 Postado por Denis Tsyplakov , arquiteto de soluções, DataArt
Postado por Denis Tsyplakov , arquiteto de soluções, DataArtNo DataArt, trabalho de duas maneiras. No primeiro, ajudo as pessoas a reparar sistemas que estão danificados de uma maneira ou de outra e por várias razões. No segundo, ajudo a projetar novos sistemas para que não sejam quebrados no futuro ou, mais realista, quebrá-los era mais difícil.
Se você não está fazendo algo fundamentalmente novo, por exemplo, o primeiro mecanismo de busca na Internet ou inteligência artificial do mundo a controlar o lançamento de mísseis nucleares, criar um bom design de sistema é bastante simples. Basta levar em consideração todos os requisitos, analisar o design de sistemas similares e fazer o mesmo, sem cometer erros graves. Parece uma simplificação excessiva do problema, mas lembremos que no quintal é o ano de 2019, e existem “receitas padrão” para o design do sistema para quase tudo. Uma empresa pode executar tarefas técnicas complexas - digamos, processar um milhão de arquivos PDF heterogêneos e remover tabelas de despesas deles - mas a arquitetura do sistema raramente é muito original. O principal aqui não é cometer um erro ao determinar qual sistema estamos construindo e não perder a escolha das tecnologias.
Erros típicos ocorrem regularmente no último parágrafo, alguns dos quais discutirei em um artigo.
Qual é a dificuldade de escolher uma pilha técnica? A adição de qualquer tecnologia ao projeto torna mais difícil e traz algum tipo de limitação. Consequentemente, a adição de uma nova ferramenta (estrutura, biblioteca) só deve ser feita quando essa ferramenta é mais útil do que prejudicial. Nas conversas com os membros da equipe sobre como adicionar bibliotecas e estruturas, eu frequentemente uso o seguinte truque: “Se você deseja adicionar uma nova dependência ao projeto, coloca uma caixa de cerveja para a equipe. Se você acha que essa dependência de uma caixa de cerveja não vale a pena, não a adicione. ”
Suponha que criemos um determinado aplicativo, digamos, em Java e adicionemos a biblioteca TimeMagus ao projeto para manipular datas (um exemplo é fictício). A biblioteca é excelente, fornece muitos recursos que não estão disponíveis na biblioteca de classes padrão. Como essa decisão pode ser prejudicial? Vejamos os cenários possíveis:
- Nem todos os desenvolvedores conhecem uma biblioteca não padrão, o limite de entrada para novos desenvolvedores será maior. Aumenta a chance de um novo desenvolvedor cometer um erro ao manipular uma data usando uma biblioteca desconhecida.
- O tamanho da distribuição está aumentando. Quando o tamanho médio do aplicativo no Spring Boot pode facilmente chegar a 100 MB, isso não é de forma alguma um pouco. Vi casos em que, por um único método, uma biblioteca de 30 MB foi inserida no kit de distribuição. Eles justificaram da seguinte maneira: "Eu usei essa biblioteca em um projeto anterior e existe um método conveniente lá".
- Dependendo da biblioteca, a hora de início pode aumentar significativamente.
- O desenvolvedor da biblioteca pode abandonar sua ideia, então a biblioteca começará a entrar em conflito com a nova versão do Java, ou um bug será detectado nela (causado por, por exemplo, mudanças de fuso horário) e nenhum patch será lançado.
- A licença da biblioteca em algum momento entrará em conflito com a licença do seu produto (você verifica as licenças de todos os produtos que usa?).
- Jar hell - a biblioteca TimeMagus precisa da versão mais recente da biblioteca SuperCollections, depois de alguns meses você precisa conectar a biblioteca para integração com uma API de terceiros, que não funciona com a versão mais recente do SuperCollections e funciona apenas com a versão 2.x. Você não pode conectar uma API. Não há outra biblioteca para trabalhar com esta API.
