Neste artigo, apresentamos as
páginas , um esquema de gerenciamento de memória muito comum que também aplicamos em nosso sistema operacional. O artigo explica por que o isolamento de memória é necessário, como funciona a
segmentação , o que
é memória virtual e como as páginas resolvem o problema de fragmentação. Também exploramos o esquema de tabelas de páginas multiníveis na arquitetura x86_64.
Este blog está publicado no
GitHub . Se você tiver alguma dúvida ou problema, abra a solicitação correspondente lá.
Proteção de memória
Uma das principais tarefas do sistema operacional é isolar os programas um do outro. Por exemplo, um navegador não deve interferir com um editor de texto. Existem várias abordagens, dependendo da implementação do hardware e do sistema operacional.
Por exemplo, alguns processadores ARM Cortex-M (em sistemas embarcados) possuem
uma unidade de proteção de memória (MPU) que define um pequeno número (por exemplo, 8) de áreas de memória com permissões de acesso diferentes (por exemplo, sem acesso, somente leitura, leitura e leitura). registros). Cada vez que a memória é acessada, o MPU garante que o endereço esteja na área com as permissões corretas, caso contrário, gera uma exceção. Alterando o escopo e as permissões de acesso, o sistema operacional garante que cada processo tenha acesso apenas à sua memória para isolar os processos um do outro.
No x86, são suportadas duas abordagens diferentes para proteger a memória:
segmentação e
paginação .
Segmentação
A segmentação foi implementada em 1978, inicialmente para aumentar a quantidade de memória endereçável. Naquele momento, a CPU suportava apenas endereços de 16 bits, o que limitava a quantidade de memória endereçável a 64 KB. Para aumentar esse volume, foram introduzidos registros de segmentos adicionais, cada um contendo um endereço de deslocamento. A CPU adiciona automaticamente esse deslocamento a cada acesso à memória, endereçando até 1 MB de memória.
A CPU seleciona automaticamente um registro de segmento, dependendo do tipo de acesso à memória: o registro de segmento de código
CS é usado para receber instruções e o registro de segmento de pilha
SS é usado para operações de pilha (push / pop). Outras instruções usam o registro de segmento de dados
DS ou o registro de segmento
ES opcional. Mais tarde, dois registradores de segmentos adicionais
FS e
GS foram adicionados para uso gratuito.
Na primeira versão da segmentação, os registros continham diretamente o deslocamento e o controle de acesso não foi realizado. Com o advento do
modo protegido, o mecanismo mudou. Quando a CPU opera nesse modo, os descritores de segmento armazenam o índice em uma tabela de descritores local ou global, que além do endereço de deslocamento contém o tamanho do segmento e as permissões de acesso. Ao carregar tabelas de descritores globais / locais separadas para cada processo, o sistema operacional pode isolar os processos um do outro.
Ao alterar os endereços de memória antes do acesso real, a segmentação implementou um método que agora é usado em quase todos os lugares: é
a memória virtual .
Memória virtual
A idéia da memória virtual é abstrair os endereços de memória de um dispositivo físico. Em vez de acessar diretamente o dispositivo de armazenamento, uma etapa de conversão é realizada primeiro. No caso de segmentação, o endereço de deslocamento do segmento ativo é adicionado no estágio de conversão. Imagine um programa que acesse o endereço de memória
0x1234000 em um segmento com um deslocamento de
0x1111000 : na realidade, o endereço vai para
0x2345000 .
Para distinguir entre dois tipos de endereços, os endereços antes da conversão são chamados
virtuais e os endereços após a conversão são chamados
físicos . Há uma diferença importante entre eles: os endereços físicos são únicos e sempre se referem ao mesmo local exclusivo na memória. Os endereços virtuais, por outro lado, dependem da função de tradução. Dois endereços virtuais diferentes podem muito bem se referir ao mesmo endereço físico. Além disso, endereços virtuais idênticos podem se referir a diferentes endereços físicos após a conversão.
Um exemplo do uso útil dessa propriedade é o lançamento paralelo do mesmo programa duas vezes:
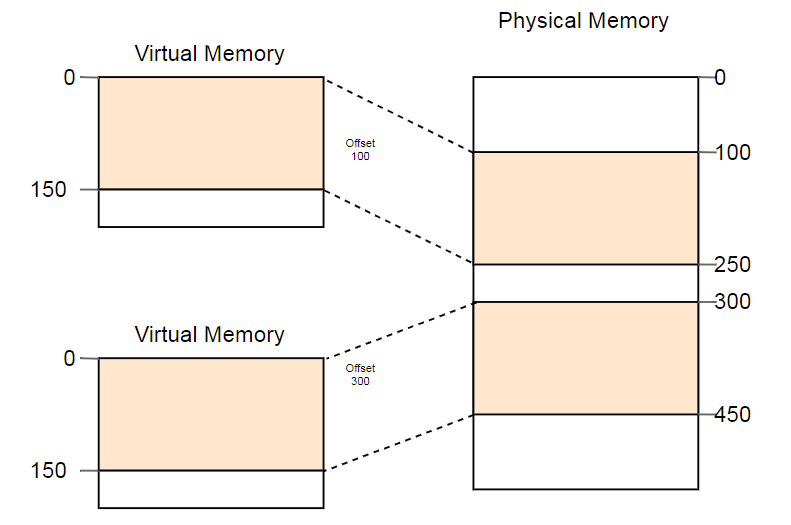
Aqui, o mesmo programa é executado duas vezes, mas com diferentes funções de conversão. A primeira instância tem um deslocamento de segmento de 100, portanto, seus endereços virtuais 0-150 são convertidos em endereços físicos 100-250. A segunda instância tem um deslocamento de 300, que converte os endereços virtuais 0-150 em endereços físicos 300-450. Isso permite que ambos os programas executem o mesmo código e usem os mesmos endereços virtuais sem interferir um com o outro.
