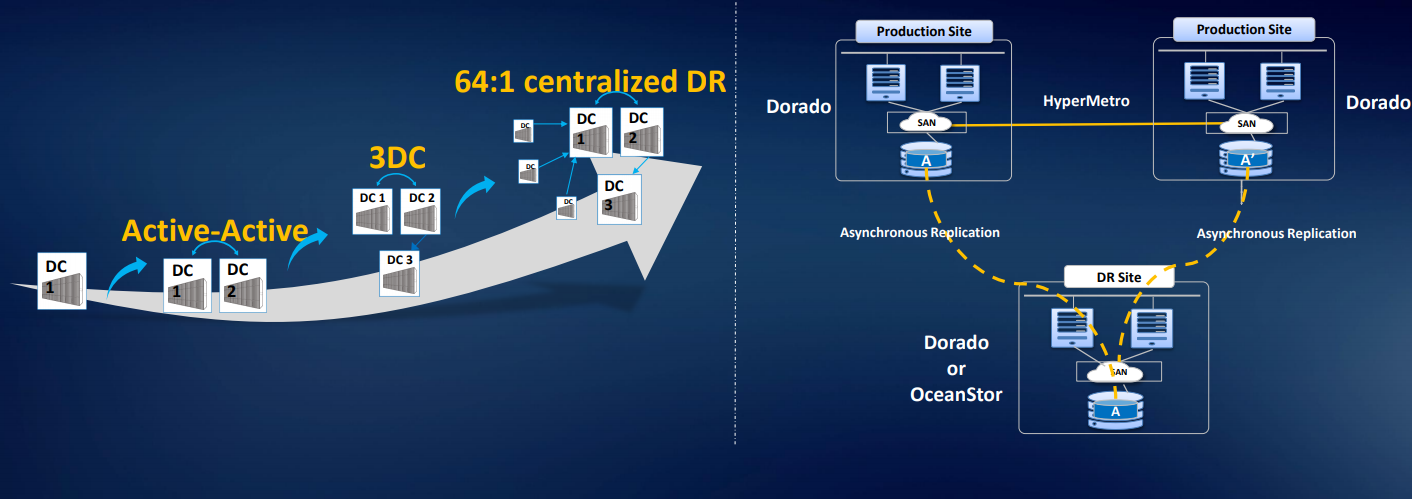
Também temos uma solução para três datacenters 3DC Ring DR Solution: dois datacenters no cluster e o terceiro está replicando. Podemos organizar a replicação assíncrona ou a migração de matrizes de terceiros. Há uma licença de virtualização inteligente, para que você possa usar volumes da maioria das matrizes padrão com acesso ao FC: Hitachi, DELL EMC, HPE, etc. A solução está realmente pronta, existem análogos no mercado, mas eles custam mais. Existem exemplos de uso na Rússia.
Como resultado, no nível de toda a solução, você pode obter a confiabilidade de seis noves e no nível do armazenamento local - cinco noves. Em geral, tentamos.
Postado por Vladimir Svinarenko, gerente sênior de soluções de TI da Huawei Enterprise na Rússia