
O Guardian é um dos maiores jornais britânicos, foi fundado em 1821. Por quase 200 anos de existência, o arquivo acumulou uma quantia justa. Felizmente, nem tudo é armazenado no site - apenas nas últimas duas décadas. O banco de dados, que os próprios britânicos chamaram de "fonte da verdade" para todo o conteúdo online, contém cerca de 2,3 milhões de elementos. E, a certa altura, eles perceberam a necessidade de migrar do Mongo para o Postgres SQL - após um dia quente de julho de 2015, os procedimentos de failover foram severamente testados. A migração levou quase 3 anos! ..
Traduzimos
um artigo que descreve como foi o processo de migração e quais dificuldades os administradores enfrentaram. O processo é longo, mas o resumo é simples: resumindo-se à grande tarefa, reconcilie que serão necessários erros. Mas, no final, três anos depois, colegas britânicos conseguiram comemorar o fim da migração. E durma.
Parte Um: O Começo
No Guardian, a maior parte do conteúdo, incluindo artigos, blogs, galerias de fotos e vídeos, é produzida em nosso próprio CMS, Composer. Até recentemente, o Composer trabalhava com o Mongo DB da AWS. Esse banco de dados era essencialmente uma "fonte de verdade" para todo o conteúdo on-line do Guardian - cerca de 2,3 milhões de elementos. E acabamos de concluir a migração do Mongo para o Postgres SQL.
O Composer e seus bancos de dados foram originalmente hospedados na Guardian Cloud, um data center no porão de nosso escritório perto de Kings Cross, com failover em outros locais de Londres. Em um
dia quente de julho de 2015, nossos procedimentos de failover foram submetidos a um teste bastante severo.
 Calor: bom para dançar na fonte, desastroso para o data center. Foto: Sarah Lee / Guardião
Calor: bom para dançar na fonte, desastroso para o data center. Foto: Sarah Lee / GuardiãoDesde então, a migração do Guardian para a AWS se tornou uma questão de vida ou morte. Para migrar para a nuvem, decidimos comprar o
OpsManager , software de gerenciamento Mongo DB, e assinamos um contrato de suporte técnico Mongo. Usamos o OpsManager para gerenciar backups, orquestrar e monitorar nosso cluster de banco de dados.
Devido aos requisitos editoriais, precisamos iniciar o cluster de banco de dados e o OpsManager em nossa própria infraestrutura na AWS, e não usar a solução gerenciada Mongo. Tivemos que suar, pois o Mongo não forneceu nenhuma ferramenta para facilitar a configuração na AWS: projetamos manualmente toda a infraestrutura e escrevemos
centenas de scripts Ruby para instalar agentes de monitoramento / automação e orquestrar novas instâncias de banco de dados. Como resultado, tivemos que organizar uma equipe de programas educacionais sobre gerenciamento de banco de dados na equipe - o que esperávamos que o OpsManager assumisse.
Desde a transição para a AWS, tivemos duas falhas significativas devido a problemas no banco de dados, cada uma das quais não permitiu a publicação no theguardian.com por pelo menos uma hora. Nos dois casos, nem a equipe de suporte técnico da OpsManager nem a Mongo puderam nos fornecer assistência suficiente, e resolvemos o problema por conta própria - em um caso, graças a um
membro da nossa equipe que conseguiu lidar com a situação por telefone do deserto nos arredores de Abu Dhabi.
Cada uma das questões problemáticas merece um post separado, mas aqui estão os pontos gerais:
- Preste muita atenção ao tempo - não bloqueie o acesso ao seu VPC a tal ponto que o NTP pare de funcionar.
- Criar automaticamente índices de banco de dados na inicialização do aplicativo é uma má idéia.
- O gerenciamento de banco de dados é extremamente importante e difícil - e não queremos fazer isso sozinhos.
O OpsManager não cumpriu sua promessa de gerenciamento simples de banco de dados. Por exemplo, o gerenciamento real do próprio OpsManager - em particular, a atualização da versão 1 para a versão 2 do OpsManager - exigiu muito tempo e conhecimento especial sobre a configuração do OpsManager. Ele também não cumpriu sua promessa de "atualizações com um clique" devido a alterações no esquema de autenticação entre diferentes versões do Mongo DB. Perdemos pelo menos dois meses de engenheiros por ano gerenciando o banco de dados.
