Meu nome é Vladislav, participo do desenvolvimento do
Tarantool - DBMS e servidor de aplicativos em uma garrafa. E hoje vou lhe contar como implementamos a escala horizontal no Tarantool usando o módulo
VShard .
Primeiro, um pouco de teoria.
Existem dois tipos de escala: horizontal e vertical. Horizontal é dividido em dois tipos: replicação e sharding. A replicação é usada para dimensionar a computação, o sharding é usado para dimensionar os dados.
O sharding é dividido em dois tipos: sharding por intervalos e sharding por hashes.
Ao compartilhar com intervalos, calculamos alguma chave de fragmento de cada registro no cluster. Essas chaves de fragmento são projetadas em uma linha reta, dividida em intervalos que adicionamos a diferentes nós físicos.
O sharding com hashes é mais simples: a partir de cada registro no cluster, consideramos uma função hash, adicionamos registros com o mesmo valor da função hash a um nó físico.
Vou falar sobre o dimensionamento horizontal usando o shard sharding.
Implementação anterior
O primeiro módulo de escala horizontal que tivemos foi o
Tarantool Shard . Esse é um sharding muito simples por hashes, que considera a chave de shard da chave primária de todas as entradas no cluster.
function shard_function(primary_key) return guava(crc32(primary_key), shard_count) end
Mas então surgiu uma tarefa que o Tarantool Shard não conseguiu lidar por três razões fundamentais.
Primeiro, a
localidade dos dados relacionados logicamente era necessária. Quando temos dados conectados logicamente, sempre queremos armazená-los no mesmo nó físico, independentemente de como a topologia do cluster é alterada ou o equilíbrio é executado. E o Tarantool Shard não garante isso. Ele considera o hash apenas pelas chaves primárias e, ao fazer o reequilíbrio, até os registros com o mesmo hash podem ser separados por algum tempo - a transferência não é atômica.
O problema da falta de localidade dos dados nos impediu mais. Eu darei um exemplo Existe um banco no qual o cliente abriu uma conta. Os dados da conta e do cliente sempre devem ser fisicamente armazenados juntos, para que possam ser lidos em uma solicitação, trocados em uma transação, por exemplo, ao transferir dinheiro de uma conta. Se você usar o sharding clássico com o Tarantool Shard, os valores das funções do shard serão diferentes para contas e clientes. Os dados podem estar em diferentes nós físicos. Isso complica muito o trabalho de leitura e transacional com esse cliente.
format = {{'id', 'unsigned'}, {'email', 'string'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}} box.schema.create_space('account', {format = format})
No exemplo acima, os campos de
id não podem corresponder facilmente a contas e clientes. Eles são conectados através do campo da conta
customer_id e
id customer_id . O mesmo campo de
id quebraria a exclusividade da chave primária da conta. E de outra maneira, o Shard não é capaz de fragmentar.
O próximo problema é
o compartilhamento lento . Esse é o problema clássico de todos os shards em hashes. A conclusão é que, quando alteramos a composição de um cluster, geralmente alteramos a função shard, porque geralmente depende do número de nós. E quando a função muda, você precisa passar por todas as entradas do cluster e recalcular a função shard novamente. Talvez transfira algumas anotações. E enquanto os estamos transferindo, não sabemos se os dados necessários para a próxima solicitação de entrada já foram transferidos, talvez eles estejam no processo de transferência. Portanto, durante o novo compartilhamento, é necessário que cada leitura faça uma solicitação para duas funções de shard: a antiga e a nova. Os pedidos estão se tornando duas vezes mais lentos e, para nós, era inaceitável.
Outro recurso do Tarantool Shard foi que, quando alguns nós nos conjuntos de réplicas falham, ele mostra
acessibilidade de leitura ruim .
