Com a disseminação e desenvolvimento de redes neurais, há uma necessidade crescente de usá-las em dispositivos embarcados e de baixa potência, robôs e drones. O dispositivo Neural Compute Stick, em conjunto com a estrutura Intel OpenVINO, nos permite resolver esse problema, realizando cálculos pesados de redes neurais. Graças a isso, você pode iniciar facilmente um classificador ou detector de rede neural em um dispositivo de baixa potência como o Raspberry Pi quase em tempo real, sem aumentar significativamente o consumo de energia. Nesta postagem, mostrarei como usar a estrutura OpenVINO (em C ++) e o Neural Compute Stick para lançar um sistema simples de detecção de rosto no Raspberry Pi.
Como sempre, todo o código está disponível no
GitHub .

Um pouco sobre o Neural Compute Stick e o OpenVINO
No verão de 2017, a Intel lançou o dispositivo
Neural Compute Stick (NCS), projetado para executar redes neurais em dispositivos de baixo consumo de energia, e após alguns meses ele pôde ser comprado e testado, o que eu fiz. O NCS é um pequeno módulo de computação com uma caixa de cor azul (também atuando como um radiador), conectado ao dispositivo principal via USB. Dentro, entre outras coisas, está o Intel Myriad
VPU , que é essencialmente um processador paralelo de 12 núcleos, aprimorado para operações que ocorrem frequentemente em redes neurais. O NCS não é adequado para o treinamento de redes neurais, mas a inferência em redes neurais já treinadas é comparável em velocidade à da GPU. Todos os cálculos no NCS são realizados em números flutuantes de 16 bits, o que permite aumentar a velocidade. O NCS requer apenas 1 Watt de energia para operar, ou seja, a 5 V, uma corrente de até 200 mA é consumida no conector USB - isso é ainda menos do que a câmera do Raspberry Pi (250 mA).

Para trabalhar com o primeiro NCS, o
Neural Compute SDK (NCSDK) foi usado: inclui ferramentas para compilar redes neurais nos formatos
Caffe e
TensorFlow para o formato NCS, ferramentas para medir seu desempenho, bem como as APIs Python e C ++ para inferência.
Em seguida, uma nova versão da estrutura NCS foi lançada:
NCSDK2 . A API mudou bastante e, embora algumas mudanças parecessem estranhas para mim, houve algumas inovações úteis. Em particular, foi adicionada a conversão automática de float 32 bits para float 16 bits em C ++ (anteriormente, as muletas tinham que ser inseridas na forma de código do Numpy). Também apareceram filas de imagens e os resultados de seu processamento.
Em maio de 2018, a Intel lançou o
OpenVINO (anteriormente chamado de Intel Computer Vision SDK). Essa estrutura foi projetada para iniciar com eficiência redes neurais em vários dispositivos: processadores e placas gráficas Intel,
FPGA e também o Neural Compute Stick.
Em novembro de 2018, uma nova versão do acelerador foi lançada:
Neural Compute Stick 2 . O poder de computação do dispositivo aumentou: na descrição no site eles prometem aceleração de até 8x, no entanto, não pude testar a nova versão do dispositivo. A aceleração é alcançada aumentando o número de núcleos de 12 para 16, além de adicionar novos dispositivos de computação otimizados para redes neurais. É verdade que não encontrei informações sobre o consumo de energia das informações.
A segunda versão do NCS já é incompatível com NCSDK ou NCSDK2: o OpenVINO, que é capaz de trabalhar com muitos outros dispositivos além das duas versões do NCS, passou sua autoridade. O próprio OpenVINO possui ótima funcionalidade e inclui os seguintes componentes:
- Otimizador de modelo: script Python que permite converter redes neurais de estruturas populares de aprendizado profundo no formato universal OpenVINO. A lista de estruturas suportadas: Caffe , TensorFlow , MXNET , Kaldi (estrutura de reconhecimento de fala), ONNX (formato aberto para representar redes neurais).
