Olá Habr! Depois de descansar o suficiente após longas férias, estamos novamente prontos para fazer o bem em todas as formas disponíveis. Os colegas do departamento de TI sempre têm algo a dizer e hoje estamos compartilhando com você um relatório de Alexander Prizov, administrador do sistema Yandex.Money, da mitap JavaJam.
Como criamos um fluxo de feedback para detectar lançamentos de problemas usando o Graphite e o Moira. Mostraremos como coletar e analisar métricas sobre o número de erros no aplicativo.
- Olá pessoal, meu nome é Alexander Prizov, trabalho no departamento de automação de operações na Yandex.Money, e hoje vou falar sobre como coletamos, processamos, analisamos informações sobre nosso sistema.
Você provavelmente deve ter se perguntado por que o relatório é chamado de Segunda Via (o nome do relatório na reunião é ed.). Tudo é bem simples. No coração do DevOps há vários princípios que são condicionalmente divididos em três grupos.
A primeira maneira é o princípio do fluxo. A segunda maneira envolve o princípio do feedback. A terceira maneira é a aprendizagem e experimentação contínuas.
Como regra, em termos de desenvolvimento e operação de produtos de software, feedback significa telemetria, que coletamos sobre o nosso sistema, e o caso mais comum é a coleta e o processamento de métricas.
Por que precisamos dessas métricas? Com a ajuda das métricas, obtemos feedback do sistema e podemos saber em que estado nosso sistema está, se tudo está indo bem, como nossas alterações afetaram sua operação e se é necessária alguma intervenção para resolver determinados problemas.
Quais métricas coletamos?
Coletamos métricas de três níveis.
O nível de negócios inclui indicadores que são interessantes do ponto de vista de qualquer tarefa de negócios. Por exemplo, podemos obter respostas para perguntas como quantos usuários registramos, com que frequência os usuários efetuam login no nosso sistema, quantos usuários ativos nosso aplicativo móvel possui.
O próximo nível é o nível do aplicativo . As métricas desse nível costumam ser visualizadas pelos desenvolvedores, porque esses indicadores respondem à pergunta de quão bem nosso aplicativo funciona, com que rapidez ele processa solicitações, existem desvantagens no desempenho. Isso inclui tempo de resposta, número de solicitações, comprimento da fila e muito mais.
E, finalmente, o nível de infraestrutura . Tudo está muito claro aqui. Usando essas métricas, podemos estimar a quantidade de recursos consumidos, como prever e identificar problemas relacionados à infraestrutura.
Agora, em poucas palavras, descreverei como enviamos, processamos e onde armazenamos essas métricas. Ao lado do aplicativo, temos um coletor de métricas. No nosso caso, este é o serviço Heka, que escuta a porta UDP e espera que as métricas no formato StatsD sejam inseridas.
O formato do StatsD é o seguinte:

Ou seja, determinamos o nome da métrica, indicamos o valor dessa métrica, é 1, 26 e assim por diante, e indica seu tipo. No total, o StatsD possui cerca de quatro ou cinco tipos. Se você estiver subitamente interessado, poderá ver em detalhes a descrição desses tipos .