Por outro lado, a biblioteca padrão fornece ferramentas convenientes para manipular datas, e se você não precisar manter, por exemplo, um calendário exótico ou calcular o número de dias entre hoje e "o segundo dia da terceira lua nova no ano anterior da águia", pode valer a pena abster-se de usar uma biblioteca de terceiros. Mesmo que seja completamente maravilhoso e em uma escala de projeto, você economizará até 50 linhas de código.
O exemplo considerado é bastante simples e acho fácil tomar uma decisão. Mas há várias tecnologias difundidas pelos ouvidos de todos, e seu uso é óbvio, o que dificulta a escolha - elas realmente oferecem sérias vantagens ao desenvolvedor. Mas isso nem sempre precisa ser uma ocasião para arrastá-los para o seu projeto. Vamos olhar para alguns deles.
Docker
Antes do surgimento dessa tecnologia realmente interessante, ao implantar sistemas, havia muitos problemas desagradáveis e complexos relacionados ao conflito de versão e dependências obscuras. O Docker permite compactar um instantâneo do status do sistema, colocá-lo em produção e executá-lo lá. Isso permite que os conflitos mencionados sejam evitados, o que, é claro, é ótimo.
Anteriormente, isso era feito de uma maneira monstruosa e algumas tarefas não eram resolvidas. Por exemplo, você tem um aplicativo PHP que usa a biblioteca ImageMagick para trabalhar com imagens, seu aplicativo também precisa de configurações específicas do php.ini e o próprio aplicativo é hospedado usando o Apache httpd. Mas há um problema: algumas rotinas regulares são implementadas executando scripts Python a partir do cron, e a biblioteca usada por esses scripts entra em conflito com as versões da biblioteca usadas no seu aplicativo. O Docker permite que você empacote seu aplicativo inteiro, juntamente com configurações, bibliotecas e um servidor HTTP, em um contêiner que atende solicitações na porta 80 e rotinas em outro contêiner. Todos juntos funcionarão perfeitamente, e você pode esquecer o conflito de bibliotecas.
Devo usar o Docker para compactar cada aplicativo? Minha opinião: não, não vale a pena. A imagem mostra uma composição típica de um aplicativo dockerizado implantado na AWS. Os retângulos aqui indicam as camadas de isolamento que temos.
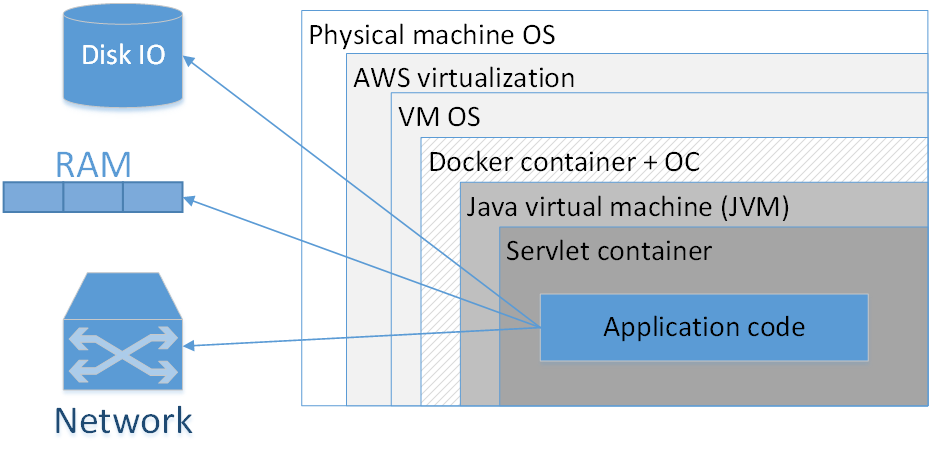
O maior retângulo é a máquina física. Em seguida é o sistema operacional da máquina física. Então - o virtualizador da Amazônia, o SO da máquina virtual, o contêiner do docker, seguido pelo SO do contêiner, JVM, o contêiner do Servlet (se for um aplicativo da web) e o código do aplicativo já está nele. Ou seja, já vemos algumas camadas de isolamento.