- Mecanismo de inferência: C ++ e API Python para inferência de rede neural, abstraídas de um dispositivo de inferência específico. O código da API será quase idêntico para CPU, GPU, FPGA e NCS.
- Um conjunto de plugins para diferentes dispositivos. Plugins são bibliotecas dinâmicas carregadas explicitamente no código do programa principal. Estamos mais interessados no plugin para o NCS.
- Um conjunto de modelos pré-treinados no formato universal OpenVINO (a lista completa está aqui ). Uma impressionante coleção de redes neurais de alta qualidade: detectores de rostos, pedestres, objetos; reconhecimento da orientação de rostos, pontos especiais de rostos, posturas humanas; super resolução; e outros Vale ressaltar que nem todos eles são suportados pelo NCS / FPGA / GPU.
- Model Downloader: outro script que simplifica o download de modelos no formato OpenVINO pela rede (embora você possa fazer isso facilmente).
- Biblioteca de visão computacional OpenCV otimizada para hardware Intel.
- Biblioteca de visão computacional OpenVX .
- Biblioteca de computação Intel para redes neurais profundas .
- Biblioteca Intel Kernel de matemática para redes neurais profundas .
- Uma ferramenta para otimizar redes neurais para FPGA (opcional).
- Documentação e exemplos de programas.
Nos meus artigos anteriores, falei sobre como executar o detector de rosto YOLO no NCS
(primeiro artigo) , além de como treinar seu detector de rosto SSD e executá-lo no Raspberry Pi e NCS
(segundo artigo) . Nestes artigos, usei NCSDK e NCSDK2. Neste artigo, mostrarei como fazer algo semelhante, mas usando o OpenVINO, farei uma pequena comparação dos dois detectores de rosto diferentes e duas estruturas para iniciá-los, e apontarei algumas armadilhas. Eu escrevo em C ++, porque acredito que dessa maneira você poderá obter um melhor desempenho, o que será importante no caso do Raspberry Pi.
Instale o OpenVINO
Não é a tarefa mais difícil, embora haja sutilezas. No momento em que escrevi, o OpenVINO suporta apenas o Ubuntu 16.04 LTS, CentOS 7.4 e Windows 10. Eu tenho o Ubuntu 18 instalado e preciso de
pequenas muletas para instalá-lo. Eu também queria comparar o OpenVINO com o NCSDK2, cuja instalação também apresenta problemas: em particular, aperta suas versões do Caffe e TensorFlow e pode alterar um pouco as configurações do ambiente. No final, decidi seguir um caminho simples e instalar as duas estruturas em uma máquina virtual com o Ubuntu 16 (eu uso o
VirtualBox ).
Vale ressaltar que, para conectar com êxito o NCS a uma máquina virtual, é necessário instalar os complementos de convidados do VirtualBox e ativar o suporte ao USB 3.0. Também adicionei um filtro universal para dispositivos USB, pelo qual o NCS se conectou sem problemas (embora a webcam ainda precise ser conectada nas configurações da máquina virtual). Para instalar e compilar o OpenVINO, você precisa ter uma conta Intel, escolha uma opção de estrutura (com ou sem suporte a FPGA) e siga as
instruções . O NCSDK é ainda mais simples: ele inicializa
no GitHub (não esqueça de selecionar o ramo ncsdk2 para a nova versão do framework), após o qual você precisa
make install .
O único problema que encontrei ao executar o NCSDK2 em uma máquina virtual é um erro do seguinte formato:
E: [ 0] dispatcherEventReceive:236 dispatcherEventReceive() Read failed -1 E: [ 0] eventReader:254 Failed to receive event, the device may have reset
Ocorre no final da execução correta do programa e (ao que parece) não afeta nada. Aparentemente, esse é um
pequeno bug relacionado à VM (não deve estar no Raspberry).
A instalação no Raspberry Pi é significativamente diferente. Primeiro, verifique se o Raspbian Stretch está instalado: ambas as estruturas funcionam oficialmente apenas neste sistema operacional. O NCSDK2 precisa ser
compilado no modo somente API , caso contrário, ele tentará instalar o Caffe e o TensorFlow, o que dificilmente agradará seu Raspberry. No caso do OpenVINO, existe uma
versão já
montada para o Raspberry , que você só precisa descompactar e configurar as variáveis de ambiente. Nesta versão, há apenas API C ++ e Python, além da biblioteca OpenCV, todas as outras ferramentas não estão disponíveis. Isso significa que, para ambas as estruturas, os modelos devem ser convertidos antecipadamente em uma máquina com o Ubuntu. Minha
demonstração de detecção de rosto funciona no Raspberry e na área de trabalho, então acabei de adicionar os arquivos de rede neural convertidos ao meu repositório GitHub para facilitar a sincronização com o Raspberry. Eu tenho um Raspberry Pi 2 modelo B, mas deve decolar com outros modelos.
Há outra sutileza em relação à interação do Raspberry Pi e do Neural Compute Stick: se, no caso de um laptop, basta enfiar o NCS na porta USB 3.0 mais próxima, então para o Raspberry você precisará encontrar um cabo USB, caso contrário, o NSC bloqueará os três conectores USB restantes com seu corpo. Também vale lembrar que o Raspberry possui todas as versões USB 2.0, portanto a taxa de inferência será menor devido a atrasos na comunicação (uma comparação detalhada será posterior). Mas se você deseja conectar dois ou mais NCS ao Raspberry, provavelmente precisará encontrar um hub USB com energia adicional.
Como é o código do OpenVINO
Muito volumoso. Há muitas ações diferentes a serem iniciadas, começando com o carregamento do plug-in e terminando com a inferência - foi por isso que escrevi uma classe de invólucro para o detector. O código completo pode ser visualizado no GitHub, mas aqui apenas listo os pontos principais. Vamos começar em ordem:
As definições de todas as funções que precisamos estão no arquivo
inference_engine.hpp no espaço para nome
InferenceEngine .
#include <inference_engine.hpp> using namespace InferenceEngine;
As seguintes variáveis serão necessárias o tempo todo. precisamos de
inputName e
outputName para endereçar a entrada e a saída da rede neural. De um modo geral, uma rede neural pode ter muitas entradas e saídas, mas em nossos detectores haverá uma de cada vez. A variável
net é a própria rede,
request é um ponteiro para a última solicitação de inferência,
inputBlob é um ponteiro para a matriz de dados de entrada da rede neural. As demais variáveis falam por si.
string inputName; string outputName; ExecutableNetwork net; InferRequest::Ptr request; Blob::Ptr inputBlob;
Agora faça o download do plug-in necessário - precisamos do responsável pelo NCS e NCS2, que pode ser obtido com o nome "MYRIAD". Deixe-me lembrá-lo que, no contexto do OpenVINO, um plug-in é apenas uma biblioteca dinâmica que se conecta por solicitação explícita. O parâmetro da função
PluginDispatcher é uma lista de diretórios nos quais procurar plug-ins. Se você configurar as variáveis de ambiente de acordo com as instruções, uma linha vazia será suficiente. Para referência, os plugins estão em
[OpenVINO_install_dir]/deployment_tools/inference_engine/lib/ubuntu_16.04/intel64/ InferencePlugin plugin = PluginDispatcher({""}).getPluginByDevice("MYRIAD");
Agora crie um objeto para carregar a rede neural, considere sua descrição e defina o tamanho do lote (o número de imagens processadas simultaneamente). Uma rede neural no formato OpenVINO é definida por dois arquivos: um .xml com uma descrição da estrutura e um .bin com pesos. Embora possamos usar detectores prontos do OpenVINO, mais tarde criaremos os nossos. Aqui
std::string filename é o nome do arquivo sem a extensão. Você também precisa ter em mente que o NCS suporta apenas um tamanho de lote 1.
CNNNetReader netReader; netReader.ReadNetwork(filename+".xml"); netReader.ReadWeights(filename+".bin"); netReader.getNetwork().setBatchSize(1);
Então acontece o seguinte:
- Para entrar na rede neural, defina o tipo de dados como char não assinado de 8 bits. Isso significa que podemos inserir a imagem no formato em que ela vem da câmera, e o InferenceEngine cuidará da conversão (o NCS realiza cálculos no formato float de 16 bits). Isso irá acelerar um pouco no Raspberry Pi - pelo que entendi, a conversão é feita no NCS, portanto, há menos atrasos na transferência de dados via USB.
- Nós obtemos os nomes de entrada e saída, para que mais tarde possamos acessá-los.
- Nós obtemos a descrição das saídas (este é um mapa do nome da saída para um ponteiro para um bloco de dados). Recebemos um ponteiro para o bloco de dados da primeira saída (única).
- Temos seu tamanho: 1 x 1 x número máximo de detecções x comprimento da descrição da detecção (7). Sobre o formato da descrição das detecções - mais tarde.
- Defina o formato de saída para flutuar 32 bits. Novamente, a conversão do float 16 bits cuida do InferenceEngine.
Agora, o ponto mais importante: carregamos a rede neural no plug-in (ou seja, no NCS). Aparentemente, a compilação para o formato desejado está em andamento. Se o programa travar nessa função, a rede neural provavelmente não é adequada para este dispositivo.
net = plugin.LoadNetwork(netReader.getNetwork(), {});
E finalmente - faremos uma inferência experimental e obteremos os tamanhos de entrada (talvez isso possa ser feito de maneira mais elegante). Primeiro, abrimos uma solicitação de inferência, depois obtemos um link para o bloco de dados de entrada e já solicitamos o tamanho dele.
Vamos tentar fazer upload de uma imagem para o NCS. Da mesma forma, criamos uma solicitação de inferência, obtemos um ponteiro para um bloco de dados e, a partir daí, obtemos um ponteiro para o próprio array. Em seguida, basta copiar os dados da nossa imagem (aqui já está reduzido ao tamanho desejado). Vale ressaltar que no
cv::Mat e
inputBlob medidas são armazenadas em ordem diferente (no OpenCV, o índice do canal muda mais rápido que tudo, no OpenVINO é mais lento que tudo), portanto, o memcpy não é suficiente. Então começamos a inferência assíncrona.
Por que assíncrono? Isso otimizará a alocação de recursos. Enquanto o NCS considera a rede neural, você pode processar o próximo quadro - isso levará a uma aceleração perceptível no Raspberry Pi.
cv::Mat data; ...
Se você conhece bem as redes neurais, pode ter uma pergunta sobre em que ponto dimensionamos os valores dos pixels de entrada da rede neural (por exemplo, trazemos para o intervalo
[ 0 , 1 ] ) O fato é que, nos modelos OpenVINO, essa transformação já está incluída na descrição da rede neural e, ao usar nosso detector, faremos algo semelhante. E como a conversão em float e a escala de entradas são realizadas pelo OpenVINO, precisamos redimensionar a imagem.
Agora (depois de fazer algum trabalho útil), concluiremos o pedido de inferência. O programa é bloqueado até que os resultados da execução cheguem. Temos um ponteiro para o resultado.
float * output; ncsCode = request->Wait(IInferRequest::WaitMode::RESULT_READY); output = request->GetBlob(outputName)->buffer().as<float*>();
Agora é hora de pensar em que formato o NCS retorna o resultado do detector. Vale ressaltar que o formato é um pouco diferente do que era ao usar o NCSDK. De um modo geral, a saída do detector é quadridimensional e possui uma dimensão (1 x 1 x número máximo de detecções x 7), podemos assumir que essa é uma matriz de tamanho (
maxNumDetectedFaces x 7).