Todos esses problemas, combinados com a significativa taxa anual que pagamos pelo contrato de suporte e pelo OpsManager, nos forçaram a procurar uma opção alternativa de banco de dados com as seguintes características:
- Esforço mínimo para gerenciar o banco de dados.
- Criptografia em repouso.
- Um caminho de migração aceitável com o Mongo.
Como todos os nossos outros serviços executam a AWS, a escolha óbvia é Dynamo, o banco de dados NoSQL da Amazon. Infelizmente, no momento, o Dynamo não suportava criptografia em repouso. Depois de esperar cerca de nove meses para que esse recurso fosse adicionado, acabamos abandonando essa ideia, decidindo usar o Postgres no AWS RDS.
"Mas o Postgres não é um repositório de documentos!" - você está indignado ... Bem, sim, este não é um repositório dock, mas possui tabelas semelhantes às colunas JSONB, com suporte para índices nos campos da ferramenta JSON Blob. Esperávamos que, usando JSONB, pudéssemos migrar do Mongo para o Postgres com alterações mínimas em nosso modelo de dados. Além disso, se quiséssemos mudar para um modelo mais relacional no futuro, teríamos essa oportunidade. Outra grande coisa sobre o Postgres é como ele funcionou: para todas as perguntas que tivemos, na maioria dos casos, a resposta já foi dada no Stack Overflow.
Em termos de desempenho, tínhamos certeza de que o Postgres poderia fazê-lo: o Composer é uma ferramenta exclusiva para gravar conteúdo (grava no banco de dados toda vez que um jornalista para de imprimir) e, geralmente, o número de usuários simultâneos não excede várias centenas - o que não requer um sistema super alta potência!
Parte dois: a migração de conteúdo de duas décadas passou sem tempo de inatividade
PlanejarA maioria das migrações de banco de dados implica as mesmas ações, e a nossa não foi exceção. Aqui está o que fizemos:
- Criou um novo banco de dados.
- Eles criaram uma maneira de gravar em um novo banco de dados (nova API).
- Criamos um servidor proxy que envia tráfego para o banco de dados antigo e o novo, usando o antigo como principal.
- Registros movidos do banco de dados antigo para o novo.
- Eles fizeram do novo banco de dados o principal.
- Removido o banco de dados antigo.
Como o banco de dados para o qual migramos fornecia o funcionamento do nosso CMS, era fundamental que a migração causasse o mínimo de problemas possível para nossos jornalistas. No final, as notícias nunca terminam.
Nova APIO trabalho na nova API baseada no Postgres começou no final de julho de 2017. Este foi o começo de nossa jornada. Mas, para entender como era, precisamos primeiro esclarecer por onde começamos.
Nossa arquitetura simplificada do CMS era mais ou menos assim: um banco de dados, uma API e vários aplicativos relacionados a ele (como uma interface do usuário). A pilha foi construída e, há 4 anos, opera com base no
Scala ,
Scalatra Framework e
Angular.js .
Após algumas análises, chegamos à conclusão de que, antes de podermos migrar o conteúdo existente, precisamos de uma maneira de entrar em contato com o novo banco de dados PostgreSQL, mantendo a antiga API operacional. Afinal, o Mongo DB é a nossa "fonte da verdade". Ela nos serviu como uma tábua de salvação enquanto experimentávamos a nova API.
Essa é uma das razões pelas quais construir sobre a API antiga não fazia parte de nossos planos. A separação de funções na API original era mínima, e os métodos específicos necessários para trabalhar especificamente com o Mongo DB podiam ser encontrados mesmo no nível do controlador. Como resultado, a tarefa de adicionar outro tipo de banco de dados a uma API existente era muito arriscada.
Fomos para o outro lado e duplicamos a API antiga. Assim nasceu o APIV2. Era uma cópia mais ou menos exata da antiga API relacionada ao Mongo e incluía os mesmos pontos de extremidade e funcionalidade. Usamos o
doobie , a camada de recursos JDBC pura para Scala, adicionamos o
Docker para executar e testar localmente e aprimoramos o registro de operações e o compartilhamento de responsabilidades. O APIV2 deveria ser uma versão rápida e moderna da API.
Até o final de agosto de 2017, implantamos uma nova API que usava o PostgreSQL como banco de dados. Mas isso foi apenas o começo. Existem artigos no Mongo DB que foram criados há mais de duas décadas e todos tiveram que migrar para o banco de dados Postgres.
