
O tópico do artigo é bastante restrito, mas pode ser útil para aqueles que estão desenvolvendo seus próprios data warehouses e pensando em integração com o Spring Framework.
Antecedentes
Os desenvolvedores geralmente não gostam de mudar seus hábitos (geralmente, as estruturas também são incluídas na lista de hábitos). Quando comecei a trabalhar com o CUBA , não precisava aprender muitas coisas novas; era possível me envolver ativamente no trabalho do projeto quase que imediatamente. Mas havia uma coisa em que eu tinha que ficar mais tempo - estava trabalhando com dados.
O Spring possui várias bibliotecas que podem ser usadas para trabalhar com o banco de dados, uma das mais populares é o spring-data-jpa , que permite na maioria dos casos não gravar SQL ou JPQL. Você só precisa criar uma interface especial com métodos nomeados de uma maneira especial e o Spring gerará e fará o resto do trabalho para buscar dados no banco de dados e criar instâncias de objetos de entidade.
Abaixo está a interface, com um método para contar clientes com um sobrenome.
interface CustomerRepository extends CrudRepository<Customer, Long> { long countByLastName(String lastName); }
Essa interface pode ser usada diretamente nos serviços Spring sem criar nenhuma implementação, o que acelera bastante o trabalho.
O CUBA possui uma API para trabalhar com dados, que inclui várias funcionalidades, como entidades parcialmente carregadas ou um sistema de segurança complicado com controle de acesso aos atributos e linhas da entidade nas tabelas do banco de dados. Mas essa API é um pouco diferente do que os desenvolvedores estão acostumados no Spring Data ou no JPA / Hibernate.
Por que não há repositórios JPA no CUBA e posso adicioná-los?
Trabalhando com dados no CUBA
No CUBA, existem três classes principais responsáveis pelo trabalho com dados: DataStore, EntityManager e DataManager.
O DataStore é uma abstração de alto nível para qualquer armazenamento de dados: banco de dados, sistema de arquivos ou armazenamento em nuvem. Essa API permite executar operações básicas em dados. Na maioria dos casos, os desenvolvedores não precisam trabalhar diretamente com o DataStore, exceto no desenvolvimento de seu próprio repositório, ou se for necessário um acesso muito especial aos dados no repositório.
EntityManager é uma cópia do conhecido JPA EntityManager. Diferentemente da implementação padrão, ele possui métodos especiais para trabalhar com visualizações CUBA , para exclusão "lógica" (lógica) de dados, bem como para trabalhar com consultas no CUBA . Como no caso do DataStore, em 90% dos projetos, um desenvolvedor comum não precisará lidar com o EntityManager, exceto quando for necessário atender a algumas solicitações que ignoram o sistema de restrição de acesso a dados.
DataManager é a classe principal para trabalhar com dados no CUBA. Fornece uma API para manipulação de dados e suporta controle de acesso a dados, incluindo acesso a atributos e restrições em nível de linha. O DataManager modifica implicitamente todas as consultas executadas no CUBA. Por exemplo, ele pode excluir os campos da tabela aos quais o usuário atual não tem acesso a partir da instrução select e adicionar condições para excluir as linhas da tabela da seleção. E isso facilita a vida dos desenvolvedores, porque você não precisa pensar em como escrever consultas corretamente, considerando os direitos de acesso, o CUBA faz isso automaticamente com base nos dados das tabelas de serviço de banco de dados.
Abaixo está um diagrama da interação dos componentes CUBA envolvidos na busca de dados por meio do DataManager.
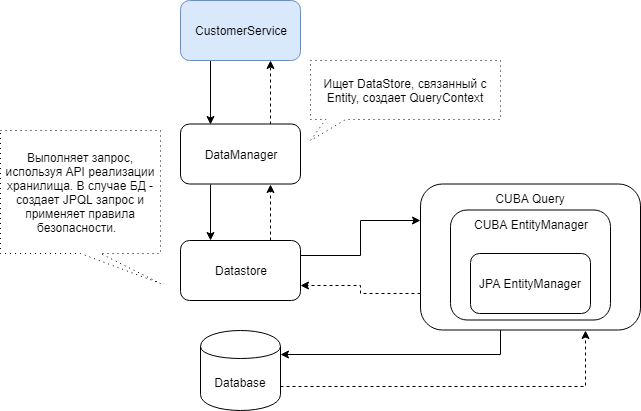
Usando o DataManager, você pode carregar de maneira relativamente fácil entidades e hierarquias inteiras de entidades usando as visualizações CUBA. Em sua forma mais simples, a consulta se parece com isso:
dataManager.load(Customer.class).list();
Como já mencionado, o DataManager filtrará os registros “excluídos logicamente”, removerá os atributos proibidos da solicitação e também abrirá e fechará a transação automaticamente.
Mas, quando se trata de consultas mais complicadas, você precisa escrever o JPQL no CUBA.
Por exemplo, se você precisar contar clientes com um sobrenome, como no exemplo da seção anterior, precisará escrever algo como este código:
public Long countByLastName(String lastName) { return dataManager .loadValue("select count(c) from sample$Customer c where c.lastName = :lastName", Long.class) .parameter("lastName", lastName) .one(); }
ou tal:
public Long countByLastName(String lastName) { LoadContext<Customer> loadContext = LoadContext.create(Customer.class); loadContext .setQueryString("select c from sample$Customer c where c.lastName = :lastName") .setParameter("lastName", lastName); return dataManager.getCount(loadContext); }
Na API CUBA, você precisa passar uma expressão JPQL como uma string (a API de Critérios ainda não é suportada), essa é uma maneira legível e compreensível de criar consultas, mas a depuração dessas consultas pode trazer muitos minutos divertidos. Além disso, as seqüências de caracteres JPQL não são verificadas pelo compilador nem pelo Spring Framework durante a inicialização do contêiner, o que leva a erros apenas no tempo de execução.