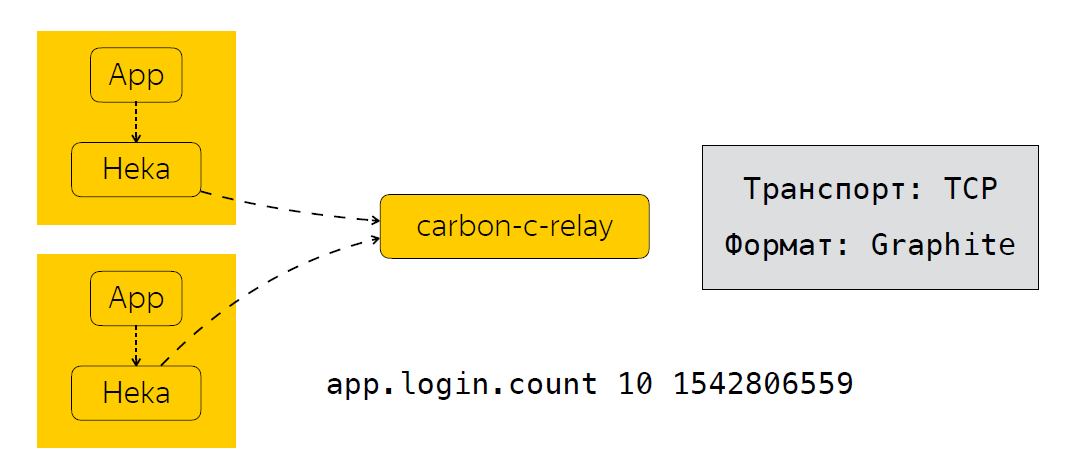
Depois que o aplicativo envia os dados Heka, as métricas são agregadas por um certo tempo. No nosso caso, são 30 segundos, após os quais a Heka envia dados para o carbono-c-relay, que executa a função de filtragem, roteamento, atualização de métricas, que, por sua vez, envia métricas para nosso armazenamento, usamos clickhouse (sim, não diminui a velocidade) ), bem como em Moira. Se alguém não souber, este é um serviço que permite configurar determinados gatilhos para métricas. Eu vou falar sobre Moira um pouco mais tarde. Então, analisamos quais métricas coletamos, como as enviamos e processamos. E o próximo passo lógico é a análise dessas métricas.
Como analisamos as métricas?
Darei uma situação real em que a análise das métricas nos deu resultados tangíveis. Tome o processo de liberação como um exemplo. Em termos gerais, inclui as seguintes etapas.
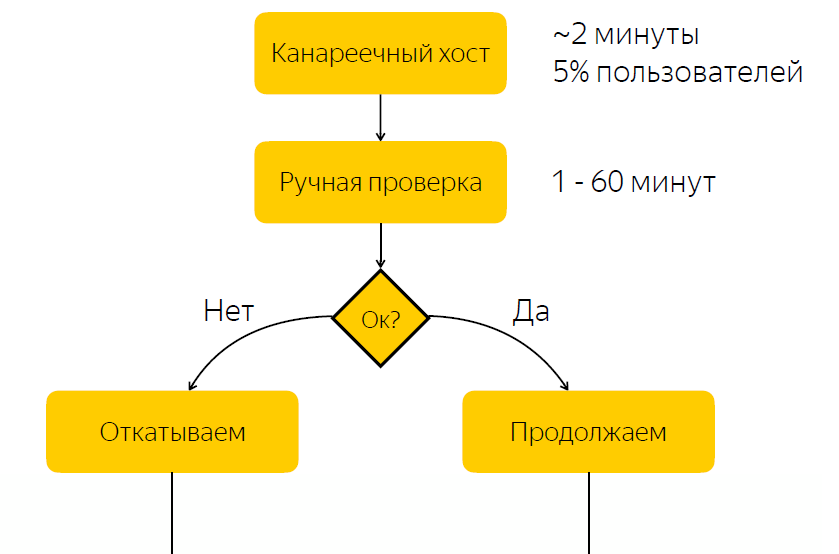
A versão é implantada no host canário. É responsável por cerca de cinco por cento do tráfego do usuário. Após a liberação do host canário, notificamos a pessoa responsável pela liberação que deve verificar se está tudo bem com a liberação. E ele deve dar uma reação, reagir a esta versão e clicar no botão com uma decisão sobre se esta versão deve ser lançada ou se deve ser revertida.
