Sou Engenheiro Líder de DevOps no Miro (ex-RealtimeBoard). Compartilharei como nossa equipe de DevOps resolveu o problema de lançamentos diários de servidores de um aplicativo com estado monolítico e os tornou automáticos, invisíveis para os usuários e convenientes para seus próprios desenvolvedores.
Nossa infraestrutura
Nossa equipe de desenvolvimento é composta por 60 pessoas, divididas em equipes Scrum, entre as quais também há a equipe DevOps. A maioria dos comandos do Scrum suporta a funcionalidade atual do produto e apresenta novos recursos. A tarefa do DevOps é criar e manter uma infraestrutura que ajude o aplicativo a trabalhar de maneira rápida e confiável e permita que as equipes entreguem rapidamente novas funcionalidades aos usuários.

Nossa aplicação é uma placa on-line sem fim. Consiste em três camadas: um site, um cliente e um servidor em Java, que é um aplicativo com estado monolítico. O aplicativo mantém uma conexão constante de soquete da Web com os clientes, e cada servidor mantém na memória um cache de placas abertas.
Toda a infraestrutura - mais de 70 servidores - está localizada na Amazon: mais de 30 servidores com nosso aplicativo Java, servidores Web, servidores de banco de dados, corretores e muito mais. Com o crescimento da funcionalidade, tudo isso deve ser atualizado regularmente, sem interromper o trabalho dos usuários.
A atualização do site e do cliente é simples: substituímos a versão antiga por uma nova e, na próxima vez em que o usuário acessar um novo site e um novo cliente. Mas se fizermos isso quando o servidor for lançado, obteremos tempo de inatividade. Para nós, isso é inaceitável, porque o principal valor do nosso produto é o trabalho conjunto dos usuários em tempo real.
Como é o nosso processo de CI / CD
O processo de CI / CD conosco é git commit, git push e, em seguida, montagem automática, auto-teste, implantação, liberação e monitoramento.
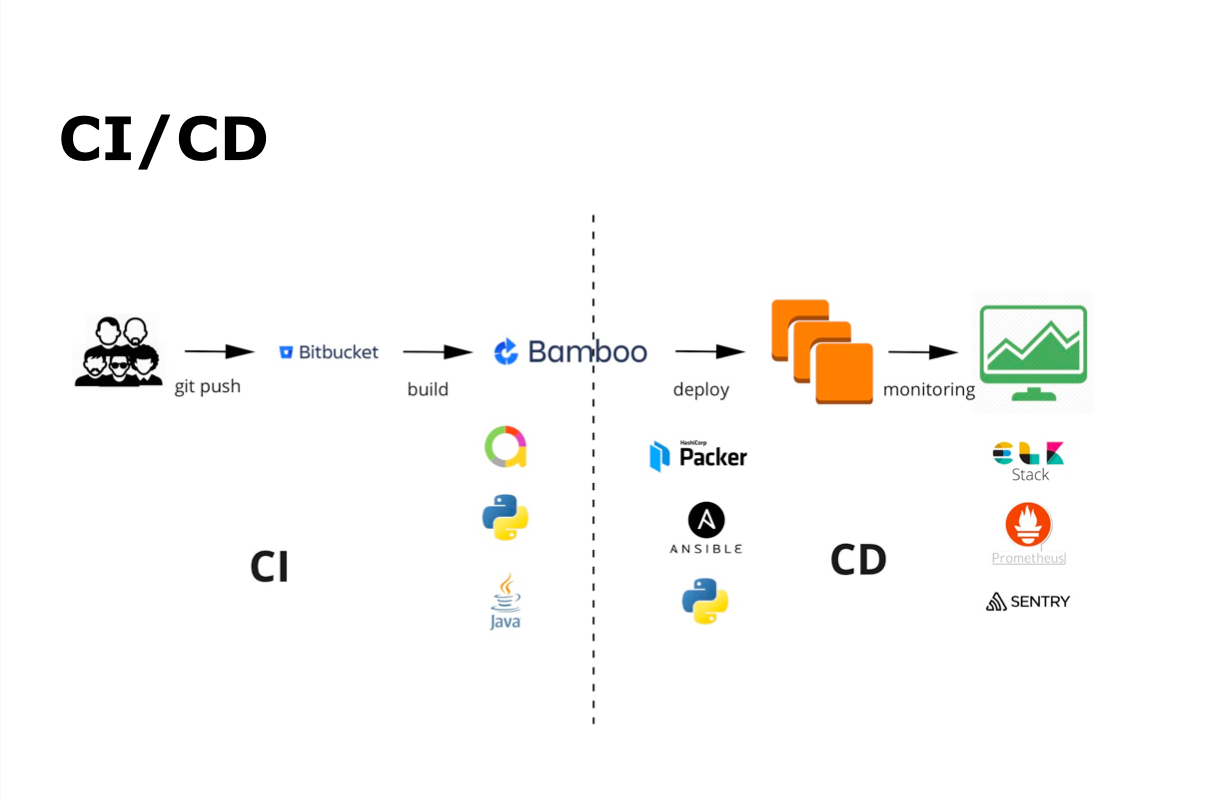
Para integração contínua, usamos Bamboo e Bitbucket. Para teste automático - Java e Python e Allure - para exibir os resultados do teste automático. Para entrega contínua - Packer, Ansible e Python. Todo o monitoramento é feito usando o ELK Stack, Prometheus e Sentry.