A migraçãoDeveríamos poder editar qualquer artigo no site, independentemente de quando ele foi publicado, portanto, todos os artigos existem em nosso banco de dados como uma única "fonte de verdade".
Embora todos os artigos estejam na
API de conteúdo do Guardian (CAPI) , que atende aos aplicativos e ao site, era extremamente importante migrar sem falhas, pois nosso banco de dados é a nossa “fonte de verdade”. Se algo acontecesse com o cluster Elasticsearch CAPI, nós o reindexaríamos do banco de dados do Composer.
Portanto, antes de desativar o Mongo, tivemos que garantir que a mesma solicitação para a API executada no Postgres e a API executada no Mongo retornasse respostas idênticas.
Para fazer isso, precisamos copiar todo o conteúdo no novo banco de dados do Postgres. Isso foi feito usando um script que interagiu diretamente com as APIs novas e antigas. A vantagem desse método era que as duas APIs já forneciam uma interface bem testada para ler e escrever artigos dentro e fora dos bancos de dados, em vez de escrever algo que acessasse diretamente os respectivos bancos de dados.
A ordem básica de migração foi a seguinte:
- Obtenha conteúdo do Mongo.
- Poste conteúdo no Postgres.
- Obtenha conteúdo do Postgres.
- Verifique se as respostas são idênticas.
A migração do banco de dados pode ser considerada bem-sucedida apenas se os usuários finais não perceberem que isso aconteceu e um bom script de migração sempre será a chave para esse sucesso. Precisávamos de um script que pudesse:
- Execute solicitações HTTP.
- Certifique-se de que, após migrar parte do conteúdo, a resposta das duas APIs seja a mesma.
- Pare quando ocorrer um erro.
- Crie um log de operação detalhado para diagnosticar problemas.
- Reinicie após um erro do ponto correto.
Começamos usando
amonita . Ele permite que você escreva scripts na linguagem Scala, que é o núcleo da nossa equipe. Foi uma boa oportunidade para experimentar algo que não tínhamos usado antes para ver se seria útil para nós. Embora a amonita nos permitisse usar uma linguagem familiar, encontramos várias deficiências ao trabalhar nela. Atualmente, a Intellij
suporta amonita, mas não o fez durante a migração - e perdemos a conclusão automática e a importação automática. Além disso, por um longo período de tempo, o script amonita falhou em ser executado.
Por fim, o Amonite não era a ferramenta certa para esse trabalho e, em vez disso, usamos o projeto sbt para fazer a migração. Isso nos permitiu trabalhar em um idioma em que estávamos confiantes, além de executar várias 'migrações de teste' antes de iniciar no ambiente de trabalho principal.
Inesperado foi o quão útil foi verificar a versão da API em execução no Postgres. Encontramos vários erros difíceis de encontrar e casos limitantes que não encontramos anteriormente.
Avance para janeiro de 2018, quando é hora de testar a migração completa em nosso ambiente de código pré-prod.
Como a maioria dos nossos sistemas, a única semelhança entre CODE e PROD é a versão do aplicativo que está sendo lançada. A infraestrutura da AWS que suporta o CODE era muito menos poderosa que o PROD, simplesmente porque ela recebe muito menos carga de trabalho.
Esperávamos que a migração de teste no ambiente CODE nos ajudasse:
- Estime quanto tempo a migração levará no ambiente do PROD.
- Avalie como (se é que existe) a migração afeta a produtividade.
Para obter medições precisas desses indicadores, tivemos que trazer os dois ambientes em completa correspondência mútua. Isso incluiu a restauração de um backup do Mongo DB do PROD para o CODE e a atualização da infraestrutura suportada pela AWS.
A migração de pouco mais de 2 milhões de itens de dados deveria levar muito mais tempo do que um dia útil padrão permitiria. Portanto, executamos o script na
tela para a noite.
Para medir o progresso da migração, enviamos consultas estruturadas (usando tokens) para nossa pilha ELK (Elasticsearch, Logstash e Kibana). A partir daí, poderíamos criar painéis detalhados rastreando o número de artigos transferidos com sucesso, o número de falhas e o progresso geral. Além disso, todos os indicadores foram exibidos na tela grande para que toda a equipe pudesse ver os detalhes.
