Fantastic Dizzy é um jogo de plataformas criado em 1991 pela Codemasters. Ela faz parte da
série Dizzy . Apesar do fato de que a série Dizzy ainda é popular e cria jogos amadores (
Dizzy Age ), parece que ninguém esteve envolvido no desenvolvimento reverso dos jogos originais.
Escrevi algumas ferramentas simples para extrair, visualizar e empacotar os recursos do jogo original. Ferramentas postadas no
GitHub .
Descompactando EXE
O arquivo binário PCDIZZY.EXE é compactado no formato Microsoft
EXEPack . Embora existam muitas ferramentas Linux que podem descompactar esses executáveis, nenhum deles parece suportar a versão usada para o Fantastic Dizzy. Portanto, para descompactar o arquivo executável, usei a versão DOS do
UNP . Após descompactar o arquivo executável, ele pode ser baixado no IDA. Convenientemente, a versão descompactada do arquivo binário ainda funcionava bem, para que pudesse ser depurada usando o depurador DOSBox.
Arquivos de dados
Existem dois arquivos de dados no jogo: DIZZY.NDX e DIZZY.RES. Extensões, bem como tamanhos de arquivo, nos dão uma dica sobre o que elas podem conter. O arquivo NDX tem aproximadamente 8 KB e o arquivo RES é aproximadamente 800 KB. Como o jogo é escrito em C, podemos procurar chamadas abertas na IDA para ver onde os arquivos de dados são abertos. Nos jogos do DOS escritos em assembler, para isso, é necessário procurar instruções int 21h (para abrir o arquivo ah = 3d). O binário Dizzy contém uma função de wrapper em torno do fopen que permite especificar o nome principal e a extensão do arquivo. Isso nos leva ao seguinte bloco de código:
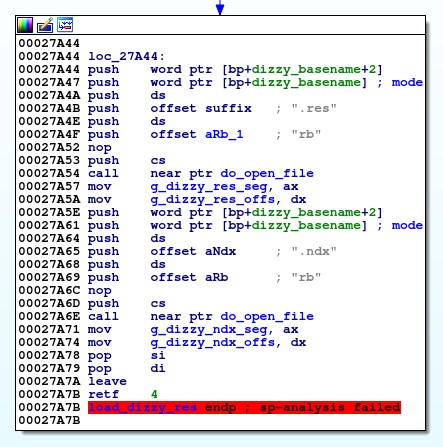
Carrega os arquivos DIZZY.RES e DIZZY.NDX e também salva ponteiros de arquivo em variáveis globais. Quando os binários do DOS são de engenharia reversa, surge um problema irritante: os registros neles são de 16 bits, mas em alguns casos os indicadores podem ser de 32 bits. Aqui, os ponteiros FILE * têm tamanho de 32 bits e são retornados de do_open_file para ax: dx. Observe que as strings também são ponteiros de 32 bits e dizzy_basename é passado para a função de chamada na pilha (e essa confusa análise automática de IDA - foi considerado um argumento de modo para fopen).
Pesquisando as ocorrências de g_dizzy_res / ndx em refexs, você pode encontrar onde os arquivos são lidos. O depurador DOSBox é útil neste momento, porque há uma alta probabilidade de muitas operações aleatórias de leitura de arquivos e o uso do IDA para determinar as compensações de leitura seria um processo bastante monótono. Uma boa orientação sobre como criar e usar o depurador DOSBox pode ser encontrada
aqui .
Ao usar o IDA e o depurador DOSBox juntos, torna-se aparente que o arquivo NDX é usado como um índice para o arquivo RES. Cada entrada no arquivo NDX leva 16 bytes; Ele armazena o identificador do fragmento, seu tamanho e deslocamento no arquivo RES. Observando como os dados do RES são lidos, você pode ver que o byte do sinalizador é verificado primeiro no arquivo NDX. Se o bit 0x80 não estiver definido, os dados serão lidos diretamente do arquivo RES, caso contrário, um caminho de código mais complexo será executado. O sinalizador é definido para a maioria dos fragmentos, portanto, com um alto grau de probabilidade, podemos assumir que denota algum tipo de compactação usada para esses fragmentos.