Não é difícil adivinhar que existe uma desvantagem significativa nesse esquema, a saber, que esperamos uma reação responsável. Se a pessoa responsável no momento, por algum motivo, não puder responder rapidamente, se tivermos uma liberação com erros, então por algum tempo cinco por cento do tráfego chegará ao nó do problema. Se tudo estiver em ordem com o lançamento, simplesmente passaremos o tempo esperando e, assim, desaceleraremos o processo de lançamento.
Sem bugs - atrasamos o processo de lançamento
Com bugs - afeto do usuário
Com a compreensão desse problema, decidimos descobrir se é possível automatizar o processo de tomada de decisão sobre se uma versão é problemática ou não.
Obviamente, procuramos nossos desenvolvedores para entender como a verificação do lançamento é feita. Acabou e parece lógico o suficiente que o principal indicador de que a versão é problemática é o aumento no número de erros nos logs deste aplicativo.
O que os desenvolvedores fizeram? Eles abriram o Kibana, fizeram uma seleção de acordo com o nível de ERRO do bloco de aplicativos e, se viram as listas, acharam que algo estava errado com o aplicativo. Vale ressaltar que os logs do nosso aplicativo são armazenados no Elastic, e parece que tudo parece bastante simples. Temos os logs no Elastic, apenas precisamos criar uma solicitação no Elastic, fazer uma seleção e entender com base nesses dados se a versão é problemática ou não. Mas essa decisão nos pareceu não muito boa.
Por que não Elastic?
Antes de tudo, estávamos preocupados com o fato de não conseguirmos receber dados rapidamente do Elastic. Existem casos como, por exemplo, durante o teste de estresse, quando temos um grande fluxo de dados, e o cluster pode não lidar e, por fim, há um atraso no envio de logs por cerca de 10 a 15 minutos.
Havia também razões secundárias, por exemplo, a falta de um nome uniforme para índices. Isso teve que ser levado em conta na ferramenta de automação. E também aplicativos em plataformas diferentes podem ter diferentes formatos de log.
Pensamos: por que não tentar fazer algum tipo de métrica com base nas quais podemos decidir se o lançamento é problemático ou não. Ao mesmo tempo, não queremos sobrecarregar nossos desenvolvedores para fazer alterações na base de código. E, como nos parece, encontramos uma solução bastante elegante adicionando um appender adicional ao log4j.
Como é isso?
<?xml version="1.0" encoding="UTF-8" ?> <Configuration status="warn" name="${sys:application.name}" > <Properties> <Property name="logsCountStatsDFormat">app_name.logs.%level:1|c</Property> </Properties> ... <Appenders> <Socket name="STATSD" host="127.0.0.1" port="8125" protocol="UDP"> <PatternLayout pattern="${logsCountStatsDFormat}"/> </Socket> </Appenders> <Loggers> <Root level="INFO"> <AppenderRef ref="STATSD"/> </Root> </Loggers> </Configuration>
Primeiro, determinamos o formato da métrica que estamos enviando. A seguir, um appender adicional que envia registros no formato que temos acima para a porta 8125 sobre UDP, ou seja, para Heka. O que isso nos dá? O Log4j para cada entrada no log envia uma métrica do tipo Contador, com um determinado nível de registro ERRO, INFO, WARN e assim por diante.
No entanto, percebemos rapidamente que o envio de uma métrica para cada entrada de log pode criar uma carga bastante significativa e escrevemos uma biblioteca que agrega as métricas por um certo tempo e envia a métrica já agregada ao serviço Heka. Na verdade, estamos adicionando esse appender aos criadores de logs e, com essa abordagem, agora sabemos quanto nosso aplicativo grava logs para nivelamento, temos um nome unificado para métricas, independentemente da plataforma usada. Podemos entender facilmente quantos erros existem no log do aplicativo. E, finalmente, conseguimos automatizar o processo de tomada de decisão para uma liberação problemática.