O parâmetro
maxNumDetectedFaces é definido na descrição da rede neural e é fácil alterá-lo, por exemplo, na descrição .prototxt da rede no formato Caffe. Anteriormente, obtivemos o objeto que representa o detector. Este parâmetro está relacionado às especificidades da classe de detectores
SSD (Single Shot Detector) , que inclui todos os detectores NCS suportados. Um SSD sempre considera o mesmo número (e muito grande) de caixas delimitadoras para cada imagem e, depois de filtrar as detecções com uma classificação de confiança baixa e remover os quadros sobrepostos usando a supressão não máxima, eles geralmente deixam os 100-200 melhores. É exatamente por isso que o parâmetro é responsável.
Os sete valores na descrição de uma detecção são os seguintes:
- o número da imagem no lote em que o objeto é detectado (no nosso caso, deve ser zero);
- classe de objeto (0 - segundo plano, a partir de 1 - outras classes, somente as detecções com uma classe positiva são retornadas);
- confiança na presença de detecção (no intervalo [ 0 , 1 ] );
- coordenada x normalizada do canto superior esquerdo da caixa delimitadora (no intervalo [ 0 , 1 ] );
- da mesma forma - coordenada y;
- largura normalizada da caixa delimitadora (no intervalo [ 0 , 1 ] );
- da mesma forma - altura;
Código para extrair caixas delimitadoras da saída do detector void get_detection_boxes(const float* predictions, int numPred, int w, int h, float thresh, std::vector<float>& probs, std::vector<cv::Rect>& boxes) { float score = 0; float cls = 0; float id = 0;
aprendemos
numPred partir do próprio detector
w,h - tamanhos de imagem para visualização.
Agora, sobre como é o esquema geral de inferência em tempo real. Primeiro, inicializamos a rede neural e a câmera, iniciamos
cv::Mat para quadros brutos e mais um para quadros reduzidos ao tamanho desejado. Enchemos nossos quadros com zeros - isso aumentará a confiança de que, em um único começo, a rede neural não encontrará nada. Então começamos o ciclo de inferência:
- Carregamos o quadro atual na rede neural usando uma solicitação assíncrona - o NCS já começou a funcionar e, neste momento, temos a oportunidade de tornar o trabalho principal útil no processador principal.
- Exibimos todas as detecções anteriores no quadro anterior, desenhamos um quadro (se necessário).
- Obtemos um novo quadro da câmera, compactamos no tamanho desejado. Para o Raspberry, recomendo usar o algoritmo de redimensionamento mais simples - no OpenCV, essa é a interpolação de vizinhos mais próximos. Isso não afetará a qualidade do desempenho do detector, mas pode adicionar um pouco de velocidade. Também espelho o quadro para facilitar a visualização (opcional).
- Agora é a hora de obter o resultado com o NCS, preenchendo a solicitação de inferência. O programa será bloqueado até que o resultado seja recebido.
- Processamos novas detecções, selecionamos quadros.
- O resto: exercitar as teclas digitadas, contar quadros, etc.
Como compilá-lo
Nos exemplos do InferenceEngine, eu não gostei dos arquivos CMake volumosos e decidi reescrever tudo no meu Makefile:
g++ $(RPI_ARCH) \ -I/usr/include -I. \ -I$(OPENVINO_PATH)/deployment_tools/inference_engine/include \ -I$(OPENVINO_PATH_RPI)/deployment_tools/inference_engine/include \ -L/usr/lib/x86_64-linux-gnu \ -L/usr/local/lib \ -L$(OPENVINO_PATH)/deployment_tools/inference_engine/lib/ubuntu_16.04/intel64 \ -L$(OPENVINO_PATH_RPI)/deployment_tools/inference_engine/lib/raspbian_9/armv7l \ vino.cpp wrapper/vino_wrapper.cpp \ -o demo -std=c++11 \ `pkg-config opencv --cflags --libs` \ -ldl -linference_engine $(RPI_LIBS)
Essa equipe trabalhará no Ubuntu e Raspbian, graças a alguns truques. Os caminhos para procurar cabeçalhos e bibliotecas dinâmicas que eu indiquei para o Raspberry e a máquina Ubuntu. Das bibliotecas, além do OpenCV, você também deve conectar o
libinference_engine e o
libdl - uma biblioteca para vincular dinamicamente outras bibliotecas, é necessário para carregar o plug-in. Ao mesmo tempo, o próprio
libmyriadPlugin não precisa ser especificado. Entre outras coisas, para o Raspberry, também conecto a biblioteca
Raspicam para trabalhar com a câmera (este é
$(RPI_LIBS) ). Eu também tive que usar o padrão C ++ 11.