Nova solução
Para resolver os três problemas descritos, criamos o
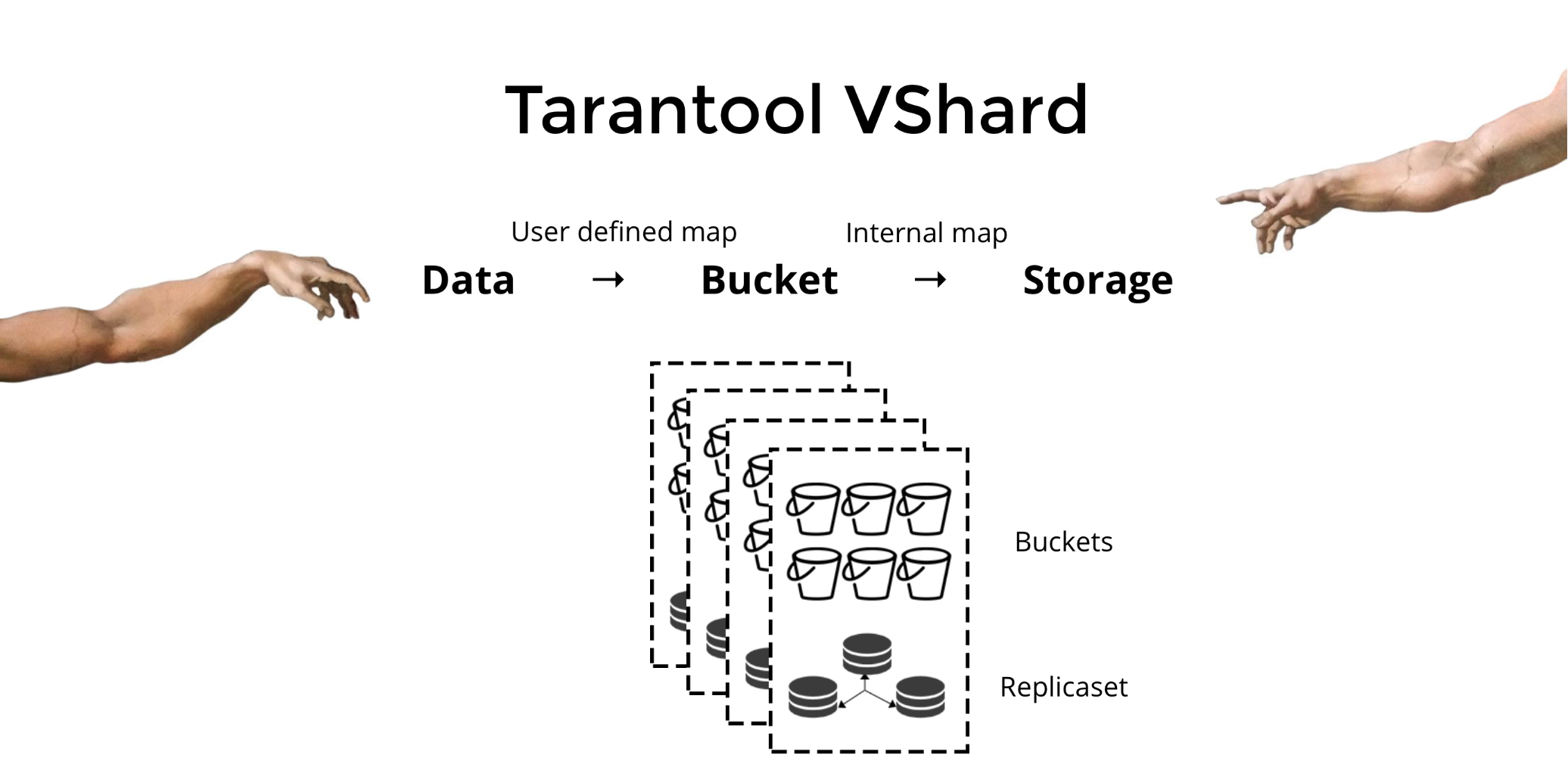
Tarantool VShard . Sua principal diferença é que o nível de armazenamento de dados é virtualizado: os armazenamentos virtuais apareceram sobre os físicos e os registros são distribuídos entre eles. Esses armazenamentos são chamados de bucket'ami. O usuário não precisa pensar sobre o que e em qual nó físico se encontra. Bucket é uma unidade de dados indivisível atômica, como no sharding clássico, uma tupla. O VShard sempre armazena o bucket inteiro em um nó físico e durante o compartilhamento compartilhado transfere todos os dados de um bucket atomicamente. Devido a isso, a localidade é fornecida. Nós só precisamos colocar os dados em um bucket e sempre podemos ter certeza de que esses dados estarão juntos com quaisquer alterações no cluster.