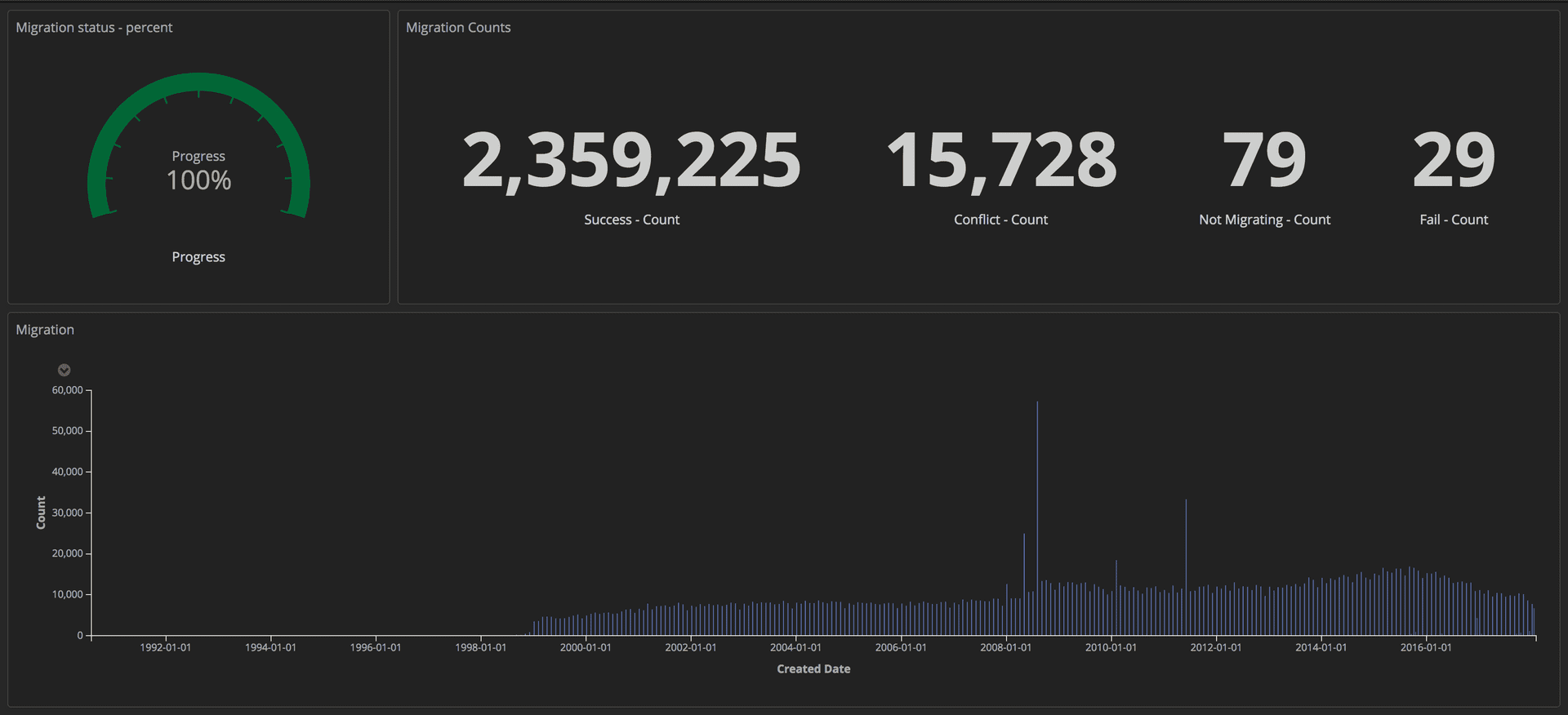 Painel mostrando o andamento da migração: Editorial Tools / Guardian
Painel mostrando o andamento da migração: Editorial Tools / GuardianDepois que a migração foi concluída, verificamos uma correspondência para cada documento no Postgres e no Mongo.
Parte Três: Proxies e Lançamento no Prod
ProxiesAgora que a nova API em execução no Postgres foi lançada, precisávamos testá-la com padrões reais de tráfego e acesso a dados para garantir sua confiabilidade e estabilidade. Havia duas maneiras possíveis de fazer isso: atualizar cada cliente que acessa a API do Mongo para acessar as duas APIs; ou execute um proxy que fará isso por nós. Escrevemos proxies no Scala usando o
Akka Streams .
O proxy era bastante simples:
- Receba tráfego do balanceador de carga.
- Redirecione o tráfego para a API principal e vice-versa.
