Hoje, a linguagem R é uma das ferramentas mais poderosas e multifuncionais para trabalhar com dados, mas como sabemos quase sempre, em qualquer barril de mel há uma mosca na pomada. O fato é que R é thread único por padrão.
Provavelmente, isso não vai incomodá-lo por um tempo suficientemente longo, e é improvável que você faça essa pergunta. Mas, por exemplo, se você tiver a tarefa de coletar dados de um grande número de contas de publicidade da API, como Yandex.Direct, poderá reduzir significativamente, pelo menos duas a três vezes, o tempo necessário para coletar dados usando o multithreading.

O tópico multithreading em R não é novo e foi levantado repetidamente em Habré aqui , aqui e aqui , mas a última publicação remonta a 2013 e, como se costuma dizer, tudo o que é novo está bem esquecido. Além disso, o multithreading foi discutido anteriormente para calcular modelos e treinar redes neurais, e falaremos sobre o uso de assincronia para trabalhar com a API. No entanto, gostaria de aproveitar esta oportunidade para agradecer aos autores desses artigos porque eles me ajudaram muito a escrever este artigo com suas publicações.
Conteúdo
A segunda parte do artigo, que trata de opções mais modernas para implementar multithreading em R, está disponível aqui .
O que é multithreading
One-threading (cálculos seqüenciais) - um modo de cálculo no qual todas as ações (tarefas) são executadas seqüencialmente, a duração total de todas as operações especificadas nesse caso será igual à soma da duração de todas as operações.
Multithreading (computação paralela) - um modo de computação no qual as ações (tarefas) especificadas são executadas em paralelo, ou seja, ao mesmo tempo, enquanto o tempo total de execução de todas as operações não será igual à soma da duração de todas as operações.
Para simplificar a percepção, vejamos a tabela a seguir:
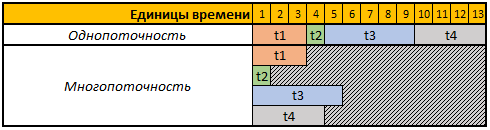
A primeira linha da tabela fornecida é de unidades de tempo condicionais. Nesse caso, não importa para nós segundos, minutos ou outros períodos.
Neste exemplo, precisamos executar 4 operações, cada operação neste caso tem uma duração de cálculo diferente, no modo de thread único, todas as 4 operações serão executadas sequencialmente uma após a outra, portanto, o tempo total para sua execução será t1 + t2 + t3 + t4, 3 + 1 + 5 + 4 = 13.
No modo multiencadeado, todas as 4 tarefas serão executadas em paralelo, ou seja, para iniciar a próxima tarefa, não há necessidade de esperar até que a anterior seja concluída; portanto, se iniciarmos nossa tarefa em 4 threads, o tempo total de cálculo será igual ao tempo de cálculo da maior tarefa; no nosso caso, é a tarefa t3, cuja duração do cálculo em nosso exemplo é 5 unidades temporárias, respectivamente, e o tempo de execução de todas as 4 operações nesse caso será igual a 5 unidades temporárias.
Quais pacotes usaremos
Para cálculos no modo multithread, usaremos os doParallel foreach , doSNOW e doParallel .
O pacote foreach permite que você use a construção foreach , que é essencialmente um loop for aprimorado.
Os doParallel e doParallel são essencialmente irmãos gêmeos, permitindo criar clusters virtuais e usá-los para realizar cálculos paralelos.
No final do artigo, usando o pacote rbenchmark mediremos e comparamos a duração das operações de coleta de dados da API Yandex.Direct usando todos os métodos descritos abaixo.
Para trabalhar com a API Yandex.Direct, usaremos o pacote ryandexdirect; neste artigo, usaremos como exemplo, mais detalhes sobre seus recursos e funções podem ser encontrados na documentação oficial .
Código para instalar todos os pacotes necessários:
install.packages("foreach") install.packages("doSNOW") install.packages("doParallel") install.packages("rbenchmark") install.packages("ryandexdirect")
Desafio
Você deve escrever um código que solicite uma lista de palavras-chave de qualquer número de contas de publicidade Yandex.Direct. O resultado deve ser coletado em um período, no qual haverá um campo adicional com o login da conta de publicidade à qual a palavra-chave pertence.
Além disso, nossa tarefa é escrever um código que execute essa operação o mais rápido possível em qualquer número de contas de publicidade.
