Muitos suspeitam da possibilidade de criar e escrever algo por conta própria. Muitas vezes, o preço é muito alto. É especialmente estranho ouvir sobre seus próprios JDKs, que supostamente estão em todas as empresas razoavelmente grandes. O que diabos está acontecendo com a gordura? Este artigo será uma história detalhada sobre a empresa, que tudo isso traz benefícios comerciais reais e que fez um péssimo trabalho, porque eles:
- Desenvolvi uma máquina Java virtual com vários inquilinos;
- Eles criaram um mecanismo para a operação de objetos que não sobrecarregam a coleta de lixo;
- Eles fizeram algo como o homólogo ReadyNow da Azul Zing;
- Eles lavaram suas próprias corotinas com rendimentos e continuações (e estão prontos para compartilhar sua experiência com Loom, sobre a qual escrevi no outono );
- Eles aparafusaram a todos esses milagres seu próprio subsistema de diagnóstico.
Como sempre, vídeo, descriptografia de texto completo e slides estão esperando por você. Bem-vindo ao inferno de uma das áreas mais difíceis de adaptação de projetos abertos!

Doutor, onde você tira essas fotos? O'Reilly Covers Corner: Os antecedentes do KDPV são fornecidos por Joshua Newton e retratam a Dança Sagrada de Sangyang Jaran em Ubud, Indonésia. Esta é uma performance clássica de Bali composta por dança de fogo e transe. Um homem de salto nu se move em volta de uma fogueira, criado com cascas de coco, empurrando as coisas com os pés e dançando em estado de transe, sob a influência de um espírito de cavalo. Ilustração perfeita para o seu próprio JDK, certo?
Slides e uma descrição do relatório (você não precisa deles, esse habratopike tem tudo que você precisa).
Olá, meu nome é Sanhong Lee, trabalho no Alibaba e gostaria de falar sobre as mudanças que fizemos no OpenJDK para as necessidades de nossos negócios. A postagem consiste em três partes. No primeiro, vou falar sobre como o Java é usado no Alibaba. A segunda parte, na minha opinião, é a mais importante - discutiremos como configuramos o OpenJDK para as necessidades de nossos negócios. A terceira parte será sobre as ferramentas que criamos para o diagnóstico.
Mas antes de passar para a primeira parte, gostaria de falar brevemente sobre a nossa empresa.
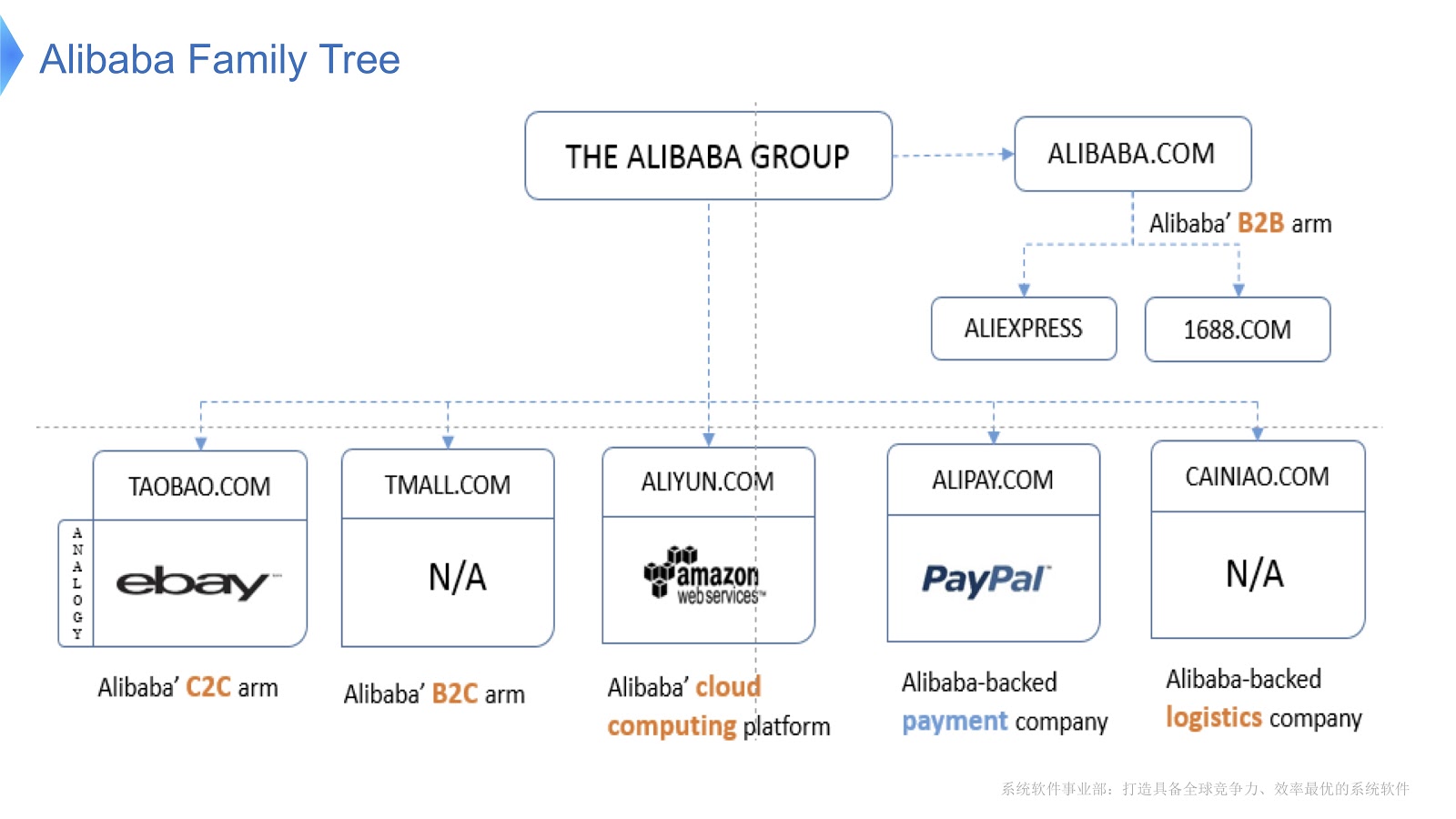
O diagrama mostra a estrutura interna do Alibaba. É composto por várias empresas cuja principal especialização é a organização do mercado eletrônico e o fornecimento de plataformas financeiras e logísticas. Acho que a maioria das pessoas na Rússia está familiarizada com o AliExpress. A Alibaba possui uma equipe dedicada de programadores que desenvolvem e dão suporte a toda a pilha distribuída, fornecendo serviços aos clientes da Aliexpress em todo o mundo.
Para ter uma idéia da escala do trabalho de Alibaba, vamos ver o que acontece na China no Dia do Solteiro . É comemorado todos os anos em 11 de novembro, e neste dia as pessoas compram especialmente muitos produtos através do Alibaba. Até onde eu sei, das férias em todo o mundo são as mais compras.
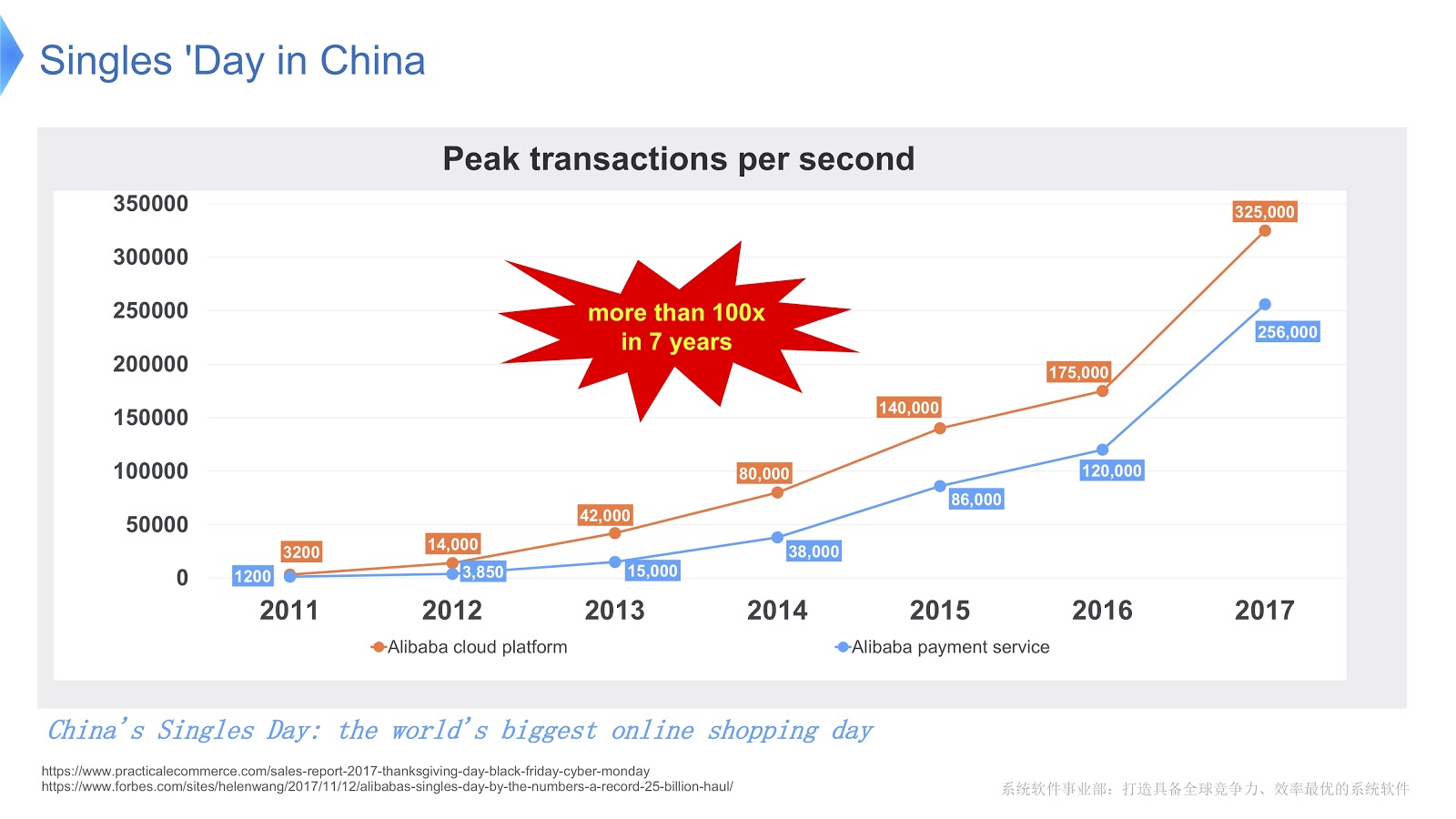
Na figura acima, você vê um diagrama que mostra a carga em nosso sistema de suporte. A linha vermelha mostra o trabalho do nosso serviço de pedidos e mostra o número máximo de transações por segundo, no ano passado foi de 325 mil. A linha azul refere-se ao serviço de pagamento, e ela tem esse número de 256 mil. Gostaria de falar sobre como otimizar a pilha que atende a tantas transações.