- Encaminhe o mesmo tráfego de forma assíncrona para uma API adicional.
- Calcule as discrepâncias entre as duas respostas e registre-as em um log.
Inicialmente, o proxy registrou muitas discrepâncias, incluindo algumas diferenças comportamentais difíceis de encontrar, mas importantes nas duas APIs que precisavam ser corrigidas.
Registro EstruturadoNo Guardian, registramos usando a pilha
ELK (Elasticsearch, Logstash e Kibana). O uso do Kibana nos deu a oportunidade de visualizar a revista da maneira mais conveniente para nós. O Kibana usa
a sintaxe de consulta do Lucene , que é bastante fácil de aprender. Mas logo percebemos que era impossível filtrar ou agrupar os lançamentos contábeis manuais na configuração atual. Por exemplo, não conseguimos filtrar os que foram enviados como resultado de solicitações GET.
Decidimos enviar dados mais estruturados para o Kibana, não apenas mensagens. Uma entrada de log contém vários campos, por exemplo, o carimbo de data e hora e o nome da pilha ou aplicativo que enviou a solicitação. Adicionar novos campos é muito fácil. Esses campos estruturados são chamados de marcadores e podem ser implementados usando a
biblioteca logstash-logback-encoder . Para cada solicitação, extraímos informações úteis (por exemplo, rota, método, código de status) e criamos um mapa com informações adicionais necessárias para o log. Aqui está um exemplo:
import akka.http.scaladsl.model.HttpRequest import ch.qos.logback.classic.{Logger => LogbackLogger} import net.logstash.logback.marker.Markers import org.slf4j.{LoggerFactory, Logger => SLFLogger} import scala.collection.JavaConverters._ object Logging { val rootLogger: LogbackLogger = LoggerFactory.getLogger(SLFLogger.ROOT_LOGGER_NAME).asInstanceOf[LogbackLogger] private def setMarkers(request: HttpRequest) = { val markers = Map( "path" -> request.uri.path.toString(), "method" -> request.method.value ) Markers.appendEntries(markers.asJava) } def infoWithMarkers(message: String, akkaRequest: HttpRequest) = rootLogger.info(setMarkers(akkaRequest), message) }
Campos adicionais em nossos logs nos permitiram criar painéis informativos e adicionar mais contexto às discrepâncias, o que nos ajudou a identificar algumas inconsistências menores entre as duas APIs.
Replicação de tráfego e refatoração de proxyDepois de transferir o conteúdo para o banco de dados CODE, obtivemos uma cópia quase exata do banco de dados PROD. A principal diferença era que o CODE não tinha tráfego. Para replicar o tráfego real no ambiente CODE, usamos a ferramenta de código aberto
GoReplay (a seguir
denominada gor). É muito fácil de instalar e flexível para personalizar de acordo com seus requisitos.
Como todo o tráfego que chegava às nossas APIs era destinado a proxies, fazia sentido instalar o gor em contêineres proxy. Veja abaixo como carregar o gor no seu contêiner e como começar a monitorar o tráfego na porta 80 e enviá-lo para outro servidor.
wget https://github.com/buger/goreplay/releases/download/v0.16.0.2/gor_0.16.0_x64.tar.gz tar -xzf gor_0.16.0_x64.tar.gz gor sudo gor --input-raw :80 --output-http http://apiv2.code.co.uk
Por um tempo, tudo funcionou bem, mas logo houve um mau funcionamento quando o proxy ficou indisponível por vários minutos. Na análise, descobrimos que todos os três contêineres proxy eram suspensos periodicamente ao mesmo tempo. A princípio, pensamos que o proxy estava travando porque o gor estava usando muitos recursos. Após uma análise mais aprofundada do console da AWS, descobrimos que os contêineres de proxy penduravam regularmente, mas não ao mesmo tempo.
Antes de nos aprofundarmos mais no problema, tentamos encontrar uma maneira de executar o gor, mas desta vez sem carga adicional no proxy. A solução veio da nossa pilha secundária para o Composer. Essa pilha é usada apenas em caso de emergência e nossa
ferramenta de monitoramento de trabalho a testa constantemente. Dessa vez, a reprodução do tráfego dessa pilha para o CODE em velocidade dupla funcionou sem problemas.