Os desenvolvedores escrevem código e o adicionam ao repositório, após o qual a montagem e o teste automáticos são iniciados. Ao mesmo tempo, a equipe se reúne de outros desenvolvedores e conduz a Revisão de Código. Quando todos os processos necessários, incluindo os autotestes, foram concluídos, a equipe mantém a compilação no ramo principal e o processo começa e é enviado para teste automático. Todo o processo é depurado e executado pela equipe por conta própria.
Imagem AMI
Paralelamente à compilação e teste de compilação, é iniciada a compilação da imagem AMI para Amazon. Para fazer isso, usamos o Packer da HashiCorp, uma ótima ferramenta de código-fonte aberto que permite criar uma imagem de uma máquina virtual. Todos os parâmetros são passados para JSON com um conjunto de chaves de configuração. O parâmetro principal é construtores, que indica para qual provedor estamos criando a imagem (no nosso caso, para a Amazon).
"builders": [{ "type": "amazon-ebs", "access_key": "{{user `aws_access_key`}}", "secret_key": "{{user `aws_secret_key`}}", "region": "{{user `aws_region`}}", "vpc_id": "{{user `aws_vpc`}}", "subnet_id": "{{user `aws_subnet`}}", "tags": { "releaseVersion": "{{user `release_version`}}" }, "instance_type": "t2.micro", "ssh_username": "ubuntu", "ami_name": "packer-board-ami_{{isotime \"2006-01-02_15-04\"}}" }],
É importante não apenas criar uma imagem de uma máquina virtual, mas configurá-la com antecedência usando o Ansible: instale os pacotes necessários e faça as definições de configuração para executar um aplicativo Java.
"provisioners": [{ "type": "ansible", "playbook_file": "./playbook.yml", "user": "ubuntu", "host_alias": "default", "extra_arguments": ["--extra_vars=vars"], "ansible_env_vars": ["ANSIBLE_HOST_KEY_CHECKING=False", "ANSIBLE_NOCOLOR=True"] }]
Papéis possíveis
Costumávamos usar o manual normal do Ansible, mas isso levou a muitos códigos repetitivos, que se tornaram difíceis de manter atualizados. Mudamos algo em um manual, esquecemos de fazer em outro e, como resultado, tivemos problemas. Então começamos a usar papéis Ansible. Nós os tornamos o mais versátil possível, para podermos reutilizá-los em diferentes partes do projeto e não sobrecarregar o código em grandes partes repetidas. Por exemplo, usamos a função Monitoramento para todos os tipos de servidores.
- name: Install all board dependencies hosts: all user: ubuntu become: yes roles: - java - nginx - board-application - ssl-certificates - monitoring
Do lado das equipes Scrum, esse processo parece o mais simples possível: a equipe recebe no Slack notificações de que a compilação e a imagem AMI estão montadas.
Pré-lançamentos
Introduzimos pré-lançamentos para fornecer alterações de produtos aos usuários o mais rápido possível. De fato, são versões canárias que permitem testar com segurança novas funcionalidades em uma pequena porcentagem de usuários.
Por que os lançamentos são chamados canary? Anteriormente, os mineiros, quando desciam na mina, levavam um canário com eles. Se havia gás na mina, o canário morria e os mineiros rapidamente subiam à superfície. O mesmo acontece conosco: se algo der errado com o servidor, o lançamento não está pronto e podemos reverter rapidamente e a maioria dos usuários não notará nada.
Como começa a liberação do canário:- A equipe de desenvolvimento da Bamboo clica em um botão -> é chamado um aplicativo Python que inicia o pré-lançamento.
- Ele cria uma nova instância no Amazon a partir de uma imagem AMI pré-preparada com uma nova versão do aplicativo.
- A instância é adicionada aos grupos-alvo e balanceadores de carga necessários.
- Com o Ansible, uma configuração individual é configurada para cada instância.
- Os usuários estão trabalhando com a nova versão do aplicativo Java.
No lado dos comandos do Scrum, o processo de lançamento de pré-lançamento parece mais simples possível: a equipe recebe no Slack notificações de que o processo foi iniciado e, após 7 minutos, o novo servidor já está em operação. Além disso, o aplicativo envia ao Slack todo o registro de alterações das alterações na versão.