Automação
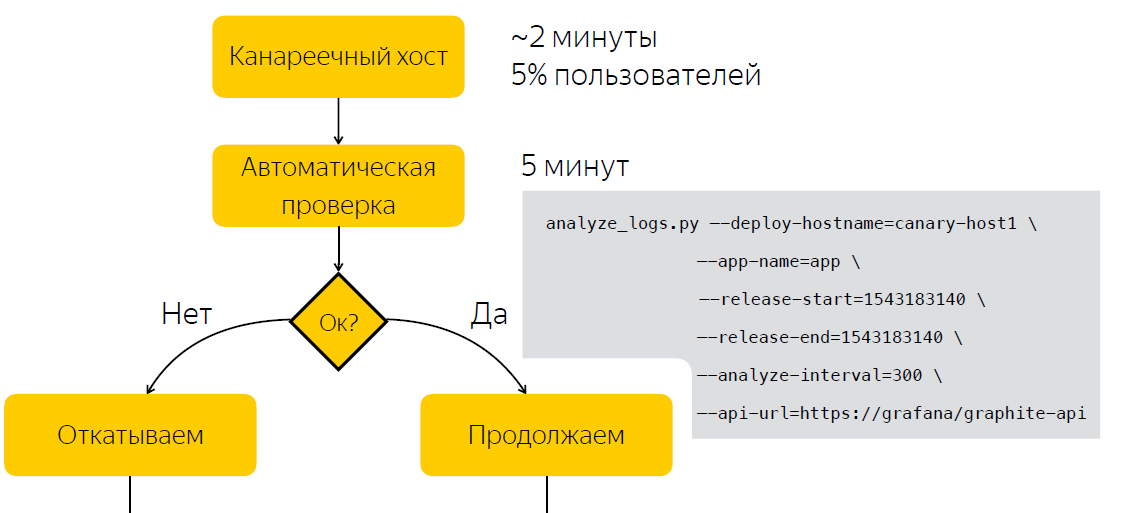
Em vez de verificar manualmente após o lançamento, aguardamos cinco minutos, após o qual coletamos dados sobre o número de entradas nos logs do aplicativo. Depois de executar o script, que, com base em duas amostras, antes e depois do lançamento, decide se o lançamento é problemático. Assim, reduzimos o tempo que gastamos em tomar uma decisão para cinco minutos.
Além do fato de que informações sobre o número de erros nos logs são úteis durante o lançamento, acabou sendo um bom bônus que também é útil durante a operação. Assim, por exemplo, podemos visualizar o número de erros nos logs do Grafana e registrar oscilações anômalas nos logs do aplicativo.
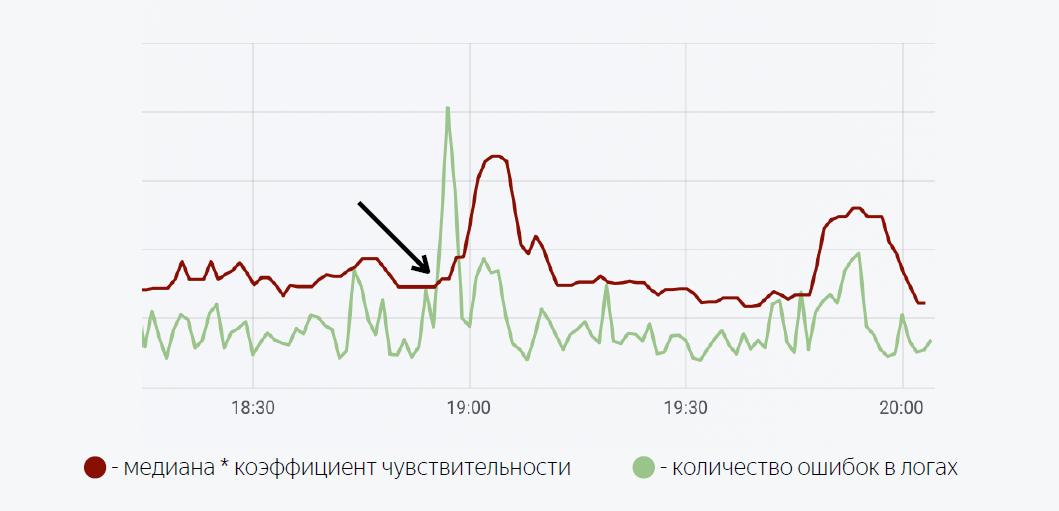
Um modelo matemático bastante simples é usado aqui. A linha verde é o número de erros nos logs do aplicativo. Vermelho escuro é a mediana vezes o fator de sensibilidade. No caso em que o número de erros nos logs ultrapassa a mediana, um acionador é acionado; quando acionado, uma notificação é enviada via Moira.
