No início de 2018, iniciamos ativamente o processo de digitalização da produção e processos na empresa. No setor petroquímico, essa não é apenas uma tendência da moda, mas um novo passo evolutivo no sentido de aumentar a eficiência e a competitividade. Considerando as especificidades do negócio, que, sem nenhuma digitalização, mostra bons resultados econômicos, os digitalizadores enfrentam uma tarefa difícil: alterar processos estabelecidos na empresa é uma tarefa bastante meticulosa.
Nossa digitalização começou com a criação de dois centros e seus blocos funcionais correspondentes.
Essa é a “Função da tecnologia digital”, que inclui todas as áreas de produtos: digitalização de processos, IIoT e análises avançadas, além de um centro de gerenciamento de dados que se tornou uma área independente.

E apenas a principal tarefa do escritório de dados é implementar totalmente a cultura de tomada de decisão com base em dados (sim, sim, decisão orientada a dados), bem como, em princípio, otimizar tudo relacionado ao trabalho com dados: análise, processamento , armazenamento e relatórios. A peculiaridade é que todas as nossas ferramentas digitais terão que não apenas usar ativamente seus próprios dados, ou seja, aqueles que eles geram (por exemplo, desvios móveis ou sensores IIoT), mas também dados externos, com uma compreensão clara de onde e por que são necessários. usar.
Meu nome é Artyom Danilov, sou o chefe do departamento de Infraestrutura e Tecnologia da SIBUR. Neste post, mostrarei como e sobre o que construímos um grande sistema de processamento e armazenamento de dados para toda a SIBUR. Para começar, falaremos apenas sobre a arquitetura de nível superior e como você pode se tornar parte de nossa equipe.
Aqui estão as áreas que incluem trabalho em um escritório de dados:
1. Trabalhar com dadosOs profissionais envolvidos ativamente no inventário e na catalogação de nossos dados trabalham aqui. Eles entendem o que precisa de uma função específica, podem determinar que tipo de análise pode ser necessária, quais métricas devem ser monitoradas para a tomada de decisões e como os dados são usados em uma área de negócios específica.
2. Visualização de BI e dadosA direção está intimamente relacionada à primeira e permite visualizar os resultados do trabalho dos rapazes da primeira equipe.
3. Direção do controle de qualidade dos dadosAqui, as ferramentas de controle de qualidade dos dados são introduzidas e toda a metodologia desse controle é implementada. Em outras palavras, os funcionários daqui implementam software, escrevem várias verificações e testes, entendem como ocorrem as verificações cruzadas entre sistemas diferentes, observam as funções dos funcionários responsáveis pela qualidade dos dados e também estabelecem uma metodologia comum.
4. Gestão do NSISomos uma grande empresa. Temos muitos tipos diferentes de diretórios - e prestadores de serviços, materiais e um diretório de empresas ... Em geral, acredite, existem diretórios mais do que suficientes.
Quando uma empresa compra ativamente algo para suas atividades, geralmente possui processos especiais para preencher esses diretórios. Caso contrário, o caos atingirá um nível tal que será impossível trabalhar a partir da palavra "completamente". Também temos esse sistema (MDM).
Aqui estão os problemas. Suponha que, em uma das divisões regionais, da qual temos muito, os funcionários se sentem e insiram dados no sistema. Contribua manualmente, com todas as consequências decorrentes deste método. Ou seja, eles precisam inserir dados, verificar se tudo chegou ao sistema na forma correta, sem duplicatas. Ao mesmo tempo, algumas coisas, no caso de preencher alguns detalhes e campos obrigatórios, você deve pesquisar e pesquisar no Google de forma independente. Por exemplo, você tem uma empresa TIN e precisa de outras informações - consulte serviços especiais e o registro.
Todos esses dados, é claro, já estão em algum lugar, portanto, seria correto simplesmente retirá-los automaticamente.
Anteriormente, a empresa, em princípio, não possuía posição única, uma equipe clara que faria isso. Havia muitas divisões dispersas que inseriam dados manualmente. Mas geralmente é difícil para essas estruturas formularem exatamente o que exatamente e onde exatamente no processo de trabalhar com dados deve ser alterado para que tudo fique perfeito. Portanto, estamos revisando o formato e a estrutura de gerenciamento do NSI.
5. Implementação do data warehouse (nó de dados)Foi exatamente isso que começamos a fazer nesta área.
Vamos definir imediatamente os termos, caso contrário, as frases que eu uso podem se cruzar com alguns outros conceitos. Grosso modo, nó de dados = data lake + data warehouse Um pouco mais adiante, revelarei isso com mais detalhes.