Vamos discutir as principais tecnologias que funcionam no Alibaba com Java. Antes de tudo, devo dizer que temos vários aplicativos de código aberto como base. Para processamento de big data, usamos o HBase Hadoop. Como contêiner, usamos o Tomcat e o OSGi. O Java é usado em uma escala colossal - milhões de instâncias da JVM são implementadas em nosso data center. Devo também dizer que nossa arquitetura é orientada a serviços, ou seja, criamos muitos serviços que se comunicam usando chamadas RPC. Finalmente, nossa arquitetura é heterogênea. Para melhorar o desempenho, muitos algoritmos são escritos usando as bibliotecas C e C ++, para que eles se comuniquem com Java usando chamadas JNI.

A história do nosso trabalho com o OpenJDK começou em 2011, durante o OpenJDK 6. Há três razões importantes pelas quais escolhemos o OpenJDK. Primeiro, podemos alterar diretamente seu código de acordo com as necessidades da empresa. Em segundo lugar, quando surgem problemas urgentes, podemos resolvê-los sozinhos mais rápido do que esperar pelo lançamento oficial. Isso é vital para os nossos negócios. Em terceiro lugar, nossos desenvolvedores Java usam nossas próprias ferramentas para depuração e diagnóstico rápidos e de alta qualidade.
Antes de passar para questões técnicas, quero listar as principais dificuldades que temos que superar. Primeiro, lançamos um grande número de instâncias da JVM - nessa situação, a questão de reduzir os custos de hardware é um problema grave. Em segundo lugar, eu já disse que atendemos a um grande número de transações. Graças ao coletor de lixo, o Java nos promete "memória infinita". Além disso, ele ganha em desempenho em um nível baixo, graças ao compilador JIT. Mas isso também tem um outro lado: um tempo mais longo para a coleta de lixo. Além disso, o Java precisa de ciclos adicionais de CPU para compilar os métodos Java. Isso significa que os compiladores competem pelos ciclos da CPU. Os dois problemas pioram à medida que o aplicativo se torna mais complexo.
A terceira dificuldade é que temos muitos aplicativos em execução. Acho que todos aqui estão familiarizados com as ferramentas que acompanham o OpenJDK, como JConsole ou VisualVM. O problema é que eles não nos fornecem as informações exatas que precisamos configurar. Além disso, quando usamos essas ferramentas (por exemplo, JConsole ou VisualVM) na produção, uma sobrecarga baixa não é apenas um desejo, mas um requisito necessário. Eu tive que escrever minhas próprias ferramentas de diagnóstico.

A imagem descreve as alterações que fizemos no OpenJDK. Vamos dar uma olhada em como superamos as dificuldades de que falei acima.
JVM com vários inquilinos
Uma solução que chamamos de JVM com vários inquilinos. Ele permite executar com segurança vários aplicativos da Web em um contêiner. Outra solução é chamada GCIH (GC Invisible Heap). Este é um mecanismo que fornece objetos Java completos, que ao mesmo tempo não exigem o custo da coleta de lixo. Além disso, para reduzir os custos dos contextos de encadeamento, implementamos corotinas em nossa plataforma Java. Além disso, escrevemos um mecanismo chamado JWarmup - sua função é muito semelhante ao ReadyNow. Douglas Hawkins parece ter mencionado ele em seu relatório . Por fim, desenvolvemos nossa própria ferramenta de criação de perfil, o ZProfiler.
Vamos dar uma olhada em como implementamos a multilocação baseada no OpenJDK.
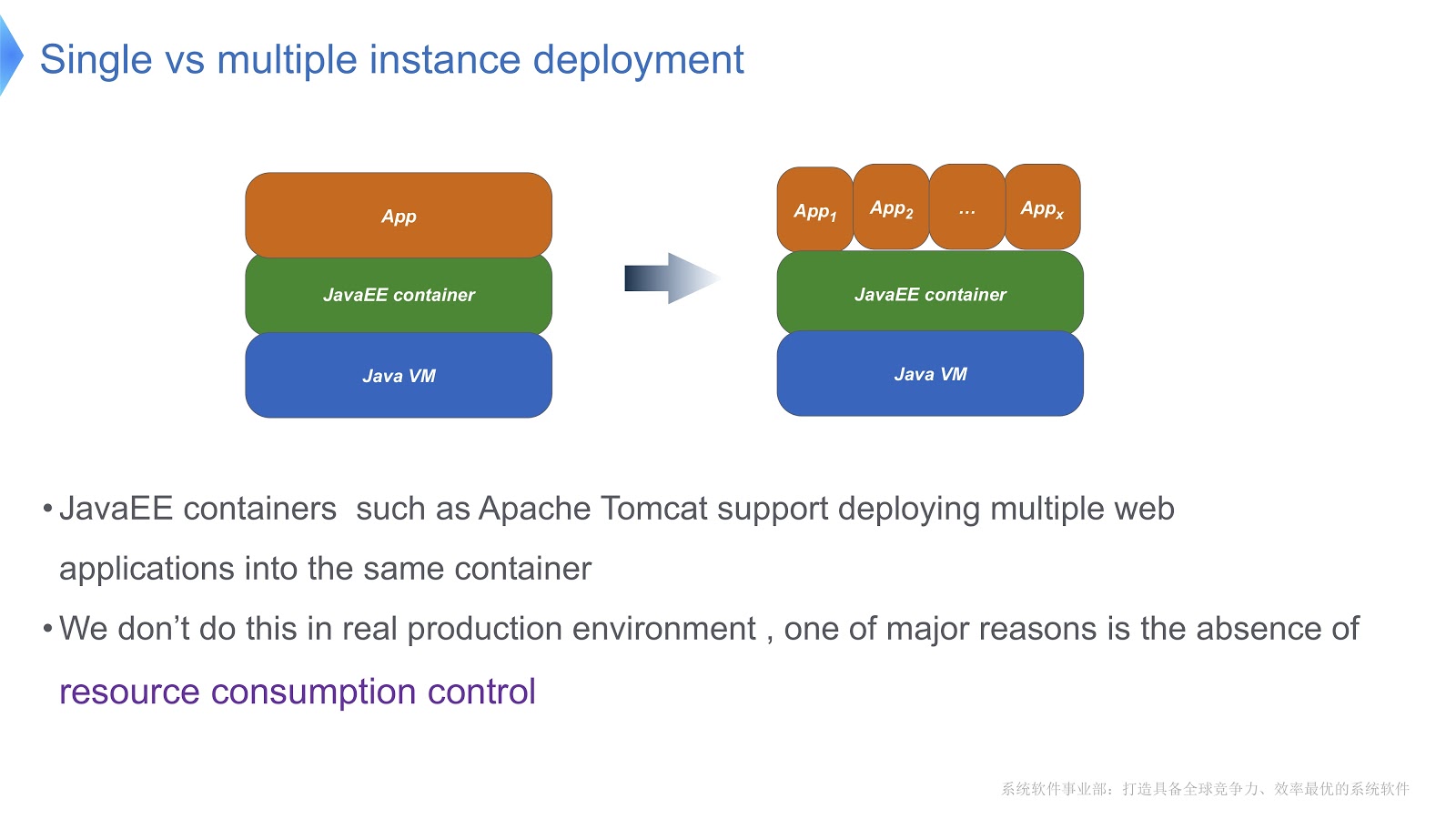
Dê uma olhada na foto acima - acho que a maioria de vocês conhece esse padrão. Compare a abordagem tradicional com o multilocatário. Se seu aplicativo estiver em execução usando o Apache Tomcat, você também poderá executar várias instâncias no mesmo contêiner. Mas o Tomcat não fornece consumo estável de recursos para cada um deles. Digamos, se um dos aplicativos em execução precisar de mais tempo de CPU que o outro, como você controlará a alocação de tempo de CPU? Como garantir que esse aplicativo não afete o trabalho de outras pessoas? Foi principalmente essa questão que nos levou a usar a tecnologia multitenant.
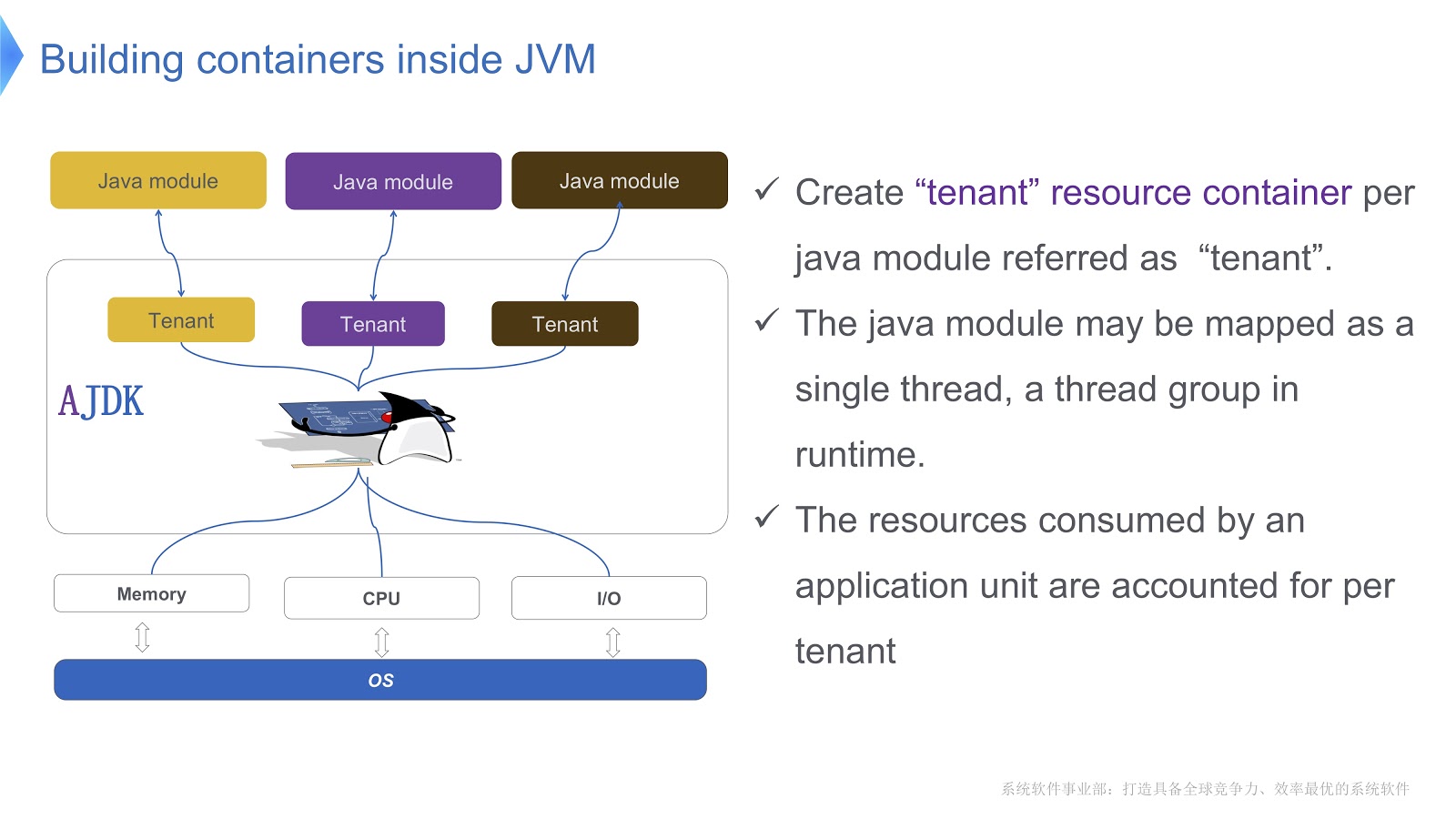
A imagem mostra esquematicamente como a implementamos. Criamos vários contêineres para inquilinos dentro da JVM. Cada um desses contêineres fornece controle confiável de consumo de recursos para cada módulo Java. Vários módulos podem ser implantados em um contêiner. Cada módulo pode ser associado a um thread ou a um grupo de threads em tempo de execução.