Separadamente, é importante notar que, ao compilar no Raspberry, o
-march=armv7-a é necessário (este é
$(RPI_ARCH) ). Se você não o especificar, o programa será compilado, mas falhará com um segfault silencioso. Você também pode adicionar otimizações usando
-O3 , isso aumentará a velocidade.
Quais são os detectores
O NCS suporta apenas detectores Caffe SSD da caixa, embora com alguns truques sujos eu consegui executar o
YOLO do formato Darknet nele.
O Single Shot Detector (SSD) é uma arquitetura popular entre redes neurais leves e, com a ajuda de diferentes codificadores (ou redes de backbone), você pode variar de forma flexível a proporção de velocidade e qualidade.
Vou experimentar com diferentes detectores de rosto:
- YOLO, retirado daqui , convertido primeiro para o formato Caffe, depois para o formato NCS (somente com NCSDK). Imagem 448 x 448.
- Meu detector Mobilenet + SSD, sobre o treinamento sobre o qual falei em uma publicação anterior . Ainda tenho uma versão recortada desse detector, que vê apenas rostos pequenos e, ao mesmo tempo, um pouco mais rápido. Vou verificar a versão completa do meu detector no NCSDK e no OpenVINO. Imagem 300 x 300.
- Detector de detecção de rosto adas-0001 do OpenVINO: MobileNet + SSD. Imagem 384 x 672.
- Detector OpenVINO de detecção de rosto-varejo-0004: leve SqueezeNet + SSD. Imagem 300 x 300.
Para detectores do OpenVINO, não há escalas no formato Caffe ou no formato NCSDK, portanto, só posso iniciá-las no OpenVINO.
Transforme seu detector em formato OpenVINO
Eu tenho dois arquivos no formato Caffe: .prototxt com uma descrição da rede e .caffemodel com pesos. Preciso obter dois arquivos deles no formato OpenVINO: .xml e .bin com uma descrição e pesos, respectivamente. Para fazer isso, use o script mo.py do OpenVINO (também conhecido como Model Optimizer):
mo.py \ --framework caffe \ --input_proto models/face/ssd-face.prototxt \ --input_model models/face/ssd-face.caffemodel \ --output_dir models/face \ --model_name ssd-vino-custom \ --mean_values [127.5,127.5,127.5] \ --scale_values [127.5,127.5,127.5] \ --data_type FP16
output_dir especifica o diretório em que novos arquivos serão criados,
model_name é o nome para novos arquivos sem extensão,
data_type (FP16/FP32) é o tipo de saldo na rede neural (o NCS suporta apenas FP16). Os
mean_values, scale_values definem a média e a escala para pré-processar as imagens antes de serem lançadas na rede neural. A conversão específica é assim:
(pixel values−média values)/scale values
Nesse caso, os valores são convertidos do intervalo
[0,255] no intervalo
[0,1] . Em geral, esse script possui muitos parâmetros, alguns dos quais são específicos para estruturas individuais. Recomendamos que você consulte o manual do script.
A distribuição OpenVINO para Raspberry não possui modelos prontos, mas eles são bastante simples de baixar.