Como posso colocar dados em um balde? No esquema que introduzimos anteriormente para o cliente do banco, adicionaremos o
bucket id do
bucket id às tabelas de acordo com o novo campo. Se os dados vinculados forem os mesmos, os registros estarão no mesmo bloco. A vantagem é que podemos armazenar esses registros com o mesmo
bucket id em espaços diferentes e até em mecanismos diferentes. A
bucket id fornecida, independentemente de como esses registros são armazenados.
format = {{'id', 'unsigned'}, {'email', 'string'}, {'bucket_id', 'unsigned'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}, {'bucket_id', 'unsigned'}} box.schema.create_space('account', {format = format})
Por que estamos tão ansiosos por isso? Se tivermos sharding clássico, os dados poderão se espalhar por todos os armazenamentos físicos que temos apenas. No exemplo com o banco, ao solicitar todas as contas de um cliente, você precisará ativar todos os nós. Acontece a dificuldade de ler O (N), onde N é o número de reservas físicas. Muito lento.
Graças ao bucket'am e à localidade pelo
bucket id sempre podemos ler dados de um nó em uma solicitação, independentemente do tamanho do cluster.

Você precisa calcular o
bucket id do
bucket id e atribuir os mesmos valores. Para alguns, isso é uma vantagem, para alguém uma desvantagem. Considero uma vantagem que você pode escolher a função para calcular o
bucket id do
bucket id .
Qual é a principal diferença entre o sharding clássico e o sharding virtual com bucket?
No primeiro caso, quando alteramos a composição do cluster, temos dois estados: o atual (antigo) e o novo, nos quais devemos ir. No processo de transição, você precisa não apenas transferir os dados, mas também recalcular as funções de hash para todos os registros. Isso é muito inconveniente, porque a qualquer momento não sabemos quais dados já foram transferidos e quais não. Além disso, isso não é confiável nem atômico, pois para a transferência atômica de um conjunto de registros com o mesmo valor da função hash, é necessário armazenar persistentemente o estado da transferência, caso a recuperação seja necessária. Existem conflitos, erros, você precisa reiniciar o procedimento várias vezes.
O sharding virtual é muito mais simples. Não temos dois estados selecionados do cluster, apenas o estado do bucket. O cluster se torna mais manobrável, gradualmente se move de um estado para outro. E agora existem mais de dois estados. Graças a uma transição suave, você pode alterar o saldo em tempo real, excluir o armazenamento recém-adicionado. Ou seja, a controlabilidade do balanceamento é bastante aumentada, torna-se granular.
Use
Digamos que escolhemos uma função para o
bucket id e inserimos tantos dados no cluster que não havia mais espaço. Agora, queremos adicionar nós e, para que os dados sejam movidos para eles mesmos. No VShard, isso é feito da seguinte maneira. Primeiro, inicie novos nós e Tarantools neles e atualize a configuração do VShard. Ele descreve todos os membros do cluster, todas as réplicas, conjuntos de réplicas, mestres, URIs atribuídos e muito mais. Adicionamos novos nós à configuração e, usando a função
VShard.storage.cfg , usamos em todos os nós do cluster.
function create_user(email) local customer_id = next_id() local bucket_id = crc32(customer_id) box.space.customer:insert(customer_id, email, bucket_id) end function add_account(customer_id) local id = next_id() local bucket_id = crc32(customer_id) box.space.account:insert(id, customer_id, 0, bucket_id) end
Como você se lembra, no sharding clássico com uma alteração no número de nós, a função shard também muda. No VShard, isso não acontece, temos um número fixo de armazenamentos virtuais - bucket'ov. Essa é a constante que você seleciona ao iniciar o cluster. Pode parecer que, por isso, a escalabilidade seja limitada, mas não realmente. Você pode escolher um grande número de bucket'ov, dezenas e centenas de milhares. O principal é que deve haver pelo menos duas ordens de magnitude a mais do que o número máximo de conjuntos de réplicas que você terá no cluster.