Vamos dar uma olhada na aparência da API do contêiner de inquilino. Temos uma classe de configuração de inquilino que armazena informações sobre o consumo de recursos. Em seguida, há uma classe do próprio contêiner.
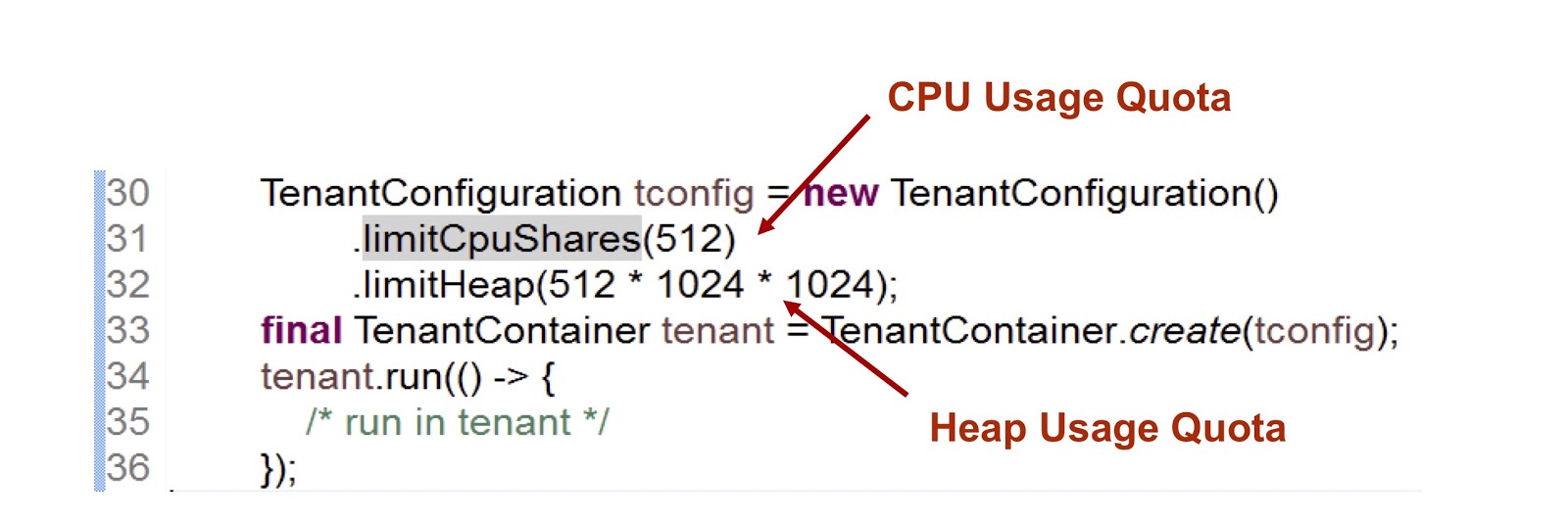
No trecho de código apresentado, criamos um inquilino e depois indicamos quanto tempo a CPU e a memória são fornecidas para ele. O primeiro indicador é um número inteiro, o que significa a parcela do tempo de CPU disponível para o inquilino, neste caso, indicamos 512. Utilizamos uma abordagem muito semelhante no caso de cgroups, abordarei isso com mais detalhes. A segunda métrica é o tamanho máximo de heap que os inquilinos podem usar.
Considere como um inquilino interage com um encadeamento. A classe TenantContainer fornece o método .run() e, quando um thread o insere, ele é anexado automaticamente ao inquilino e, quando sai, o procedimento inverso ocorre. Portanto, todo o código é executado dentro do método .run() . Além disso, qualquer encadeamento criado dentro do método .run() é anexado ao inquilino do encadeamento pai.
Chegamos a uma pergunta muito importante - como a CPU é gerenciada em uma JVM com vários inquilinos? Nossa solução acaba de ser implementada na plataforma Linux x64. Existe um mecanismo de grupo de controle, cgroups. Ele permite que você selecione um processo em um grupo separado e indique seu modo de consumo de recursos para cada grupo. Vamos tentar transferir essa abordagem para o contexto da JVM do Hotspot. No Hotstpot, os encadeamentos Java são organizados como encadeamentos nativos.

Isso é mostrado no diagrama acima: cada encadeamento Java está em uma correspondência individual com o encadeamento nativo. Em nosso exemplo, temos um contêiner TenantA , no qual existem dois threads nativos. Para poder controlar a distribuição do tempo da CPU, colocamos os dois threads nativos em um grupo de controle. Por esse motivo, podemos regular o consumo de recursos, contando apenas com a funcionalidade de [grupos de controle] ( https://en.wikipedia.org/wiki/Cgroups ).
Vamos dar uma olhada em um exemplo mais detalhado.
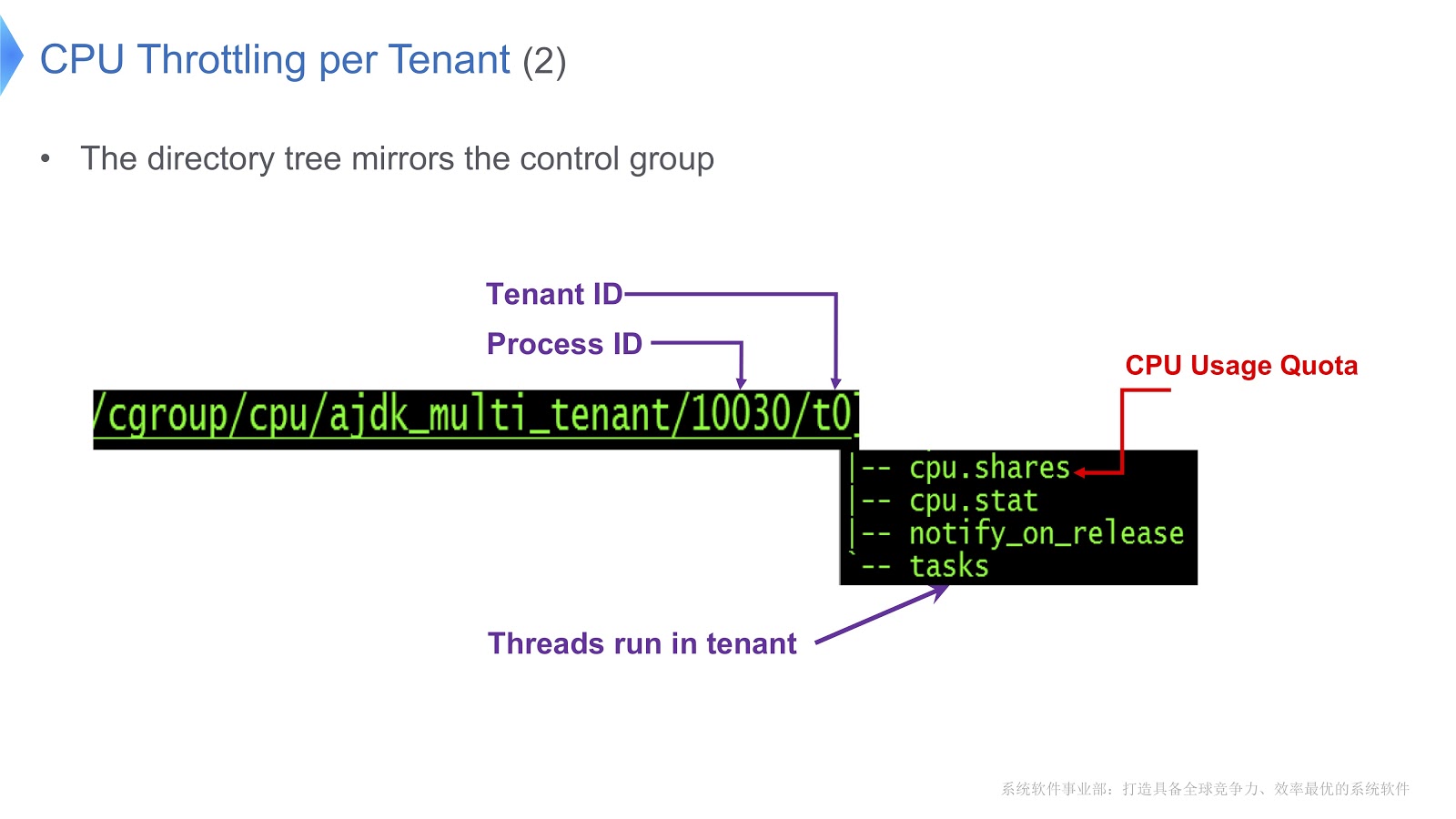
Grupos de controle no Linux são mapeados para um diretório. Em nosso exemplo, criamos o diretório /t0 para o inquilino 0. Esse diretório contém o diretório /t0/tasks , todos os encadeamentos para t0 serão localizados aqui. Outro arquivo importante é /t0/cpu.shares . Indica quanto tempo a CPU será dada a esse inquilino. Toda essa estrutura é herdada dos grupos de controle - simplesmente garantimos uma correspondência direta entre o encadeamento Java, o encadeamento nativo e o grupo de controle.
Outra questão importante diz respeito ao gerenciamento de vários inquilinos.
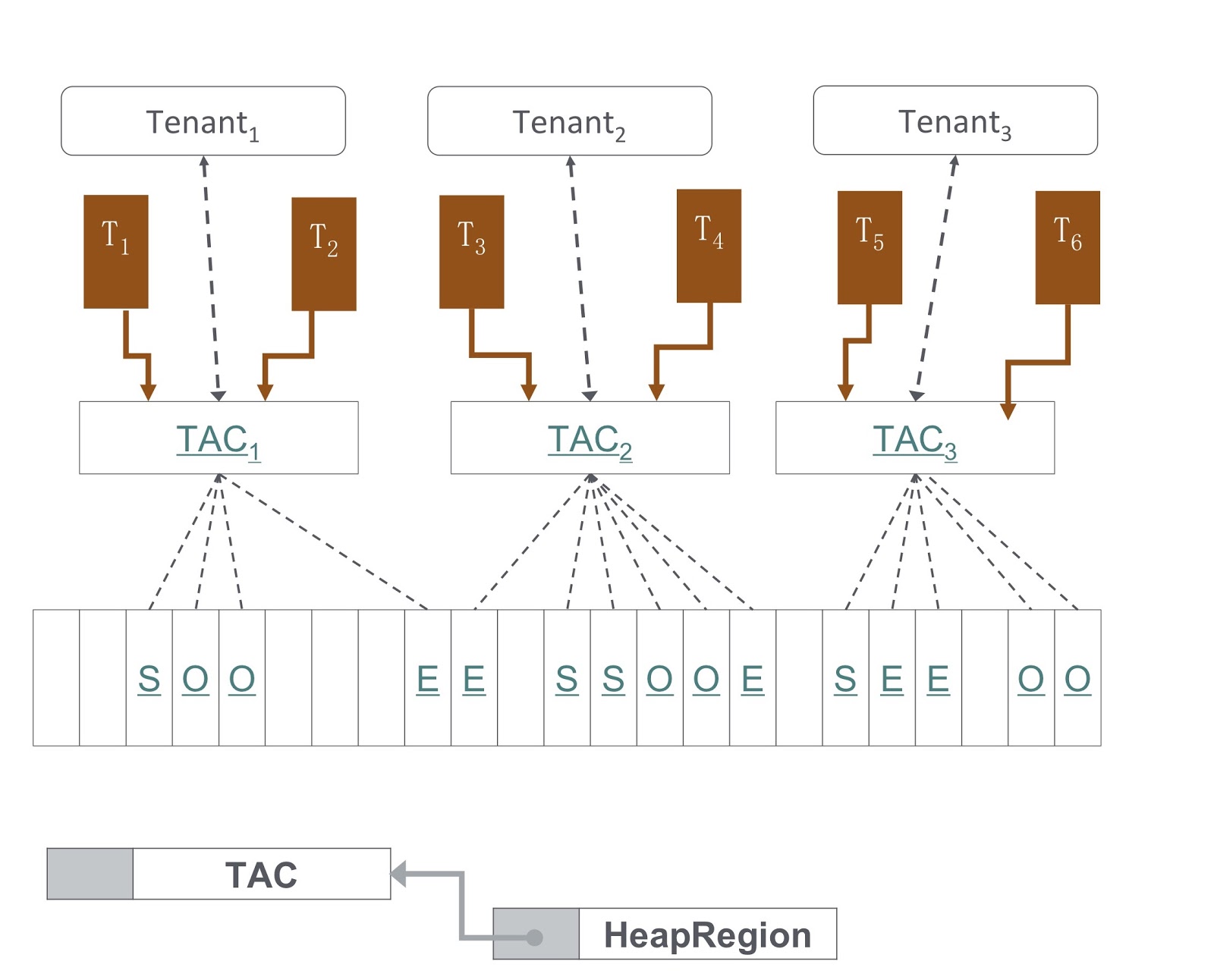
Na figura, você vê um diagrama de como é implementado. Nossa abordagem é baseada no G1GC. Na parte inferior da imagem, o G1GC divide a pilha em seções do mesmo tamanho. Com base neles, criamos TACs, Contextos de alocação de inquilino, com os quais o inquilino gerencia sua seção de heap. Por meio do TAC, limitamos o tamanho da parte da pilha disponível para o inquilino. Aqui, o princípio se aplica, segundo o qual cada seção da pilha contém objetos de apenas um inquilino. Para implementá-lo, precisávamos fazer alterações no processo de copiar um objeto durante a coleta de lixo - era necessário garantir que o objeto fosse copiado na seção correta da pilha.
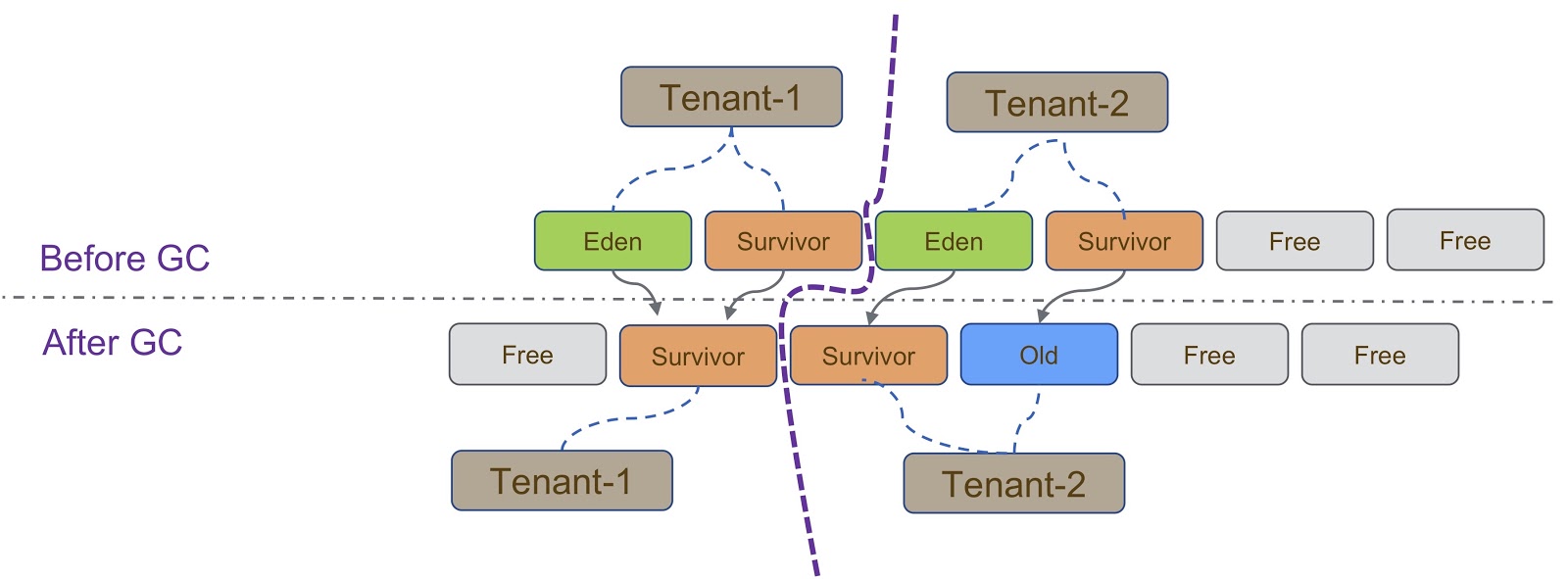
Esquematicamente, esse processo é representado no diagrama acima. Como eu disse, nossa implementação é baseada no G1GC. O G1GC é um coletor de lixo de cópia; portanto, durante a coleta de lixo, precisamos garantir que o objeto seja copiado para a seção correta da pilha. No slide, todos os objetos criados pelo Tenant-1 devem ser copiados para sua parte da pilha, semelhante ao Tenant-2 .
Há outras considerações que surgem quando os inquilinos são isolados um do outro. Aqui devo dizer sobre o TLAB (Thread Local Allocation Buffer) - um mecanismo para a alocação rápida de memória. O espaço TLAB depende da seção de heap. Como eu disse, diferentes inquilinos têm diferentes grupos de seções de heap.

As especificidades do trabalho com o TLAB são mostradas no slide - quando o encadeamento alterna entre o Tenant 1 e o Tenant 2 , precisamos garantir que a seção de heap correta seja usada para o espaço TLAB. Isso pode ser alcançado de duas maneiras. A primeira maneira é quando o Thread A alterna do Tenant 1 para o Tenant 2 , apenas nos livramos do antigo e criamos um novo no Tenant 2 . Esse método é relativamente fácil de implementar, mas desperdiça espaço no TLAB, o que é indesejável. A segunda maneira é mais complicada - conscientizar o TLAB dos inquilinos. Isso significa que teremos vários buffers TLAB para um thread. Quando o Thread A alterna do Tenant 1 para o Tenant 2 , precisamos alterar o buffer e usar o que foi criado no Tenant 2 .
Outro mecanismo que precisa ser dito em relação à delimitação de inquilinos é o IHOP (Percentagem de ocupação de encadeamento inicial). Inicialmente, o IHOP foi calculado com base em todo o heap, mas, no caso de um mecanismo multitenant, ele deve ser calculado com base em apenas uma seção do heap.
Vamos dar uma olhada no que é GCIH (GC Invisible Heap). Esse mecanismo cria uma seção na pilha, oculta do coletor de lixo e, portanto, não é afetada pela coleta de lixo. Este site é gerenciado pelo locatário da GCIH.

É importante dizer aqui que fornecemos uma API pública para nossos desenvolvedores Java. Um exemplo de como trabalhar com ele pode ser visto na tela. Permite usar o método moveIn() para mover objetos de um heap regular para uma parte do heap GCIH. Sua vantagem é que você ainda pode interagir com esses objetos, pois com objetos Java regulares, eles são muito semelhantes na estrutura. Mas, ao mesmo tempo, eles não exigem o custo da coleta de lixo. A conclusão, na minha opinião, é que, se você deseja acelerar a coleta de lixo, precisa personalizar o comportamento do coletor de lixo de acordo com as necessidades do seu aplicativo.