Para que essa barreira de verificação de proteção e confiabilidade funcione, as equipes do Scrum monitoram novos erros no Sentry. Este é um aplicativo de rastreamento de erros de código aberto em tempo real. O Sentry se integra perfeitamente ao Java e possui conectores com logback e log2j. Quando o aplicativo é iniciado, transferimos para o Sentry a versão em que está sendo executado e, quando ocorre um erro, vemos em qual versão do aplicativo ocorreu. Isso ajuda as equipes do Scrum a responder rapidamente aos erros e corrigi-los rapidamente.
O pré-lançamento deve funcionar por pelo menos 4 horas. Durante esse período, a equipe monitora seu trabalho e decide se deve liberar a versão para todos os usuários.
Várias equipes podem lançar simultaneamente seus lançamentos . Para fazer isso, eles concordam entre si o que entra no pré-lançamento e quem é o responsável pelo lançamento final. Depois disso, as equipes combinam todas as alterações em um pré-lançamento ou lançam vários pré-lançamentos ao mesmo tempo. Se todos os pré-lançamentos estiverem corretos, eles serão lançados como um lançamento no dia seguinte.
Lançamentos
Fazemos um lançamento diário:
- Introduzimos novos servidores para funcionar.
- Monitoramos a atividade do usuário em novos servidores usando o Prometheus.
- Feche o acesso de novos usuários a servidores antigos.
- Transferimos usuários de servidores antigos para novos.
- Desligue o servidor antigo.
Tudo é construído usando os aplicativos Bamboo e Python. O aplicativo verifica o número de servidores em execução e se prepara para iniciar o mesmo número de novos. Se não houver servidores suficientes, eles serão criados a partir da imagem AMI. Uma nova versão é implementada neles, um aplicativo Java é iniciado e os servidores são colocados em operação.
Ao monitorar, o aplicativo Python usando a API do Prometheus verifica o número de placas abertas em novos servidores. Quando entende que tudo está funcionando corretamente, fecha o acesso aos servidores antigos e transfere os usuários para os novos.
import requests PROMETHEUS_URL = 'https://prometheus' def get_spaces_count(): boards = {} try: params = { 'query': 'rtb_spaces_count{instance=~"board.*"}' } response = requests.get(PROMETHEUS_URL, params=params) for metric in response.json()['data']['result']: boards[metric['metric']['instance']] = metric['value'][1] except requests.exceptions.RequestException as e: print('requests.exceptions.RequestException: {}'.format(e)) finally: return boards
O processo de transferência de usuários entre servidores é exibido no Grafana. Na metade esquerda do gráfico, os servidores em execução na versão antiga são exibidos, à direita - na nova. A interseção de gráficos é o momento da transferência do usuário.

A equipe supervisiona o lançamento do Slack. Após o lançamento, todo o registro de alterações é publicado em um canal separado no Slack, e no Jira todas as tarefas associadas a este lançamento são fechadas automaticamente.
O que é migração de usuários
Armazenamos o estado do quadro branco no qual os usuários trabalham, na memória do aplicativo e salvamos constantemente todas as alterações no banco de dados. Para transferir a placa no nível de interação do cluster, nós a carregamos na memória no novo servidor e enviamos ao cliente um comando para reconectar. Nesse ponto, o cliente se desconecta do servidor antigo e se conecta ao novo. Após alguns segundos, os usuários veem a inscrição - Conexão restaurada. No entanto, eles continuam a trabalhar e não percebem nenhum inconveniente.
O que aprendemos ao tornar a implantação invisível
A que chegamos depois de uma dúzia de iterações:
- A equipe scrum verifica seu próprio código.
- A equipe scrum decide quando iniciar o pré-lançamento e trazer algumas das mudanças para novos usuários.
- A equipe Scrum decide se seu lançamento está pronto para ser usado por todos os usuários.
- Os usuários continuam trabalhando e não percebem nada.
Isso não foi possível imediatamente, pisamos no mesmo rake várias vezes e enchemos muitos cones. Quero compartilhar as lições que recebemos.
Primeiro, o processo manual, e somente então sua automação. Os primeiros passos não precisam se aprofundar na automação, porque você pode automatizar o que no final não é útil.
Ansible é bom, mas os papéis Ansible são melhores. Tornamos nossos papéis o mais universal possível: nos livramos do código repetitivo, de modo que eles carregam apenas a funcionalidade que deveriam. Isso permite que você economize tempo reutilizando funções, que já temos mais de 50.
Reutilize o código no Python e divida-o em bibliotecas e módulos separados. Isso ajuda você a navegar em projetos complexos e a mergulhar rapidamente novas pessoas neles.
Próximas etapas
O processo de implantação invisível ainda não acabou. Aqui estão algumas das seguintes etapas:
- Permita que as equipes concluam não apenas os pré-lançamentos, mas todos os lançamentos.
- Faça reversões automáticas em caso de erros. Por exemplo, um pré-lançamento deve reverter automaticamente se erros críticos forem detectados no Sentry.
- Automatize totalmente a versão na ausência de erros. Se não houver erros no pré-lançamento, isso significa que ele pode ser implementado automaticamente.
- Adicione verificação automática de código para possíveis erros de segurança.