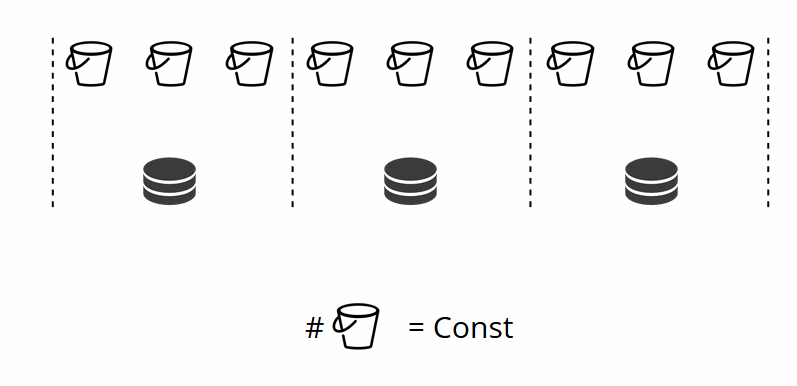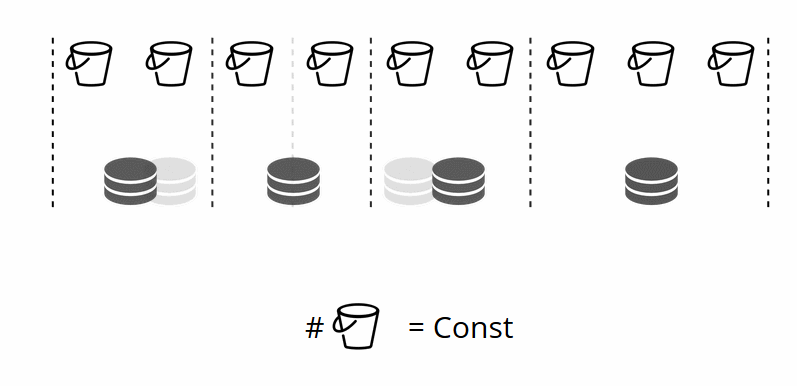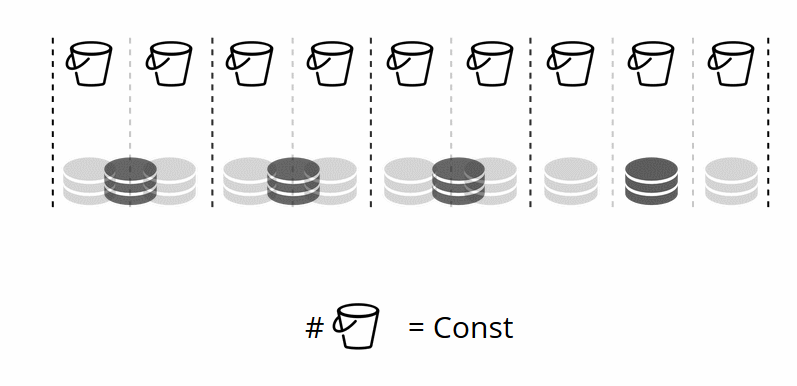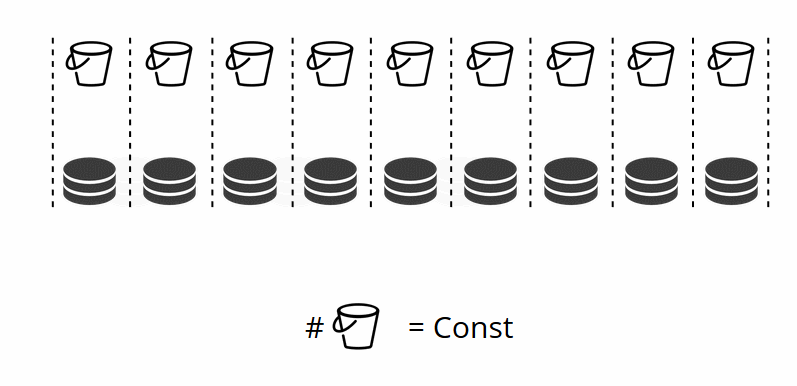
Como o número de armazenamentos virtuais não muda - e a função shard depende apenas desse valor -, podemos adicionar quantos armazenamentos físicos forem necessários, sem recontar a função shard.
Como os pacotes são distribuídos por lojas físicas por conta própria? Quando VShard.storage.cfg é chamado em um dos nós, o processo de reequilíbrio é ativado. Este é um processo analítico que calcula o equilíbrio perfeito em um cluster. Ele vai a todos os nós físicos, pergunta quem tem quantos bucket'ov e constrói rotas para o seu movimento, a fim de calcular a média da distribuição. O rebalanceador envia rotas para armazéns lotados e eles começam a enviar baldes. Após algum tempo, o cluster fica equilibrado.
Mas em projetos reais, o conceito de equilíbrio perfeito pode ser diferente. Por exemplo, quero armazenar menos dados em um conjunto de réplicas do que no outro, porque há menos espaço no disco rígido. O VShard acha que tudo está bem equilibrado e, na verdade, meu armazenamento está prestes a transbordar. Fornecemos um mecanismo para ajustar as regras de balanceamento usando pesos. Cada conjunto de réplicas e repositório pode ser ponderado. Quando o balanceador decide para quem enviar quantos bucket'ov, ele leva em consideração o
relacionamento de todos os pares de pesos.