Autorização no Yandex.Direct
Para trabalhar com a API da plataforma de publicidade Yandex.Direct, inicialmente é necessário passar por uma autorização em cada conta da qual planejamos solicitar uma lista de palavras-chave.
Todo o código fornecido neste artigo reflete um exemplo de trabalho com contas de publicidade Yandex.Direct regulares, se você estiver trabalhando em uma conta de agente, precisará usar o argumento AgencyAccount e passar o login da conta do agente para ele. Você pode descobrir mais sobre como trabalhar com contas de agente do Yandex.Direct usando o pacote ryandexdirect aqui .
Para autorização, é necessário executar a função yadirAuth partir do pacote yadirAuth , repetir o código abaixo é necessário para cada conta da qual você solicitará uma lista de palavras-chave e seus parâmetros.
ryandexdirect::yadirAuth(Login = " ")
O processo de autorização no Yandex.Direct através do pacote ryandexdirect totalmente seguro, apesar de ser transmitido por um site de terceiros. Eu já falei detalhadamente sobre a segurança de seu uso no artigo "Quão seguro é usar pacotes R para trabalhar com a API de sistemas de publicidade"
Após a autorização, um arquivo login.yadirAuth.RData será criado em cada conta no seu diretório de trabalho, que armazenará as credenciais para cada conta. O nome do arquivo será iniciado no login especificado no argumento Login . Se você precisar salvar arquivos que não estão no diretório de trabalho atual, mas em alguma outra pasta, use o argumento TokenPath , mas, neste caso, ao consultar palavras-chave usando a função yadirGetKeyWords também será necessário usar o argumento TokenPath e especificar o caminho para a pasta onde você salvou os arquivos com credenciais.
Solução sequencial de thread único usando o loop for
A maneira mais fácil de coletar dados de várias contas ao mesmo tempo é usar o loop for . Simples, mas não o mais eficaz, porque Um dos princípios de desenvolvimento na linguagem R é evitar o uso de loops no código.
Abaixo está um código de exemplo para coletar dados de 4 contas usando o loop for; na verdade, você pode usar este exemplo para coletar dados de qualquer número de contas de publicidade.
Código 1: processamos 4 contas usando o loop for usual library(ryandexdirect) # logins <- c("login_1", "login_2", "login_3", "login_4") # res1 <- data.frame() # for (login in logins) { temp <- yadirGetKeyWords(Login = login) temp$login <- login res1 <- rbind(res1, temp) }
A medição do tempo de execução usando a função system.time mostrou o seguinte resultado:
Tempo de trabalho:
Usuário: 178.83
sistema: 0.63
passou: 320.39
A coleta de palavras-chave para 4 contas levou 320 segundos e, a partir das mensagens informativas que a função yadirGetKeyWords exibe durante a operação, a maior conta é vista, das quais 5970 palavras-chave foram recebidas, 142 segundos foram processados.
Solução multithreading em R
Eu já escrevi acima que, para multithreading, usaremos os doParallel e doParallel .
Quero chamar a atenção para o fato de que quase qualquer API tem suas próprias limitações, e a API Yandex.Direct não é exceção. De fato, a ajuda para trabalhar com a API Yandex.Direct diz:
Não são permitidas mais de cinco solicitações simultâneas de API em nome de um usuário.
Portanto, apesar de, neste caso, considerarmos um exemplo com a criação de 4 fluxos, ao trabalhar com o Yandex.Direct, você pode criar 5 fluxos, mesmo que envie todas as solicitações sob o mesmo usuário. Mas é mais racional usar 1 encadeamento por 1 núcleo do seu processador, você pode determinar o número de núcleos físicos do processador usando o comando parallel::detectCores(logical = FALSE) , o número de núcleos lógicos pode ser encontrado usando o parallel::detectCores(logical = TRUE) . Uma compreensão mais detalhada do que é possível ter um núcleo lógico e físico na Wikipedia .
Além do limite no número de solicitações, há um limite diário no número de pontos para acessar a API Yandex.Direct, pode ser diferente para todas as contas, cada solicitação também consome um número diferente de pontos, dependendo da operação que está sendo executada. Por exemplo, para consultar uma lista de palavras-chave, serão deduzidos 15 pontos para uma consulta concluída e 3 pontos para cada 2000 palavras, você pode descobrir como os pontos são baixados no certificado oficial . Você também pode ver informações sobre o número de pontos marcados e disponíveis, bem como o limite diário das mensagens de informações retornadas ao console pela função yadirGetKeyWords .
