Fui solicitado a escrever este artigo com uma grande quantidade de materiais sobre análise estática, que cada vez mais chamam minha atenção. Primeiro, este é o
blog do
PVS-studio , que está se promovendo ativamente no Habré com a ajuda de análises de erros encontradas por sua ferramenta em projetos de código aberto. Recentemente, o PVS-studio implementou
suporte para Java e, é claro, os desenvolvedores do IntelliJ IDEA, cujo analisador embutido é provavelmente o mais avançado para Java atualmente,
não puderam ficar de fora .
Ao ler essas resenhas, parece que estamos falando de um elixir mágico: clique no botão e aqui está - uma lista de defeitos diante de seus olhos. Parece que, à medida que os analisadores melhoram, mais e mais erros são encontrados automaticamente, e os produtos verificados por esses robôs se tornam cada vez melhores, sem nenhum esforço de nossa parte.
Mas não há elixires mágicos. Eu gostaria de falar sobre algo que geralmente não é mencionado em posts como “estas são as coisas que nosso robô pode encontrar”: o que os analisadores não podem fazer, qual é o seu real papel e lugar no processo de entrega do software e como implementá-los corretamente.
 Catraca (fonte: Wikipedia ).
Catraca (fonte: Wikipedia ).O que os analisadores estáticos nunca podem
O que é, do ponto de vista prático, a análise do código fonte? Submetemos algumas fontes à entrada e, na saída em um curto espaço de tempo (muito menor que a execução do teste), obtemos algumas informações sobre nosso sistema. A limitação fundamental e matematicamente intransponível é que só podemos obter uma classe de informações bastante restrita dessa maneira.
O exemplo mais famoso de um problema que não pode ser resolvido com a ajuda da análise estática é
o problema de desligamento : este é um teorema que prova que é impossível desenvolver um algoritmo geral que determinaria pelo código fonte de um programa se ele repetir ou terminar em um tempo finito. Uma extensão desse teorema é
o teorema de Rice, que afirma que, para qualquer propriedade não trivial de funções computáveis, determinar se um programa arbitrário calcula uma função com essa propriedade é um problema algoritmicamente insolúvel. Por exemplo, é impossível escrever um analisador que determine por qualquer código fonte se o programa que está sendo analisado é uma implementação de um algoritmo que calcula, digamos, o quadrado de um número inteiro.
Assim, a funcionalidade dos analisadores estáticos tem limitações intransponíveis. Em todos os casos, o analisador estático nunca poderá detectar coisas como, por exemplo, a ocorrência de uma "exceção de ponteiro nulo" em idiomas anuláveis ou em todos os casos determinará a ocorrência de um "atributo não encontrado" em idiomas dinamicamente digitados. Tudo o que o analisador estático mais avançado pode fazer é destacar casos particulares, cujo número entre todos os possíveis problemas com o seu código-fonte é, sem exagero, uma queda no balde.
A análise estática não é uma pesquisa de bug
A conclusão segue do exposto acima: a análise estática não é um meio de reduzir o número de defeitos em um programa. Atrevo-me a afirmar: quando aplicado pela primeira vez ao seu projeto, ele encontrará lugares "ocupados" no código, mas provavelmente não encontrará defeitos que afetem a qualidade do seu programa.
Os exemplos de defeitos encontrados automaticamente pelos analisadores são impressionantes, mas não devemos esquecer que esses exemplos foram encontrados ao digitalizar um grande conjunto de grandes bases de códigos. Pelo mesmo princípio, os crackers com a capacidade de enumerar algumas senhas simples em um grande número de contas acabam encontrando as contas que possuem uma senha simples.
Isso significa que a análise estática não precisa ser aplicada? Claro que não! E exatamente pelo mesmo motivo que vale a pena verificar cada nova senha para acessar a lista de senhas "simples".
A análise estática é mais do que a busca de bugs
De fato, as tarefas praticamente resolvidas pela análise são muito mais amplas. De fato, em geral, a análise estática é qualquer verificação das fontes realizadas antes de serem lançadas. Aqui estão algumas coisas que você pode fazer:
- Verificação do estilo de codificação no sentido amplo da palavra. Isso inclui verificar a formatação e procurar o uso de colchetes vazios / extras, definir valores de limite para métricas como o número de linhas / complexidade ciclomática do método etc. - tudo o que potencialmente dificulta a leitura e a manutenção do código. Em Java, essa ferramenta é o Checkstyle, em Python - flake8. Programas desta classe são geralmente chamados de linters.
- Não apenas o código executável pode ser analisado. Arquivos de recursos como JSON, YAML, XML, .properties podem (e devem!) Ser verificados automaticamente quanto à validade. Afinal, é melhor descobrir que, devido a algumas cotações não emparelhadas, a estrutura JSON é violada no estágio inicial da verificação automática de solicitação por solicitação do que na execução de testes ou no tempo de execução? Ferramentas relevantes estão disponíveis: por exemplo, YAMLlint , JSONLint .
