Oi Meu nome é Ivan Smurov e lidero o grupo de pesquisa em PNL da ABBYY. Você pode ler sobre o que nosso grupo está fazendo
aqui . Recentemente, dei uma palestra sobre Processamento de Linguagem Natural (PNL) na
Escola de Aprendizagem Profunda - este é um grupo da Escola de Matemática Aplicada e Ciência da Computação da PhysTech no MIPT para estudantes seniores interessados em programação e matemática. Talvez as teses da minha palestra sejam úteis para alguém, então eu as compartilharei com Habr.
Como tudo não pode ser entendido ao mesmo tempo, dividiremos o artigo em duas partes. Hoje vou falar sobre como as redes neurais (ou aprendizado profundo) são usadas na PNL. Na segunda parte do artigo, focaremos em uma das tarefas mais comuns da PNL - a tarefa de extrair entidades nomeadas (reconhecimento de entidade nomeada, NER) e analisar detalhadamente a arquitetura de suas soluções.
O que é a PNL?
Essa é uma ampla variedade de tarefas para processar textos em um idioma natural (ou seja, o idioma que as pessoas falam e escrevem). Há um conjunto de tarefas clássicas da PNL, cuja solução é de uso prático.
- A primeira e mais importante tarefa historicamente importante é a tradução automática. É praticada há muito tempo e há um tremendo progresso. Mas a tarefa de obter uma tradução totalmente automática de alta qualidade (FAHQMT) permanece por resolver. De certa forma, esse é o mecanismo da PNL, uma das maiores tarefas que você pode executar.

- A segunda tarefa é a classificação dos textos. É fornecido um conjunto de textos, e a tarefa é classificá-los em categorias. Qual? Esta é uma pergunta para o corpo.
A primeira e uma das maneiras mais práticas de aplicá-lo do ponto de vista prático é a classificação de letras em spam e boor (não spam).
Outra opção clássica é a classificação multiclasse de notícias em categorias (rubrica) - política externa, esportes, big top, etc. Ou, digamos, você recebe cartas e deseja separar pedidos da loja online de passagens aéreas e reservas de hotel.
A terceira aplicação clássica do problema de classificação de texto é a análise sentimental. Por exemplo, a classificação das revisões como positiva, negativa e neutra.
Como existem tantas categorias possíveis em que você pode dividir os textos, a classificação dos textos é uma das tarefas práticas mais populares da PNL. - A terceira tarefa é recuperar entidades nomeadas, NER. Selecionamos nas seções de texto que correspondem a um conjunto pré-selecionado de entidades, por exemplo, você precisa encontrar todos os locais, pessoas e organizações no texto. No texto "Ostap Bender - Diretor do escritório" Horns and Hooves "", você deve entender que Ostap Bender é uma pessoa e "Horns and Hooves" é uma organização. Por que essa tarefa é necessária na prática e como resolvê-la, falaremos na segunda parte do nosso artigo.
 A quarta tarefa está relacionada à terceira - a tarefa de extrair fatos e relações (extração de relações). Por exemplo, há uma atitude de trabalho (ocupação). No texto "Ostap Bender - Diretor do escritório" Chifres e Cascos "", fica claro que nosso herói está conectado com relações profissionais com "Chifres e Cascos". O mesmo pode ser dito de muitas outras maneiras: "O escritório de Ostap Bender é chefiado pelo escritório" Horns and Hooves ", ou" Ostap Bender passou do simples filho do tenente Schmidt para o chefe do escritório "Horns and Hooves". " Essas sentenças diferem não apenas no predicado, mas também na estrutura.
A quarta tarefa está relacionada à terceira - a tarefa de extrair fatos e relações (extração de relações). Por exemplo, há uma atitude de trabalho (ocupação). No texto "Ostap Bender - Diretor do escritório" Chifres e Cascos "", fica claro que nosso herói está conectado com relações profissionais com "Chifres e Cascos". O mesmo pode ser dito de muitas outras maneiras: "O escritório de Ostap Bender é chefiado pelo escritório" Horns and Hooves ", ou" Ostap Bender passou do simples filho do tenente Schmidt para o chefe do escritório "Horns and Hooves". " Essas sentenças diferem não apenas no predicado, mas também na estrutura.