Outra vantagem é que agora os programas podem ser colocados em locais arbitrários na memória física. Assim, o sistema operacional usa toda a quantidade de memória disponível sem a necessidade de recompilar os programas.
Fragmentação
A diferença entre endereços virtuais e físicos é uma conquista real da segmentação. Mas há um problema. Imagine que queremos executar a terceira cópia do programa que vimos acima:
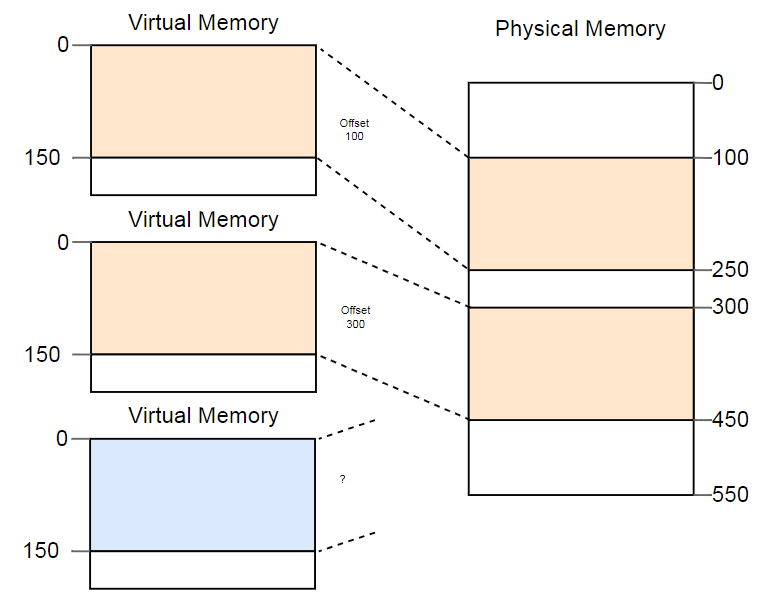
Embora exista espaço mais que suficiente na memória física, a terceira cópia não cabe em lugar algum. O problema é que ele precisa de um fragmento
contínuo de memória e não podemos usar seções livres separadas.
Uma maneira de combater a fragmentação é pausar a execução do programa, aproximar partes da memória usadas, atualizar a conversão e retomar a execução:
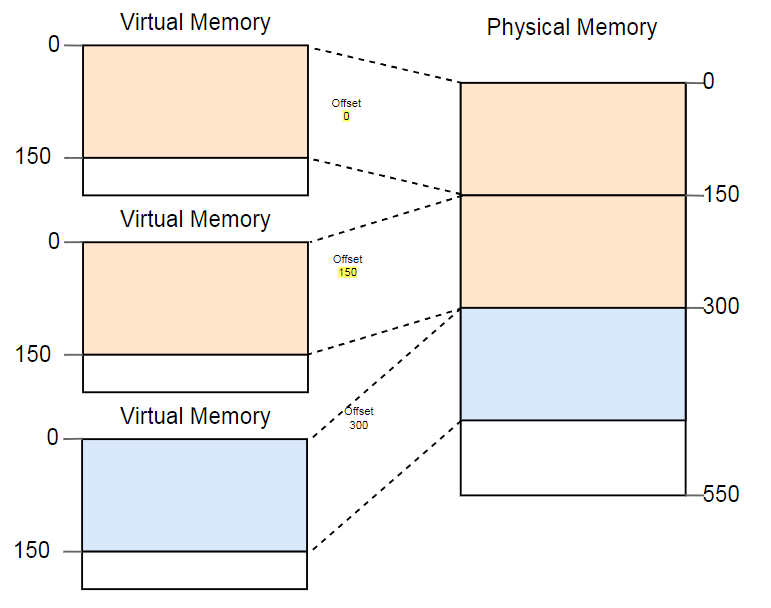
Agora, há espaço suficiente para iniciar a terceira instância.
A desvantagem dessa desfragmentação é a necessidade de copiar grandes quantidades de memória, o que reduz o desempenho. Este procedimento deve ser executado regularmente até que a memória fique muito fragmentada. O desempenho se torna imprevisível, os programas param a qualquer momento e podem parar de responder.
A fragmentação é uma das razões pelas quais a segmentação não é usada na maioria dos sistemas. De fato, ele não é mais suportado, mesmo no modo de 64 bits no x86. Em vez de segmentação, são usadas páginas que eliminam completamente o problema de fragmentação.
Organização da página da memória
A idéia é dividir o espaço da memória virtual e física em pequenos blocos de tamanho fixo. Os blocos de memória virtual são chamados de páginas e os blocos de espaço de endereço físico são chamados de quadros. Cada página é mapeada individualmente para um quadro, o que permite dividir grandes áreas de memória entre quadros físicos não adjacentes.