A situação ficará ainda pior se olharmos para a sigla JVM. A JVM é, curiosamente, a Java Virtual Machine, ou seja, sempre temos pelo menos uma máquina virtual em Java. Adicionar aqui um contêiner Docker adicional, em primeiro lugar, geralmente não oferece uma vantagem tão perceptível, porque a própria JVM já nos isola muito bem do ambiente externo e, em segundo lugar, não é sem custo.
Peguei números de um estudo da IBM, se não me engano, há dois anos. Resumidamente, se estamos falando sobre operações de disco, uso do processador ou acesso à memória, o Docker quase não adiciona uma sobrecarga (literalmente uma fração de um por cento), mas se estamos falando sobre a latência da rede, os atrasos são bastante visíveis. Eles não são gigantescos, mas, dependendo do aplicativo que você possui, podem surpreendê-lo desagradável.
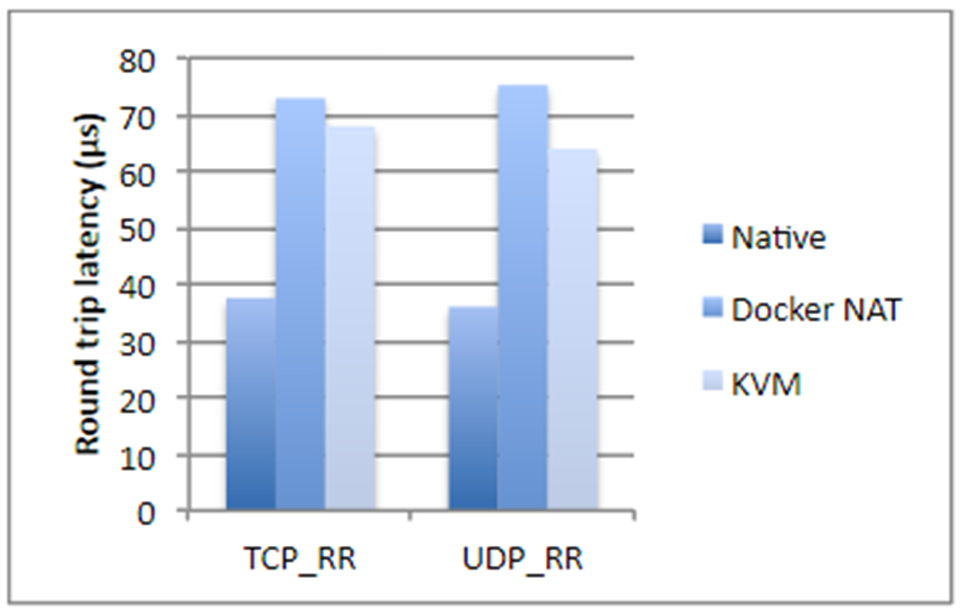
Além disso, o Docker ocupa mais espaço em disco, ocupa parte da memória e aumenta o tempo de inicialização. Todos os três pontos não são críticos para a maioria dos sistemas - geralmente há muito espaço em disco e memória. O tempo de inicialização, como regra, também não é um problema crítico, o principal é que o aplicativo seja iniciado. Mas ainda existem situações em que a memória pode acabar, e o tempo total de início do sistema, composto por vinte serviços dependentes, já é bastante grande. Além disso, isso afeta o custo de hospedagem. E se você estiver envolvido em alguma negociação de alta frequência, o Docker categoricamente não combina com você. Em geral, é melhor não encaixar qualquer aplicativo sensível a atrasos na rede de até 250 a 500 ms.
Além disso, com a janela de encaixe, a análise de problemas nos protocolos de rede é notavelmente complicada, não apenas os atrasos aumentam, mas todos os tempos se tornam diferentes.
Quando o Docker é realmente necessário?
Quando temos versões diferentes do JRE, e seria bom arrastar o JRE. Há momentos em que você precisa executar uma certa versão do Java (não "o Java 8 mais recente", mas algo mais específico). Nesse caso, é bom compactar o JRE com o aplicativo e executar como um contêiner. Em princípio, é claro que versões diferentes de Java podem ser colocadas no sistema de destino devido a JAVA_HOME etc. Mas, neste sentido, o Docker é muito mais conveniente, porque você conhece a versão exata do JRE, tudo é empacotado e, com outro JRE, o aplicativo nem inicia por acidente. .