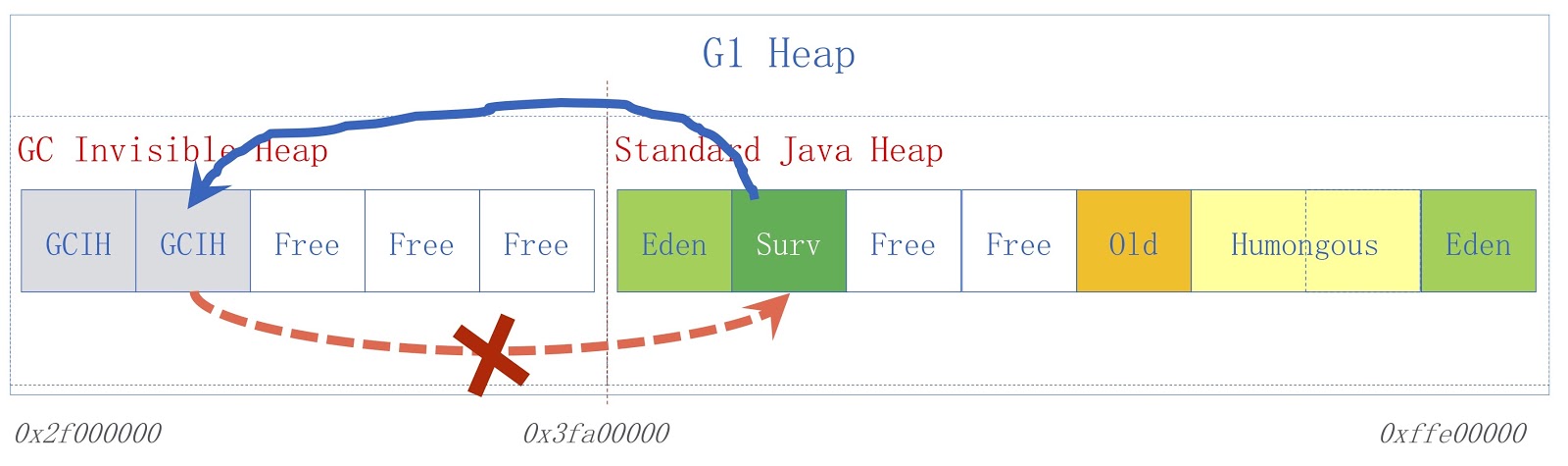
A imagem mostra um esquema GCIH de alto nível. À direita, há um heap Java comum, à esquerda, o espaço alocado para o GCIH. Os links de um heap regular para objetos no GCIH são válidos, mas os links do GCIH para um heap regular não são. Para entender por que isso acontece, considere um exemplo. Temos o objeto "A" no GCIH, que contém uma referência ao objeto "B" em um heap regular. O problema é que o objeto B pode ser movido pelo coletor de lixo. Como eu já disse, não fazemos atualizações no GCIH, portanto, depois que o coletor de lixo funcionar, o objeto "A" poderá conter uma referência inválida ao objeto "B". Esse problema pode ser resolvido usando a barreira de pré-gravação - eles foram discutidos em um relatório anterior. Como exemplo, suponha que alguém precise salvar um link de um heap Java regular no GCIH antes que o salvamento que assumimos resultaria em uma exceção de preditor com um sinalizador indicador de que a regra foi violada.
Para um aplicativo específico, uma JVM com vários inquilinos é usada em nossa Plataforma de Personalização Taobao, TPP abreviado. Este é um sistema de recomendação para o nosso aplicativo de compras eletrônicas. O TPP pode implantar vários microsserviços em um contêiner e, com a ajuda da JVM com vários inquilinos, controlamos o tempo de memória e CPU fornecido para cada microsserviço.
Quanto ao GCIH, ele é usado em nosso outro sistema, a Plataforma da UM. Este é um aplicativo de descontos online. O proprietário deste aplicativo usa o GCIH para pré-armazenar em cache os dados do GCIH na máquina local, para não acessar objetos no servidor de cache remoto ou no banco de dados remoto. Como resultado, reduzimos a carga na rede e executamos menos serialização e desserialização.
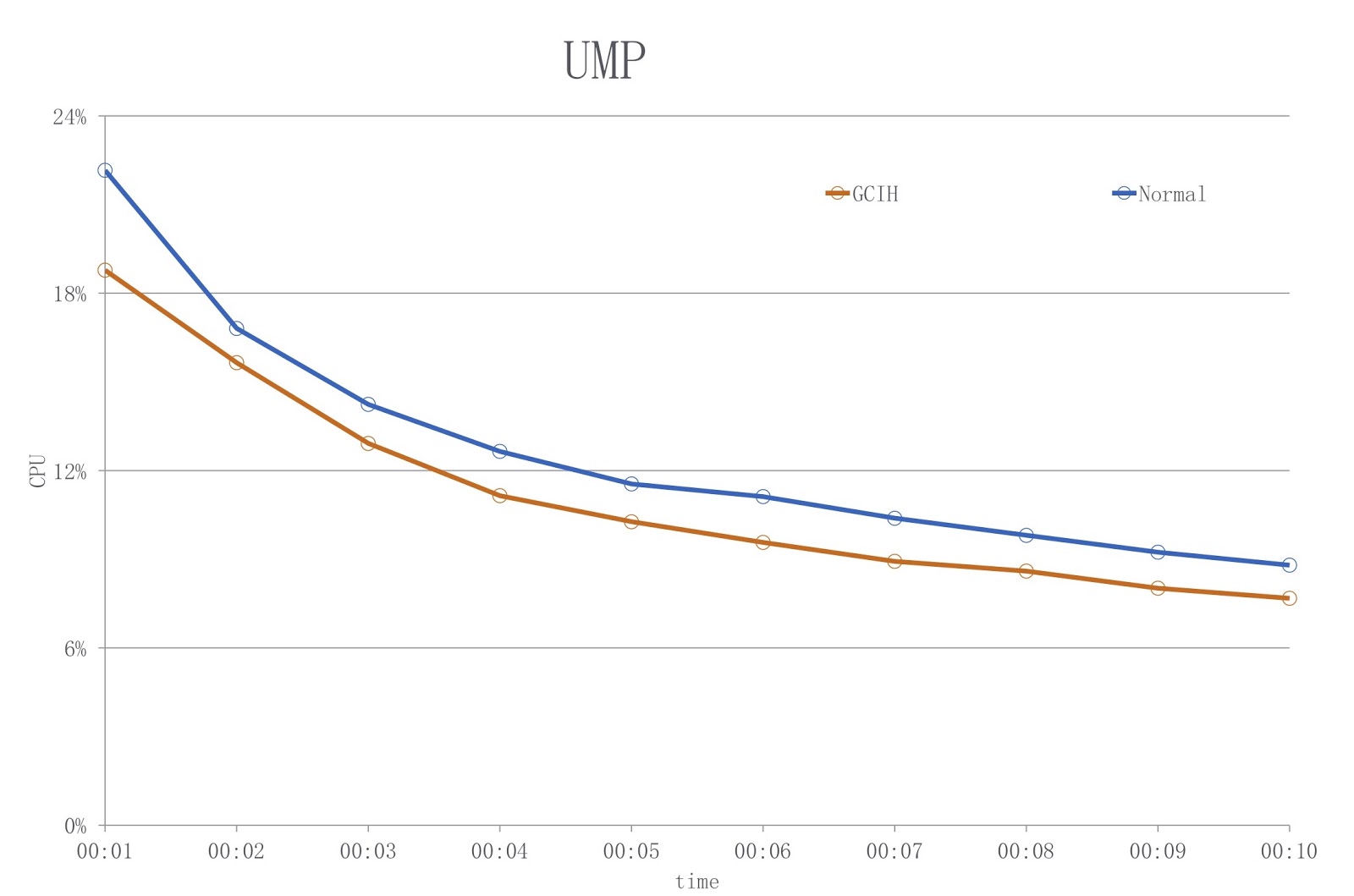
A figura mostra um diagrama no qual a cor azul mostra a carga ao usar um JDK convencional e o vermelho - GCIH. Como você pode ver, estamos reduzindo a utilização da CPU em mais de 18%.
Até onde eu sei, um problema semelhante foi resolvido pela BellSoft e sua solução foi semelhante à GCIH, mas eles usaram uma abordagem diferente para reduzir os custos de serialização e desserialização.
Corotinas em Java
Vamos voltar ao Alibaba e ver como as corotinas podem ser implementadas em Java. Mas primeiro, vamos falar sobre as origens, sobre por que precisamos fazer isso. Em Java, sempre foi muito fácil escrever aplicativos multithreading. Mas o problema com a criação desses aplicativos é que, como eu disse, no Hotspot, os threads Java já estão implementados como threads nativos. Portanto, quando há muitos encadeamentos em seu aplicativo, os custos de alteração do contexto do encadeamento tornam-se muito altos.

Considere um exemplo no qual teremos 4 threads de E / S e 200 threads com a lógica do seu aplicativo. A tabela na tela mostra os resultados do início desta demonstração simples - você pode ver quanto tempo a CPU leva para mudar os contextos. A solução para esse problema pode ser a implementação de corutin em Java.
Para fornecê-lo, precisávamos de duas coisas. Primeiro, o Alibaba JDK precisava adicionar suporte de continuação. Este trabalho foi baseado no patch da JKU, abordaremos mais detalhadamente. Em segundo lugar, adicionamos um sheduler no modo de usuário que será responsável pela continuação do encadeamento. Em terceiro lugar, existem muitas aplicações no Alibaba. Portanto, nossa solução é muito importante para nossos desenvolvedores Java e era necessário torná-la absolutamente transparente para eles. E isso significa que em nosso aplicativo de negócios não deveria haver praticamente nenhuma alteração no código. Chamamos nossa solução de Wisp. Nossa implementação de corotinas em Java é amplamente usada no Alibaba, portanto, pode-se considerar comprovado que funciona em Java. Conheça-o em mais detalhes.

Vamos começar com o exemplo, cujo código é apresentado acima - este é um aplicativo Java completamente comum. Primeiro, um pool de threads é criado. Em seguida, outra tarefa executável é criada que aceita o soquete. Depois disso, a leitura do fluxo é realizada. Em seguida, criamos outra tarefa Runnable, com a qual nos conectamos ao servidor e, finalmente, escrevemos dados no fluxo. Como você pode ver, tudo parece bastante padrão. Se você executar o código em um JDK regular, cada uma dessas tarefas Runnable será executada em um encadeamento separado. Mas em nossa decisão, a mecânica será completamente diferente.