A vantagem se torna óbvia se você repetir o exemplo com um espaço de memória fragmentado, mas desta vez usando páginas em vez de segmentação:
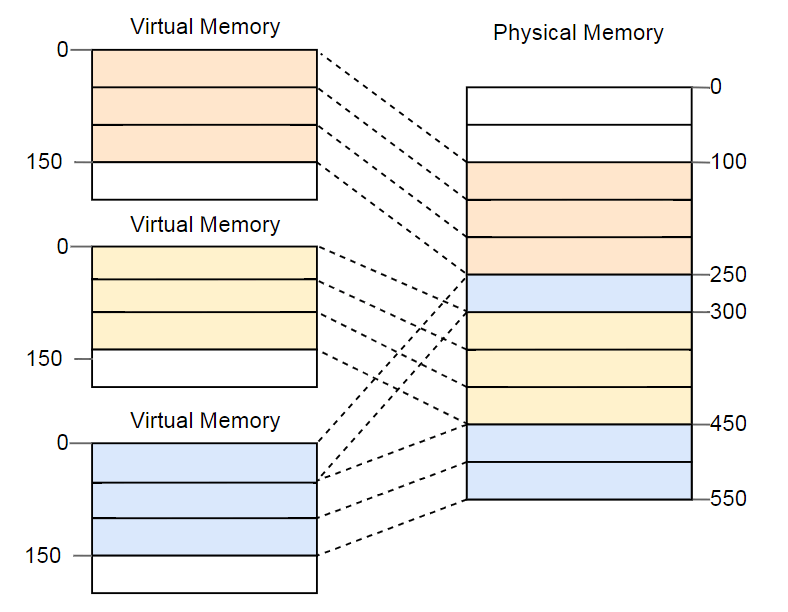
Neste exemplo, o tamanho da página é de 50 bytes, ou seja, cada uma das áreas de memória é dividida em três páginas. Cada página é mapeada para um quadro separado, para que uma região contígua da memória virtual possa ser mapeada para quadros físicos isolados. Isso permite que você execute a terceira instância do programa sem desfragmentação.
Fragmentação oculta
Comparada à segmentação, uma organização de paginação usa muitas áreas pequenas de memória de tamanho fixo em vez de várias áreas grandes de tamanho variável. Cada quadro tem o mesmo tamanho, portanto, a fragmentação devido a quadros muito pequenos não é possível.
Mas isso é apenas uma
aparência . De fato, existe uma forma oculta de fragmentação, a chamada
fragmentação interna, devido ao fato de que nem toda área de memória é exatamente um múltiplo do tamanho da página. Imagine no exemplo acima, um programa de tamanho 101: ele ainda precisará de três páginas de tamanho 50, e precisará de 49 bytes a mais do que você precisa. Para maior clareza, a fragmentação devido à segmentação é chamada
fragmentação externa .
Não há nada de bom na fragmentação interna, mas muitas vezes é um mal menor que a fragmentação externa. A memória extra ainda é consumida, mas agora você não precisa desfragmentá-la, e o volume de fragmentação é previsível (em média, meia página por área de memória).
Tabelas de Páginas
Vimos que cada um dos milhões de páginas possíveis é mapeado individualmente para um quadro. Essas informações de tradução de endereço precisam ser armazenadas em algum lugar. Ao segmentar, registradores de segmentos separados são usados para cada área de memória ativa, o que é impossível no caso de páginas, porque há muito mais deles que registradores. Em vez disso, ele usa uma estrutura chamada
tabela de página .
Para o exemplo acima, as tabelas ficarão assim:
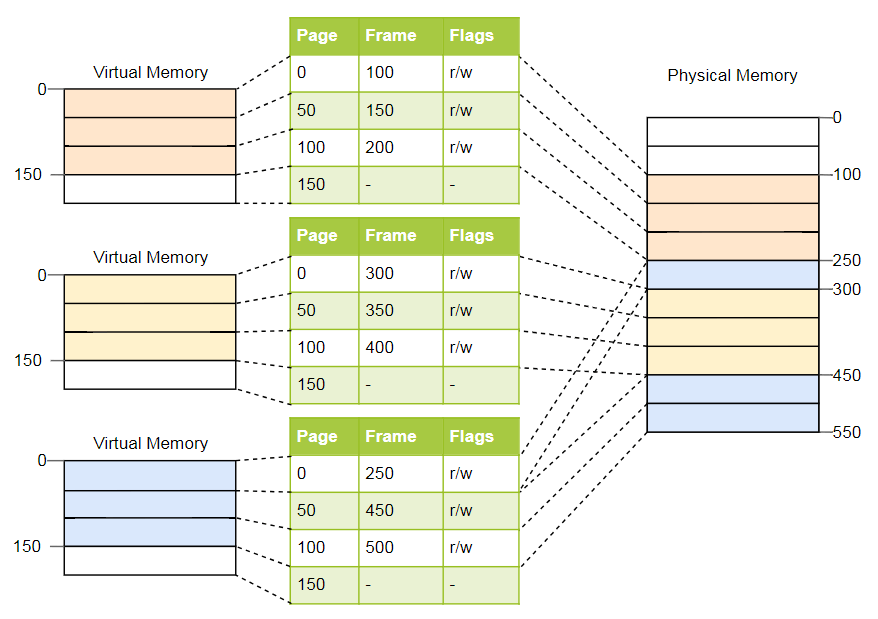
Como você pode ver, cada instância do programa possui sua própria tabela de páginas. Um ponteiro para a tabela ativa atual é armazenado em um registro especial da CPU. No
x86 é chamado de
CR3 . Antes de iniciar cada instância do programa, o sistema operacional deve carregar um ponteiro na tabela de páginas correta.
Cada vez que a memória é acessada, a CPU lê o ponteiro da tabela no registro e procura o quadro correspondente na tabela. Esta é uma função totalmente de hardware que é executada de forma totalmente transparente para um programa em execução. Para acelerar o processo, muitas arquiteturas de processadores têm um cache especial que lembra os resultados das últimas conversões.
Dependendo da arquitetura, atributos como permissões também podem ser armazenados no campo de sinalizador da tabela de páginas. No exemplo acima, o sinalizador
r/w torna a página legível e gravável.