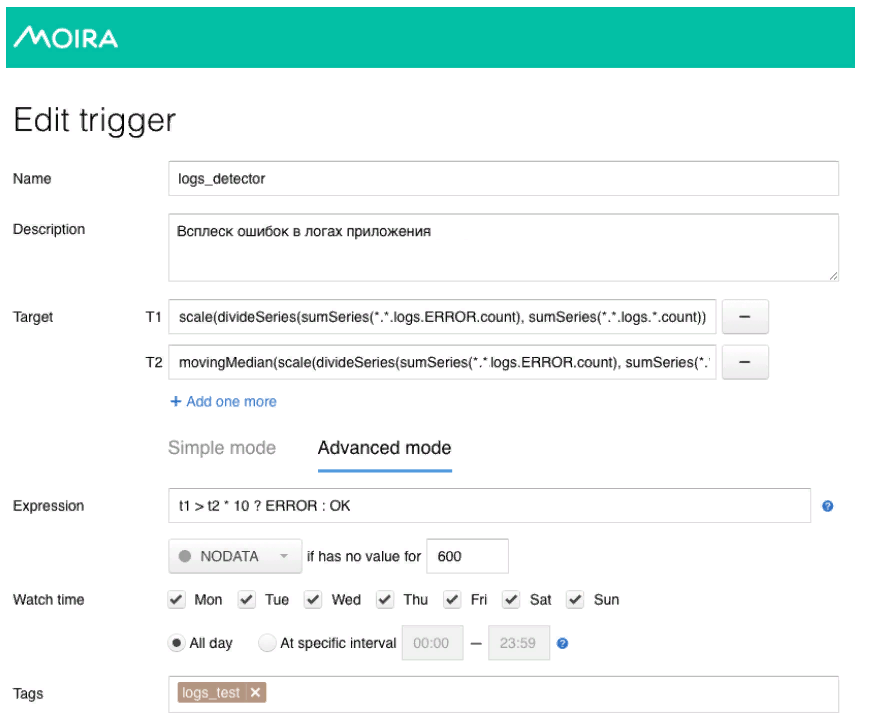
Como prometi, vou falar um pouco sobre Moira, como funciona. Definimos as métricas de destino que queremos observar. Esse é o número de erros e a mediana móvel, bem como as condições sob as quais esse gatilho funcionará, ou seja, quando o número de erros nos logs exceder a mediana multiplicada pelo coeficiente de sensibilidade. Quando o gatilho é acionado, o desenvolvedor recebe uma notificação de que uma explosão anormal de erros foi registrada no aplicativo e algumas ações devem ser tomadas.

O que temos no final? Desenvolvemos um mecanismo comum para todos os aplicativos de back-end, o que nos permite obter informações sobre o número de entradas nos logs de um determinado nível. Além disso, usando métricas sobre o número de erros nos logs do aplicativo, conseguimos automatizar o processo de tomada de decisão sobre se a versão é problemática ou não. Eles também escreveram uma biblioteca para o log4j, que você pode usar se quiser experimentar a abordagem que descrevi. Link para a biblioteca abaixo.
Provavelmente é tudo para mim. Obrigada
Links úteis
Log4j-count-appender
Moira