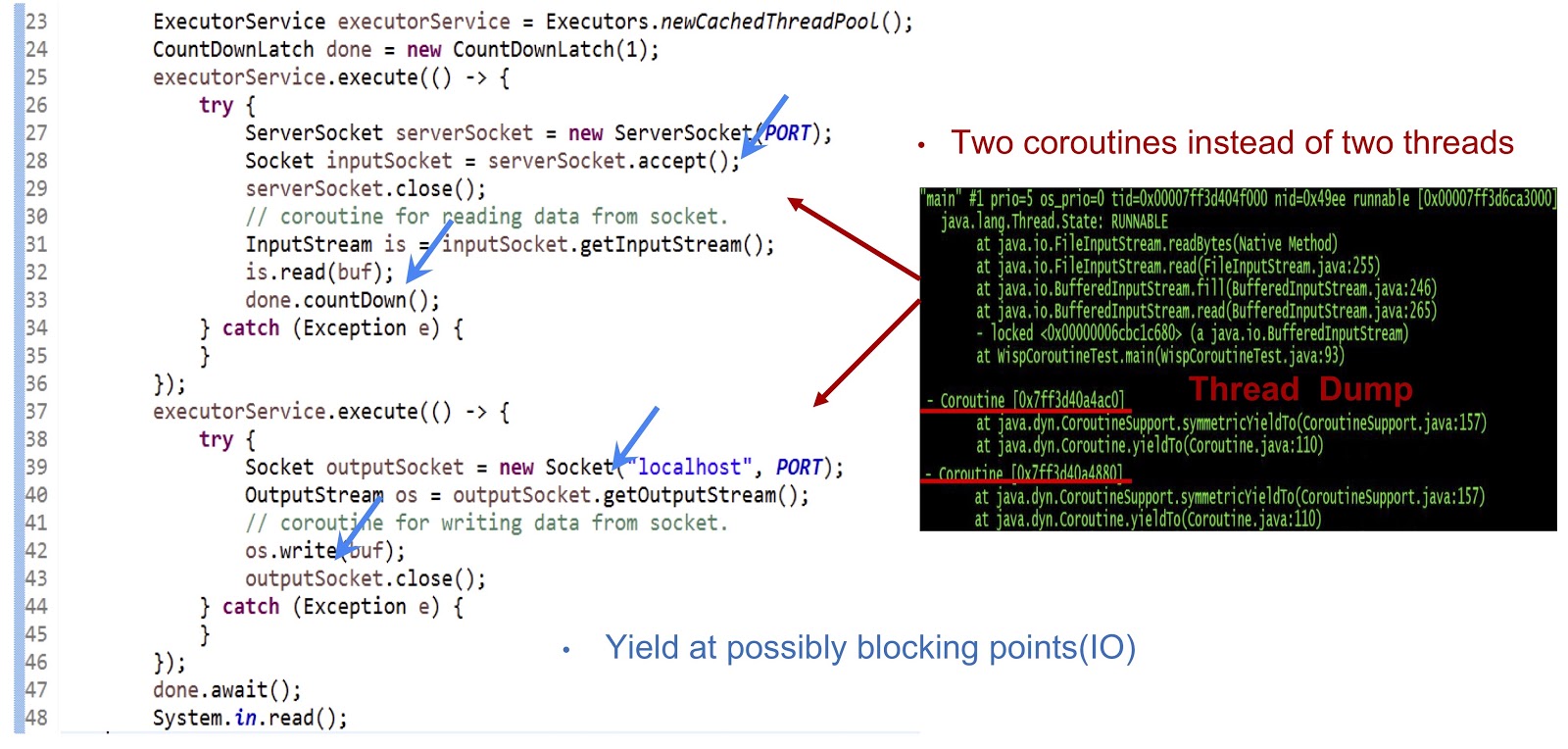
Como você pode ver no dump do thread mostrado no slide, criamos duas corotinas em um thread, e não dois. Agora você precisa fazer esta solução funcionar. O principal aqui é fazer a geração de eventos yieldTo em todos os possíveis pontos de bloqueio. Em nosso exemplo, esses pontos serão serverSocket.accept() , is.read(buf) , uma conexão de soquete e os.write(buf) . Graças a produzir eventos nesses pontos, poderemos transferir o controle de uma corotina para outra dentro do mesmo encadeamento. Para resumir, nossa abordagem é obter desempenho assíncrono usando a corotina, mas nossos programadores podem escrever código em um estilo síncrono, pois esse código é muito mais simples e fácil de manter e depurar.
Vejamos exatamente como fornecemos suporte de continuação no Alibaba JDK. Como eu disse, este trabalho é baseado em um projeto de máquina virtual multilíngue criado pela comunidade - é de domínio público. Usamos esse patch no Alibaba JDK e corrigimos alguns erros que ocorreram em nosso ambiente de produção.
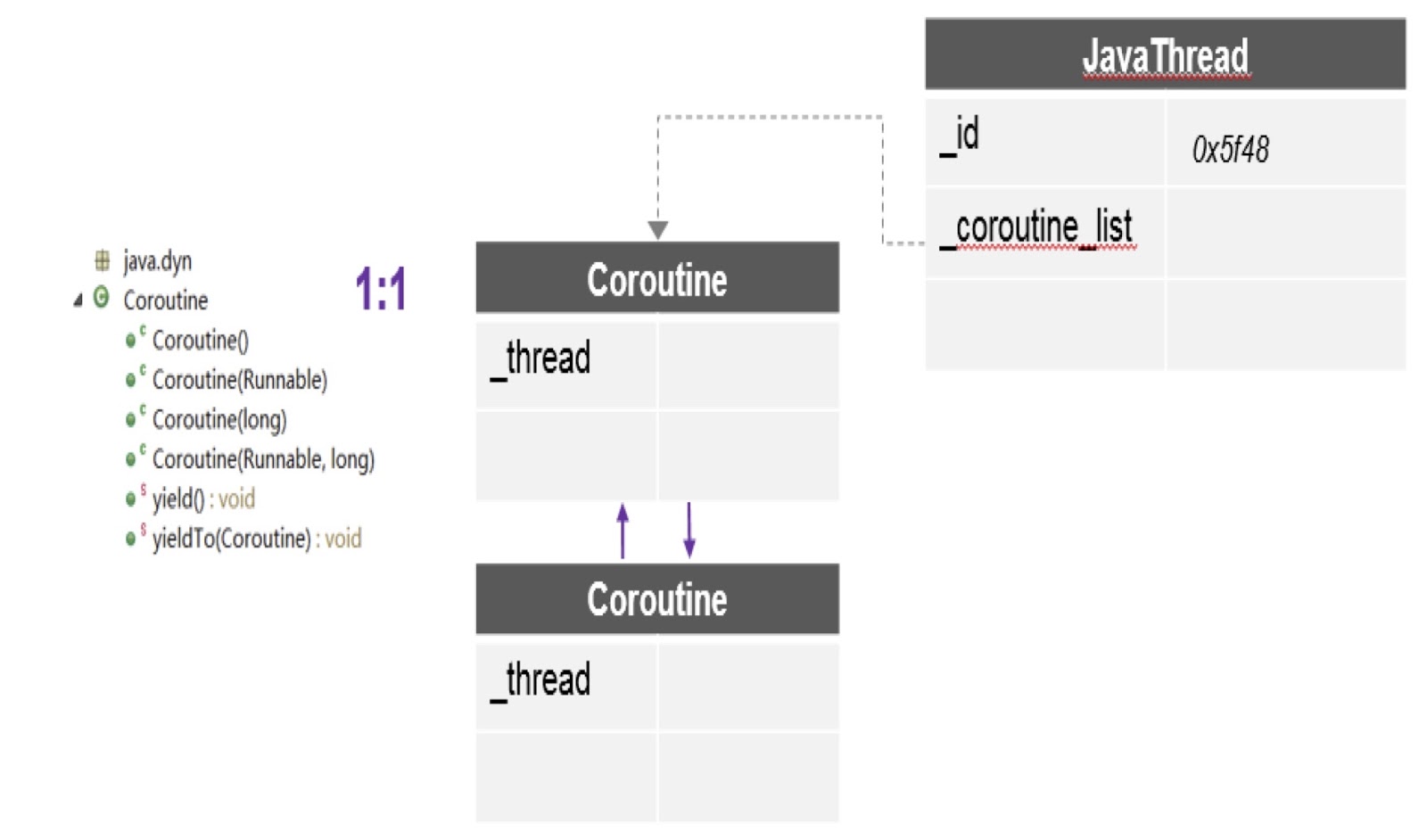
Como você pode ver no diagrama, aqui em um encadeamento podem existir várias corotinas e para cada uma é criada uma pilha separada. Além disso, o patch sobre o qual falei fornece a API mais importante aqui - yieldTo, com a ajuda de que o controle é transferido de uma corotina para outra.
Vamos seguir como implementamos o sheduler no modo de usuário da corotina. Usamos um seletor e, com ele, registramos vários canais. Quando qualquer evento de E / S (leitura, gravação, conexão ou aceitação de soquete) ocorre, ele é gravado como uma chave para o seletor. Portanto, no final deste evento, recebemos um alerta do seletor. Portanto, usamos um seletor para planejar corotinas no caso de um bloqueio de E / S. Considere um exemplo de como isso funcionará.