Tabelas de páginas em camadas
Tabelas de páginas simples têm um problema com grandes espaços de endereço: a memória é desperdiçada. Por exemplo, o programa usa quatro páginas virtuais
0 ,
1_000_000 ,
1_000_050 e
1_000_100 (usamos
_ como um separador de dígitos):
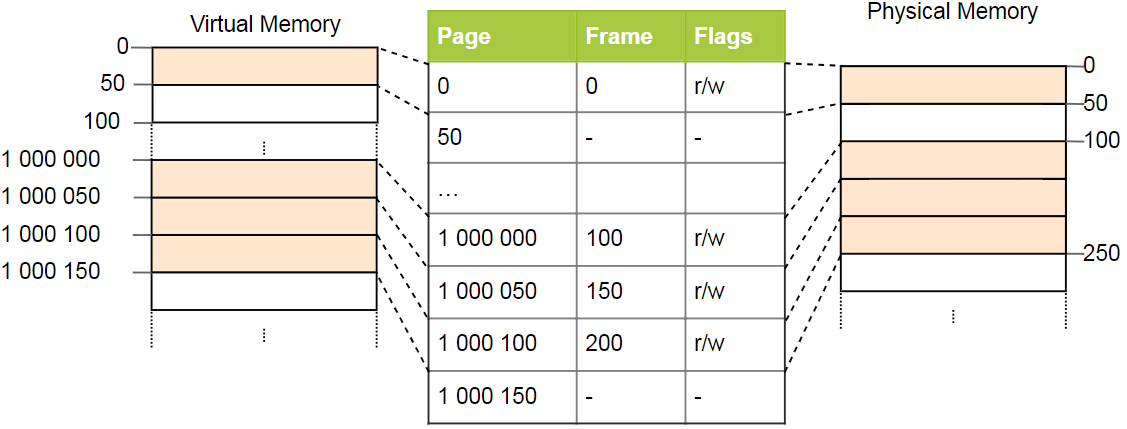
Apenas quatro quadros físicos são necessários, mas há mais de um milhão de registros na tabela de páginas. Não podemos pular entradas vazias, porque a CPU durante o processo de conversão não poderá ir diretamente para a entrada correta (por exemplo, não é mais garantido que a quarta página use a quarta entrada).
Para reduzir a perda de memória, você pode usar uma
organização de dois níveis . A idéia é que usamos tabelas diferentes para áreas diferentes. Uma tabela adicional, chamada tabela de página de
segundo nível , converte entre as áreas de endereço e as tabelas de página de primeiro nível.
Isso é melhor explicado pelo exemplo. Definimos que cada tabela de nível 1 é responsável por uma área de tamanho
10_000 . No exemplo acima, as seguintes tabelas existirão:
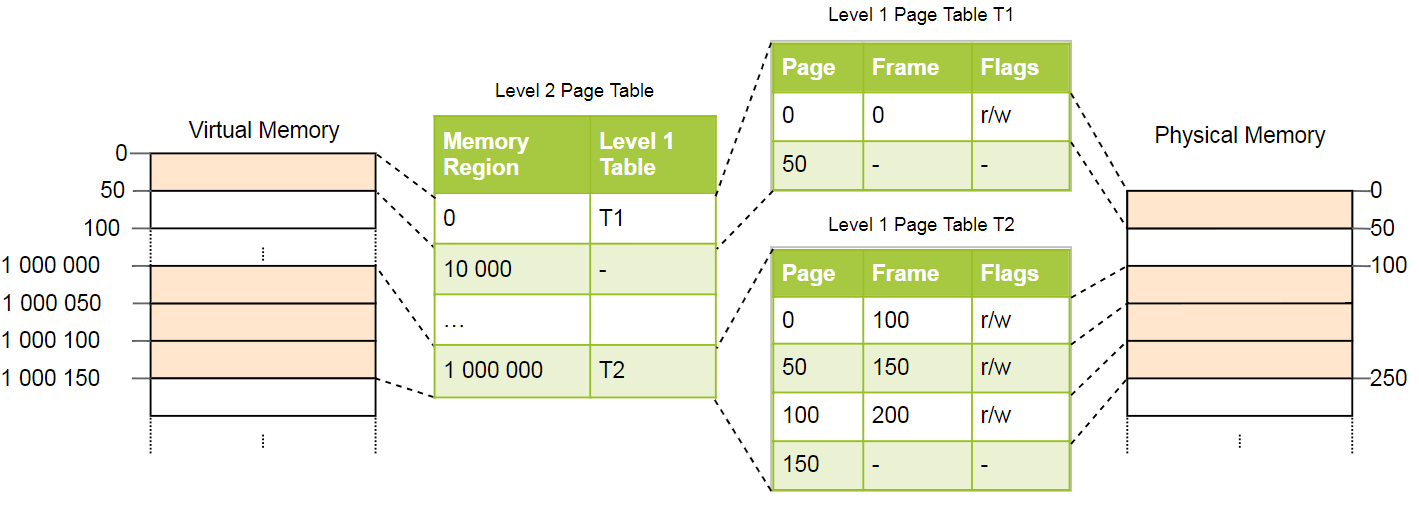
A página 0 cai na primeira área de
10_000 bytes, portanto, ela usa o primeiro registro na tabela de páginas do segundo nível. Essa entrada aponta para a tabela de páginas T1 de primeiro nível, que determina que a página 0 se refere ao quadro 0.
As páginas
1_000_000 ,
1_000_050 e
1_000_100 caem na região de 100 bytes de
10_000 , portanto, elas usam o 100º registro da tabela de páginas de nível 2. Esse registro aponta para outra tabela de primeiro nível T2, que converte três páginas nos quadros 100, 150 e 200. Observação que o endereço da página nas tabelas do primeiro nível não contém um deslocamento da região; portanto, por exemplo, o registro da página
1_000_050 é de apenas
50 .
Ainda temos 100 entradas vazias na tabela do segundo nível, mas isso é muito menor que o milhão anterior. O motivo da economia é que você não precisa criar tabelas de páginas de primeiro nível para áreas de memória
10_000 entre
10_000 e
1_000_000 .
O princípio das tabelas de dois níveis pode ser estendido para três, quatro ou mais níveis. Em geral, esse sistema é chamado de tabela de página
multinível ou
hierárquica .
Conhecendo a organização da página e as tabelas de vários níveis, é possível ver como a organização da página é implementada na arquitetura x86_64 (presumimos que o processador funcione no modo de 64 bits).