Compare isso com o Spring JPA:
interface CustomerRepository extends CrudRepository<Customer, Long> { long countByLastName(String lastName); }
O código é três vezes mais curto e sem linhas. Além disso, o nome do método countByLastName verificado durante a inicialização do contêiner Spring. Se houver um erro de digitação e você escreveu countByLastNsme , o aplicativo countByLastNsme com um erro durante a implantação:
Caused by: org.springframework.data.mapping.PropertyReferenceException: No property LastNsme found for type Customer!
O CUBA é construído em torno do Spring Framework, para que você possa usar a biblioteca spring-data-jpa em um aplicativo escrito usando o CUBA, mas há um pequeno problema - o controle de acesso. A implementação do Spring CrudRepository usa seu EntityManager. Assim, todas as consultas serão realizadas ignorando o DataManager. Portanto, para usar repositórios JPA no CUBA, é necessário substituir todas as chamadas do EntityManager pelas chamadas do DataManager e adicionar suporte às visualizações do CUBA.
Alguém pode dizer que o spring-data-jpa é uma caixa preta não controlada e é sempre preferível escrever JPQL puro ou mesmo SQL. Esse é o eterno problema do equilíbrio entre conveniência e nível de abstração. Todo mundo escolhe o método que prefere, mas ter uma maneira adicional de trabalhar com dados no arsenal nunca será prejudicial. E para aqueles que precisam de mais controle, o Spring tem uma maneira de definir sua própria solicitação de métodos de repositório JPA.
Implementação
Os repositórios JPA são implementados como um módulo CUBA usando a biblioteca spring-data-commons . Abandonamos a ideia de modificar o spring-data-jpa, porque a quantidade de trabalho seria muito mais comparada à escrita do nosso próprio gerador de consultas. Especialmente porque o spring-data-commons faz a maior parte do trabalho. Por exemplo, a análise de um nome de método e a associação de um nome a classes e propriedades são feitas completamente nesta biblioteca. O Spring-data-commons contém todas as classes base necessárias para implementar seus próprios repositórios e não é preciso muito esforço para implementá-lo. Por exemplo, essa biblioteca é usada no spring-data-mongodb .
O mais difícil foi implementar com precisão a geração JPQL com base em uma hierarquia de objetos - o resultado da análise do nome do método. Felizmente, porém, uma tarefa semelhante já foi implementada no Apache Ignite, portanto o código foi retirado de lá e adaptado um pouco para gerar JPQL em vez de SQL e oferecer suporte ao operador de delete .
O Spring-data-commons usa proxy para criar dinamicamente implementações de interface. Quando o contexto do aplicativo CUBA é inicializado, todos os links para interfaces são substituídos por links para caixas de proxy publicadas no contexto. Quando o método da interface é chamado, é interceptado pelo objeto proxy correspondente. Em seguida, esse objeto gera uma consulta JPQL pelo nome do método, substitui os parâmetros e envia a consulta com parâmetros ao DataManager para execução. O diagrama a seguir mostra um processo simplificado de interação entre os principais componentes do módulo.

Usando repositórios no CUBA
Para usar repositórios no CUBA, basta conectar o módulo no arquivo de construção do projeto:
appComponent("com.haulmont.addons.cuba.jpa.repositories:cuba-jpa-repositories-global:0.1-SNAPSHOT")
Você pode usar a configuração XML para "ativar" os repositórios:
<?xml version="1.0" encoding="UTF-8"?> <beans:beans xmlns:beans="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:repositories="http://www.cuba-platform.org/schema/data/jpa" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd http://www.cuba-platform.org/schema/data/jpa http://www.cuba-platform.org/schema/data/jpa/cuba-repositories.xsd"> <context:component-scan base-package="com.company.sample"/> <repositories:repositories base-package="com.company.sample.core.repositories"/> </beans:beans>
E você pode usar as anotações:
@Configuration @EnableCubaRepositories public class AppConfig {
Após a ativação do suporte de repositórios, você pode criá-los da forma usual, por exemplo:
public interface CustomerRepository extends CubaJpaRepository<Customer, UUID> { long countByLastName(String lastName); List<Customer> findByNameIsIn(List<String> names); @CubaView("_minimal") @JpqlQuery("select c from sample$Customer c where c.name like concat(:name, '%')") List<Customer> findByNameStartingWith(String name); }
Para cada método, você pode usar anotações:
@CubaView - para definir a visualização CUBA a ser usada no DataManager@JpqlQuery - para especificar a consulta JPQL que será executada, independentemente do nome do método.
Este módulo é usado no módulo global da estrutura CUBA, portanto, os repositórios podem ser usados no módulo core e na web . A única coisa que você precisa lembrar é ativar os repositórios nos arquivos de configuração dos dois módulos.
Um exemplo de uso do repositório no serviço CUBA:
@Service(CustomerService.NAME) public class CustomerServiceBean implements PersonService { @Inject private CustomerRepository customerRepository; @Override public List<Date> getCustomersBirthDatesByLastName(String name) { return customerRepository.findByNameStartingWith(name) .stream().map(Customer::getBirthDate).collect(Collectors.toList()); } }
Conclusão
CUBA é uma estrutura flexível. Se você deseja adicionar algo a ele, não há necessidade de consertar o kernel você mesmo ou esperar por uma nova versão. Espero que este módulo torne o desenvolvimento do CUBA mais eficiente e rápido. A primeira versão do módulo está disponível no GitHub , testada no CUBA versão 6.10