Por exemplo, uma loja pesa 100 e a outra 200. A primeira armazenará duas vezes menos bucket'ov que a segunda. Observe que estou falando especificamente sobre a
proporção de pesos. Significados absolutos não têm efeito. Você pode escolher pesos com base em uma distribuição de cluster de 100%: uma loja possui 30% e outra 70%. Você pode considerar a capacidade de armazenamento em gigabytes ou medir pesos no número de bucket'ov. O principal é observar a atitude que você precisa.
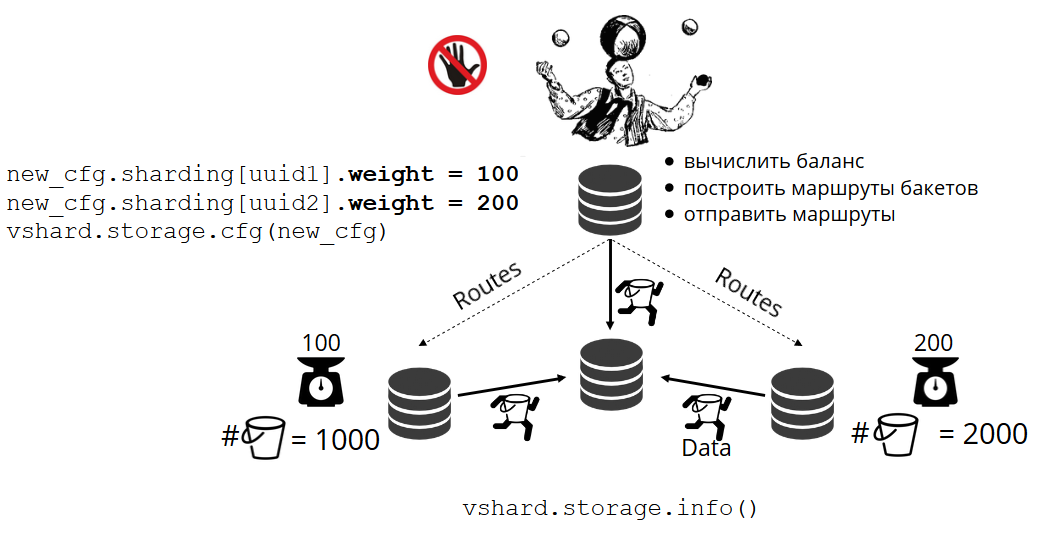
Esse sistema tem um efeito colateral interessante: se você atribuir um peso zero a alguma loja, o balanceador solicitará que a loja distribua todos os seus baldes. Depois disso, você pode remover todo o conjunto de réplicas da configuração.
Transferência de caçamba atômica
Temos um depósito, ele aceita algum tipo de solicitação de leitura e gravação e, em seguida, o balanceador pede para transferi-lo para outro armazenamento. O bucket deixa de aceitar solicitações de gravação; caso contrário, eles terão tempo para atualizá-lo durante a transferência, terão tempo para atualizar a atualização portátil, a atualização portátil e assim por diante. Portanto, o registro está bloqueado e você ainda pode ler no balde. A transferência de pedaços para um novo local começa. Após a conclusão da transferência, o bucket começará novamente a aceitar solicitações. No antigo local, ele ainda está, mas já foi marcado como lixo e, posteriormente, o coletor de lixo o exclui pedaço por pedaço.
Cada bloco está associado aos metadados armazenados fisicamente no disco. Todas as etapas acima são salvas no disco e, não importa o que aconteça com o repositório, o estado do bucket será restaurado automaticamente.
Você pode ter perguntas:
- O que acontecerá com as solicitações que funcionaram com o bucket quando começaram a portá-lo?
Existem dois tipos de links nos metadados de cada bloco: leitura e gravação. Quando o usuário faz uma solicitação para o bucket, ele indica como ele trabalhará com ele, somente leitura ou leitura e gravação. Para cada solicitação, o contador de referência correspondente é incrementado.
Por que preciso de um contador de referência para solicitações de leitura? Digamos que o balde seja transferido silenciosamente, e aqui o coletor de lixo vem e deseja excluir esse balde. Ele vê que a contagem de links é maior que zero, então você não pode excluí-la. E quando as solicitações forem processadas, o coletor de lixo poderá concluir seu trabalho.