O Docker também é necessário se você tiver dependências em algumas bibliotecas binárias, por exemplo, para processamento de imagem. Nesse caso, pode ser uma boa ideia compactar todas as bibliotecas necessárias com o próprio aplicativo Java.
O caso a seguir se refere a um sistema que é um composto complexo de vários serviços escritos em vários idiomas. Você tem uma parte do Node.js, uma parte do Java, uma biblioteca do Go e, além disso, algum tipo de Machine Learning no Python. Todo esse zoológico deve ser cuidadoso e cuidadosamente ajustado para ensinar seus elementos a se verem. Dependências, caminhos, endereços IP - tudo isso deve ser pintado e cuidadosamente aumentado na produção. Obviamente, nesse caso, o Docker o ajudará muito. Além disso, fazê-lo sem a ajuda dele é simplesmente doloroso.
O Docker pode oferecer alguma comodidade quando você precisar especificar muitos parâmetros diferentes na linha de comandos para iniciar o aplicativo. Por outro lado, os scripts do bash fazem isso muito bem, geralmente a partir de uma única linha. Decida qual usar melhor.
A última coisa que vem à mente de uma vez é a situação em que você usa, digamos, o Kubernetes, e precisa orquestrar o sistema, ou seja, aumentar um certo número de microsserviços diferentes que escalam automaticamente de acordo com certas regras.
Em todos os outros casos, o Spring Boot é suficiente para compactar tudo em um único arquivo jar. E, em princípio, o jarro de mola é uma boa metáfora para o contêiner do Docker. Obviamente, isso não é a mesma coisa, mas em termos de facilidade de implantação, eles são realmente semelhantes.
Kubernetes
E se usarmos o Kubernetes? Para começar, essa tecnologia permite implantar um grande número de microsserviços em diferentes máquinas, gerenciá-las, fazer escalonamento automático etc. No entanto, existem muitos aplicativos que permitem gerenciar a orquestração, por exemplo, Puppet, mecanismo CF, SaltStack e outros. O Kubernetes em si é certamente bom, mas pode adicionar uma sobrecarga significativa, com a qual nem todo projeto está pronto para viver.
Minha ferramenta favorita é Ansible, combinada com Terraform onde você precisar. Ansible é uma ferramenta leve declarativa bastante simples. Ele não requer a instalação de agentes especiais e possui a sintaxe compreensível dos arquivos de configuração. Se você estiver familiarizado com a composição do Docker, verá imediatamente as seções sobrepostas. E se você usa o Ansible, não há necessidade de pré-rezerez - você pode implantar sistemas usando meios mais clássicos.
É claro que, mesmo assim, essas são tecnologias diferentes, mas há um conjunto de tarefas nas quais elas são intercambiáveis. E uma abordagem consciente do design requer uma análise de qual tecnologia é mais adequada para o sistema que está sendo desenvolvido. E como será melhor combinar isso daqui a alguns anos.
Se o número de serviços diferentes em seu sistema for pequeno e a configuração deles for relativamente simples, por exemplo, você terá apenas um arquivo jar e não verá um crescimento repentino e explosivo na complexidade, provavelmente poderá se dar bem com mecanismos de implantação clássicos.
Isso levanta a questão: "espere, como está um arquivo jar?". O sistema deve consistir no maior número possível de microsserviços atômicos! Vamos ver quem e o que o sistema deve com microsserviços.
Microsserviços
Antes de tudo, os microsserviços permitem obter maior flexibilidade e escalabilidade, além de permitir versões flexíveis de partes individuais do sistema. Suponha que tenhamos algum tipo de aplicativo que esteja em produção há muitos anos. A funcionalidade está crescendo, mas não podemos desenvolvê-la infinitamente de uma maneira extensa. Por exemplo.