- A compilação (ou análise de linguagens de programação dinâmicas) também é uma forma de análise estática. Como regra, os compiladores podem emitir avisos sinalizando problemas com a qualidade do código-fonte e não devem ser ignorados.
- Às vezes, compilação não é apenas compilação de código executável. Por exemplo, se você tiver documentação no formato AsciiDoctor , no momento da conversão em HTML / PDF, o manipulador AsciiDoctor ( plug-in Maven ) poderá emitir avisos, por exemplo, sobre links internos quebrados. E esse é um bom motivo para não aceitar a solicitação de recebimento com alterações na documentação.
- A verificação ortográfica também é uma forma de análise estática. O utilitário aspell é capaz de verificar a ortografia não apenas na documentação, mas também nos códigos-fonte dos programas (comentários e literais) em várias linguagens de programação, incluindo C / C ++, Java e Python. Um erro de ortografia na interface do usuário ou na documentação também é um defeito!
- Testes de configuração (para o que é - veja este e este relatório), embora sejam executados em um ambiente de tempo de execução para testes de unidade como pytest, também são de fato um tipo de análise estática, porque eles não executam códigos-fonte durante sua execução .
Como você pode ver, a busca por bugs nesta lista tem o papel menos importante e todo o resto está disponível através do uso de ferramentas gratuitas de código aberto.
Qual desses tipos de análise estática deve ser usado no seu projeto? Claro, tudo, quanto mais - melhor! O principal é implementá-lo corretamente, o que será discutido mais adiante.
Pipeline de entrega como filtro de vários estágios e análise estática como sua primeira cascata
A metáfora clássica da integração contínua é o pipeline através do qual as alterações fluem - da alteração do código-fonte à entrega à produção. A sequência padrão de etapas neste pipeline é a seguinte:
- análise estática
- compilação
- testes de unidade
- testes de integração
- Testes de interface do usuário
- verificação manual
Alterações rejeitadas no enésimo estágio do transportador não são transferidas para o estágio N + 1.
Por que sim, e não o contrário? Na parte de teste do pipeline, os testadores reconhecem a bem conhecida pirâmide de teste.
 Pirâmide de teste. Fonte: artigo de Martin Fowler.
Pirâmide de teste. Fonte: artigo de Martin Fowler.Na parte inferior desta pirâmide, existem testes mais fáceis de escrever, mais rápidos de executar e sem tendência a falsos positivos. Portanto, deve haver mais, eles devem cobrir mais código e ser executados primeiro. No topo da pirâmide, tudo é o contrário, então o número de testes de integração e interface do usuário deve ser reduzido ao mínimo necessário. A pessoa nesta cadeia é o recurso mais caro, lento e não confiável; portanto, ele está no final e faz o trabalho apenas se as etapas anteriores não revelarem defeitos. No entanto, de acordo com os mesmos princípios, um transportador é construído em peças que não estão diretamente relacionadas aos testes!
Eu gostaria de oferecer uma analogia na forma de um sistema de filtragem de água em vários estágios. Água suja (alterações com defeitos) é fornecida à entrada; na saída, precisamos obter água limpa, na qual toda a poluição indesejável é eliminada.
 Filtro de vários estágios. Fonte: Wikimedia Commons
Filtro de vários estágios. Fonte: Wikimedia CommonsComo você sabe, os filtros de limpeza são projetados para que cada cascata subsequente possa filtrar uma fração cada vez menor de contaminantes. Ao mesmo tempo, cascatas mais grossas têm maior produtividade e menor custo. Em nossa analogia, isso significa que os portões de qualidade de entrada têm maior velocidade, exigem menos esforço para iniciar e são mais despretensiosos em seu trabalho - e é nessa sequência que eles são construídos. O papel da análise estática, que, como agora entendemos, é capaz de eliminar apenas os defeitos mais grosseiros, é o papel da grade da “armadilha de sujeira” no início da cascata do filtro.
A análise estática por si só não melhora a qualidade do produto final, assim como um coletor de lama não produz água potável. No entanto, em conjunto com outros elementos do transportador, sua importância é óbvia. Embora no filtro de vários estágios os estágios de saída sejam potencialmente capazes de capturar tudo da mesma forma que os de entrada, é claro que consequências a tentativa de fazer com estágios finos sem estágios de entrada levará a ele.