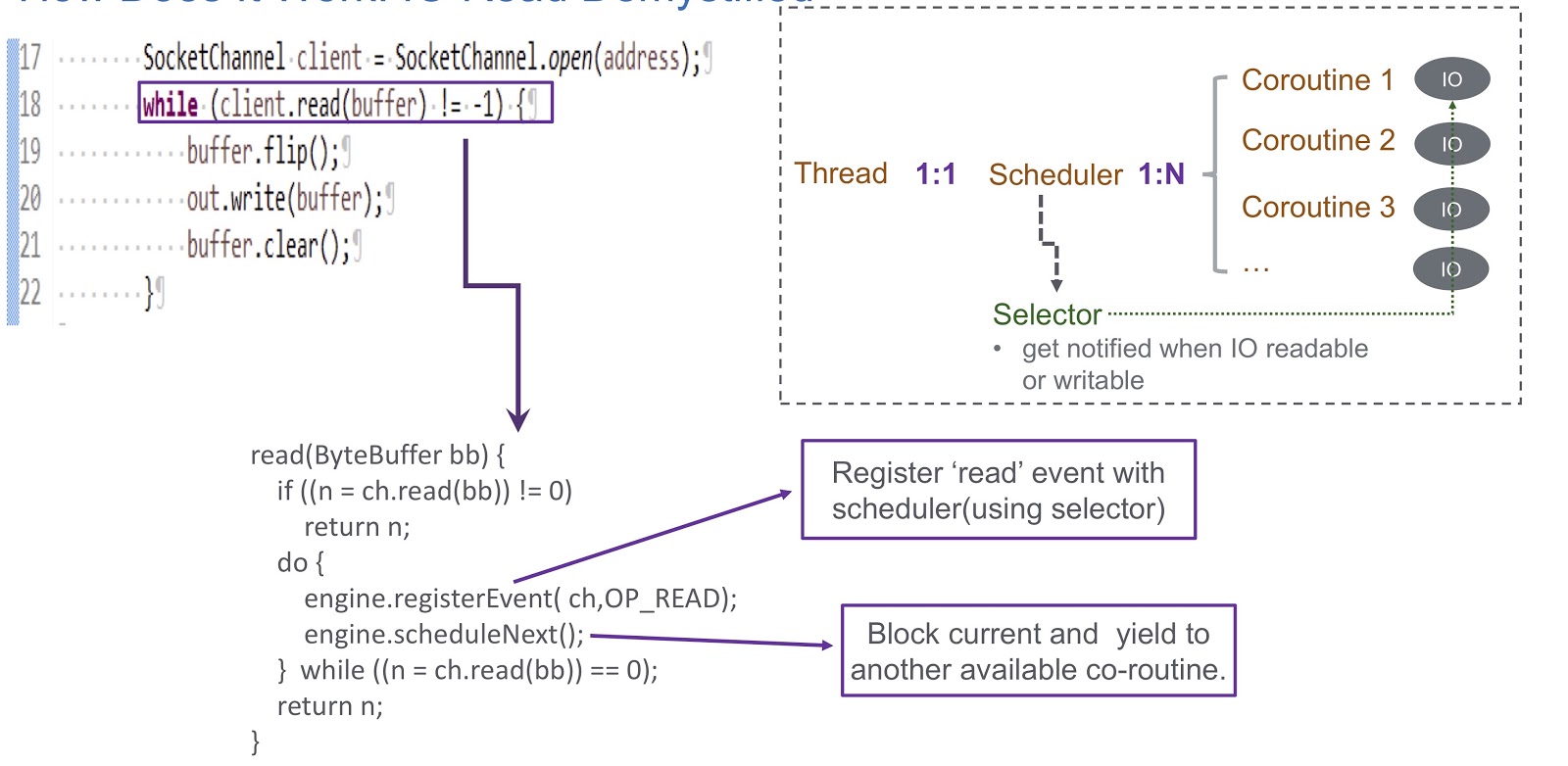
Na figura, vemos o soquete e a chamada síncrona client.read(buffer) . Na parte inferior do slide, é escrito um código que será executado dentro desta chamada. Primeiro, verifica se é possível ler a partir do canal ou não. Nesse caso, retornamos o resultado. A coisa mais interessante acontece se a leitura não puder ser feita. Em seguida, registramos o evento de leitura em nosso planejador com o seletor. Isso torna possível planejar a execução de qualquer outra rotina. Veja como isso acontece. Temos um segmento no qual um agendador é criado. O fio e a nossa rotina estão em correspondência um com o outro. O Sheduler nos permite gerenciar as corotinas desse segmento. O que acontece se a E / S estiver bloqueada? Quando ocorrem eventos de E / S, o sheduler recebe um alerta e, nessa situação, ele depende inteiramente do seletor. Após esse evento, o sheduler tem a oportunidade de planejar a próxima rotina disponível.
Vamos resumir a visão geral do nosso sheduler, que chamamos de WispEngine. Para cada um de nossos threads, alocamos um WispEngine separado. Quando ocorre um bloqueio de rotina, registramos certos eventos (leitura / gravação de soquete e assim por diante) usando o WispEngine. Alguns eventos estão relacionados ao estacionamento de threads, por exemplo, se você chamar thread.sleep() com um atraso de 100 milissegundos. Nesse caso, um evento de estacionamento de threads será gerado para você, que será registrado no seletor. Outra questão importante é quando o cronômetro indica a próxima rotina disponível. Existem duas condições principais. O primeiro é quando determinados eventos são gerados, como eventos de E / S ou eventos de tempo limite. Tudo é bem simples aqui: suponha que você faça uma chamada para thread.sleep() com um atraso de 200 milissegundos. Quando expiram, o sheduler tem a oportunidade de executar a próxima rotina disponível. Ou aqui, podemos falar sobre alguns eventos de descompactação que são gerados, digamos, chamando object.notify() ou object.notifyAll() A segunda condição é quando o usuário envia novas solicitações e criamos uma corotina para atendê-las e, em seguida, o sheduler atribui sua implementação.
Aqui você também precisa falar sobre o serviço que criamos, WispThreadExecutor.

Um código de exemplo é apresentado na tela e vemos que este é um ExecutorService comum, criado da mesma maneira. Os .execute() e submit() estão disponíveis para tarefas executáveis, mas o problema é que todas as tarefas executáveis que passam pelo método submit() serão executadas em corutin e não no encadeamento. Esta solução é completamente transparente para quem implementará nossa aplicação, eles poderão usar nossa API para corotinas.

Chego à última parte difícil do post - como resolver o problema da sincronização nas corotinas. Esta é uma pergunta complexa, então vamos ver com um exemplo simplificado. Aqui temos a corotina A ( test::foo ) e a corutina test::bar ). Primeiro, atribuímos a execução do test:foo à corotina wait() . Se nada for feito, o encadeamento atual será bloqueado pela chamada para wait() . Como pode ser visto neste despejo do encadeamento, ocorrerá um impasse e não poderemos agendar a próxima rotina a ser executada.
Como resolver este problema? O ponto de acesso fornece três tipos de bloqueios. O primeiro é o bloqueio rápido. Aqui, o proprietário do bloqueio é determinado pelo endereço na pilha. Como eu disse, cada uma das nossas rotinas possui uma pilha separada. Portanto, no caso de bloqueio rápido, não precisamos fazer nenhum trabalho adicional. Não há suporte semelhante para bloqueio parcial no nosso sistema. Tentamos fazer isso em nossa produção e, na ausência de um bloqueio tendencioso, o desempenho não diminui. Para nós, é bastante adequado.
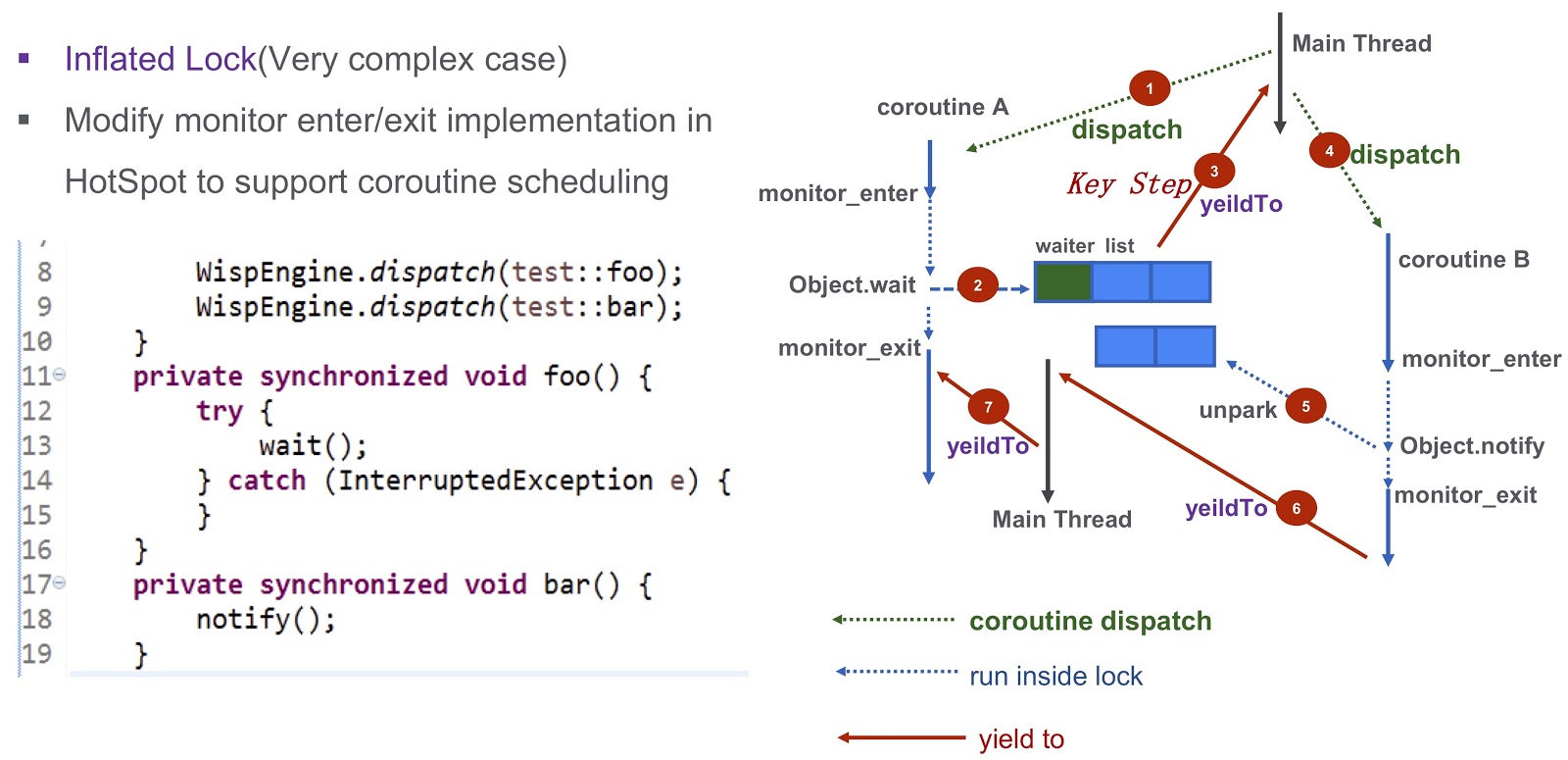
Vamos falar sobre um caso mais complicado - bloqueio inflado. Vamos olhar novamente para o exemplo que citei acima. Temos Corutin .foo() ) e Corutin B ( .bar() ). Primeiro, atribuímos a execução da corotina Object.wait , após o qual entra na lista de espera. Depois disso, damos um passo muito importante: geramos o evento yieldTo , que transfere o controle para o thread principal. Em seguida, começamos Corutin B Ele chama Object.notify , e os eventos de Object.notify correspondentes são unpark . Eventualmente, eles acordarão a corotina bar() , será possível transferir o controle para a rotina
Vamos discutir o desempenho agora. Usamos corotinas em um de nossos aplicativos online de Carrinhos. Com base nisso, podemos comparar o trabalho de corutin com o trabalho de um JDK regular.
Como você pode ver, eles permitem reduzir o consumo de tempo do processador em quase 10%. Entendo que a maioria de vocês provavelmente não tem a capacidade de fazer diretamente alterações tão complexas no código JDK. Mas a principal conclusão aqui, na minha opinião, é que se as perdas de produtividade custam dinheiro e o valor resultante é grande o suficiente, você pode tentar melhorar a produtividade usando a biblioteca corutin.