Temos um aplicativo no Spring Boot 1 e Java 8. Uma combinação maravilhosa e estável. Mas o ano é 2019 e, gostemos ou não, precisamos avançar para o Spring Boot 2 e Java 12. Mesmo a transição relativamente simples de um sistema grande para a nova versão do Spring Boot pode ser muito trabalhosa, mas é preciso pular o abismo do Java 8 para o Java 12 eu não quero conversar. Ou seja, em teoria tudo é simples: migramos, corrigimos os problemas que surgiram, testamos tudo e executamos na produção. Na prática, isso pode significar vários meses de trabalho que não trazem novas funcionalidades aos negócios. Uma pequena mudança para o Java 12, como você sabe, também não funciona. Aqui a arquitetura de microsserviço pode nos ajudar.
Podemos alocar um grupo compacto de funções de nosso aplicativo em um serviço separado, migrar esse grupo de funções para uma nova pilha técnica e colocá-lo em produção em um tempo relativamente curto. Repita o processo, peça por peça, até que as tecnologias antigas estejam completamente esgotadas.
Além disso, os microsserviços podem fornecer isolamento de falhas quando um componente caído não arruina todo o sistema.
Os microsserviços nos permitem ter uma pilha técnica flexível, ou seja, não escrever tudo monoliticamente em um idioma e uma versão e, se necessário, usar uma pilha técnica diferente para componentes individuais. Obviamente, é melhor usar uma pilha técnica uniforme, mas isso nem sempre é possível e, nesse caso, os microsserviços podem ajudar.
Os microsserviços também permitem uma maneira técnica de resolver vários problemas gerenciais. Por exemplo, quando sua grande equipe consiste em grupos separados, trabalhando em empresas diferentes (sentados em fusos horários diferentes e falando idiomas diferentes). Os microsserviços ajudam a isolar essa diversidade organizacional por componentes que serão desenvolvidos separadamente. Os problemas de uma parte da equipe permanecerão dentro de um serviço e não se espalharão por todo o aplicativo.
Mas os microsserviços não são a única maneira de resolver esses problemas. Curiosamente, há algumas décadas, para metade deles, as pessoas criaram classes e, um pouco mais tarde - componentes e o padrão de Inversão do controle.
Se olharmos para o Spring, veremos que, de fato, é uma arquitetura de microsserviço dentro de um processo Java. Podemos declarar um componente que, em essência, é um serviço. Temos a capacidade de fazer uma pesquisa através do @Autowired, existem ferramentas para gerenciar o ciclo de vida dos componentes e a capacidade de configurar componentes separadamente a partir de uma dúzia de fontes diferentes. Em princípio, obtemos quase tudo o que temos com microsserviços - apenas dentro de um processo, o que reduz significativamente os custos. Uma classe Java regular é o mesmo contrato de API que também permite isolar detalhes de implementação.
Estritamente falando, no mundo Java, os microsserviços são mais parecidos com o OSGi - lá temos uma cópia quase exata de tudo o que existe nos microsserviços, exceto, além da possibilidade de usar diferentes linguagens de programação e execução de código em diferentes servidores. Mas, mesmo mantendo os recursos das classes Java, temos uma ferramenta bastante poderosa para resolver um grande número de problemas de isolamento.
Mesmo em um cenário "gerencial" com isolamento de equipe, podemos criar um repositório separado que contém um módulo Java separado com um contrato externo claro e um conjunto de testes. Isso reduzirá significativamente a capacidade de uma equipe de complicar inadvertidamente a vida de outra equipe.