Exemplos de outros relacionamentos que são frequentemente destacados são Compra e Venda, Propriedade, o fato de nascer com atributos como data, local etc. (Nascimento) e alguns outros.
A tarefa parece não ter aplicação prática óbvia, mas, no entanto, é usada na estruturação de informações não estruturadas. Além disso, é importante nos sistemas de perguntas e respostas e de diálogo, nos mecanismos de busca - sempre quando você precisa analisar uma pergunta e entender com que tipo ela se relaciona, bem como quais restrições existem na resposta.

- As próximas duas tarefas são provavelmente as mais exageradas. Estes são sistemas de perguntas e respostas e diálogo (bots de bate-papo). Amazon Alexa, Alice são exemplos clássicos de sistemas de conversação. Para que funcionem corretamente, muitas tarefas da PNL devem ser resolvidas. Por exemplo, a classificação de texto ajuda a determinar se caímos em um dos cenários de chatbot orientado a objetivos. Suponha "a questão das taxas de câmbio". A extração de relacionamento é necessária para identificar espaços reservados para o modelo de script, e a tarefa de conduzir o diálogo sobre tópicos comuns (“oradores”) nos ajudará em uma situação em que não caímos em nenhum dos cenários.
Os sistemas de perguntas e respostas também são uma coisa compreensível e útil. Você faz uma pergunta a um carro, o carro está procurando uma resposta em um banco de dados ou corpo de texto. Exemplos de tais sistemas são IBM Watson ou Wolfram Alpha. - Outro exemplo do problema clássico da PNL é a sammarização. A declaração do problema é simples - o sistema de entrada aceita texto grande e a saída é um texto menor, refletindo de alguma forma o conteúdo de um texto maior. Por exemplo, uma máquina é necessária para gerar uma recontagem de um texto, seu nome ou anotação.

- Outra tarefa popular é a mineração de argumentação, a busca de justificativa no texto. Você recebe um fato e um texto. Você precisa encontrar uma justificativa para esse fato no texto.
Isso não é de forma alguma a lista inteira de tarefas da PNL. Existem dezenas deles. De um modo geral, tudo o que pode ser feito com texto em um idioma natural pode ser atribuído às tarefas da PNL, apenas os tópicos listados são de ouvido e eles têm as aplicações práticas mais óbvias.
Por que é difícil resolver tarefas de PNL?
A redação das tarefas não é muito complicada, mas as tarefas em si não são nada simples, porque trabalhamos com a linguagem natural. Os fenômenos da polissemia (palavras polissêmicas têm um significado inicial comum) e a homonímia (palavras com significados diferentes são pronunciadas e escritas da mesma forma) são características de qualquer linguagem natural. E se um falante nativo de russo entende bem que a
recepção calorosa tem pouco em comum com a
técnica de combate , por um lado, e a
cerveja quente , por outro, o sistema automático precisa aprender isso por um longo tempo. Por que é melhor traduzir "
Pressione a barra de espaço para continuar " para chato "
Para continuar, pressione a barra de espaço " do que "A
barra de imprensa de espaço continuará funcionando ".
- Polissemia: parada (processo ou construção), mesa (organização ou objeto), pica-pau (pássaro ou pessoa).
- Homonímia: chave, arco, fechadura, fogão.

- Outro exemplo clássico de complexidade da linguagem é o pronome anáfora. Por exemplo, recebamos o texto " Zelador, duas horas de neve, ele estava insatisfeito ". O pronome "ele" pode se referir tanto ao zelador quanto à neve. Por contexto, entendemos facilmente que ele é zelador, não neve. Mas conseguir que o computador também entendesse isso facilmente não é fácil. O problema do pronome anáfora ainda não está muito bem resolvido; tentativas ativas para melhorar a qualidade das decisões continuam.
- Outra complexidade adicional é a elipse. Por exemplo, " Petya comeu uma maçã verde e Masha comeu uma vermelha ." Entendemos que Masha comeu uma maçã vermelha. No entanto, não é fácil fazer a máquina entender isso também. Agora, a tarefa de restaurar as elipses está sendo resolvida em casos minúsculos (várias centenas de sentenças), e neles a qualidade da restauração completa é francamente fraca (da ordem de 0,5). É claro que, para aplicações práticas, essa qualidade não é boa.
A propósito, este ano, na conferência
Dialogue , serão realizadas faixas em anáfora e em gapping (um tipo de elipse) para o idioma russo. Para ambas as tarefas, os casos foram montados com um volume várias vezes maior que os volumes de edifícios existentes atualmente (além disso, para lacunas, o volume do caso é uma ordem de magnitude maior que os volumes dos casos, não apenas para o russo, mas para todos os idiomas em geral). Se você deseja participar de competições nesses edifícios,
clique aqui (com inscrição, mas sem SMS) .
Como as tarefas da PNL são resolvidas
Ao contrário do processamento de imagem, ainda é possível encontrar artigos na PNL que descrevem soluções que usam algoritmos clássicos como
SVM ou
Xgboost , e não redes neurais, e que mostram resultados que não são muito inferiores às soluções de ponta.
No entanto, há vários anos, as redes neurais começaram a derrotar os modelos clássicos. É importante observar que, para a maioria das tarefas, as soluções baseadas em métodos clássicos eram únicas, em regra, não semelhantes à solução de outros problemas, tanto na arquitetura quanto na maneira como ocorre a coleta e o processamento de atributos.
No entanto, as arquiteturas de redes neurais são muito mais gerais. A arquitetura da própria rede, provavelmente, também é diferente, mas muito menor, há uma tendência à universalização total. No entanto, com quais recursos e como exatamente trabalhamos, já é quase o mesmo para a maioria das tarefas da PNL. Somente as últimas camadas das redes neurais diferem. Assim, podemos assumir que um único pipel de PNL foi formado. Sobre como está organizado, agora contaremos mais.
Pipeline nlp
Essa maneira de trabalhar com sinais, que é mais ou menos o mesmo para todas as tarefas.
Quando se trata de linguagem, a unidade básica com a qual trabalhamos é a palavra. Ou, mais formalmente, um "token". Usamos esse termo porque não está muito claro o que é 2128506 - isso é uma palavra ou não? A resposta não é óbvia. O token geralmente é separado de outros tokens por espaços ou sinais de pontuação. E como você pode entender pelas dificuldades que descrevemos acima, o contexto de cada token é muito importante. Existem abordagens diferentes, mas em 95% dos casos, o contexto considerado durante o trabalho do modelo é uma proposta que inclui o token inicial.
Muitas tarefas geralmente são resolvidas no nível da proposta. Por exemplo, tradução automática. Geralmente, traduzimos apenas uma frase e não usamos um contexto mais amplo. Existem tarefas em que esse não é o caso, por exemplo, sistemas de diálogo. É importante lembrar sobre o que o sistema foi perguntado antes para poder responder a perguntas. No entanto, a oferta também é a principal unidade com a qual trabalhamos.
Portanto, as duas primeiras etapas do pipeline que são executadas para resolver quase todas as tarefas são segmentação (dividindo texto em frases) e tokenização (dividindo frases em tokens, ou seja, palavras individuais). Isso é feito com algoritmos simples.
Em seguida, você precisa calcular as características de cada token. Como regra, isso acontece em duas etapas. O primeiro é calcular atributos de token independentes de contexto. Este é um conjunto de sinais que de modo algum dependem de outras palavras em torno de nosso token. Atributos independentes de contexto comuns são:
- casamentos
- sinais simbólicos
- recursos adicionais específicos para uma tarefa ou idioma específico
Falaremos sobre casamentos e sinais simbólicos em mais detalhes abaixo (sobre sinais simbólicos - não hoje, mas na segunda parte do nosso artigo), mas por enquanto vamos dar exemplos possíveis de sinais adicionais.
Um dos recursos mais usados é a parte da fala ou tag POS (parte da fala). Esses recursos podem ser importantes para resolver muitos problemas, por exemplo, analisar tarefas. Para idiomas com morfologia complexa, como a língua russa, os caracteres morfológicos também são importantes: por exemplo, nesse caso o substantivo, que tipo de adjetivo. A partir disso, podemos tirar conclusões diferentes sobre a estrutura da proposta. Além disso, a morfologia é necessária para a lematização (redução de palavras às formas iniciais), com a ajuda da qual podemos reduzir a dimensão do espaço de atributo e, portanto, a análise morfológica é ativamente usada para a maioria dos problemas da PNL.
Quando resolvemos um problema em que a interação entre diferentes objetos é importante (por exemplo, na tarefa de extração de relações ou na criação de um sistema de perguntas e respostas), precisamos saber muito sobre a estrutura da proposta. Isso requer análise. Na escola, todo mundo analisava uma sentença para um assunto, predicado, adição etc. A análise sintática é algo nesse espírito, mas mais complicado.
Outro exemplo de um recurso adicional é a posição do token no texto. Podemos saber a priori que alguma entidade é encontrada com mais frequência no início do texto ou vice-versa no final.
Todos juntos - casamentos, sinais simbólicos e adicionais - formam um vetor de sinais simbólicos que não depende do contexto.
Recursos sensíveis ao contexto
Sinais de token sensíveis ao contexto são um conjunto de sinais que contém informações não apenas sobre o próprio token, mas também sobre seus vizinhos. Existem diferentes maneiras de calcular esses sintomas. Nos algoritmos clássicos, as pessoas simplesmente caminhavam pela “janela”: elas levavam vários (por exemplo, três) tokens para o original e vários tokens depois e depois calculavam todos os sinais em uma janela. Essa abordagem não é confiável, já que informações importantes para análise podem estar a uma distância maior que a janela, respectivamente, podemos perder alguma coisa.
Portanto, agora todos os recursos sensíveis ao contexto são calculados no nível da proposta de maneira padrão: usando redes neurais recorrentes bidirecionais LSTM ou GRU. Para obter atributos de token sensíveis ao contexto a partir de todos os tokens de oferta, independente do contexto e independente do contexto, os itens são submetidos à RNN bidirecional (única ou multicamadas). A saída da RNN bidirecional no i-ésimo momento é um sinal sensível ao contexto do i-token, que contém informações sobre os dois tokens anteriores (já que essas informações estão contidas no i-ésimo valor da RNN direta) e sobre os subsequentes (t .k. essas informações estão contidas no valor correspondente da RNN inversa).
Além disso, para cada tarefa individual, fazemos algo diferente, mas as primeiras camadas - até a RNN bidirecional, podem ser usadas para praticamente qualquer tarefa.
Esse método de obtenção de recursos é chamado de pipeline da PNL.
Vale a pena notar que, nos últimos 2 anos, os pesquisadores tentaram ativamente melhorar o pipeline de PNL - tanto em termos de velocidade (por exemplo, transformador - uma arquitetura baseada em auto-atenção que não contém RNN e, portanto, é capaz de aprender e aplicar mais rapidamente), e com ponto de vista dos sinais utilizados (agora eles estão usando ativamente sinais baseados em modelos de linguagem pré-treinados, por exemplo
ELMo , ou estão usando as primeiras camadas do modelo de linguagem pré-treinado e treinando-os novamente no caso disponível para a tarefa -
ULMFit ,
BERT ).
Incorporações em forma de palavra
Vamos dar uma olhada no que é incorporação. Grosso modo, incorporar é uma representação concisa do contexto de uma palavra. Por que é importante conhecer o contexto de uma palavra? Porque acreditamos em uma hipótese de distribuição - que palavras com significado semelhante são usadas em contextos semelhantes.
Vamos agora tentar dar uma definição rigorosa de incorporação. A incorporação é um mapeamento de um vetor discreto de recursos categóricos para um vetor contínuo com uma dimensão predeterminada.
Um exemplo canônico de incorporação é a incorporação de palavras (incorporação de forma de palavra).
O que geralmente atua como um vetor de característica discreta? Um vetor booleano correspondente a todos os valores possíveis de uma determinada categoria (por exemplo, todas as partes possíveis do discurso ou todas as palavras possíveis de algum dicionário limitado).
Para incorporações em forma de palavra, essa categoria geralmente é o índice da palavra no dicionário. Digamos que exista um dicionário com uma dimensão de 100 mil. Assim, cada palavra tem um vetor de característica discreta - um vetor booleano de dimensão 100 mil, onde em um só lugar (o índice da palavra em nosso dicionário) é um e o restante são zeros.
Por que queremos mapear nossos vetores de recursos discretos para dimensões dadas contínuas? Como vetores com uma dimensão de 100 mil não são muito convenientes para usar em cálculos, mas vetores de números inteiros das dimensões 100, 200 ou, por exemplo, 300, são muito mais convenientes.
Em princípio, não podemos tentar impor restrições adicionais a esse mapeamento. Mas, como estamos construindo esse mapeamento, vamos tentar garantir que os vetores de palavras com significado semelhante também sejam próximos em algum sentido. Isso é feito usando uma rede neural de feed-forward simples.
Incorporação de treinamento
Como os treinamentos são treinados? Estamos tentando resolver o problema de restaurar uma palavra por contexto (ou vice-versa, restaurar um contexto por palavra). No caso mais simples, obtemos o índice no dicionário da palavra anterior (o vetor booleano da dimensão do dicionário) como uma entrada e tentamos determinar o índice no dicionário da nossa palavra. Isso é feito usando uma grade com uma arquitetura extremamente simples: duas camadas totalmente conectadas. Primeiro, vem uma camada totalmente conectada do vetor booleano da dimensão do dicionário à camada oculta da dimensão de incorporação (ou seja, apenas multiplicando o vetor booleano pela matriz da dimensão desejada). E então vice-versa, uma camada totalmente conectada com softmax a partir de uma camada oculta de dimensão incorporada a um vetor de dimensão de dicionário. Graças à função de ativação softmax, obtemos a distribuição de probabilidade de nossa palavra e podemos escolher a opção mais provável.
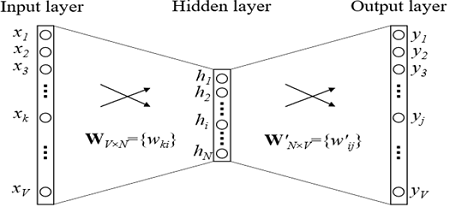
Nos modelos usados na prática, a arquitetura é mais complexa, mas não muito. A principal diferença é que não usamos um vetor do contexto para definir nossa palavra, mas vários (por exemplo, tudo em uma janela de tamanho 3). Uma opção um pouco mais popular é quando tentamos prever não uma palavra por contexto, mas um contexto por palavra. Essa abordagem é chamada Skip-gram.
Vamos dar um exemplo da aplicação de uma tarefa que é resolvida durante o treinamento de incorporações (na variante CBOW, previsões de palavras por contexto). Por exemplo, suponha que um contexto de token consista em 2 palavras anteriores. “ ”, , , “”.
, ( ), , .
, , , (, , ). — .
, , . , , , .
, — ELMo, ULMFit, BERT. , ( , , , ).
?
, 2 .
- -, , , - 100 . – : , , .
- -, . -. . . , , . , , . . , , .
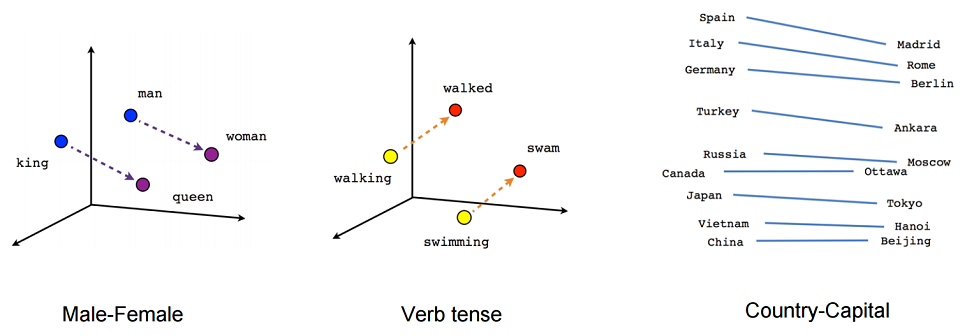
, .
, , , , , . , , , , .
NER. , , . , , , , .