O contador de referência para pedidos de gravação garante que o bucket nem comece a ser transportado enquanto pelo menos um pedido de gravação estiver trabalhando com ele. Mas as solicitações de gravação podem vir constantemente e, em seguida, o depósito nunca será transferido. O fato é que, se o balanceador manifestou desejo de transferi-lo, novas solicitações de gravação começarão a ser bloqueadas e o sistema atual aguardará a conclusão de algum tempo limite. Se as solicitações não forem concluídas no tempo alocado, o sistema começará novamente a aceitar novas solicitações de gravação, adiando a transferência do bucket por algum tempo. Assim, o balanceador fará as tentativas de transferência até que uma seja bem-sucedida.
O VShard possui uma API bucket_ref de baixo nível, caso você tenha poucos recursos de alto nível. Se você realmente deseja fazer algo, basta acessar esta API a partir do código. - É possível não bloquear registros?
Isso é impossível. Se o depósito contiver dados críticos que precisam de acesso de gravação constante, você terá que bloquear completamente sua transferência. Existe uma função bucket_pin para isso, ela anexa firmemente o bucket ao conjunto de réplicas atual, impedindo sua transferência. Nesse caso, o bucket'y vizinho poderá se mover sem restrições.

Existe uma ferramenta ainda mais poderosa que o bloqueio do conjunto de réplicas bucket_pin . Isso não é mais feito no código, mas através da configuração. O bloqueio proíbe o movimento de qualquer bucket'ov deste conjunto de réplicas e a recepção de novos. Consequentemente, todos os dados estarão constantemente disponíveis para gravação.

VShard.router
O VShard consiste em dois submódulos: VShard.storage e VShard.router. Eles podem ser criados e dimensionados independentemente, mesmo em uma instância. Ao acessar o cluster, não sabemos onde está o depósito, e o VShard.router o procurará pelo
bucket id .
Vejamos um exemplo de como isso se parece. Retornamos ao cluster bancário e às contas de clientes. Quero poder extrair todas as contas de um cliente específico do cluster. Para fazer isso, escrevo a função usual para pesquisa local:
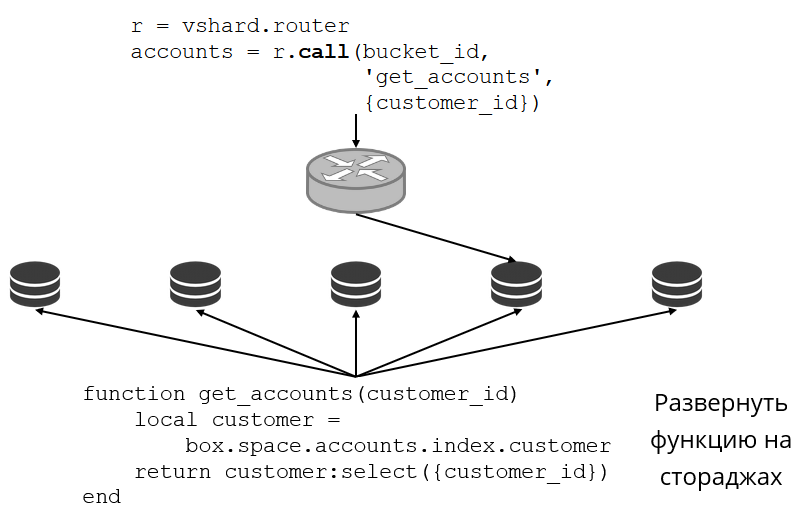
Ela procura todas as contas de clientes pelo ID dele. Agora eu preciso decidir em qual dos repositórios chamar essa função. Para fazer isso, calculo o
bucket id do
bucket id partir do
bucket id do cliente em minha solicitação e solicito ao VShard.router que me chame de tal função no armazenamento em que o bucket com o
bucket id resultante vive. Há uma tabela de roteamento no submódulo, na qual a localização do bucket no conjunto de réplicas é especificada. E o VShard.router proxies meu pedido.
Obviamente, pode acontecer que, nesse momento, o novo compartilhamento tenha começado e o balde tenha começado a se mover. O roteador em segundo plano atualiza gradualmente a tabela em grandes partes: consulta os repositórios em busca de suas tabelas de bucket atuais.
Pode até acontecer que voltemos ao balde que acabou de ser movido e o roteador ainda não conseguiu atualizar sua tabela de roteamento. Em seguida, ele voltará para o repositório antigo e ele informará ao roteador onde procurar o bucket ou simplesmente responderá que ele não possui os dados necessários. Em seguida, o roteador percorrerá todos os armazenamentos em busca do balde desejado. E tudo isso é transparente para nós, nem perceberemos uma falta na tabela de roteamento.