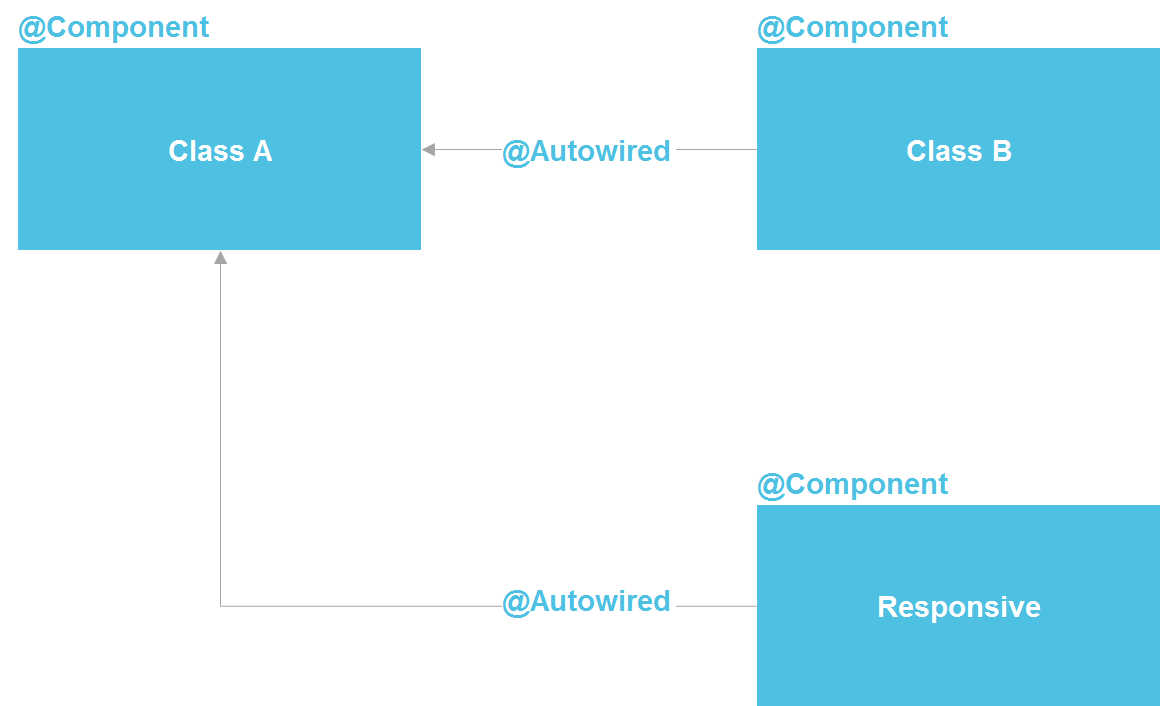
Ouvi repetidamente que é impossível isolar detalhes de implementação sem microsserviços. Mas posso responder que toda a indústria de software está apenas isolando a implementação. Para isso, a sub-rotina foi inventada (nos anos 50 do século passado), depois funções, procedimentos, classes e microsserviços posteriores. Mas o fato de os microsserviços desta série aparecerem por último não os torna o ponto mais alto de desenvolvimento e não nos obriga a sempre recorrer à ajuda deles.
Ao usar microsserviços, também é necessário levar em consideração que as chamadas entre eles levam algum tempo. Isso geralmente não é importante, mas vi um caso em que o cliente precisava ajustar o tempo de resposta do sistema de 3 segundos. Era uma obrigação contratual conectar-se a um sistema de terceiros. A cadeia de chamadas passou por várias dezenas de microsserviços atômicos e a sobrecarga de fazer chamadas HTTP não tornou possível diminuir em três segundos. Em geral, você precisa entender que qualquer divisão do código monolítico em vários serviços afeta inevitavelmente o desempenho geral do sistema. Só porque os dados não podem ser teleportados entre processos e servidores "de graça".
Quando são necessários os microsserviços?
Em que casos um aplicativo monolítico realmente precisa ser dividido em vários microsserviços? Primeiro, quando há um uso desequilibrado de recursos em áreas funcionais.