Novas descobertas levantaram muitas questões. O proxy foi criado como uma ferramenta temporária, portanto, pode não ter sido tão cuidadosamente projetado quanto outros aplicativos. Além disso, ele foi construído usando o
Akka Http , com o qual ninguém da nossa equipe estava familiarizada. O código estava confuso e cheio de correções rápidas. Decidimos iniciar muitas refatorações para melhorar a legibilidade. Desta vez, usamos geradores for, em vez da crescente lógica aninhada que usamos antes. E adicionou ainda mais marcadores de log.
Esperávamos que seríamos capazes de impedir que os contêineres proxy congelassem se entrássemos em detalhes do que estava acontecendo dentro do sistema e simplificássemos a lógica de sua operação. Mas isso não funcionou. Depois de duas semanas tentando tornar o proxy mais confiável, nos sentimos presos. Era necessário tomar uma decisão. Decidimos correr o risco e deixar o proxy como está, pois é melhor dedicar tempo à migração do que tentar consertar um software que se tornará desnecessário em um mês. Pagamos por essa solução com mais duas falhas - quase dois minutos cada -, mas isso tinha que ser feito.
Avance para março de 2018, quando já concluímos a migração para o CODE sem sacrificar o desempenho da API ou a experiência do cliente no CMS. Agora poderíamos começar a pensar em anular proxies do CODE.
O primeiro passo foi alterar as prioridades da API para que o proxy interagisse primeiro com o Postgres. Como dissemos acima, isso foi decidido por uma alteração nas configurações. No entanto, houve uma dificuldade.
O compositor envia mensagens para o fluxo Kinesis após atualizar o documento. Apenas uma API precisava enviar mensagens para evitar duplicação. Para isso, as APIs têm um sinalizador na configuração: true para a API suportada pelo Mongo e false para o Postgres suportado. Simplesmente alterar o proxy para interagir primeiro com o Postgres não foi suficiente, pois a mensagem não seria enviada ao fluxo do Kinesis até que a solicitação chegasse ao Mongo. Já faz muito tempo.
Para resolver esse problema, criamos pontos de extremidade HTTP para alterar instantaneamente a configuração de todas as instâncias do balanceador de carga em tempo real. Isso nos permitiu conectar a API principal muito rapidamente, sem a necessidade de editar o arquivo de configuração e reimplementar. Além disso, isso pode ser automatizado, reduzindo a interação humana e a probabilidade de erros.
Agora, todas as solicitações foram enviadas primeiro ao Postgres e a API2 interagiu com o Kinesis. As substituições podem se tornar permanentes com alterações de configuração e reimplementação.
A próxima etapa foi remover completamente o proxy e forçar os clientes a acessar exclusivamente a API do Postgres. Como temos muitos clientes, não foi possível atualizar cada um deles individualmente. Portanto, elevamos essa tarefa ao nível do DNS. Ou seja, criamos um CNAME no DNS que primeiro apontava para o proxy ELB e mudava para apontar para a API ELB. Isso permitiu que uma única alteração fosse feita em vez de atualizar cada cliente API individual.
É hora de mudar o PROD. Embora tenha sido um pouco assustador, bem, porque este é o principal ambiente de trabalho. O processo foi relativamente simples, pois tudo foi decidido alterando as configurações. Além disso, à medida que um marcador de estágio foi adicionado aos logs, tornou-se possível re-criar um perfil dos painéis construídos anteriormente, simplesmente atualizando o filtro Kibana.
Desativando proxies e Mongo DBApós 10 meses e 2,4 milhões de artigos migrados, finalmente conseguimos desativar toda a infraestrutura relacionada ao Mongo. Mas primeiro, tivemos que fazer o que estávamos esperando: matar o proxy.