Number of API points spent when executing the request: 60 Available balance of daily limit API points: 993530 Daily limit of API points:996000
Vamos lidar com doSNOW e doParallel em ordem.
Pacote DoSNOW e recursos multithread
Reescrevemos a mesma operação para o modo de cálculos multithread, criamos 4 threads nesse caso e, em vez do loop for , usamos a construção foreach .
Código 2: computação paralela com doSNOW library(foreach) library(doSNOW) # logins <- c("login_1", "login_2", "login_3", "login_4") cl <- makeCluster(4) registerDoSNOW(cl) res2 <- foreach(login = logins, # - .combine = 'rbind', # .packages = "ryandexdirect", # .inorder=F ) %dopar% {cbind(yadirGetKeyWords(Login = login), login) } stopCluster(cl)
Nesse caso, a medição do tempo de execução usando a função system.time mostrou o seguinte resultado:
Tempo de trabalho:
usuário: 0,17
sistema: 0.08
aprovada: 151.47
O mesmo resultado, ou seja, recebemos a coleção de palavras-chave de 4 contas Yandex.Diretas em 151 segundos, ou seja, 2 vezes mais rápido. Além disso, escrevi no último exemplo quanto tempo levou para carregar uma lista de palavras-chave da maior conta (142 segundos), ou seja, neste exemplo, o tempo total é quase idêntico ao tempo de processamento da maior conta. O fato é que, com a ajuda da função foreach , lançamos simultaneamente o processo de coleta de dados em 4 fluxos, ou seja, ao mesmo tempo, coletamos dados das 4 contas, respectivamente, o tempo total é igual ao tempo de processamento da maior conta.
makeCluster dar uma pequena explicação para o código 2 , a função makeCluster responsável pelo número de threads, nesse caso, criamos um cluster de 4 núcleos de processador, mas como escrevi anteriormente ao trabalhar com a API Yandex.Direct, você pode criar 5 threads, independentemente de quantas contas você precisa processar 5-15-100 ou mais, pode enviar 5 solicitações para a API ao mesmo tempo.
Em seguida, a função registerDoSNOW inicia o cluster criado.
Depois disso, usamos a construção foreach , como eu disse anteriormente, essa construção é um loop for aprimorado. Você define o contador como o primeiro argumento, no exemplo que chamei de login e ele iterará sobre os elementos do vetor logins a cada iteração; obteríamos o mesmo resultado no loop for se escrevêssemos for ( login in logins) .
Em seguida, você precisa indicar no argumento .combine a função com a qual você combinará os resultados obtidos em cada iteração, as opções mais comuns são:
rbind - une as tabelas resultantes linha por linha, uma sob a outra;cbind - une as tabelas resultantes em colunas;"+" - resume o resultado obtido em cada iteração.
Você também pode usar qualquer outra função, mesmo auto-escrita.
O argumento .inorder = F permite acelerar um pouco mais a função se você não se importa em que ordem combinar os resultados; nesse caso, a ordem não é importante para nós.
A seguir, vem o operador %dopar% , que inicia o loop no modo de computação paralela; se você usar o operador %do% , as iterações serão executadas sequencialmente, como no loop for usual.
A função stopCluster para o cluster.
Multithreading, ou melhor, a construção foreach no modo multithread, possui alguns recursos; de fato, nesse caso, iniciamos cada processo paralelo em uma nova sessão R limpa. Portanto, para usar as funções e objetos genéricos dentro dele que foram definidos fora da construção foreach , você precisa exportá-los usando o argumento .export . Esse argumento usa um vetor de texto que contém os nomes dos objetos que você usará dentro do foreach .
Além disso, o foreach , no modo paralelo, não vê os pacotes conectados anteriormente por padrão, portanto, eles também precisam ser passados dentro do foreach usando o argumento .packages . Também é necessário transferir pacotes listando seus nomes em um vetor de texto, por exemplo .packages = c("ryandexdirect", "dplyr", "lubridate") . No exemplo de código 2 acima, dessa maneira, carregamos o pacote ryandexdirect a cada iteração do foreach .
Pacote DoParallel
Como escrevi acima, os doParallel e doParallel são gêmeos, portanto, eles têm a mesma sintaxe.