Arquitetura
Primeiro, tentamos descobrir com que tipo de dados trabalhar - quais sistemas existem, quais sensores. Entendemos como seriam os dados de streaming (é o que as próprias empresas geram a partir de todos os seus equipamentos, isto é IIoT e assim por diante) e sistemas clássicos, diferentes CRM, ERP e similares.
Percebemos que os dados nos sistemas atuais não serão diretamente suficientes para serem muito grandes em volume, mas com a introdução de ferramentas digitais e IIoT, haverá muitos deles. E também haverá dados muito heterogêneos dos sistemas contábeis clássicos. Portanto, eles criaram a arquitetura desse plano.

Mais detalhes sobre os blocos.
Armazenamento
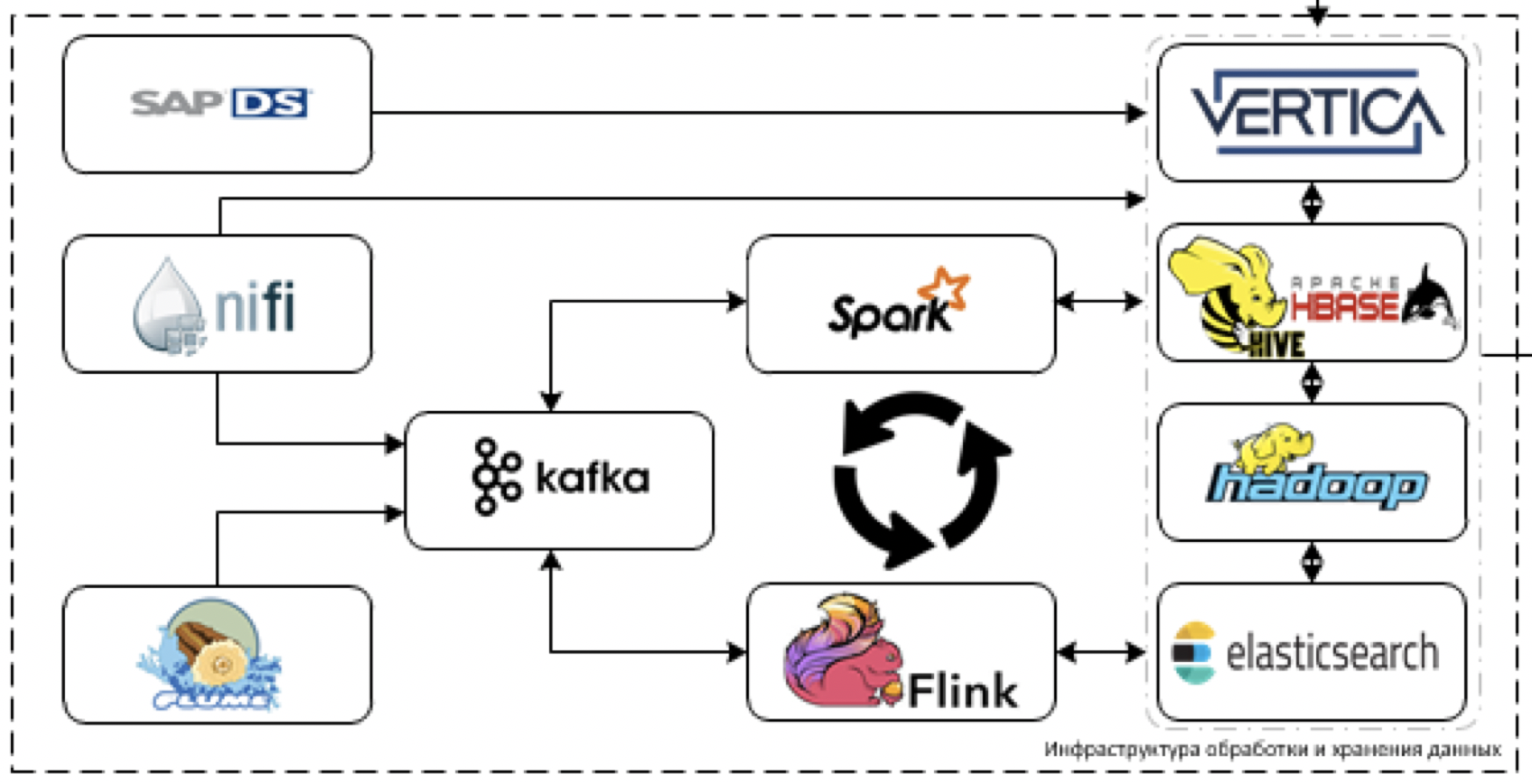
Este é o núcleo da nossa plataforma. O que é usado para processar e armazenar dados. O desafio é fazer o download de dados de mais de 60 sistemas diferentes quando eles começarem a entregá-los. Ou seja, geralmente existem todos os dados que podem ser úteis para a tomada de algumas decisões.