Compressão
O caminho de compactação começa lendo da base do fragmento RES duas palavras de 32 bits, indicando os tamanhos inicial e final e, em seguida, a função de descompressão é chamada. Em 1991, a codificação simples de comprimento de execução (RLE) e a compactação de dicionário eram populares, como vários algoritmos Liv-Zempel. O início do ciclo de descompactação é assim:
Os tokens para descompactar são obtidos usando a função get_next_token, que lê a próxima parte dos dados de origem em ax: dx com um deslocamento por cl. O registro cl é usado como a posição da troca de bits, retornando a zero após atingir oito. No início do ciclo, o token é lido e o bit inferior é verificado. Se o sinalizador estiver definido, o código será simples:
Ele apenas salva o byte atual, recebe o próximo token e continua a trabalhar. Se o sinalizador estiver limpo, um caminho de código mais longo é selecionado, que termina com a instrução rep movsb. Isso indica que algum tipo de dicionário é usado na compactação.
O algoritmo de compactação é interessante por vários motivos. Em primeiro lugar, ele usa codificação de tamanho de bit variável. O valor absoluto é codificado como 1 sinalizador e um valor de dados de 8 bits. Curiosamente, o fluxo de bits é codificado como pouco endian. Isso complica um pouco a análise da descompressão, observando o arquivo RES em um editor hexadecimal. Por exemplo, se os três primeiros bytes de um fragmento forem codificados como valores absolutos, os dados serão organizados da seguinte maneira:
: AAAAAAAA BBBBBBBB CCCCCCCC DDDDDDDD 1: 6543210F 7 2: 543210F 76 3: 43210F 765
Além disso, o desempacotador pode pular o byte ao ler, se o contador cl voltar a zero após o recebimento do próximo token. Não sei se isso é otimização, um bug ou um hack criado pelo desenvolvedor do jogo para corrigir o problema com minhas ferramentas.
Se o sinalizador for limpo, o desempacotador realiza a cópia da parte inicial dos dados desempacotados. Nesse caso, os seguintes bits codificam o comprimento e o deslocamento do qual copiar. O deslocamento é codificado em 10 ou 13 bits e a opção desejada indica o sinalizador. Parece uma escolha muito estranha, porque complica um pouco o código e, na melhor das hipóteses, economiza apenas 2 bits.
Codificar o comprimento da série parece um pouco estranho. O desempacotador lê os bits até atingir o bit zero. Então, o número de bits usado para codificar o comprimento é dois mais o número de bits diferentes de zero. Por exemplo, ao codificar um comprimento de 58 (0x3a), o fluxo de bits fica assim:
11110 111010
A codificação requer 11 bits. Comprimentos pequenos são melhor codificados porque o tamanho mínimo de bit é 2. Cópias de até 3 requerem apenas 3 bits para codificação, até 7 requerem 5 bits e assim por diante. Não sei ao certo se esse tipo de codificação é uma técnica comum.
O depurador DOSBox também é muito útil para reconstruir o algoritmo de descompressão. Se você não souber como devem ser os dados descompactados, será difícil entender se o desempacotador funciona corretamente. Usando o depurador, você pode percorrer todo o algoritmo de descompressão e salvar um despejo de memória descompactada para comparação.
Outro recurso útil é o sinalizador no arquivo NDX, indicando que o recurso está compactado. Como o jogo original suporta recursos descompactados, podemos reembalar o arquivo RES sem a necessidade de um algoritmo de compactação. Modificar e reembalar fragmentos com o lançamento subsequente do jogo é uma boa maneira de testar nossas suposições sobre os formatos de dados.