Por exemplo, temos um grupo de chamadas de API que executam cálculos que exigem muito tempo do processador. E há um grupo de chamadas de API que são executadas muito rapidamente, mas exigem que uma estrutura de dados de 64 GB seja armazenada na memória. Para o primeiro grupo, precisamos de um grupo de máquinas com um total de 32 processadores, pois a segunda máquina é suficiente (OK, que haja duas máquinas para tolerância a falhas) com 64 GB de memória. Se tivermos um aplicativo monolítico, precisaremos de 64 GB de memória em cada máquina, o que aumenta o custo de cada máquina. Se essas funções forem divididas em dois serviços separados, podemos economizar recursos otimizando o servidor para uma função específica. A configuração do servidor pode ser assim:

São necessários microsserviços e, se precisarmos escalar seriamente alguma área funcional estreita. Por exemplo, cem métodos de API são chamados 10 vezes por segundo e, digamos, quatro métodos de API são chamados 10 mil vezes por segundo. A ampliação de todo o sistema geralmente não é necessária, ou seja, é claro que podemos multiplicar todos os 100 métodos em muitos servidores, mas isso, via de regra, é visivelmente mais caro e mais complicado do que a ampliação de um grupo restrito de métodos. Podemos separar essas quatro chamadas em um serviço separado e escalá-lo apenas para um grande número de servidores.
Também está claro que podemos precisar de um microsserviço se tivermos escrito uma área funcional separada, por exemplo, em Python. Como algumas bibliotecas (por exemplo, para aprendizado de máquina) estavam disponíveis apenas no Python, e queremos separá-las em um serviço separado. Também faz sentido fazer um microsserviço se alguma parte do sistema estiver propensa a falhas. É bom, é claro, escrever código para que não haja falhas em princípio, mas os motivos podem ser externos. E ninguém está a salvo de seus próprios erros. Nesse caso, o bug pode ser isolado dentro de um processo separado.
Se o seu aplicativo não possui nenhuma das opções acima e não é esperado em um futuro próximo, provavelmente, um aplicativo monolítico será o mais adequado para você. A única coisa - eu recomendo escrever para que as áreas funcionais que não estão relacionadas uma à outra não dependam uma da outra no código. Para que, se necessário, áreas funcionais não interconectadas possam ser separadas umas das outras. No entanto, essa é sempre uma boa recomendação, seguida pela qual aumenta a consistência interna e ensina a formular cuidadosamente contratos de módulos.
Arquitetura reativa e programação reativa
Uma abordagem reativa é uma coisa relativamente nova. O momento de seu aparecimento pode ser considerado no ano de 2014, quando
o Manifesto Reativo foi publicado. Dois anos após a publicação do manifesto, ele era bem conhecido por todos. Essa é uma abordagem verdadeiramente revolucionária ao design do sistema. , , , , .
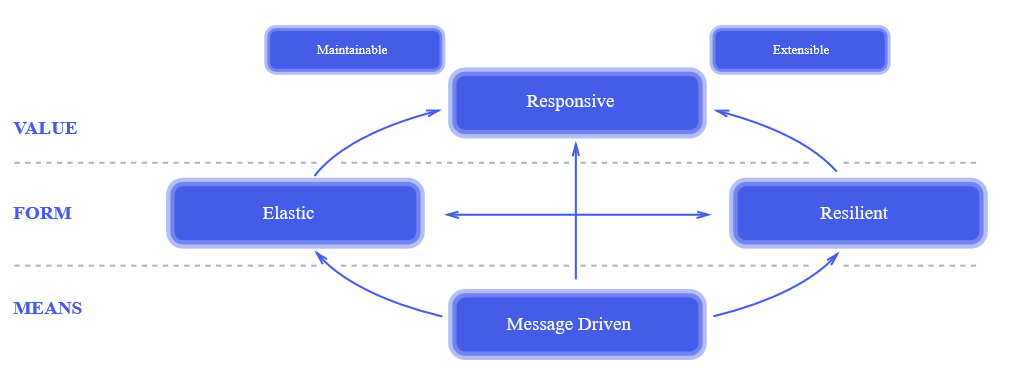
, . , , : « , !?» , , , , «». , 100% , , .
— , — . .
? , .
- , - . - -, , HTTP-. , . , . , , , .
? , HTTP- , ( callback) ( ) . , - ( , HTTP-) .
— . . . . 3 Ghz , , . . . , Java-, HTTP- — 5-10%. , , , , 100 50 $/ — $500 . , , .
, ? .
, . , , , , , , . , , . .
- . , JDBC ( . ADA, R2DBC, ). 90 % , . — HTTP- , . , .