O objetivo do "coletor de sujeira" é aliviar as cascatas subsequentes de capturar defeitos muito graves. Por exemplo, pelo menos a pessoa que faz a revisão do código não deve ser distraída pelo código formatado incorretamente e pela violação dos padrões de codificação estabelecidos (como colchetes extras ou ramificações aninhadas muito profundamente). Erros como o NPE devem ser detectados por testes de unidade, mas, mesmo antes do teste, o analisador nos diz que o erro deve acontecer inevitavelmente, isso acelerará significativamente sua correção.
Acredito que agora esteja claro por que a análise estática não melhora a qualidade do produto, se aplicada esporadicamente, e deve ser usada continuamente para detectar alterações com defeitos graves. A questão é se o uso de um analisador estático melhorará a qualidade do seu produto. É aproximadamente equivalente à pergunta "as qualidades de beber da água retirada de um reservatório sujo melhorarão se for passada por uma peneira?"
Implementação em um projeto legado
Uma questão prática importante: como integrar a análise estática ao processo de integração contínua como um “portão da qualidade”? No caso de testes automáticos, tudo é óbvio: há um conjunto de testes, a queda de qualquer um deles é uma razão suficiente para acreditar que a montagem não passou pela barreira da qualidade. Uma tentativa de configurar o portão da mesma maneira com base nos resultados da análise estática falha: há muitos avisos de análise no código legado, você não deseja ignorá-los completamente, mas é impossível interromper a entrega do produto apenas porque ele contém avisos do analisador.
Quando aplicado pela primeira vez, o analisador gera um grande número de avisos em qualquer projeto, a grande maioria dos quais não está relacionada ao bom funcionamento do produto. É impossível corrigir todas essas observações de uma só vez, e muitas não são necessárias. No final, sabemos que nosso produto como um todo funciona e antes da introdução da análise estática!
Como resultado, muitos se limitam ao uso episódico da análise estática ou apenas no modo de informação, quando o relatório do analisador é simplesmente emitido durante a montagem. Isso é equivalente à ausência de qualquer análise, porque se já temos muitos avisos, o surgimento de outro (arbitrariamente sério) ao alterar o código passa despercebido.
Os seguintes métodos de administração de portas de qualidade são conhecidos:
- Definir um limite para o número total de avisos ou o número de avisos dividido pelo número de linhas de código. Isso funciona mal, pois esse portão ignora livremente as alterações com novos defeitos até que seu limite seja excedido.
- Corrigindo, em um determinado momento, todos os avisos antigos no código como ignorados e recusando a criação quando novos avisos ocorrem. Essa funcionalidade é fornecida pelo PVS-studio e alguns recursos online, por exemplo, Codacy. Não pude trabalhar no PVS-studio. Quanto à minha experiência com o Codacy, o principal problema é que determinar o que é “velho” e o que é “novo” é um algoritmo bastante complicado e nem sempre funciona, especialmente se arquivos são fortemente modificados ou renomeados. Na minha memória, o Codacy poderia pular novos avisos na solicitação de recebimento e, ao mesmo tempo, não pular a solicitação de recebimento devido a avisos não relacionados a alterações no código deste PR.
- Na minha opinião, a solução mais eficaz é descrita no livro Entrega contínua "catraca" ("catraca"). A idéia principal é que a propriedade de cada release seja o número de avisos de análise estática, e somente essas alterações são permitidas que não aumentem o número total de avisos.
Catraca
Funciona assim:
- No estágio inicial, o número de avisos no código encontrado pelos analisadores é registrado nos metadados sobre o lançamento. Portanto, ao criar a ramificação principal, não apenas a "versão 7.0.2", mas a "versão 7.0.2, contendo 100500 avisos do estilo de verificação" são gravadas no seu gerenciador de repositório. Se você usar um gerenciador de repositório avançado (como o Artifactory), será fácil salvar esses metadados sobre sua liberação.
- Agora, cada solicitação de recebimento durante a montagem compara o número de avisos recebidos com o número na liberação atual. Se o PR levar a um aumento nesse número, o código não passará pela porta da qualidade para análise estática. Se o número de avisos diminuir ou não mudar, ele passa.
- No próximo release, o número contado de avisos será reescrito nos metadados do release.
Pouco a pouco, mas de forma constante (como na catraca), o número de avisos tenderá a zero. Obviamente, o sistema pode ser enganado introduzindo um novo aviso, mas corrigindo o de outra pessoa. Isso é normal, porque a longa distância dá o resultado: os avisos são geralmente corrigidos, não individualmente, mas imediatamente por um grupo de um determinado tipo, e todos os avisos facilmente eliminados são rapidamente eliminados.