Níveis
Fantastic Dizzy é um jogo com um mundo aberto. Níveis são áreas com rolagem vertical ou horizontal. O jogador se move entre os níveis, chegando ao final do nível ou entrando e saindo de edifícios. Embora as referências aos fragmentos no arquivo RES sejam feitas por meio de identificadores (IDs) de 16 bits, o arquivo binário do jogo realmente contém uma tabela de nomes de níveis correspondentes aos identificadores de fragmento. Cada nível consiste em vários fragmentos: um título, uma ou mais camadas, um conjunto de peças e uma paleta. Há pouca redundância aqui, porque alguns níveis usam a mesma paleta e conjunto de peças, mas não reutilizam os mesmos fragmentos; portanto, o arquivo RES contém muitos recursos duplicados.
Camadas codificam blocos para um nível. Para diferentes partes do mundo ou para camadas de fundo, você pode usar camadas adicionais. Por exemplo, no nível do tree1.stg, existem oito camadas para diferentes partes do topo das árvores e uma camada de fundo comum. No entanto, os níveis subaquáticos são divididos em sea1.stg e sea2.stg, cada um com uma camada em primeiro plano e uma em segundo plano.
As camadas de fundo são fundos de largura fixa sem rolagem, por exemplo, uma floresta em uma parte de um jogo com copas de árvores. Os blocos de primeiro e segundo plano, localizados na frente e atrás do personagem, são codificados na mesma camada dos blocos em que você pode caminhar. Por exemplo, a captura de tela mostra o nível das copas das árvores desde o início do jogo:
Nível das copas das árvoresÉ a sétima camada do tree1.stg:
Sétimo nível da camada tree1.stgVale ressaltar que o jogador pode passar na frente da cabana, mas atrás de duas árvores. Todas as informações de bloco estão contidas em uma matriz de mapa de bloco localizada em uma camada. Os blocos nos fragmentos da camada são codificados em dois bytes e os 9 bits inferiores são usados para o índice do bloco. Não entendi completamente os bits superiores, mas pelo menos eles contêm informações sobre a mudança da paleta para o bloco e, provavelmente, informações sobre colisões.
Como níveis no jogo, cenas, retratos de personagens e uma tela de controle de inventário também são armazenados. Parece que essa técnica é padrão para jogos do DOS, provavelmente porque minimiza a quantidade de código necessária.
"Nível" de gerenciamento de inventárioSprites
O formato do sprite não é particularmente interessante. Cada sprite é um bitmap com um byte por pixel, mas com apenas 16 cores por sprite. O uso de um número limitado de cores era uma técnica comum na era do VGA de 256 cores, porque para sprites era fácil executar a troca de paleta ou usá-la em níveis com outras paletas; além disso, economizou o espaço alocado para sprites.
Os sprites têm tamanhos diferentes, portanto, um fragmento separado contém informações sobre o tamanho do sprite e seus deslocamentos em x e y. Os sprites são agrupados em conjuntos, mas o agrupamento parece bastante arbitrário. Por exemplo, um conjunto de sprites contém gráficos de proteção de tela, objetos de inventário e alguns personagens que não são jogadores. Isso torna a visualização de conjuntos de sprites um pouco complicada, porque a paleta não é a mesma para todos os sprites.
Sprites de Personagem do JogadorO que mais resta?
Resta fazer a engenharia reversa de mais algumas coisas. Principalmente, estou interessado em formatos de arquivo de dados, mas há alguns aspectos que não entendo:
- Onde estão os locais dos objetos (chaves, frutas, etc.). Parece que eles não estão escritos em fragmentos de nível. Talvez eles estejam armazenados no arquivo binário do jogo, porque o jogador pode pegar um objeto em um nível e jogá-lo em outro.
- Como as colisões de nível funcionam. Um jogador pode andar na frente ou atrás de alguns ladrilhos, e o piso pode ser plano ou inclinado.
- Como os níveis estão conectados. Esta informação pode ser armazenada no binário do jogo.
- A mudança da paleta para blocos nos níveis não está totalmente correta. Alguns blocos exibem cores incorretas.
- Cada conjunto de sprites possui três fragmentos: cabeçalho, tabela e dados. Fragmentos com uma tabela e dados são claros para mim, mas algumas informações sobre sprites estão incluídas no cabeçalho, por exemplo, o deslocamento em x e y. Não entendi completamente o formato.