Código 5: computação paralela com doParallel library(foreach) library(doParallel) logins <- c("login_1", "login_2", "login_3", "login_4") cl <- makeCluster(4) registerDoParallel(cl) res3 <- data.frame() res3 <- foreach(login=logins, .combine= 'rbind', .inorder=F) %dopar% {cbind(ryandexdirect::yadirGetKeyWords(Login = login), login) stopCluster(cl)
Tempo de trabalho:
usuário: 0,25
sistema: 0.01
aprovada: 173.28
Como você pode ver neste caso, o tempo de execução difere um pouco do exemplo anterior de código de computação paralela usando o pacote doSNOW .
Teste de velocidade entre as três abordagens revisadas
Agora execute o teste de velocidade usando o pacote rbenchmark .
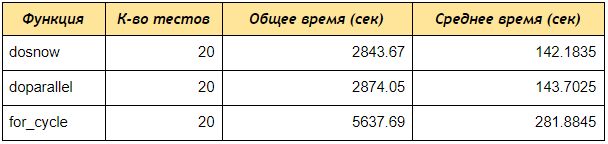
Como você pode ver, mesmo em um teste de 4 contas, os doParallel e doParallel receberam dados por palavras-chave 2 vezes mais rápido que o loop for sequencial, se você criar um cluster de 5 núcleos e processar 50 ou 100 contas, a diferença será ainda mais significativa.
Código 6: Script para comparar a velocidade da multithreading e da computação seqüencial # library(ryandexdirect) library(foreach) library(doParallel) library(doSNOW) library(rbenchmark) # for for_fun <- function(logins) { res1 <- data.frame() for (login in logins) { temp <- yadirGetKeyWords(Login = login) res1 <- rbind(res1, temp) } return(res1) } # foreach doSNOW dosnow_fun <- function(logins) { cl <- makeCluster(4) registerDoSNOW(cl) res2 <- data.frame() system.time({ res2 <- foreach(login=logins, .combine= 'rbind') %dopar% {temp <- ryandexdirect::yadirGetKeyWords(Login = login } }) stopCluster(cl) return(res2) } # foreach doParallel dopar_fun <- function(logins) { cl <- makeCluster(4) registerDoParallel(cl) res2 <- data.frame() system.time({ res2 <- foreach(login=logins, .combine= 'rbind') %dopar% {temp <- ryandexdirect::yadirGetKeyWords(Login = login) } }) stopCluster(cl) return(res2) } # within(benchmark(for_cycle = for_fun(logins = logins), dosnow = dosnow_fun(logins = logins), doparallel = dopar_fun(logins = logins), replications = c(20), columns=c('test', 'replications', 'elapsed'), order=c('elapsed', 'test')), { average = elapsed/replications })
Concluindo, darei uma explicação do código 5 acima, com o qual testamos a velocidade do trabalho.
Inicialmente, criamos três funções:
for_fun - uma função que solicita palavras-chave de várias contas, classificando-as sequencialmente em um ciclo regular.
dosnow_fun - uma função que solicita uma lista de palavras-chave no modo multithread, usando o pacote doSNOW .
dopar_fun - uma função que solicita uma lista de palavras-chave no modo multithread, usando o pacote doParallel .
Em seguida, dentro da construção inside, executamos a função benchmark no pacote rbenchmark , especificamos os nomes dos testes (for_cycle, dosnow, doparallel) e cada função especificamos as funções, respectivamente: for_fun(logins = logins) ; dosnow_fun(logins = logins) ; dopar_fun(logins = logins) .
O argumento de replicação é responsável pelo número de testes, ou seja, quantas vezes executaremos cada função.
O argumento de colunas permite especificar quais colunas você deseja receber, no nosso caso 'teste', 'replicações', 'decorrido' significa retornar as colunas: nome do teste, número de testes, tempo total de execução de todos os testes.
Você também pode adicionar colunas calculadas ( { average = elapsed/replications } ), ou seja, a saída será uma coluna média que dividirá o tempo total pelo número de testes, portanto calculamos o tempo médio de execução de cada função.
O pedido é responsável pela classificação dos resultados do teste.
Conclusão
Neste artigo, em princípio, é descrito um método bastante universal para acelerar o trabalho com a API, mas cada API tem seus limites, portanto, especificamente neste formulário, com tantos threads, o exemplo acima é adequado para trabalhar com a API Yandex.Direct, para usá-lo com a API. de outros serviços, é necessário inicialmente ler a documentação sobre os limites da API no número de solicitações enviadas simultaneamente, caso contrário, você poderá receber um erro de Too Many Requests excesso.
A continuação deste artigo está disponível aqui .