Jarmarm
Vamos para a nossa outra ferramenta - JWarmup. É muito semelhante a outra ferramenta, ReadyNow. Como sabemos, em Java há um problema de aquecimento - o compilador neste estágio requer ciclos adicionais de CPU. Isso nos causou problemas - por exemplo, ocorreu um erro de tempo limite. Ao escalar, esses problemas pioram e, no nosso caso, estamos falando de uma aplicação muito complexa - mais de 20 mil classes e mais de 50 mil métodos.
Antes de começarmos a usar o JWarmup, os proprietários do nosso aplicativo usavam dados simulados para aquecer. Nesses dados, o compilador JIT pré-compilou antes que as solicitações fossem recebidas. Mas os dados simulados são diferentes dos reais, portanto, não são representativos para o compilador. Em alguns casos, ocorreu desoptimização inesperada, desempenho prejudicado. A solução para esse problema foi o JWarmup. Ele tem duas etapas principais de trabalho - gravação e compilação. O Alibaba possui dois tipos de ambientes, beta e produção. Ambos recebem solicitações reais dos usuários, após o qual a mesma versão do aplicativo é implantada nesses dois ambientes. No ambiente beta, apenas os dados de criação de perfil são coletados, com base nos quais a compilação preliminar na produção é executada.

Vamos ver com mais detalhes que tipo de informação coletamos. Precisamos anotar exatamente quais classes são inicializadas, quais métodos são compilados, para que esses dados sejam liberados no log do disco rígido, acessível ao compilador. O momento mais difícil é a inicialização das aulas. . — Bar Foo.test() , foo.count . , .
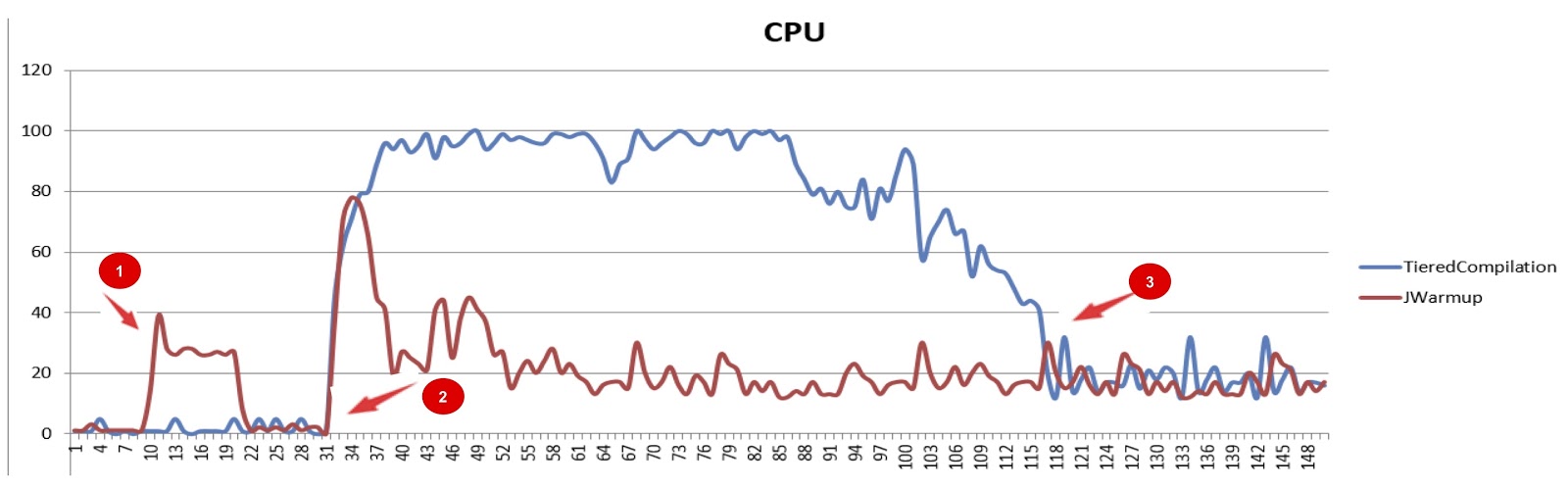
JWarmup (tiered compilation), . , — CPU. JWarmup , CPU, JDK. , , JDK. , , .
JWarmup. , , , groovy-, Java-, . . , , «null check elimination». . , JWarmup , JWarmup, .
, Alibaba.
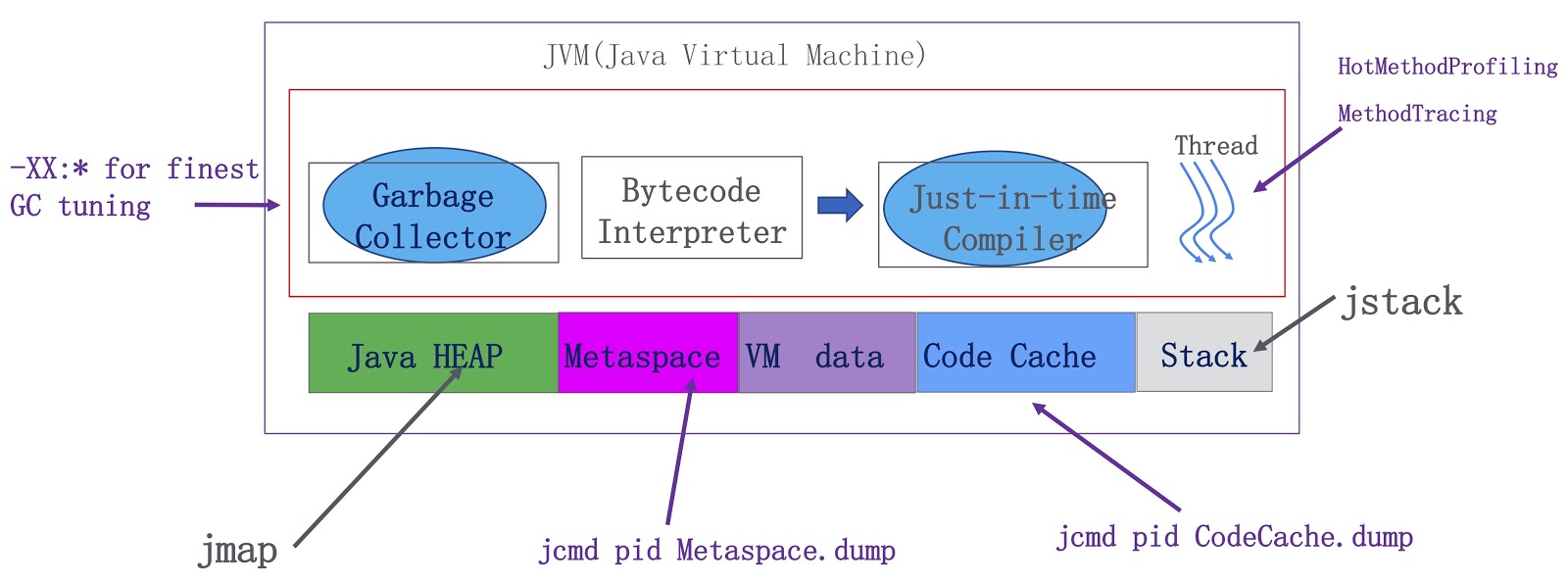
. JVM — , , . Java-, metaspace, VM ( VM) JIT-. OpenJDK. -, , . -, . HotMethodProfiling, , CPU. , , Honest Profiler , , , HotMethodProfiling. MethodTracing. , , . , metaspace . Java-, . metaspace , . Java.
, , ZProfiler.
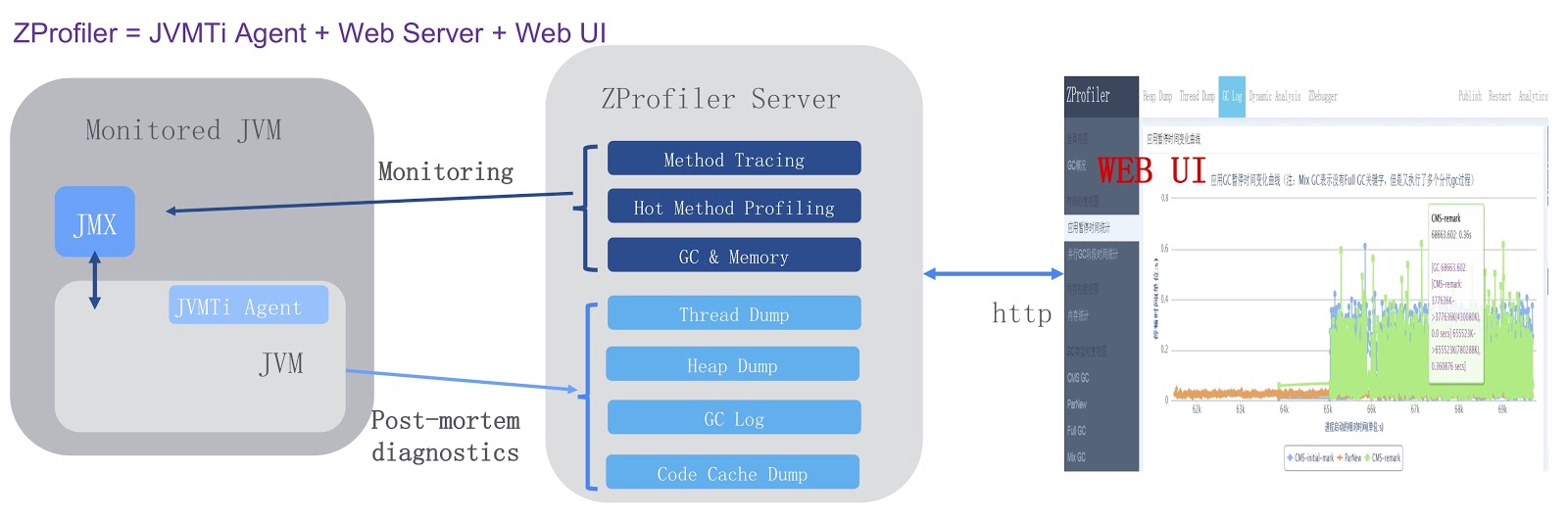
. JVMTi, JVM ( ). , ZProfiler Apache Tomcat. -. ZProfiler JVM. , ZProfiler -UI, . ZProfiler . -, UI JVM. -, ZProfiler post-mortem . , OutOfMemoryError, , JVM ZProfiler, . , , , Eclipse MAT.
. . JVM, GCIH, Alibaba JDK, JWarmup — , ReadyNow Zing JVM. , ZProfiler. , , OpenJDK. , , JWarmup OpenJDK. , OpenJDK Loom, Java. , .
. , , JPoint 2018 . 2019 , JPoint , 5-6 . , Rafael Winterhalter Sebastian Daschner. . , YouTube . JPoint!