O Prometheus 2.6.0 otimizou o carregamento do WAL, o que acelera o processo de inicialização.
O objetivo não oficial do desenvolvimento do TSDB do Prometheus 2.x é acelerar o lançamento para que não demore mais do que um minuto. Nos últimos meses, houve relatos de que o processo está demorando um pouco mais e, se o Prometheus for reiniciado por algum motivo, isso já é um problema. Quase todo esse tempo, o WAL (gravação pré-gravação) é carregado, o que inclui amostras das últimas horas que ainda precisam ser compactadas em um bloco. No final de outubro, finalmente consegui descobrir; o resultado é o PR # 440 , que reduz o tempo da CPU em 6,5 vezes e o tempo de cálculo em 4 vezes. Vamos ver como eu fiz essas melhorias.

Primeiro, é necessária uma configuração de teste. Criei um pequeno programa Go que gera TSDB com WAL com um bilhão de amostras espalhadas por 10.000 séries temporais. Abri este TSDB e verifiquei quanto tempo levou para usar o utilitário de time (não a estrutura interna, pois não inclui estatísticas de memória) e também criei um perfil de CPU usando o pacote runtime / pprof :
f, err := os.Create("cpu.prof") if err != nil { log.Fatal(err) } pprof.StartCPUProfile(f) defer pprof.StopCPUProfile()
O perfil da CPU não nos permite determinar diretamente o tempo de cálculo de seu interesse, no entanto, existe uma correlação significativa. Como resultado, no meu computador desktop (processador i7-3770 com 16 GB de RAM e unidades de estado sólido), o download levou cerca de 4 minutos e um pouco menos de 6 GB de RAM em seu pico:
1727.50user 16.61system 4:01.12elapsed 723%CPU (0avgtext+0avgdata 5962812maxresident)k 23625165inputs+95outputs (196major+2042817minor)pagefaults 0swaps
Isso não é um problema, então vamos carregar o perfil usando a go tool pprof cpu.prof e ver quanto tempo o processo levará se você usar o comando top .

Aqui é flat a quantidade de tempo gasto em uma determinada função e cum é o tempo gasto nessa função e em todas as funções chamadas por ela. Também pode ser útil visualizar esses dados em um gráfico para ter uma idéia da pergunta. Eu prefiro usar o comando web para isso, mas existem outras opções, incluindo arquivos svg, png e pdf.
Pode-se observar que cerca de um terço de nossa CPU é gasto na adição de amostras ao banco de dados interno, cerca de dois terços no processamento WAL em geral e um quarto na limpeza de memória ( runtime.scanobject ). Vejamos o código do primeiro desses processos usando a list memSeries.*append :
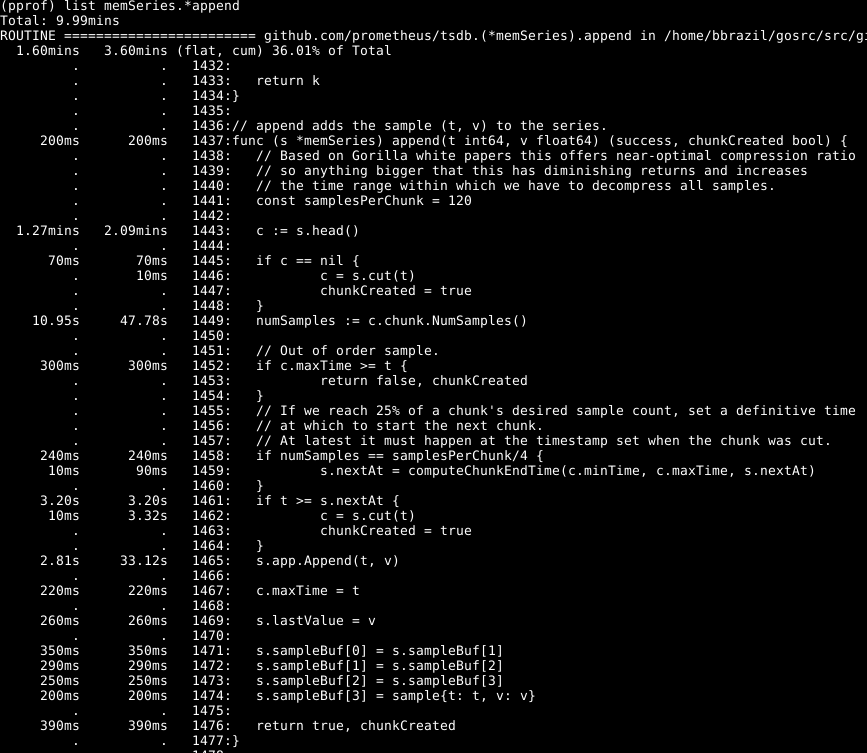
O seguinte é impressionante aqui: mais da metade do tempo é gasto na obtenção dos dados principais da série na linha 1443. Além disso, não é gasto pouco tempo em definir o número de amostras nesse dado na linha 1449. O tempo necessário para concluir a linha 1465 - esperado, pois esse é o núcleo da ação dessa função. Por conseguinte, esperava que a operação levasse a maior parte do tempo.
Dê uma olhada no elemento memSeries.head : ele calcula um dado que é retornado a cada vez. O fragmento de dados muda somente após cada 120 adições e, portanto, podemos salvar o fragmento de cabeçalho atual na estrutura de dados da série . Isso ocupa parte da RAM ( que retornarei mais tarde ), mas economiza uma quantidade significativa de CPU. E no geral, também acelera Prometheus.
Então, vamos dar uma olhada em Head.processWALSamples :
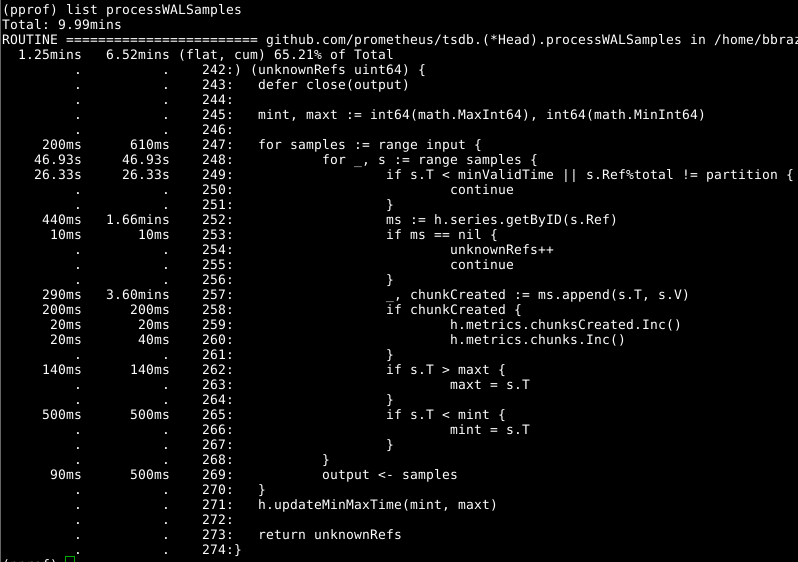
Esse complemento já foi otimizado acima, então veja o próximo culpado óbvio, getByID na linha 252:
(código)
Parece que há algum tipo de conflito de bloqueio e o tempo é desperdiçado na pesquisa de mapas em dois níveis. O cache para cada identificador reduz significativamente esse indicador.
Vale a pena Head.processWALSamples segunda olhada em Head.processWALSamples e você Head.processWALSamples surpreso com quanto tempo foi gasto na linha 249. Vamos voltar um pouco à questão de como o carregamento do WAL funciona: Head.processWALSamples Head.processWALSamples é criado para cada CPU disponível, além de outro para leitura e decodificação WAL do disco. As linhas são segmentadas por essas goroutines; portanto, a simultaneidade pode ser uma vantagem. O método de implementação é o seguinte: todas as amostras são enviadas para a primeira gorutina, que processa os elementos necessários. Em seguida, ela envia todas as amostras para o segundo gorutin, que processa os elementos de que precisa, e assim por diante, até o último gorutin de Head.processWALSamples envia todos os dados de volta ao gorutin de controle.
Enquanto isso, os complementos são distribuídos pelos kernels - e é disso que você precisa - e muitas tarefas duplicadas são executadas em cada gorutin, que deve processar todas as amostras e calcular o módulo. De fato, quanto mais núcleos, mais trabalho é duplicado. Fiz alterações para segmentar os dados no gourutin do controlador, para que cada gorutin do Head.processWALSamples agora obtenha apenas as amostras necessárias . No meu computador - 8 rodando gorutin - o tempo de cálculo foi poupado um pouco, mas o volume da CPU foi decente. Para computadores com um grande número de núcleos, os benefícios devem ser mais substanciais.
E, novamente, voltamos à pergunta: hora de limpar a memória. Não podemos (geralmente) determinar isso através de perfis de CPU. Em vez disso, preste atenção aos perfis de memória dinâmica para encontrar os elementos que se destacam. Isso requer alguma expansão de código no final do programa:
runtime.GC() hf, err := os.Create("heap.prof") if err != nil { log.Fatal(err) } pprof.WriteHeapProfile(hf)
A limpeza formal da memória está associada a algumas informações da memória dinâmica, cuja coleta e limpeza são realizadas apenas durante a limpeza da memória.
Novamente usamos a mesma ferramenta, mas especificamos o rótulo -alloc_space , pois estamos interessados em todas as operações de alocação de memória, e não apenas nas operações que usam memória em um determinado momento; portanto, execute a go tool pprof -alloc_space heap.prof . Se você olhar para o distribuidor superior, o culpado é óbvio:
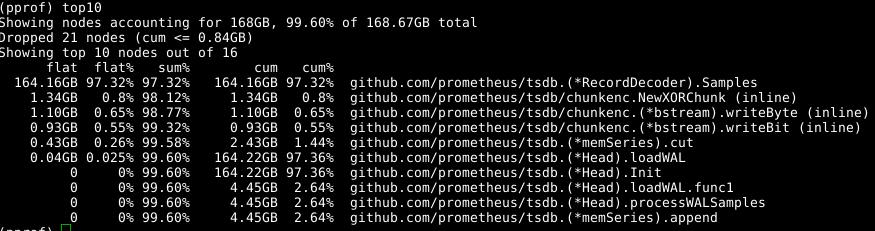
Dê uma olhada no código:
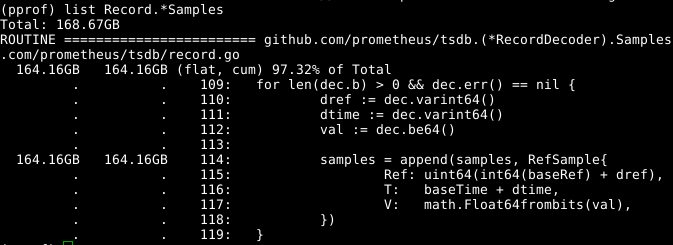
A matriz de samples extensíveis parece ser um problema. Se pudéssemos reutilizar a matriz ao mesmo tempo em que chamava RecordDecoder.Samples , isso economizaria uma quantidade significativa de memória. Acontece que o código foi composto dessa maneira, mas um pequeno erro de codificação levou ao fato de que não funcionou. Se você corrigi-lo , a memória é limpa em 8 segundos da CPU em vez de 151 segundos.
Os resultados gerais são bastante tangíveis:
269.18user 10.69system 1:05.58elapsed 426%CPU (0avgtext+0avgdata 3529556maxresident)k 23174929inputs+70outputs (815major+1083172minor)pagefaults 0swap
Não apenas reduzimos o tempo de cálculo em 4 vezes, e o tempo da CPU - em 6,5 vezes, mas também a quantidade de memória ocupada é reduzida em mais de 2 GB.
Parece que tudo é simples, mas o truque é este: decentemente vasculhei a base de código e analisei tudo como se fosse uma retrospectiva. Estudando o código, cheguei a um beco sem NumSamples várias vezes, por exemplo, ao excluir uma chamada NumSamples , ler e decodificar em threads separados, bem como de várias maneiras para segmentar processWALSamples . Estou quase certo de que, ao regular o número de gorutinas, mais pode ser alcançado, mas, para esse teste, é necessário executar em máquinas mais poderosas que as minhas, para que haja mais núcleos. Atingi meu objetivo: a produtividade aumentou e percebi que era melhor não tornar o registro do programa muito grande e, portanto, decidi parar por aí.