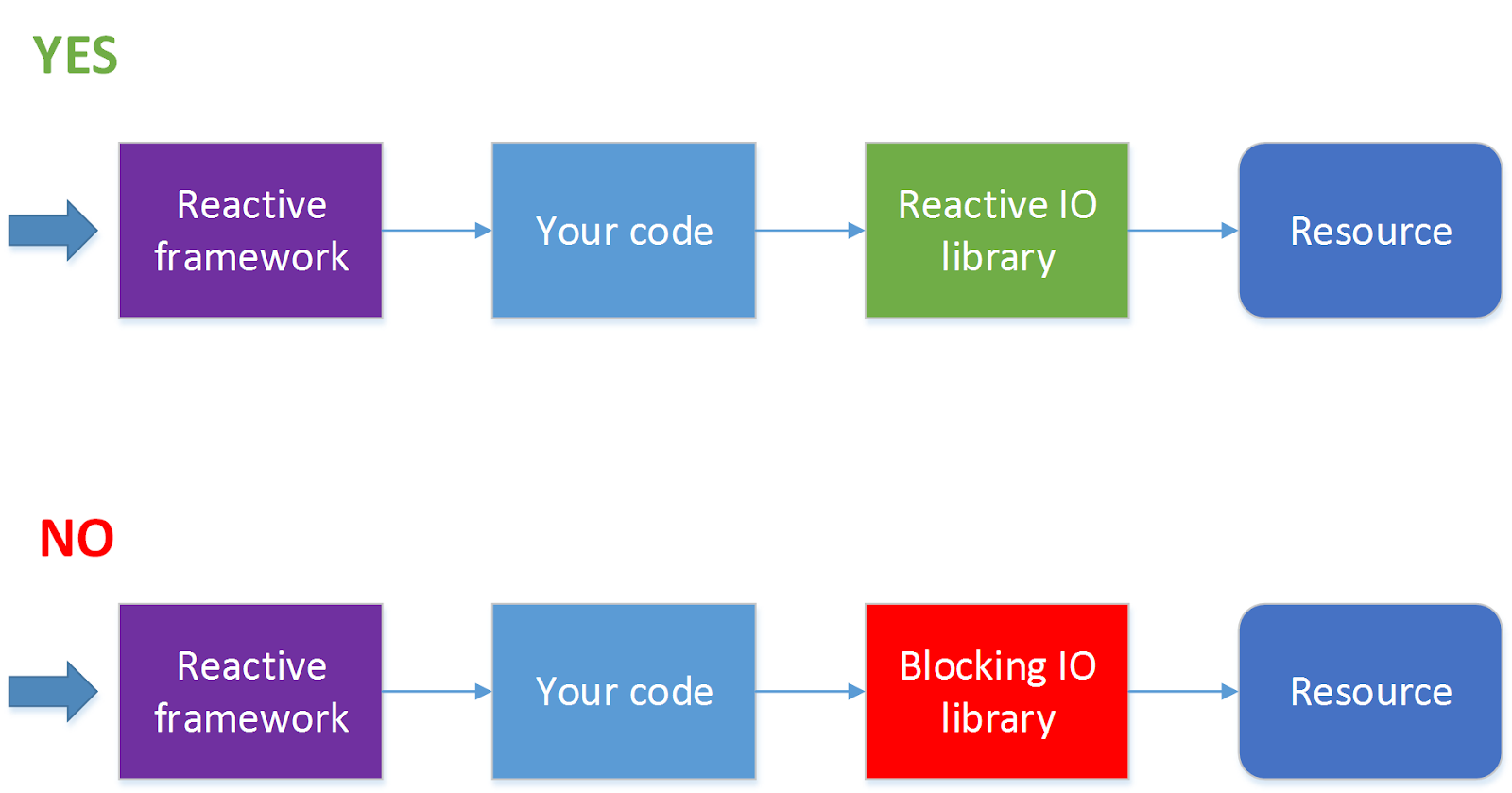
?
, , , ( ) . — - , . , , , HTTP.
, , , , , , .
. , « , » , , , . , , , 10 11 , , , .
Conclusão
, . , , , .