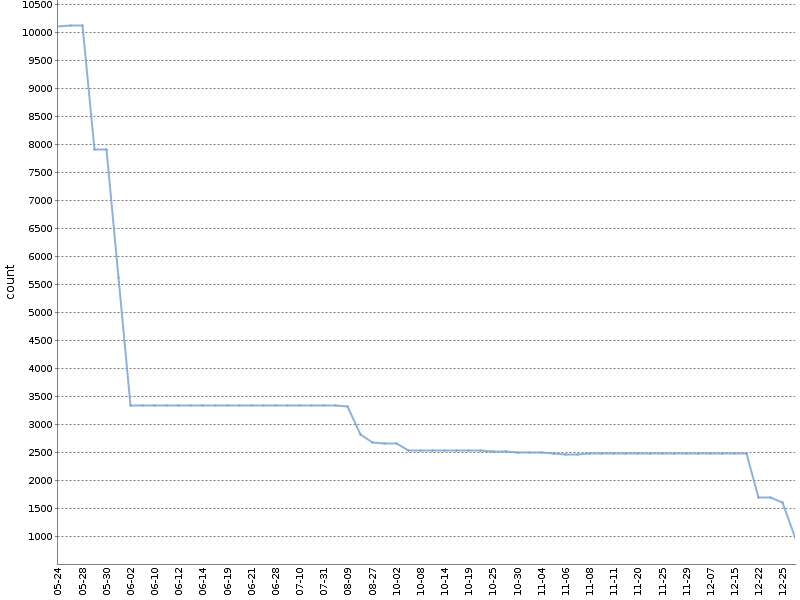
Este gráfico mostra o número total de avisos do Checkstyle por meio ano trabalhando com uma catraca em
um de nossos projetos OpenSource . O número de avisos diminuiu em uma ordem de magnitude, e isso aconteceu naturalmente, paralelamente ao desenvolvimento do produto!
Eu uso uma versão modificada desse método, contando separadamente avisos divididos por módulos de projeto e ferramentas de análise; o arquivo YAML gerado com metadados de montagem é semelhante a este:
celesta-sql: checkstyle: 434 spotbugs: 45 celesta-core: checkstyle: 206 spotbugs: 13 celesta-maven-plugin: checkstyle: 19 spotbugs: 0 celesta-unit: checkstyle: 0 spotbugs: 0
Em qualquer sistema avançado de CI, o "catraca" pode ser implementado para qualquer ferramenta de análise estática, sem depender de plug-ins e ferramentas de terceiros. Cada um dos analisadores produz seu relatório em um formato simples de texto ou XML, fácil de analisar. Resta registrar apenas a lógica necessária no script do IC. Você pode ver como isso é implementado em nossos projetos de código aberto baseados em Jenkins e Artifactory
aqui ou
aqui . Ambos os exemplos dependem da biblioteca
ratchetlib : o método
countWarnings() conta as tags xml nos arquivos gerados pelo Checkstyle e Spotbugs, e
compareWarningMaps() implementa a mesma catraca,
compareWarningMaps() um erro quando o número de avisos em qualquer uma das categorias aumenta.
Uma implementação interessante da catraca é possível analisar a ortografia dos comentários, literais de texto e documentação usando o aspell. Como você sabe, ao verificar a ortografia, nem todas as palavras desconhecidas no dicionário padrão estão incorretas; elas podem ser adicionadas ao dicionário do usuário. Se você tornar um dicionário personalizado parte do código-fonte do projeto, a porta de qualidade para ortografia pode ser formulada da seguinte maneira: executar o aspell com um dicionário padrão e personalizado
não deve encontrar nenhum erro ortográfico.
Sobre a importância de corrigir a versão do analisador
Em conclusão, o seguinte deve ser observado: não importa como você integra a análise ao seu pipeline de entrega, a versão do analisador deve ser corrigida. Se você permitir que o analisador atualize espontaneamente, ao montar a próxima solicitação pull, poderão surgir novos defeitos que não estão relacionados à alteração do código, mas estão relacionados ao fato de que o novo analisador simplesmente consegue encontrar mais defeitos - e isso interromperá o processo de recebimento de solicitações pull. . A atualização do analisador deve ser uma ação consciente. No entanto, a correção rigorosa da versão de cada componente do assembly geralmente é um requisito necessário e um tópico para uma conversa em separado.
Conclusões
- A análise estática não encontrará erros e não melhorará a qualidade do seu produto como resultado de um único aplicativo. Um efeito positivo na qualidade é fornecido apenas pelo seu uso constante no processo de entrega.
- Procurar bugs não é a principal tarefa da análise, a grande maioria das funções úteis está disponível nas ferramentas de código-fonte aberto.
- Implemente portões de qualidade com base nos resultados da análise estática no primeiro estágio do pipeline de entrega, usando catraca para o código legado.
Referências
- Entrega contínua
- A. Kudryavtsev: Análise de programas: como entender que você é um bom relatório de programador sobre diferentes métodos de análise de código (não apenas estático!)