Instabilidade de leitura
Lembre-se de quais problemas tivemos inicialmente:
- Não havia localidade de dados. Decidimos adicionando bucket'ov.
- Compartilhar novamente reduziu a velocidade e diminuiu a velocidade. Implementou a transferência de dados atômicos bucket'ami, livrou-se de recontar funções de shard.
- Leitura instável.
O último problema foi resolvido pelo VShard.router usando o subsistema de failover de leitura automática.
O roteador efetua ping periodicamente no armazenamento especificado na configuração. E então alguns deles pararam de tocar. O roteador possui uma conexão de backup quente para cada réplica e, se a atual parar de responder, será direcionada para outra. A solicitação de leitura será processada normalmente, porque podemos ler em réplicas (mas não em escrever). Podemos definir a prioridade das réplicas pelas quais o roteador deve selecionar o failover para as leituras. Fazemos isso com zoneamento.
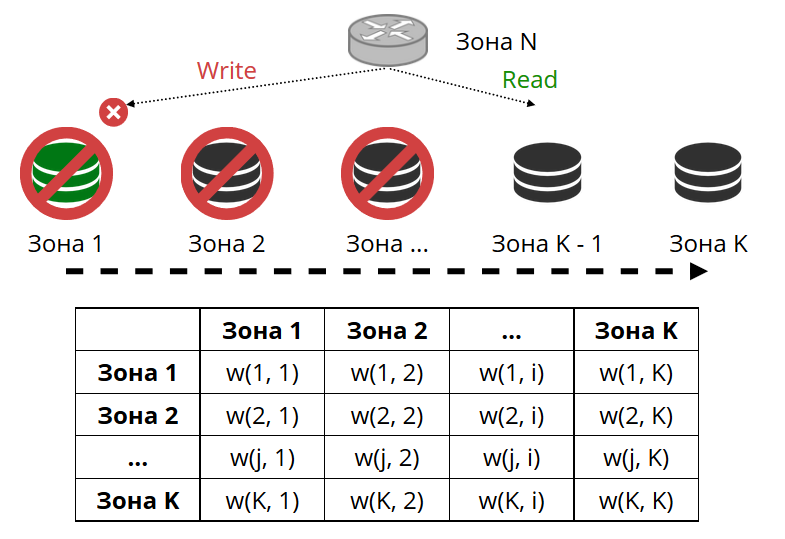
Atribuímos um número de zona a cada réplica e a cada roteador e definimos uma tabela na qual indicamos a distância entre cada par de zonas. Quando o roteador decide para onde enviar uma solicitação de leitura, ele selecionará uma réplica na zona mais próxima da sua.
Como fica na configuração:
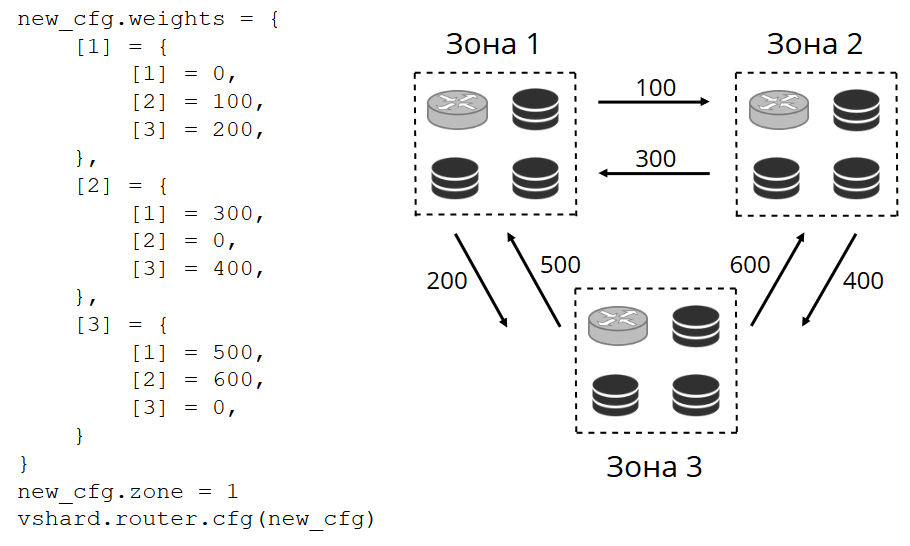
Em geral, você pode se referir a uma réplica arbitrária, mas se o cluster for grande e complexo, muito distribuído, o zoneamento será muito útil. Racks de servidor diferentes podem ser zonas, para não carregar a rede com tráfego. Ou podem ser pontos geograficamente distantes um do outro.
