Assim, em 4 de janeiro, às 7:15, depois de ter enxugado os olhos do sono, encontro um pacote de uma mensagem no grupo Telegram do servidor Zabbix que a carga da CPU em um dos servidores de virtualização aumentou:
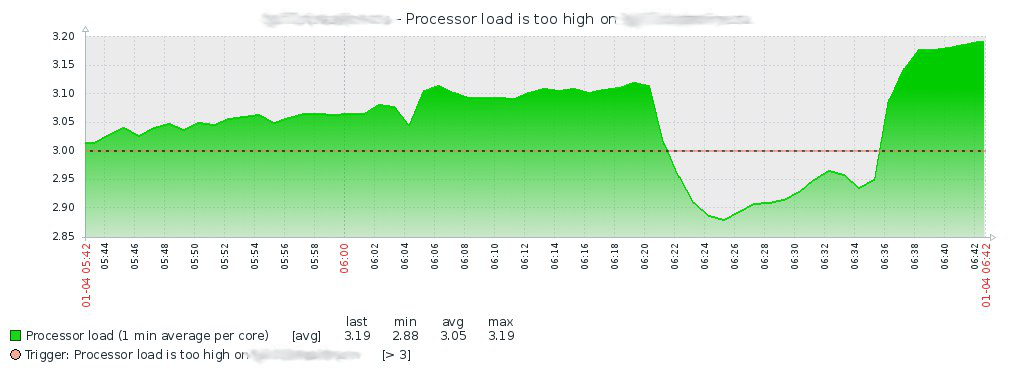
Depois de examinar a história no Zabbix, subo no servidor e procuro no dmesg, onde encontro o seguinte:
[ 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter. [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device
Estou subindo no armazenamento em que o adaptador QLogic FC está olhando. Vejo que, em 1º de janeiro às 19:54, uma das unidades no armazenamento foi retirada de serviço, a unidade Spare foi retirada e a resilvering terminou em 2 de janeiro às 9:11:

Pensei: talvez algo tenha vindo do repositório ou do comutador FC, o que fez com que o driver se enfurecesse com o adaptador QLogic.
Criou uma tarefa no rastreador, reiniciou o servidor, tudo funcionou novamente como deveria, à primeira vista.
Por isso, adiou novas ações até o final do feriado de Ano Novo.
Com o início da semana de trabalho em 9 de janeiro, ele começou a descobrir a causa do fracasso.
Desde a mensagem:
[ 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter.
não muito informativo, subiu na fonte do driver.
A julgar pelo código do driver, uma mensagem é emitida quando o driver é descarregado devido a um erro no PCI (linux / drivers / scsi / qla2xxx / qla_os.c (kernel v4.15)):
qla2x00_disable_board_on_pci_error(struct work_struct *work) { struct qla_hw_data *ha = container_of(work, struct qla_hw_data, board_disable); struct pci_dev *pdev = ha->pdev; scsi_qla_host_t *base_vha = pci_get_drvdata(ha->pdev); /* * if UNLOAD flag is already set, then continue unload, * where it was set first. */ if (test_bit(UNLOADING, &base_vha->dpc_flags)) return; ql_log(ql_log_warn, base_vha, 0x015b, "Disabling adapter.\n");
Comecei a cavar mais, entrei no BMC, procuro no Event Log:
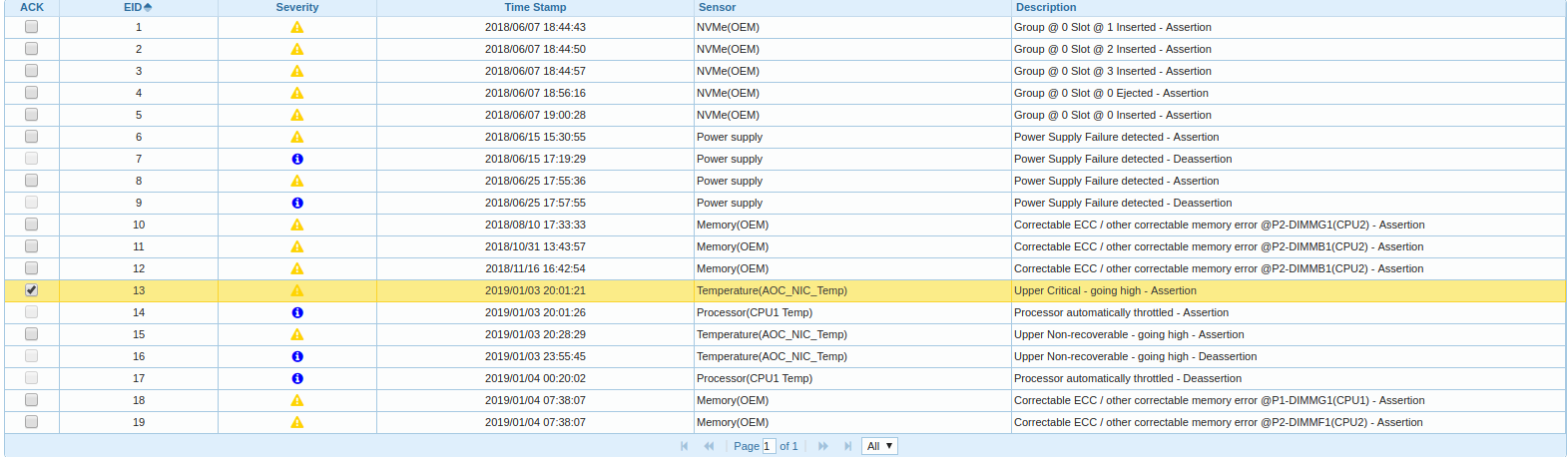
Acontece que um dos dois nós da CPU na plataforma está aquecendo e limitando, e o tempo da mensagem sobre o descarregamento do driver do adaptador FC se correlaciona com o horário de início da regulagem.
Aqui, vale ressaltar que a plataforma do servidor que temos aqui é https://www.supermicro.com/Aplus/system/2U/2123/AS-2123BT-HNC0R.cfm com dois EPYC 7601 para cada nó:
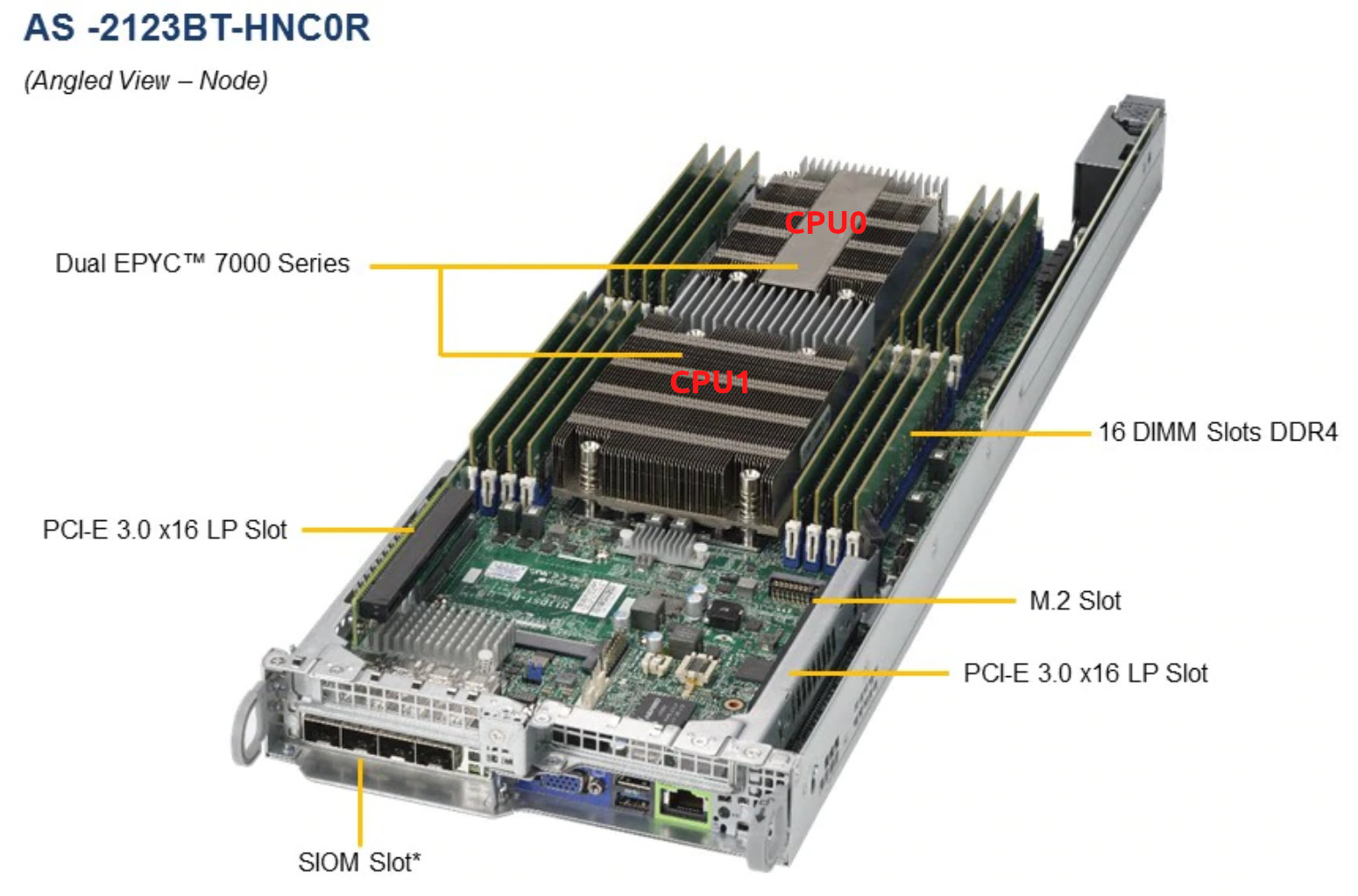
Mudei para o data center, removi o nó do servidor, mudei a pasta térmica, prendi novamente, mas ainda esquenta.
Percebemos que o fluxo de ar em uma parte do servidor não é tão forte quanto na outra. Depois de carregar levemente todos os nós com stress-ng, ficou claro que os processadores de nós no lado direito da plataforma não explodem corretamente e a temperatura da segunda CPU em dois nós rapidamente atinge a crítica.
Depois de tentar alterar os parâmetros de sopro no BMC, eles não tiveram efeito:
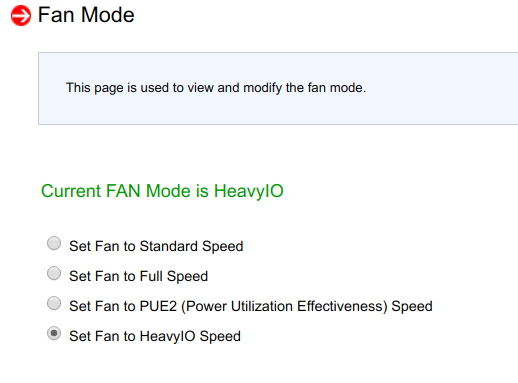
Reiniciar o BMC também não teve efeito.
Observando as leituras dos sensores, vi que em um nó dos 53 sensores, apenas 4 são detectados e no outro nó apenas 6:
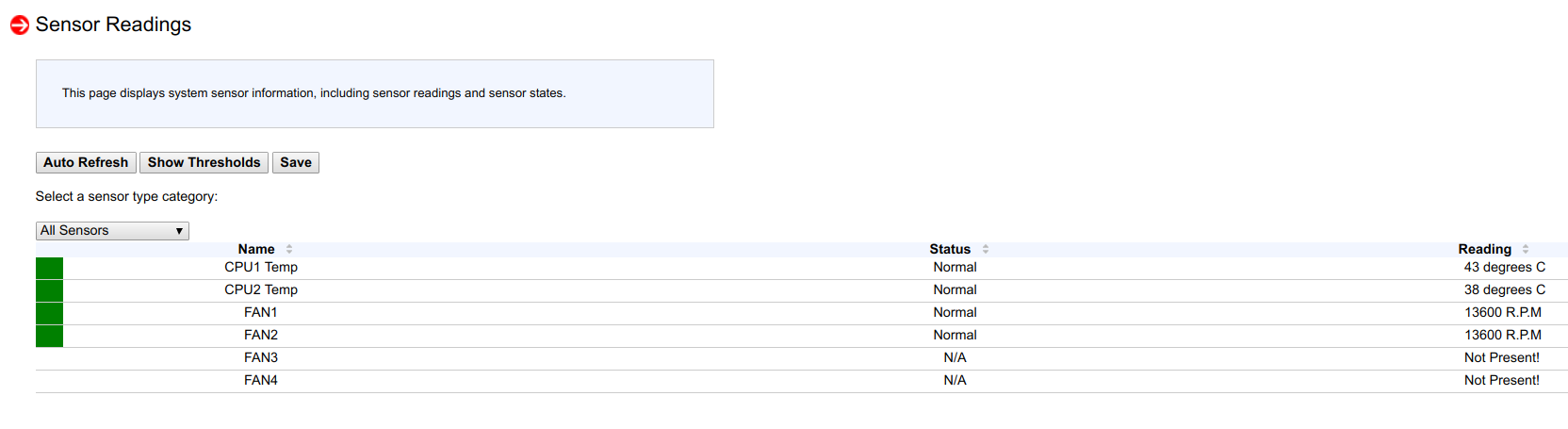
E então, lembrei-me de que depois de atualizar uma nova versão do BIOS e um novo BMC para nós há um mês ou dois, em dois nós não redefini a configuração do BMC para as configurações de fábrica (para verificar um caso específico de ajuste).
Após redefinir o BMC para os parâmetros de fábrica, todos os 53 sensores foram novamente detectados, o controle de velocidade do ventilador funcionou novamente e os processadores pararam de aquecer.
O fato de a causa do descarregamento do driver QLogic ser o superaquecimento do processador não é exato, mas não encontrei outras correlações próximas.
Conclusões:
- depois do firmware da BMC, mesmo que tudo funcione bem à primeira vista, ainda vale a pena redefinir as configurações de fábrica;
- Obviamente, as mensagens de erro de temperatura e de kernel devem ser monitoradas e isso é natural nos planos, mas não de uma só vez.