Organização da página em x86_64
A arquitetura x86_64 usa uma tabela de quatro níveis com um tamanho de página de 4 KB. Independentemente do nível, cada tabela de páginas possui 512 elementos. Cada registro tem um tamanho de 8 bytes; portanto, o tamanho das tabelas é de 512 × 8 bytes = 4 KB.

Como você pode ver, cada índice de tabela contém 9 bits, o que faz sentido, porque as tabelas possuem 2 ^ 9 = 512 entradas. Os 12 bits inferiores são o deslocamento da página de 4 kilobytes (2 ^ 12 bytes = 4 KB). Os bits 48 a 64 são descartados; portanto, x86_64 não é realmente um sistema de 64 bits, mas suporta apenas endereços de 48 bits. Há planos de expandir o tamanho do endereço para 57 bits por meio de uma
tabela de páginas de 5 níveis , mas esse processador ainda não foi criado.
Embora os bits 48 a 64 sejam descartados, eles não podem ser configurados para valores arbitrários. Todos os bits nesse intervalo devem ser cópias do bit 47 para preservar endereços exclusivos e permitir expansão futura, por exemplo, para uma tabela de páginas de 5 níveis. Isso é chamado de extensão de sinal, porque é muito semelhante a
uma extensão de sinal em código adicional . Se o endereço for expandido incorretamente, a CPU emitirá uma exceção.
Exemplo de conversão
Vejamos um exemplo de como a tradução de endereços funciona:
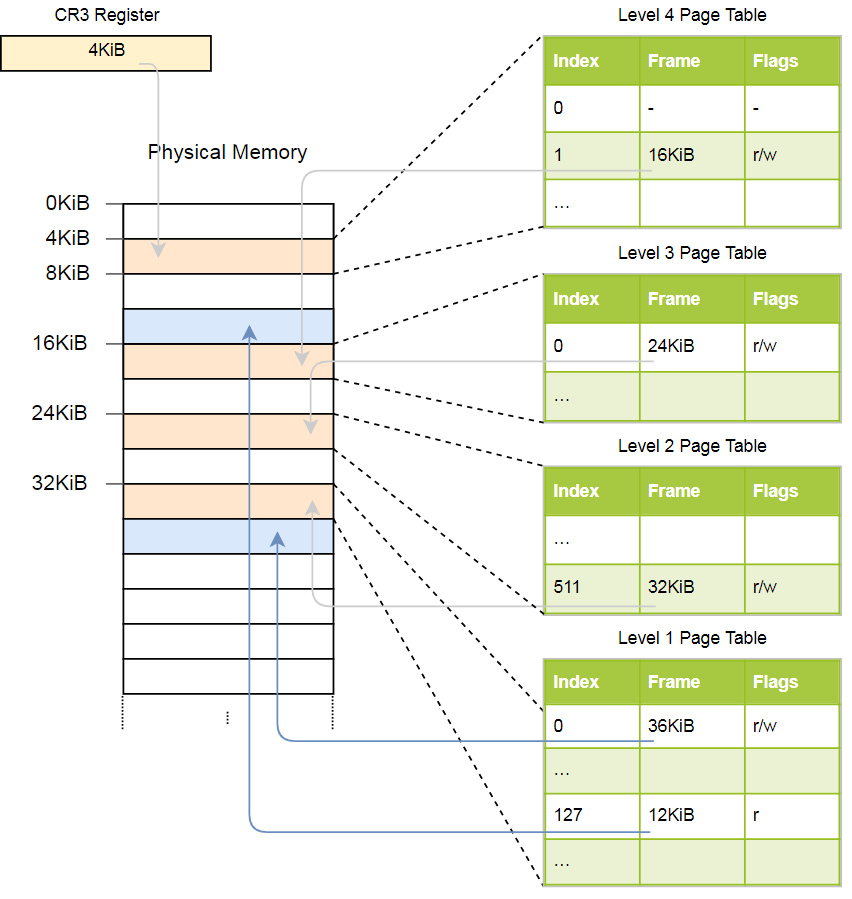
O endereço físico da tabela de páginas ativas atual das páginas de nível 4, que é a tabela raiz das páginas de páginas desse nível, é armazenado no
CR3 . Cada entrada da tabela de páginas aponta para o quadro físico da próxima tabela de níveis. Uma entrada da tabela de nível 1 indica o quadro exibido. Observe que todos os endereços nas tabelas de páginas são físicos e não virtuais, porque, caso contrário, a CPU precisará converter esses endereços (o que pode levar a uma recursão infinita).
A hierarquia acima converte duas páginas (em azul). A partir dos índices, podemos concluir que os endereços virtuais dessas páginas são
0x803fe7f000 e
0x803FE00000 . Vamos ver o que acontece quando um programa tenta ler a memória no endereço
0x803FE7F5CE . Primeiro, converta o endereço em binário e determine os índices da tabela de páginas e o deslocamento do endereço:

Usando esses índices, agora podemos percorrer a hierarquia das tabelas de páginas e encontrar o quadro correspondente:
- Leia o endereço da tabela de quarto nível no
CR3 . - O índice do quarto nível é 1, portanto, examinamos o registro com o índice 1 nesta tabela. Ela diz que uma tabela de nível 3 é armazenada em 16 KB.
- Carregamos a tabela de terceiro nível desse endereço e examinamos o registro com o índice 0, que aponta para a tabela de segundo nível em 24 KB.
- O índice do segundo nível é 511, portanto, estamos procurando o último registro nesta página para descobrir o endereço da tabela do primeiro nível.
- A partir da entrada com o índice 127 na tabela de primeiro nível, finalmente descobrimos que a página corresponde a um quadro de 12 KB ou 0xc000 no formato hexadecimal.