Vamos começar com a extração e o processamento de dados. Para esses fins, planejamos usar a ferramenta NiFi ETL para streaming e pacote de dados, bem como ferramentas de processamento de streaming: Flume para recepção e decodificação inicial de dados, Kafka para buffering, Flink e Spark Streaming como as principais ferramentas de processamento de fluxo de dados.
Mais difícil de trabalhar com sistemas de pilha SAP. É necessário recuperar dados do SAP usando uma ferramenta ETL separada - SAP Data Services.
Como ferramentas de armazenamento, planejamos usar a plataforma Cloudera Hadoop (HDFS, HBASE, Hive, Impala propriamente dita), o DBMS analítico da Vertica e, para casos individuais, a pesquisa elástica.
Basicamente, usamos a pilha mais avançada. Sim, você pode tentar jogar tomates em nós e provocar o que chamamos de pilha mais moderna, mas na verdade - é.
Não estamos limitados ao desenvolvimento legado, mas não podemos usar a vantagem em uma solução industrial devido à orientação explícita da empresa em nossa plataforma. Portanto, talvez não arrastemos Horton, mas nos limitemos a Clouder, sempre que possível, estamos definitivamente tentando arrastar uma ferramenta mais nova.

O SAS Data Quality é usado para controlar a qualidade dos dados e o Airflow é usado para gerenciar toda essa bondade. Monitoramos toda a plataforma através da pilha ELK. Planejamos fazer a maior parte da visualização no Tableau, alguns relatórios completamente estáticos no SAP BO.
Já entendemos que parte das tarefas não pode ser realizada por meio de soluções de BI padrão, pois é necessária uma visualização em tempo real muito sofisticada com muitos controles de papelão. Portanto, escreveremos nossa própria estrutura de visualização, que pode ser incorporada em produtos digitais em desenvolvimento.
Sobre a plataforma digital
Se você olhar um pouco mais amplamente, agora nossos colegas da função de tecnologia digital estão construindo uma única plataforma digital, cuja tarefa é desenvolver rapidamente nossos próprios aplicativos.
O data lake é um dos elementos desta plataforma.
Como parte dessa atividade, entendemos que precisaremos implementar uma interface conveniente para acessar dados analíticos. Portanto, planejamos implementar a API de dados e o modelo de objeto de produção para um acesso mais conveniente aos dados de produção.
O que mais fazemos e de quem precisamos
Além de armazenar e processar dados, todo o aprendizado de máquina, bem como a estrutura IIoT, funcionará em nossa plataforma. O lago atuará tanto como fonte de dados para modelos de treinamento e trabalho, quanto como capacidade para modelos de trabalho. Uma estrutura de ML que funcionará no topo da plataforma já está pronta.

No momento, tenho uma equipe, dois arquitetos e seis desenvolvedores, por isso estamos procurando ativamente novas pessoas (preciso de
arquitetos e
engenheiros de dados ) que nos ajudarão no desenvolvimento da plataforma. Você não precisa bisbilhotar no legado (o legado está aqui apenas na entrada dos sistemas), a pilha é nova.
É aí que as sutilezas estarão - é nas integrações. Conectar o antigo ao novo, para que ele funcione bem e resolva problemas, é um desafio. Além disso, será necessário inventar, elaborar e pendurar várias métricas diferentes.
A coleta de dados é realizada em todos os principais sistemas - 1C, SAP e um monte de tudo o mais. Com base nos dados coletados aqui, todas as análises, todas as previsões, todos os relatórios digitais serão criados.
Em resumo, queremos que os dados funcionem muito bem. Por exemplo, marketing e vendas - eles têm pessoas que coletam todas as estatísticas manualmente. Ou seja, eles ficam sentados e, de 5 sistemas diferentes, extraem dados diferentes em formatos diferentes, baixam-nos de 5 programas diferentes e descarregam tudo isso no Excel. Em seguida, eles resumem as informações em tabelas unificadas do Excel, de alguma forma tentam fazer a visualização.
Em geral, o vagão leva todo esse tempo. Queremos resolver esses problemas com nossa plataforma. E nos posts a seguir, falaremos detalhadamente sobre como conectamos os elementos e configuramos a operação correta do sistema.
A propósito, além dos
arquitetos e
engenheiros de dados desta equipe, teremos o maior prazer em ver: