
No início de 2018, foi publicado um artigo O aprendizado profundo por reforço ainda não funciona ("O aprendizado com reforço ainda não funciona"). A principal reclamação era que algoritmos modernos de aprendizado com reforço exigem aproximadamente a mesma quantidade de tempo para resolver um problema que uma pesquisa aleatória regular.
Alguma coisa mudou desde então? Não.
O aprendizado reforçado é considerado um dos três principais caminhos para a construção de IA forte. Mas as dificuldades enfrentadas por essa área de aprendizado de máquina e os métodos que os cientistas estão tentando lidar com essas dificuldades sugerem que pode haver problemas fundamentais com essa abordagem em si.
Espere, o que significa um de três? Quais são os outros dois?
Dado o sucesso das redes neurais nos últimos anos e a análise de como elas funcionam com habilidades cognitivas de alto nível, que antes eram consideradas características apenas de seres humanos e animais superiores, hoje na comunidade científica existe uma opinião de que existem três abordagens principais para criar IA forte em a base de redes neurais, que podem ser consideradas mais ou menos realistas:
1. Processamento de texto
O mundo acumulou um grande número de livros e textos na Internet, incluindo livros e livros de referência. O texto é conveniente e rápido para processamento em um computador. Teoricamente, esse conjunto de textos deve ser suficiente para treinar uma forte IA de conversação.
Está implícito que nessas matrizes textuais a estrutura completa do mundo é refletida (pelo menos, é descrita em livros didáticos e livros de referência). Mas isso não é fato. Os textos como forma de apresentação de informações são fortemente divorciados do mundo tridimensional real e do curso do tempo em que vivemos.
Bons exemplos de IA treinados em matrizes de texto são bots de bate-papo e tradutores automáticos. Como para traduzir o texto, você precisa entender o significado da frase e recontá-lo em novas palavras (em outro idioma). Existe um equívoco comum de que regras de gramática e sintaxe, incluindo uma descrição de todas as exceções possíveis, descrevem completamente um idioma específico. Isto não é verdade. A linguagem é apenas uma ferramenta auxiliar na vida, muda e se adapta facilmente a novas situações.
O problema com o processamento de texto (mesmo por sistemas especialistas, até redes neurais) é que não há um conjunto de regras, cujas frases devem ser aplicadas em quais situações. Observe - não as regras para a construção das próprias frases (o que a gramática e a sintaxe fazem), mas as frases em que situações. Na mesma situação, as pessoas pronunciam frases em idiomas diferentes que geralmente não são relacionados entre si em termos de estrutura do idioma. Compare frases com extrema surpresa: "oh deus!" e "oh, merda!". Bem, e como fazer uma correspondência entre eles, conhecendo o modelo de linguagem? De jeito nenhum. Isso aconteceu por acaso historicamente. Você precisa conhecer a situação e o que eles normalmente falam em um idioma específico. É por isso que os tradutores automáticos são tão imperfeitos.
Não se sabe se esse conhecimento pode ser distinguido apenas de uma série de textos. Mas se os tradutores automáticos traduzirem perfeitamente sem cometer erros tolos e ridículos, isso será uma prova de que é possível criar uma IA forte apenas com base no texto.
2. Reconhecimento de imagem
Olhe para esta imagem

Olhando para esta foto, entendemos que as filmagens foram realizadas à noite. A julgar pelas bandeiras, o vento sopra da direita para a esquerda. E, a julgar pelo tráfego da direita, o caso não está acontecendo na Inglaterra ou na Austrália. Nenhuma dessas informações é indicada explicitamente nos pixels da imagem, isto é conhecimento externo. Na foto, existem apenas sinais pelos quais podemos usar o conhecimento obtido de outras fontes.
Você sabe mais alguma coisa olhando para esta foto?Sobre isso e o discurso ... E encontre uma garota, finalmente
Portanto, acredita-se que, se você treinar uma rede neural para reconhecer objetos em uma imagem, ela terá uma ideia interna de como o mundo real funciona. E essa visão, obtida das fotografias, certamente corresponderá ao nosso mundo real e real. Ao contrário de matrizes de textos onde isso não é garantido.
O valor das redes neurais treinadas em um conjunto de fotografias ImageNet (e agora o OpenImages V4 , COCO , KITTI , BDD100K e outros) não é de todo o fato do reconhecimento de um gato em uma foto. E isso é armazenado na penúltima camada. É aqui que um conjunto de recursos de alto nível que descrevem nosso mundo está localizado. Um vetor de 1024 números é suficiente para obter uma descrição de 1000 categorias diferentes de objetos, com 80% de precisão (e em 95% dos casos, a resposta correta estará nas 5 opções mais próximas). Apenas pense sobre isso.
É por isso que esses recursos da penúltima camada são usados com tanto êxito em tarefas completamente diferentes na visão computacional. Através do aprendizado de transferência e do ajuste fino. A partir deste vetor em 1024 números, é possível obter, por exemplo, um mapa de profundidade da imagem
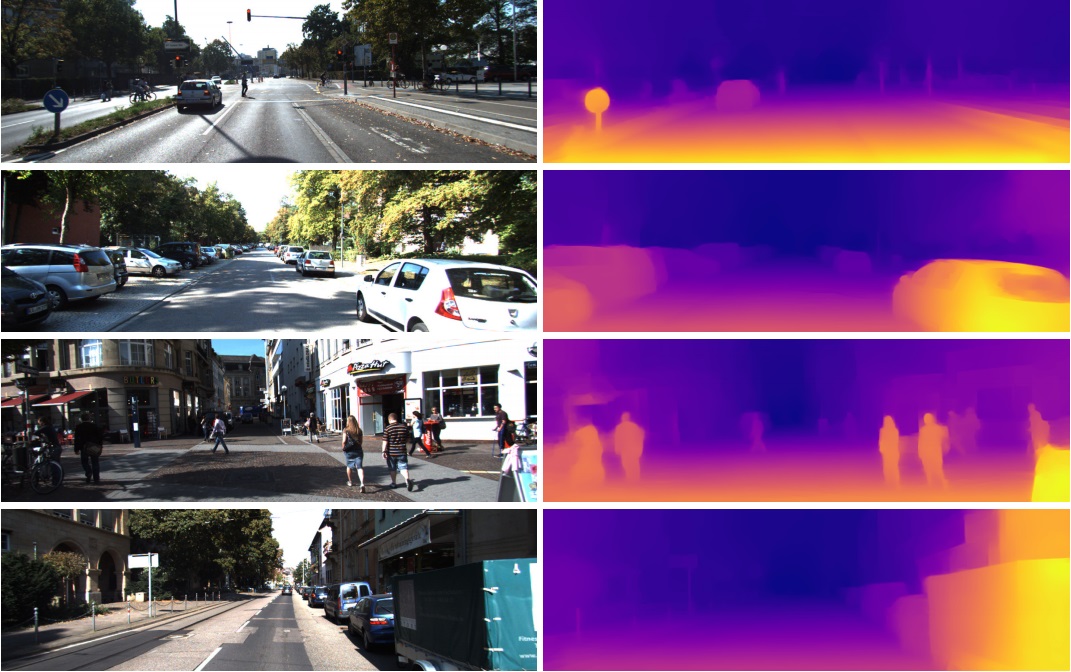
(um exemplo do trabalho em que uma rede Densenet-169 pré-treinada praticamente inalterada é usada)
Ou determine a pose de uma pessoa. Existem muitas aplicações.
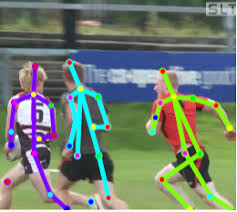
Como resultado, o reconhecimento de imagem pode ser potencialmente usado para criar uma IA forte, pois reflete realmente o modelo do nosso mundo real. Um passo da fotografia para o vídeo, e o vídeo é a nossa vida, pois obtemos cerca de 99% das informações visualmente.
Mas, a partir da fotografia, é completamente incompreensível como motivar a rede neural a pensar e tirar conclusões. Ela pode ser treinada para responder perguntas como "quantos lápis estão sobre a mesa?" (essa classe de tarefas é chamada Resposta visual às perguntas, um exemplo desse conjunto de dados: https://visualqa.org ). Ou dê uma descrição textual do que está acontecendo na foto. Esta é a classe de tarefa Legenda da imagem .

Mas isso é inteligência? Tendo desenvolvido essa abordagem, em um futuro próximo, as redes neurais poderão responder a perguntas em vídeo como "Dois pardais sentados nos fios, um deles voou para longe, quantos pardais restaram?". Isso é matemática real, em casos um pouco mais complicados, inacessíveis aos animais e no nível da educação escolar humana. Especialmente se, exceto os pardais, houver mamas sentadas ao lado deles, mas eles não precisam ser levados em consideração, pois a pergunta era apenas sobre pardais. Sim, definitivamente será inteligência.
3. Aprendizado por Reforço
A idéia é muito simples: incentivar ações que levem à recompensa e evitar levar ao fracasso. Essa é uma maneira universal de aprender e, obviamente, pode definitivamente levar à criação de uma IA forte. Portanto, tem havido tanto interesse no aprendizado por reforço nos últimos anos.
Misture, mas não agiteObviamente, é melhor criar uma IA forte combinando as três abordagens. Nas fotos e com o treinamento de reforço, você pode obter IA de nível animal. E adicionando nomes textuais de objetos às imagens (uma piada, é claro - forçando a IA a assistir vídeos onde as pessoas interagem e conversam, como quando ensinam um bebê), e treinando novamente em uma matriz de texto para obter conhecimento (um análogo de nossa escola e universidade), em teoria, você pode obter AI de nível humano. Capaz de falar.
O aprendizado reforçado tem uma grande vantagem. No simulador, você pode criar um modelo simplificado do mundo. Portanto, para uma figura humana, basta 17 graus de liberdade, em vez de 700 em uma pessoa viva (número aproximado de músculos). Portanto, no simulador, você pode resolver o problema em uma dimensão muito pequena.
Olhando para o futuro, os algoritmos modernos de Aprendizado por Reforço não são capazes de controlar arbitrariamente o modelo de uma pessoa, mesmo com 17 graus de liberdade. Ou seja, eles não podem resolver o problema de otimização, onde existem 44 números na entrada e 17. Na entrada, é possível fazer isso apenas em casos muito simples, com o ajuste fino das condições iniciais e dos hiperparâmetros. E mesmo neste caso, por exemplo, para ensinar um modelo humanóide com 17 graus de liberdade para correr, e começando de uma posição em pé (que é muito mais simples), você precisa de vários dias de cálculos em uma poderosa GPU. E casos um pouco mais complicados, por exemplo, aprender a levantar-se de uma pose arbitrária, podem nunca aprender nada. Isso é um fracasso.
Além disso, todos os algoritmos de Aprendizagem por Reforço funcionam com redes neurais deprimente pequenas, mas não conseguem lidar com a aprendizagem de grandes. As grandes redes de convolução são usadas apenas para reduzir a dimensão da imagem a vários recursos, que são alimentados com algoritmos de aprendizado com reforço. O mesmo humanóide em execução é controlado por uma rede Feed Forward com duas ou três camadas de 128 neurônios. Sério? E com base nisso, estamos tentando construir uma IA forte?
Para tentar entender por que isso acontece e o que há de errado com o aprendizado por reforço, você primeiro precisa se familiarizar com as arquiteturas básicas do aprendizado por reforço moderno.
A estrutura física do cérebro e do sistema nervoso é sintonizada pela evolução para o tipo específico de animal e suas condições de vida. Assim, no curso da evolução, uma mosca desenvolveu um sistema nervoso e esse trabalho de neurotransmissores nos gânglios (um análogo do cérebro em insetos) para evitar rapidamente um mata-moscas. Bem, não de um mata-moscas, mas de pássaros que pescam há 400 milhões de anos (brincando, os próprios pássaros apareceram 150 milhões de anos atrás, provavelmente de sapos 360 milhões de anos). Um rinoceronte suficiente para o sistema nervoso e o cérebro girarem lentamente em direção ao alvo e começarem a correr. E lá, como eles dizem, o rinoceronte tem uma visão ruim, mas esse não é o problema dele.
Mas, além da evolução, cada indivíduo específico, a partir do nascimento e ao longo da vida, trabalha precisamente o mecanismo de aprendizado usual com reforço. No caso de mamíferos e insetos também , o sistema de dopamina faz esse trabalho. Seu trabalho é cheio de segredos e nuances, mas tudo se resume ao fato de que, no caso de um prêmio, o sistema de dopamina, através de mecanismos de memória, de alguma forma corrige as conexões entre os neurônios que estavam ativos imediatamente antes. É assim que a memória associativa é formada.
Que, devido à sua associatividade, é então usado na tomada de decisão. Simplificando, se a situação atual (neurônios ativos atuais nessa situação) através da memória associativa ativar neurônios do prazer, o indivíduo seleciona as ações que realizou em uma situação semelhante e das quais se lembrou. "Escolhe ações" é uma definição ruim. Não há escolha. Os neurônios da memória de prazer simplesmente ativados, fixados pelo sistema de dopamina para uma determinada situação, ativam automaticamente os neurônios motores, levando à contração muscular. Isso ocorre se uma ação imediata for necessária.
Aprendizado artificial com reforço, como um campo de conhecimento, é necessário resolver esses dois problemas:
1. Escolha a arquitetura da rede neural (o que a evolução já fez por nós)
A boa notícia é que funções cognitivas mais altas desempenhadas no neocórtex em mamíferos (e no estriado em corvídeos ) são executadas em uma estrutura aproximadamente uniforme. Aparentemente, isso não precisa de alguma "arquitetura" rigidamente prescrita.
A diversidade das regiões do cérebro deve-se provavelmente a razões puramente históricas. Quando, à medida que evoluíam, novas partes do cérebro cresceram acima das básicas que sobraram dos primeiros animais. Pelo princípio que funciona - não toque. Por outro lado, em pessoas diferentes, as mesmas partes do cérebro reagem às mesmas situações. Isso pode ser explicado tanto pela associatividade (características e "neurônios da avó" naturalmente formados nesses locais durante o processo de aprendizado) quanto pela fisiologia. Que as vias de sinalização codificadas nos genes levam exatamente a essas áreas. Não há consenso, mas você pode ler, por exemplo, este artigo recente: "Inteligência biológica e artificial" .
2. Aprenda a treinar redes neurais de acordo com os princípios de aprendizado com reforço
Isso é o que o moderno aprendizado por reforço está fazendo principalmente. E quais são os sucessos? Na verdade não.
Abordagem ingênua
Parece que é muito simples treinar uma rede neural com reforço: realizamos ações aleatórias e, se recebermos uma recompensa, consideramos as ações tomadas como “referência”. Nós os colocamos na saída da rede neural como etiquetas padrão e treinamos a rede neural pelo método de propagação reversa do erro, para que ele produz exatamente essa saída. Bem, o treinamento de rede neural mais comum. E se as ações levaram ao fracasso, ignore esse caso ou suprima-o (definimos outros como saída, por exemplo, qualquer outra ação aleatória). Em geral, essa idéia repete o sistema de dopamina.
Mas se você tentar treinar qualquer rede neural dessa maneira, não importa quão complexa seja a arquitetura, a distribuição direta recursiva, convolucional ou comum, então ... Não funcionará!
Porque Desconhecido
Acredita-se que o sinal útil seja tão pequeno que se perca no contexto do ruído. Portanto, a rede não aprende o método padrão de propagação traseira do erro. Uma recompensa acontece muito raramente, talvez uma vez em centenas ou mesmo milhares de etapas. E até o LSTM se lembra de um máximo de 100-500 pontos na história e, em seguida, apenas em tarefas muito simples. Mas nos mais complexos, se houver 10 a 20 pontos na história, já é bom.
Mas a raiz do problema está justamente em recompensas muito raras (pelo menos em tarefas de valor prático). No momento, não sabemos como treinar redes neurais que lembrariam casos isolados. O que o cérebro lida com brilho. Você pode se lembrar de algo que aconteceu apenas uma vez na vida. E, a propósito, a maior parte do treinamento e do trabalho do intelecto é construída justamente nesses casos.
Isso é algo como um terrível desequilíbrio de classes no campo do reconhecimento de imagens. Simplesmente não há maneiras de lidar com isso. O melhor que eles conseguiram criar até agora é simplesmente enviar à entrada da rede, juntamente com novas situações, situações bem-sucedidas do passado armazenadas em um buffer especial artificial. Ou seja, ensinar constantemente não apenas casos novos, mas também casos antigos bem-sucedidos. Naturalmente, esse buffer não pode ser aumentado infinitamente, e não está claro o que exatamente armazenar nele. Ainda tentando consertar temporariamente os caminhos dentro da rede neural, ativos durante um caso de sucesso, para que o treinamento subsequente não os substitua. Uma analogia bastante próxima do que está acontecendo no cérebro, na minha opinião, embora eles também não tenham conseguido muito sucesso nessa direção. Como as novas tarefas treinadas em seus cálculos usam os resultados dos neurônios que saem dos caminhos congelados, o sinal interfere apenas nos novos congelados, e as tarefas antigas param de funcionar. Há outra abordagem curiosa: treinar a rede com novos exemplos / tarefas apenas na direção ortogonal às tarefas anteriores ( https://arxiv.org/abs/1810.01256 ). Isso não substitui a experiência anterior, mas limita drasticamente a capacidade da rede.
Uma classe separada de algoritmos projetados para lidar com esse desastre (e ao mesmo tempo dando esperança de obter uma IA forte) está sendo desenvolvida no Meta-Learning. Essas são tentativas de ensinar uma rede neural várias tarefas ao mesmo tempo. Não no sentido de reconhecer imagens diferentes em uma tarefa, ou seja, tarefas diferentes em domínios diferentes (cada uma com seu próprio cenário de distribuição e solução). Diga, reconheça fotos e ande de bicicleta ao mesmo tempo. Até agora, o sucesso também não é muito bom, já que geralmente tudo se resume a preparar uma rede neural antecipadamente com pesos universais gerais e, em seguida, rapidamente, em apenas alguns passos de descida de gradiente, para adaptá-los a uma tarefa específica. Exemplos de algoritmos de meta-aprendizado são MAML e Reptile .
Em geral, apenas esse problema (a incapacidade de aprender com exemplos únicos bem-sucedidos) põe fim ao treinamento moderno com reforço. Todo o poder das redes neurais antes desse triste fato é até agora impotente.
Esse fato, de que a maneira mais simples e óbvia não funciona, forçou os pesquisadores a voltar ao clássico Aprendizado por Reforço baseado em tabela. O qual, como ciência, apareceu até na antiga antiguidade, quando as redes neurais não estavam no projeto. Mas agora, em vez de calcular manualmente os valores em tabelas e fórmulas, vamos usar um aproximador tão poderoso como redes neurais como o objetivo funciona! Essa é a essência do aprendizado moderno por reforço. E sua principal diferença do treinamento usual de redes neurais.
Q-learning e DQN
O aprendizado por reforço (mesmo antes das redes neurais) nasceu como uma idéia bastante simples e original: vamos fazer ações aleatórias e, em seguida, para cada célula da tabela e cada direção do movimento, calculamos de acordo com uma fórmula especial (chamada equação de Bellman, esta palavra você em quase todos os trabalhos com treinamento de reforço) quão boa é essa célula e a direção escolhida. Quanto maior esse número, maior a probabilidade de esse caminho levar à vitória.
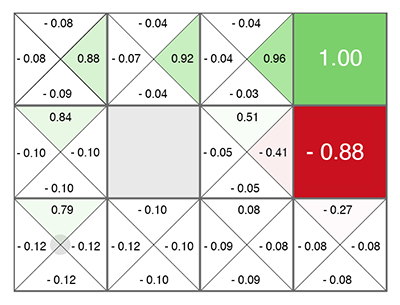
Não importa em que célula você aparece, mova-se ao longo do verde crescente! (em direção ao número máximo nas laterais da célula atual).
Esse número é chamado Q (da palavra qualidade - qualidade de escolha, obviamente), e o método é Q-learning. Substituindo a fórmula para calcular esse número por uma rede neural, ou melhor, ensinando a rede neural usando essa fórmula (mais alguns truques conectados puramente à matemática do treinamento de redes neurais), o Deepmind adotou o método DQN . Foi ele quem, em 2015, ganhou a pilha de jogos da Atari e marcou o início da revolução no Deep Reinforcement Learning.
Infelizmente, esse método em sua arquitetura funciona apenas com ações discretas e discretas. No DQN, o estado atual (a situação atual) é alimentado à entrada da rede neural e, na saída, a rede neural prediz o número Q. E como a saída da rede lista todas as ações possíveis de uma só vez (cada uma com seu próprio Q previsto), verifica-se que a rede neural no DQN implementa a função clássica Q (s, a) do Q-learning. Q state action ( Q(s,a) s a). argmax Q , .
Q, . , Q- (.. Q , ). . , (Exploration), , , . , .
, ? 5 Atari, continuous ? , -1..1 0.1, , Atari. . , . 10 . - , 10 . . DQN , 17 . , , .
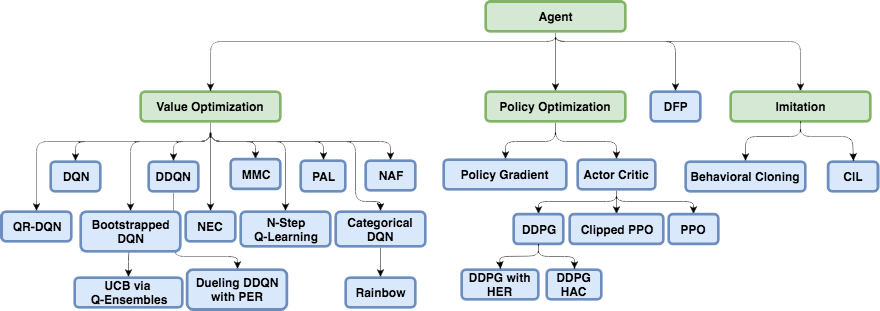
DQN, , , continuous ( ): DDQN, DuDQN, BDQN, CDQN, NAF, Rainbow. , Direct Future Prediction (DFP) , DQN . Q , DFP , . . , . , , , .
, Reinforcement Learning.
Policy Gradient
state, ( , ). , actions, . , R . ( ), ( ). . .
, R , , . ! . "" labels ( ), . , , R.
Policy Gradient. — , R, . — , , . , .
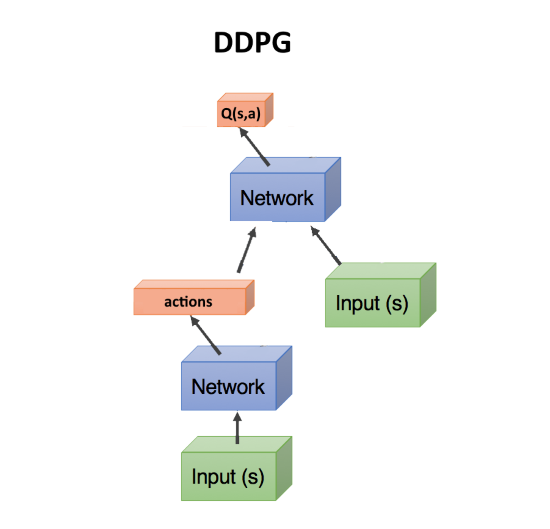
Actor-critic, DDPG
, — , . , Q- , DQN. state, action(s). state, action, , Q : Q(s,a).
, Q(s,a), ( critic, ), , ( , actor), R. , . actor-critic. Policy Gradient, , . .
DDPG. actions, continuous . DDPG continuous DQN .
Advantage Actor Critic (A3C/A2C)
critic Q(s,a) — , actor, DDPG. , .
, . , , , . , , , ( , ).
Q(s,a), Advantage: A(s,a) = Q(s,a) — V(s). A(s,a) Q(s,a) , — , V(s). A(s,a) > 0, , . A(s,a) < 0, , , .. .
V(s) state , ( s, a). — state, V(s). , state, V(s).
, Q(s,a) r, , A = r — V(s).
, V(s) ( ), — actor critic, ! state, head: actions, V(s). c , .. state. , .
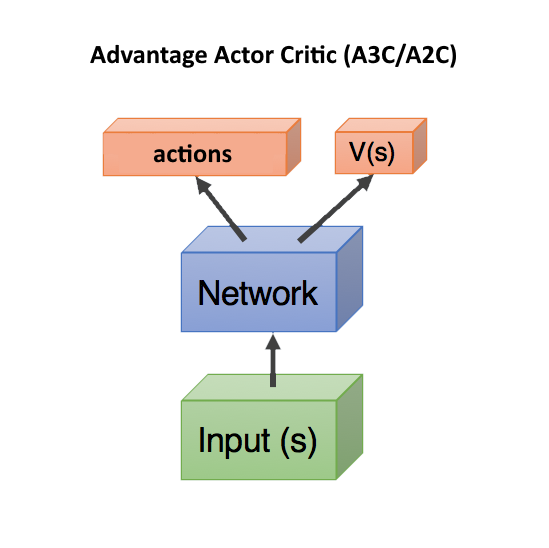
V(s) . V(s), action ( ), . Dueling Q-Network (DuDQN), Q(s,a) Q(s,a) = V(s) + A(a), .
Asynchronous Advantage Actor Critic (A3C) , , actor. batch . , actor. , , . , A2C — A3C, actor ( ). A2C , , .
TRPO, PPO, SAC
, .
, . Reinforcement Learning , , , — , . .
— TRPO PPO, state-of-the-art, Actor-Critic. PPO RL. , OpenAI Five Dota 2.
, TRPO PPO — , . , A3C/A2C , . , policy , . - gradient clipping , . , ( , ), , , - .
Recentemente, o algoritmo Soft-Actor-Critic (SAC) vem ganhando popularidade. Não é muito diferente do PPO, apenas um objetivo foi adicionado ao aprender a aumentar a entropia na política. Torne o comportamento do agente mais aleatório. Não, não é assim. Que o agente foi capaz de agir em situações mais aleatórias. Isso aumenta automaticamente a confiabilidade da política, assim que o agente estiver pronto para qualquer situação aleatória. Além disso, o SAC exige um pouco menos de exemplos de treinamento que o PPO e é menos sensível às configurações de hiperparâmetro, o que também é uma vantagem. No entanto, mesmo com o SAC, para treinar um humanóide para correr com 17 graus de liberdade, a partir de uma posição ereta, você precisa de cerca de 20 milhões de quadros e cerca de um dia de cálculo em uma GPU. Condições iniciais mais difíceis, digamos, para ensinar um humanóide a se levantar de uma pose arbitrária, podem não ser ensinadas.
Total, a recomendação geral no Aprendizado por Reforço moderno: use SAC, PPO, DDPG, DQN (nessa ordem, decrescente).
Baseado em modelo
Existe outra abordagem interessante, indiretamente relacionada ao aprendizado por reforço. Isso é para construir um modelo do ambiente e usá-lo para prever o que acontecerá se tomarmos alguma ação.
Sua desvantagem é que não diz de forma alguma quais ações devem ser tomadas. Apenas sobre o resultado deles. Mas essa rede neural é fácil de treinar - basta treinar em qualquer estatística. Acontece algo como um simulador de mundo baseado em uma rede neural.
Depois disso, geramos um grande número de ações aleatórias, e cada uma é conduzida por esse simulador (por uma rede neural). E olhamos qual deles trará a recompensa máxima. Há uma pequena otimização - para gerar não apenas ações aleatórias, mas desviar-se de acordo com a lei normal da trajetória atual. E, de fato, se levantarmos a mão, com alta probabilidade, precisamos continuar a aumentá-la. Portanto, primeiro você precisa verificar os desvios mínimos da trajetória atual.
O truque aqui é que mesmo um simulador físico primitivo como MuJoCo ou pyBullet produz cerca de 200 FPS. E se você treina uma rede neural para prever o avanço de pelo menos algumas etapas, em ambientes simples, é possível obter facilmente lotes de previsões de 2000 a 5000 por vez. Dependendo do poder da GPU, é possível obter uma previsão para dezenas de milhares de ações aleatórias por segundo devido à paralelização na GPU e à velocidade computacional na rede neural. A rede neural aqui simplesmente atua como um simulador muito rápido da realidade.
Além disso, como a rede neural pode prever o mundo real (essa é uma abordagem baseada em modelos, no sentido geral), o treinamento pode ser realizado inteiramente na imaginação, por assim dizer. Esse conceito no Aprendizado por Reforço é chamado Mundos dos Sonhos, ou Modelos do Mundo. Isso funciona bem, uma boa descrição está aqui: https://worldmodels.imtqy.com . Além disso, possui uma contrapartida natural - sonhos comuns. E rolagem múltipla de eventos recentes ou planejados na cabeça.
Imitação de aprendizagem
Devido à impotência de os algoritmos de Aprendizagem por Reforço não funcionarem em grandes dimensões e tarefas complexas, as pessoas decidiram pelo menos repetir as ações de especialistas na forma de pessoas. Aqui, bons resultados foram alcançados (inatingíveis pelo aprendizado convencional por reforço). Então, OpenAI acabou por passar o jogo Montezuma's Revenge . O truque acabou sendo simples - colocar o agente imediatamente no final do jogo (no final da trajetória mostrada pela pessoa). Lá, com a ajuda do PPO, graças à proximidade da recompensa final, o agente aprende rapidamente a caminhar ao longo da trajetória. Depois disso, colocamos-lhe um pouco de volta, onde ele rapidamente aprende a chegar ao lugar que já estudou. E assim, mudando gradualmente o ponto de "renascimento" ao longo da trajetória até o início do jogo, o agente aprende a passar / simular a trajetória do especialista ao longo do jogo.
Outro resultado impressionante é a repetição de movimentos para pessoas filmadas no Motion Capture: DeepMimic . A receita é semelhante ao método OpenAI: cada episódio não inicia do início do caminho, mas de um ponto aleatório ao longo do caminho. Em seguida, o PPO estuda com êxito os arredores deste ponto.
Devo dizer que o sensacional algoritmo Go-Explore do Uber, que passou pela Vingança de Montezuma com pontos de registro, não é um algoritmo de Aprendizado por Reforço. Esta é uma pesquisa aleatória regular, mas começando com uma célula celular visitada aleatoriamente (uma célula grossa na qual vários estados se enquadram). E somente quando a trajetória até o final do jogo é encontrada por uma pesquisa tão aleatória, a rede neural é treinada usando o Imitation Learning. De maneira semelhante à OpenAI, ou seja, começando no final da trajetória.
Curiosidade (Curiosidade)
Um conceito muito importante no aprendizado por reforço é a curiosidade. Na natureza, é um motor de pesquisa ambiental.
O problema é que, como medida de curiosidade, você não pode usar um simples erro de previsão de rede, o que acontecerá a seguir. Caso contrário, essa rede ficará pendurada na frente da primeira árvore com folhagem ondulada. Ou na frente de uma TV com comutação aleatória de canal. Como o resultado devido à complexidade será impossível de prever e o erro sempre será grande. No entanto, esta é precisamente a razão pela qual nós (pessoas) adoramos olhar para a folhagem, a água e o fogo. E como as outras pessoas trabalham =). Mas temos mecanismos de proteção para não ficarmos para sempre.
Um desses mecanismos foi inventado como o Modelo Inverso na Exploração Conduzida pela Curiosidade por
Previsão auto-supervisionada . Em resumo, um agente (rede neural), além de prever quais ações são melhores executadas em uma determinada situação, tenta adicionalmente prever o que acontecerá com o mundo após as ações tomadas. E ele usa essa previsão do mundo para o próximo passo, para que ele e o passo atual possam prever suas ações tomadas anteriormente (sim, é difícil, você não consegue descobrir sem um litro).
Isso leva a um efeito curioso: o agente fica curioso apenas para o que ele pode influenciar com suas ações. Ele não pode influenciar os galhos de uma árvore, de modo que eles se tornam desinteressantes para ele. Mas ele pode andar pelo distrito, por isso está curioso para andar e explorar o mundo.
No entanto, se o agente tiver um controle remoto de TV que alterna canais aleatórios, ele poderá afetá-lo! E ele ficará curioso em clicar nos canais ad infinitum (já que ele não pode prever qual será o próximo canal, porque é aleatório). Uma tentativa de contornar esse problema foi feita pelo Google no trabalho de Curiosidade episódica por meio da acessibilidade .
Mas talvez o melhor resultado de ponta seja devido à curiosidade, atualmente a OpenAI é proprietária da idéia de Random Network Distillation (RND) . Sua essência é que é necessária uma segunda rede completamente inicializada aleatoriamente e o estado atual é alimentado a ela. E nossa principal rede neural em funcionamento está tentando adivinhar o resultado dessa rede neural. A segunda rede não é treinada, permanece fixa o tempo todo como foi inicializada.
Qual é o objetivo? O ponto é que, se algum estado já foi visitado e estudado por nossa rede de trabalho, ele poderá prever com mais ou menos sucesso a saída dessa segunda rede. E se esse é um estado novo, onde nunca estivemos, nossa rede neural não será capaz de prever a saída dessa rede RND. Esse erro ao prever a saída daquela rede inicializada aleatoriamente é usado como um indicador de curiosidade (ele oferece grandes recompensas se não pudermos prever sua saída nessa situação).
Por que isso funciona não é totalmente claro. Mas eles escrevem que isso elimina o problema quando o destino da previsão é estocástico e quando não há dados suficientes para prever o que acontecerá a seguir (o que gera um grande erro de previsão nos algoritmos comuns de curiosidade). De um jeito ou de outro, mas o RND realmente mostrou excelentes resultados de pesquisa com base na curiosidade nos jogos. E lida com o problema da TV aleatória.
Com o RND, a curiosidade no OpenAI pela primeira vez honestamente (e não através de uma pesquisa aleatória preliminar, como no Uber) passou o primeiro nível da Vingança de Montezuma. Nem sempre e de maneira não confiável, mas de vez em quando acontece.

Qual é o resultado?
Como você pode ver, em apenas alguns anos, o Aprendizado por Reforço já percorreu um longo caminho. Não apenas algumas soluções bem-sucedidas, como em redes convolucionais, em que conexões ressudais e pulam tornaram possível treinar redes com centenas de camadas de profundidade, em vez de uma dúzia de camadas apenas com a função de ativação Relu, que superou o problema de gradientes de fuga no sigmóide e no tanh. No aprendizado com reforço, houve progresso nos conceitos e no entendimento das razões pelas quais esta ou aquela versão ingênua da implementação não funcionou. A palavra-chave "não funcionou".
Mas, do ponto de vista técnico, tudo ainda se baseia nas previsões dos mesmos valores Q, V ou A. Não há dependências de tempo em escalas diferentes, como no cérebro (o aprendizado de reforço hierárquico não conta, a hierarquia é muito primitiva em comparação com a associatividade no cérebro vivo). Nenhuma tentativa de criar uma arquitetura de rede adaptada especificamente para o aprendizado por reforço, como aconteceu com o LSTM e outras redes recorrentes para seqüências de tempo. O Aprendizado por Reforço, ou pisa no local, regozijando-se em pequenos sucessos, ou se move em uma direção completamente errada.
Eu gostaria de acreditar que, uma vez no aprendizado por reforço, haverá um avanço na arquitetura das redes neurais, semelhante ao que aconteceu nas redes convolucionais. E veremos um aprendizado de reforço realmente funcionando. Aprendendo exemplos isolados, trabalhando com memória associativa e trabalhando em diferentes escalas de tempo.