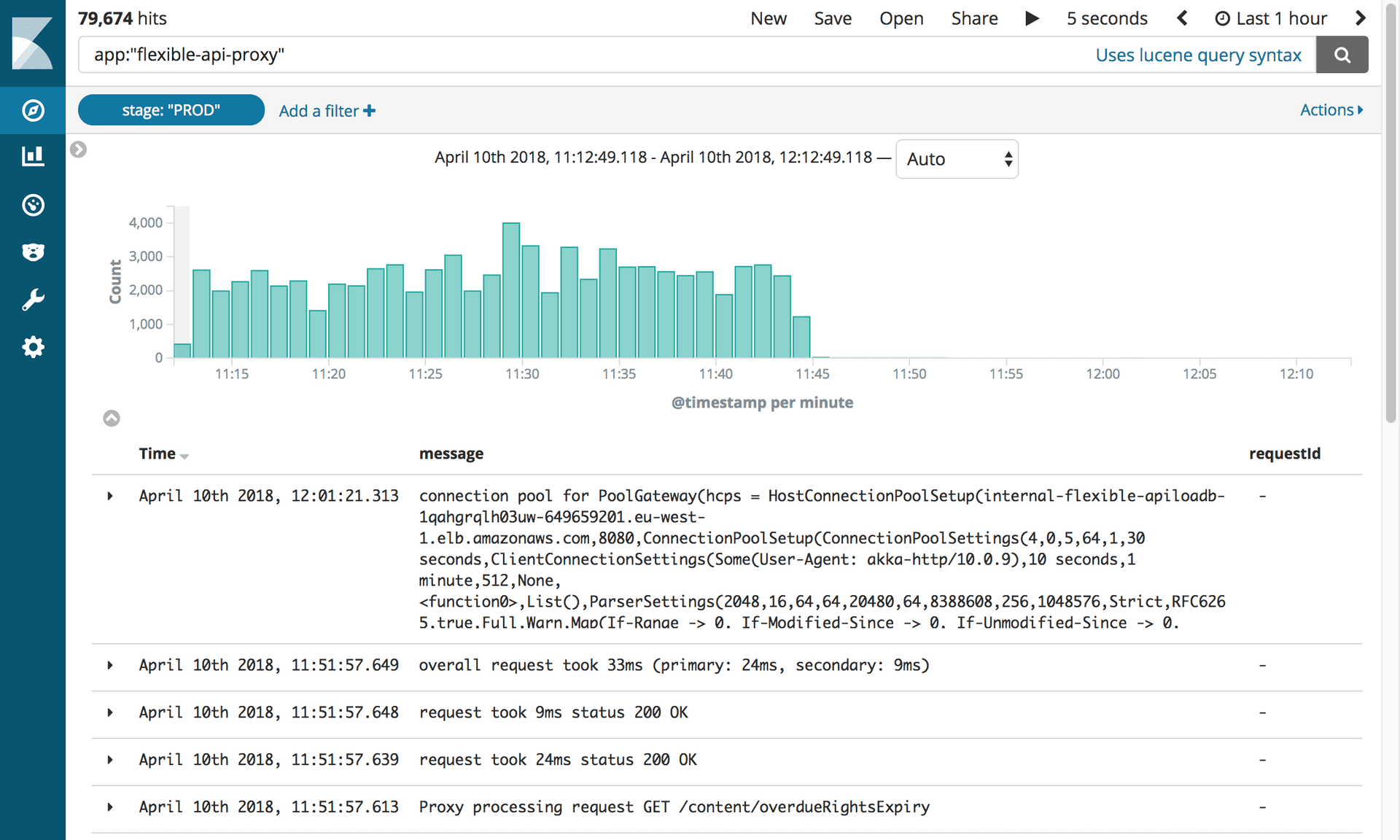 Logs mostrando a desativação do proxy flexível da API. Fotografia: Editorial Tools / Guardian
Logs mostrando a desativação do proxy flexível da API. Fotografia: Editorial Tools / GuardianEsse pequeno software nos causou tantos problemas que ansiamos por desconectá-lo em breve! Tudo o que tivemos que fazer foi atualizar o registro CNAME para apontar diretamente para o balanceador de carga APIV2.
Toda a equipe se reuniu em torno de um computador. Era necessário pressionar apenas uma tecla. Todo mundo prendeu a respiração! Silêncio completo ... Clique! O trabalho está feito. E nada voou! Todos nós exalamos alegremente.
No entanto, a remoção da antiga API do Mongo DB foi repleta de mais um teste. Desesperados para remover o código antigo, descobrimos que nossos testes de integração nunca foram ajustados para usar a nova API. Tudo rapidamente ficou vermelho. Felizmente, a maioria dos problemas estava relacionada à configuração e os corrigimos facilmente. Houve vários problemas com as consultas do PostgreSQL que foram detectados pelos testes. Pensando no que poderia ser feito para evitar esse erro, aprendemos uma lição: ao iniciar uma grande tarefa, reconcilie que haverá erros.
Depois disso, tudo funcionou sem problemas. Desconectamos todas as instâncias do Mongo do OpsManager e depois as desconectamos. A única coisa que faltava fazer era comemorar. E durma.