O zoneamento também ajuda com o desempenho variável da réplica. Por exemplo, em cada conjunto de réplicas, temos uma réplica de backup, que não deve aceitar solicitações, mas apenas armazena uma cópia dos dados. Em seguida, chegamos à zona, que estará muito longe de todos os roteadores da tabela, e eles se voltarão para ele no caso mais extremo.
Instabilidade de gravação
Como estamos falando de failover de leitura, e o failover de gravação ao alterar o assistente? Aqui, o VShard não é tão otimista: a eleição de um novo mestre não é implementada nele, você terá que fazer isso sozinho. Quando a selecionamos de alguma forma, é necessário que essa instância agora assuma a autoridade do mestre. Atualizamos a configuração especificando
master = false para o antigo mestre e
master = true para o novo, aplicamos via VShard.storage.cfg e rolamos para o armazenamento. Então tudo acontece automaticamente. O antigo mestre para de aceitar solicitações de gravação e começa a sincronizar com o novo, porque pode haver dados que já foram aplicados no antigo, mas o novo ainda não chegou. Depois disso, o novo mestre entra na função e começa a aceitar solicitações, e o antigo mestre se torna uma réplica. É assim que o failover de gravação funciona no VShard.
replicas = new_cfg.sharding[uud].replicas replicas[old_master_uuid].master = false replicas[new_master_uuid].master = true vshard.storage.cfg(new_cfg)
Como agora seguir toda essa variedade de eventos?
No caso geral, duas alças são suficientes -
VShard.storage.info e
VShard.router.info .
VShard.storage.info exibe informações em várias seções.
vshard.storage.info() --- - replicasets: <replicaset_2>: uuid: <replicaset_2> master: uri: storage@127.0.0.1:3303 <replicaset_1>: uuid: <replicaset_1> master: missing bucket: receiving: 0 active: 0 total: 0 garbage: 0 pinned: 0 sending: 0 status: 2 replication: status: slave Alerts: - ['MISSING_MASTER', 'Master is not configured for ''replicaset <replicaset_1>']
A primeira é a seção de replicação. O status do conjunto de réplicas ao qual você aplicou esta função é exibido: qual atraso de replicação possui, com quem tem conexões e com quem não está disponível, quem está disponível e não está disponível, qual assistente está configurado para qual etc.
Na seção Balde, é possível ver em tempo real quantos bucket'ov estão atualmente migrando para o conjunto de réplicas atual, quantos o estão deixando, quantos estão trabalhando atualmente, quantos estão marcados como lixo e quantos estão anexados.
A seção Alert é uma mistura de todos os problemas que o VShard conseguiu determinar independentemente: o mestre não está configurado, o nível de redundância é insuficiente, o mestre está lá, mas todas as réplicas falharam etc.
E a última seção é uma luz que acende em vermelho quando as coisas ficam realmente ruins. É um número de zero a três, quanto mais, pior.
VShard.router.info tem as mesmas seções, mas elas significam um pouco diferente.
vshard.router.info() --- - replicasets: <replicaset_2>: replica: &0 status: available uri: storage@127.0.0.1:3303 uuid: 1e02ae8a-afc0-4e91-ba34-843a356b8ed7 bucket: available_rw: 500 uuid: <replicaset_2> master: *0 <replicaset_1>: replica: &1 status: available uri: storage@127.0.0.1:3301 uuid: 8a274925-a26d-47fc-9e1b-af88ce939412 bucket: available_rw: 400 uuid: <replicaset_1> master: *1 bucket: unreachable: 0 available_ro: 800 unknown: 200 available_rw: 700 status: 1 alerts: - ['UNKNOWN_BUCKETS', '200 buckets are not discovered']
A primeira seção é replicação. , : , replica set' , , , replica set' bucket' , .
Bucket bucket', ; bucket' ; , replica set'.
Alert, , , failover, bucket'.
, .
VShard?
— bucket'.
int32_max ? bucket' — 30 16 . bucket', . bucket', bucket'. , .
— -
bucket id . , - , bucket — . , bucket' , VShard bucket'. -, bucket' bucket, -. .
Sumário
Vshard :
- ;
- ;
- ;
- read failover;
- bucket'.
VShard . - . —
. , . .
—
lock-free bucket' . , bucket' . , .
—
. : - , , ? .