- A etapa final é adicionar um deslocamento ao endereço do quadro para obter o endereço físico: 0xc000 + 0x5ce = 0xc5ce.
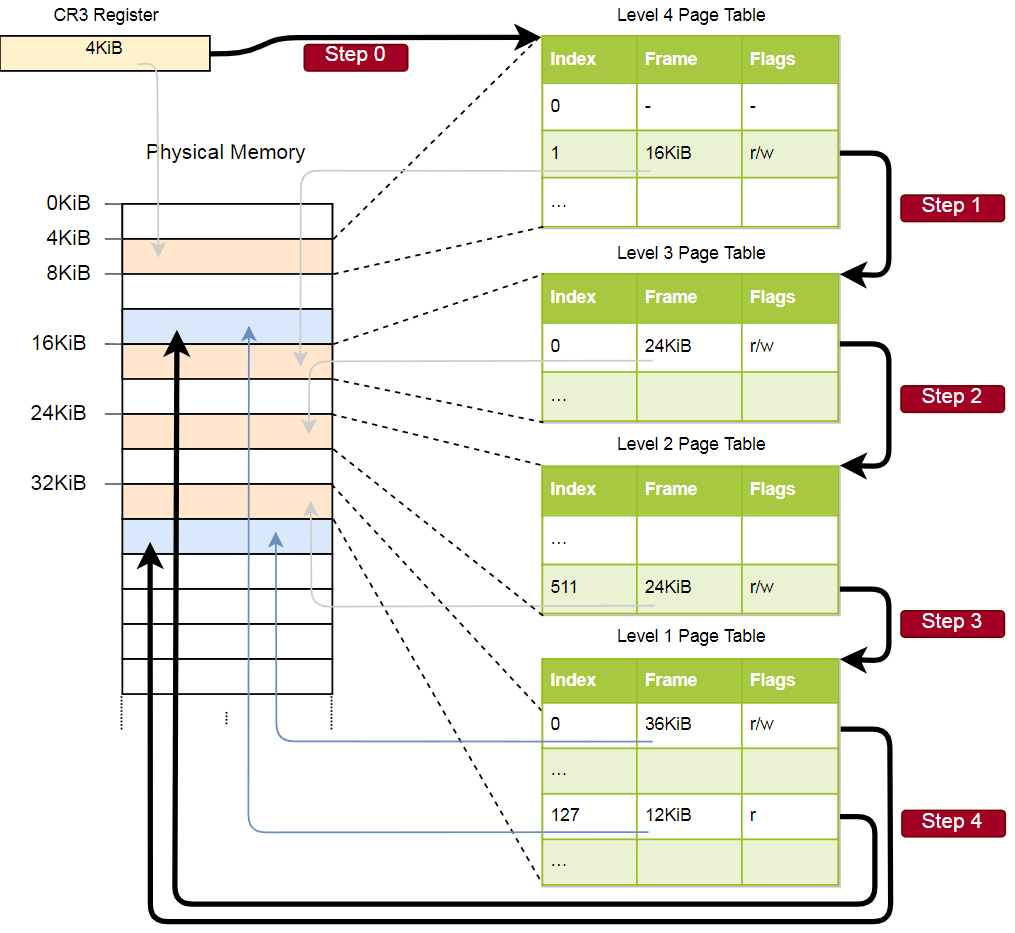
Para a página na tabela do primeiro nível, o sinalizador
r é especificado, ou seja, apenas a leitura é permitida. Uma exceção será lançada no nível do hardware se tentarmos gravar lá. As permissões das tabelas de nível superior se estendem aos níveis inferiores; portanto, se definirmos o sinalizador somente leitura no terceiro nível, nenhuma página subsequente de nível inferior será gravável, mesmo que os sinalizadores que permitem a gravação sejam indicados lá.
Embora este exemplo use apenas uma instância de cada tabela, geralmente em cada espaço de endereço, existem várias instâncias de cada nível. Máximo:
- uma mesa do quarto nível,
- 512 tabelas do terceiro nível (já que existem 512 registros na tabela do quarto nível),
- 512 * 512 tabelas de segundo nível (já que cada uma das tabelas de terceiro nível possui 512 entradas) e
- 512 * 512 * 512 tabelas do primeiro nível (512 registros para cada tabela do segundo nível).
Formato da tabela de páginas
Na arquitetura x86_64, as tabelas de páginas são essencialmente matrizes de 512 entradas. Na sintaxe Rust:
#[repr(align(4096))] pub struct PageTable { entries: [PageTableEntry; 512], }
Conforme indicado no atributo
repr , as tabelas devem estar alinhadas na página, ou seja, na borda de 4 KB. Esse requisito garante que a tabela sempre preencha de maneira ideal a página inteira, tornando as entradas muito compactas.
O tamanho de cada registro é 8 bytes (64 bits) e o seguinte formato:
| Bit (s) | Título | Valor |
|---|
| 0 0 | presente | página na memória |
| 1 | gravável | registro permitido |
| 2 | acessível ao usuário | se o bit não estiver definido, somente o kernel terá acesso à página |
| 3 | escrever através de cache | escreva diretamente na memória |
| 4 | desativar cache | desativar cache para esta página |
| 5 | acessado | A CPU define esse bit quando a página está em uso. |
| 6 | sujo | A CPU define esse bit ao escrever na página |
| 7 | página enorme / nula | o bit zero em P1 e P4 cria páginas de 1 KB em P3, página de 2 MB em P2 |
| 8 | global | a página não é preenchida do cache ao alternar o espaço de endereço (o bit PGE do registro CR4 deve ser definido) |
| 9-11 | disponível | OS pode usá-los livremente |
| 12-51 | endereço físico | endereço físico de 52 bits alinhado à página do quadro ou a seguinte tabela de páginas |
| 52-62 | disponível | OS pode usá-los livremente |
| 63. | sem executar | proíbe a execução de código nesta página (o bit NXE deve ser definido no registro EFER) |
Vemos que apenas os bits 12 a 51 são usados para armazenar o endereço físico do quadro, e o restante funciona como sinalizador ou pode ser usado livremente pelo sistema operacional. Isso é possível porque sempre apontamos para um endereço alinhado a 4096 bytes ou para uma página alinhada de tabelas ou para o início do quadro correspondente. Isso significa que os bits de 0 a 11 são sempre zero, portanto, não podem ser armazenados, são simplesmente redefinidos para o nível de hardware antes de usar o endereço. O mesmo se aplica aos bits 52-63, uma vez que a arquitetura x86_64 suporta apenas endereços físicos de 52 bits (e apenas endereços virtuais de 48 bits).