Por exemplo, assim. wget --no-check-certificate \ https://download.01.org/openvinotoolkit/2018_R4/open_model_zoo/face-detection-retail-0004/FP16/face-detection-retail-0004.xml \ -O ./models/face/vino.xml; \ wget --no-check-certificate \ https://download.01.org/openvinotoolkit/2018_R4/open_model_zoo/face-detection-retail-0004/FP16/face-detection-retail-0004.bin \ -O ./models/face/vino.bin
Comparação de detectores e estruturas
Usei três opções de comparação: 1) NCS + Máquina Virtual com Ubuntu 16.04, processador Core i7, conector USB 3.0; 2) NCS + A mesma máquina, conector USB 3.0 + cabo USB 2.0 (haverá mais atraso na troca com o dispositivo); 3) NCS + Raspberry Pi 2 modelo B, Raspbian Stretch, conector USB 2.0 + cabo USB 2.0.
Iniciei meu detector com o OpenVINO e o NCSDK2, detectores do OpenVINO apenas com sua estrutura nativa, YOLO apenas com o NCSDK2 (provavelmente, ele também pode ser executado no OpenVINO).
A tabela FPS para diferentes detectores é semelhante a esta (os números são aproximados):
| Modelo | USB 3.0 | USB 2.0 | Raspberry pi |
|---|
| SSD personalizado com NCSDK2 | 10,8 | 9,3 | 7.2 |
| SSD de longo alcance personalizado com NCSDK2 | 11,8 | 10.0 | 7.3 |
| YOLO v2 com NCSDK2 | 5.3 | 4.6 | 3.6. |
| SSD personalizado com OpenVINO | 10,6 | 9,9 | 7,9 |
| OpenVINO detecção de rosto-varejo-0004 | 15,6 | 14,2 | 9,3 |
| Detecção de rosto OpenVINO-adas-0001 | 5,8 | 5.5 | 3.9 |
Nota: o desempenho foi medido para todo o programa de demonstração, incluindo processamento e visualização de quadros.YOLO foi o mais lento e mais instável de todos. Frequentemente ignora a detecção e não pode funcionar com quadros iluminados.
O detector que eu treinei funciona duas vezes mais rápido, é mais resistente à distorção nos quadros e até detecta rostos pequenos. No entanto, às vezes ainda ignora a detecção e, às vezes, detecta falsos. Se você cortar as últimas camadas, ela se tornará um pouco mais rápida, mas deixará de ver rostos grandes. O mesmo detector lançado pelo OpenVINO se torna um pouco mais rápido ao usar o USB 2.0, a qualidade não muda visualmente.
Os detectores OpenVINO, é claro, são muito superiores ao YOLO e ao meu detector. (Eu nem começaria a treinar meu detector se o OpenVINO existisse na sua forma atual naquele momento). O modelo retail-0004 é muito mais rápido e quase nunca erra o rosto, mas consegui enganá-lo um pouco (embora a confiança nessas detecções seja baixa):
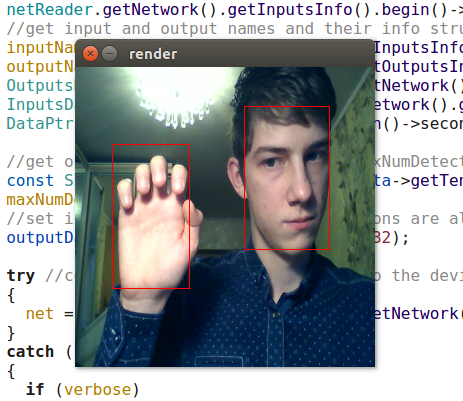 Ataque competitivo da inteligência natural contra artificial
Ataque competitivo da inteligência natural contra artificialO detector adas-0001 é muito mais lento, mas funciona com imagens grandes e deve ser mais preciso. Não percebi a diferença, mas verifiquei quadros bastante simples.
Conclusão
Em geral, é muito bom que, em um dispositivo de baixa energia como o Raspberry Pi, você possa usar redes neurais e até em tempo quase real. O OpenVINO fornece uma funcionalidade muito extensa para a inferência de redes neurais em muitos dispositivos diferentes - muito mais ampla do que eu descrevi no artigo.
Acho que o Neural Compute Stick e o OpenVINO serão muito úteis na minha pesquisa robótica.