Vamos dar uma olhada nos sinalizadores disponíveis:
- O sinalizador
present distingue as páginas exibidas das não exibidas. Pode ser usado para salvar temporariamente as páginas no disco quando a memória principal estiver cheia. Na próxima vez que a página for acessada, ocorrerá uma exceção especial PageFault, à qual o SO responderá trocando a página do disco - o programa continua. - Os sinalizadores
writable e no execute determinam se o conteúdo da página é gravável ou contém instruções executáveis, respectivamente. - Os sinalizadores
accessed e dirty são definidos automaticamente pelo processador ao ler ou gravar na página. O sistema operacional pode usar essas informações, por exemplo, se trocar de página ou ao verificar se o conteúdo da página foi alterado desde o último bombeamento para o disco. - Os sinalizadores de
write through caching e disable cache permitem gerenciar o cache de cada página individualmente. - O sinalizador
user accessible torna a página acessível para código no espaço do usuário, caso contrário, está disponível apenas para o kernel. Esta função pode ser usada para acelerar as chamadas do sistema , mantendo o mapeamento de endereços para o kernel enquanto o programa do usuário está em execução. No entanto, a vulnerabilidade Spectre permite que essas páginas sejam lidas por programas no espaço do usuário. global , (. TLB ) (address space switch). user accessible .huge page , 2 3 . 512 : 2 = 512 × 4 , 1 = 512 × 2 . .
A arquitetura x86_64 define o formato das tabelas de páginas e seus registros , portanto, não precisamos criar essas estruturas sozinhos.Buffer de tradução associativa (TLB)
Por causa dos quatro níveis, cada conversão de endereço requer quatro acessos à memória. Por motivos de desempenho, x86_64 armazena em cache as últimas traduções no chamado buffer de tradução associativa (TLB). Isso permite que você pule a conversão se ela ainda estiver no cache.Diferentemente de outros caches de processador, o TLB não é completamente transparente, não atualiza ou exclui conversões ao alterar o conteúdo das tabelas de páginas. Isso significa que o kernel deve atualizar o próprio TLB sempre que modificar a tabela de páginas. Para fazer isso, existe uma instrução especial da CPU chamada invlpg(página inválida), que remove a tradução da página especificada do TLB, para que na próxima vez que ela seja carregada novamente da tabela de páginas. O TLB é completamente limpo ao recarregar o registroCR3que imita um comutador de espaço de endereço. Ambas as opções estão disponíveis através do módulo tlb no Rust.É importante lembrar de limpar o TLB após cada alteração na tabela de páginas, caso contrário, a CPU continuará usando a tradução antiga, o que levará a erros imprevisíveis que são muito difíceis de depurar.Implementação
Não mencionamos uma coisa: nosso núcleo já suporta a organização da página . O gerenciador de inicialização do artigo “Minimal Kernel on Rust” já estabeleceu uma hierarquia de quatro níveis que mapeia cada página do nosso kernel para um quadro físico, porque a organização da página é necessária no modo de 64 bits no x86_64.Isso significa que em nosso núcleo todos os endereços de memória são virtuais. O acesso ao buffer VGA no endereço 0xb8000funcionou apenas porque o identificador do carregador de inicialização converteu esta página na memória, ou seja, mapeou a página virtual 0xb8000para o quadro físico 0xb8000.Graças à organização da página, o kernel já é relativamente seguro: todo acesso além da memória permitida causa um erro de página e não permite a gravação na memória física. O carregador até define as permissões de acesso corretas para cada página: somente páginas com código serão executáveis e somente páginas com dados são graváveisErros de página (PageFault)
Vamos tentar chamar o PageFault acessando a memória fora do kernel. Primeiro, crie um manipulador de erros e registre-o em nosso IDT para ver uma exceção específica em vez de um erro duplo de um tipo geral:
Se a página falhar, a CPU definirá o caso automaticamente CR2. Ele contém o endereço virtual da página que causou a falha. Para ler e exibir este endereço usando a função Cr2::read. Normalmente, o tipo PageFaultErrorCodefornece mais informações sobre o tipo de acesso à memória que causou o erro, mas devido ao erro do LLVM, um código de erro inválido é passado, portanto, ignoramos essas informações por enquanto. A execução do programa não pode ser continuada até que resolvamos o erro da página, então insira no final hlt_loop.Agora temos acesso à memória fora do kernel:
Após o início, vemos que o manipulador de erros de página é chamado: O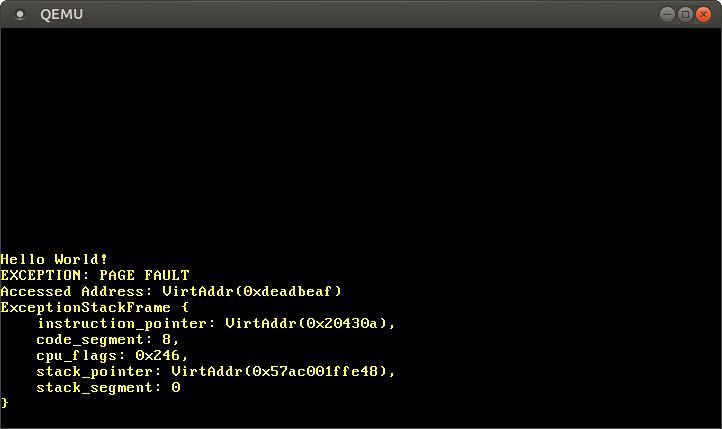 registro
registro CR2realmente contém o endereço que 0xdeadbeafdesejamos acessar.O ponteiro de instrução atual é 0x20430a, portanto sabemos que esse endereço aponta para uma página de código. As páginas de código são exibidas pelo carregador somente leitura, portanto, a leitura desse endereço funciona e a gravação causará um erro. Tente alterar o ponteiro 0xdeadbeafpara 0x20430a:
Se comentarmos a última linha, podemos garantir que a leitura funcione e a gravação cause um erro de PageFault.Acesso a tabelas de páginas
Agora dê uma olhada nas tabelas de páginas do kernel:
A função Cr3::readfrom x86_64retorna do registro a CR3tabela ativa atual de páginas do quarto nível. Um casal volta PhysFramee Cr3Flags. Estamos interessados apenas no primeiro.Após o início, vemos este resultado:Level 4 page table at: PhysAddr(0x1000)Atualmente, a tabela ativa de páginas do quarto nível é armazenada na memória física no endereço 0x1000indicado pelo tipo PhysAddr. Agora a pergunta é: como acessar esta tabela a partir do kernel?Com a organização da página, o acesso direto à memória física não é possível; caso contrário, os programas poderão ignorar facilmente a proteção e obter acesso à memória de outros programas. Portanto, a única maneira de obter acesso é através de alguma página virtual, que é traduzida em um quadro físico em0x1000. Este é um problema típico porque o kernel deve acessar regularmente as tabelas de páginas, por exemplo, ao alocar uma pilha para um novo encadeamento.As soluções para esse problema serão descritas em detalhes no próximo artigo. Por enquanto, digamos apenas que o carregador usa um método chamado tabelas de páginas recursivas . A última página do espaço de endereço virtual é 0xffff_ffff_ffff_f000, usamos-o para ler algumas entradas nesta tabela:
Reduzimos o endereço da última página virtual para um ponteiro para u64. Conforme declarado na seção anterior, cada entrada da tabela de páginas tem 8 bytes (64 bits) de tamanho e, portanto, u64representa exatamente uma entrada. Usando o loop, forexibimos os 10 primeiros registros da tabela. Dentro do loop, usamos um bloco não seguro para ler diretamente do ponteiro e offsetcalcular o ponteiro.Depois de iniciar vemos os seguintes resultados: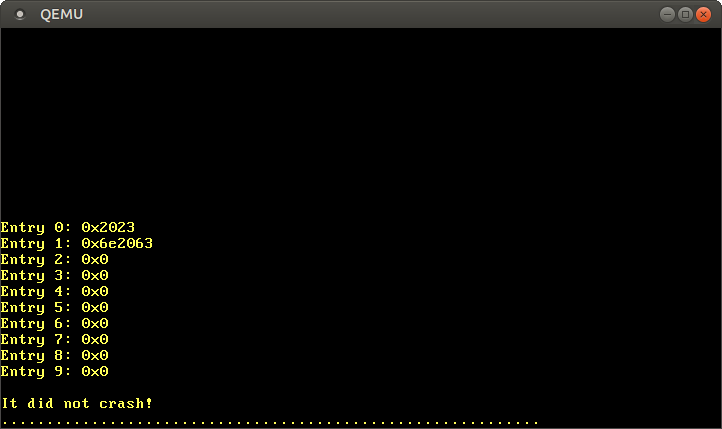 De acordo com o formato descrito acima, o valor de
De acordo com o formato descrito acima, o valor de 0x2023meios de registo possuindo bandeiras 0 present, writable, accessede a tradução numa moldura 0x2000. O registro 1 é transmitido no quadro 0x6e2000e possui os mesmos sinalizadores, além dedirty. As entradas 2 a 9 estão ausentes, portanto, esses intervalos de endereços virtuais não são mapeados para nenhum endereço físico.Em vez de trabalhar diretamente com ponteiros não seguros, você pode usar um tipo PageTablede x86_64:
0xffff_ffff_ffff_f000 , Rust. - , , .
&PageTable , ,
.
x86_64 , :

— 0 1 3. ,
0x2000 0x6e5000 , . .
Sumário
O artigo apresenta dois métodos de proteção de memória: segmentação e organização da página. O primeiro método usa áreas de memória de tamanho variável e sofre fragmentação externa, o segundo usa páginas de tamanho fixo e permite um controle muito mais granular sobre os direitos de acesso.Uma organização de páginas armazena informações de conversão de páginas em tabelas de um ou mais níveis. A arquitetura x86_64 usa tabelas de quatro níveis com um tamanho de página de 4 KB. O equipamento ignora automaticamente as tabelas de páginas e armazena em cache os resultados da conversão no buffer de tradução associativo (TLB). Ao alterar as tabelas de páginas, ele deve ser forçado a limpar.Aprendemos que nosso núcleo já suporta a organização da página e que o acesso não autorizado à memória reduz o PageFault. Tentamos acessar as tabelas de páginas ativas no momento, mas conseguimos acessar apenas a tabela de quarto nível, pois os endereços das páginas armazenam endereços físicos e não podemos acessá-los diretamente do kernel.O que vem a seguir?
O artigo a seguir é baseado nos fundamentos fundamentais que aprendemos agora. Para acessar as tabelas de páginas do kernel, uma técnica avançada chamada tabelas de páginas recursivas é usada para percorrer a hierarquia das tabelas e implementar a tradução de endereços programática. O artigo também explica como criar novas traduções em tabelas de páginas.