
O aprendizado de máquina é usado ativamente em muitas áreas de nossas vidas. Os algoritmos ajudam a reconhecer sinais de trânsito, filtrar spam, reconhecer os rostos de nossos amigos no facebook e até ajudar a negociar em bolsas de valores. O algoritmo toma decisões importantes, portanto, você precisa ter certeza de que não pode ser enganado.
Neste artigo, que é o primeiro de uma série, apresentaremos o problema da segurança dos algoritmos de aprendizado de máquina. Isso não requer um alto nível de conhecimento do aprendizado de máquina do leitor, basta ter uma idéia geral dessa área.
Primeiro, fornecemos os termos usados no tópico segurança dos algoritmos de aprendizado de máquina:
Um exemplo contraditório é um vetor que alimenta uma entrada para um algoritmo no qual o algoritmo produz uma saída incorreta.
Ataque adversário - um algoritmo de ação cujo objetivo é obter um exemplo adversário.
Para entender o problema dos exemplos adversários, vamos relembrar uma das tarefas do aprendizado de máquina - aprender com um professor na classificação. Nesse problema, temos pares "rótulo de objeto" e precisamos aprender a prever o valor para novos objetos.
Se considerarmos esse problema do ponto de vista geométrico, é necessário dividir o espaço de forma a prever a classe "correta" no novo objeto. Além disso, se tivéssemos um conjunto de dados geral (por exemplo, para um conjunto de dígitos manuscritos MNIST para ter todos os tipos de imagens de todos os dígitos), esse hiperplano poderia ser realizado idealmente, desde que as classes sejam separáveis. Mas como a população geral geralmente não existe, para resolver esse problema, usamos algoritmos de aprendizado de máquina para aproximar o hiperplano “ideal” da maneira mais precisa possível, usando os dados que temos.
Qualquer desvio do hiperplano do ideal gera um certo “intervalo”, no qual os objetos são classificados incorretamente. É por isso que exemplos como o panda, classificado como gibão, aparecem. E a tarefa do atacante é reduzida a alterar o vetor dos parâmetros do objeto para que caia nessa "lacuna".
Exemplos de ataques adversos
Existe uma rede neural que detecta o rosto em uma fotografia. Ela lida com êxito com a tarefa (imagem à esquerda). Porém, depois de adicionar um pouco de ruído a essa foto (imagem à direita), o algoritmo no exemplo adversário obtido (imagem no centro) não detecta mais o rosto na imagem.

Este exemplo, demonstrado no artigo “ Ataques adversos em detectores de rosto usando otimização restrita baseada em rede neural ”, é interessante porque muitos sistemas reais de reconhecimento de rosto usam abordagens de rede neural para detectar rostos. Uma pessoa não notará a diferença ao olhar para as duas imagens.
O exemplo a seguir foi retirado do setor automotivo, ou seja, reconhecimento de sinais de trânsito. Este exemplo é interessante, pois o exemplo contraditório não precisa ser um objeto pelo menos um pouco próximo dos objetos nos quais a rede foi treinada. Por exemplo, em Sinais desonestos: enganando o reconhecimento de sinais de tráfego com anúncios e logotipos maliciosos , foi mostrado que o exemplo contraditório do sinal KFC será "reconhecido" pela rede neural original como um sinal de PARADA com 100% de probabilidade.
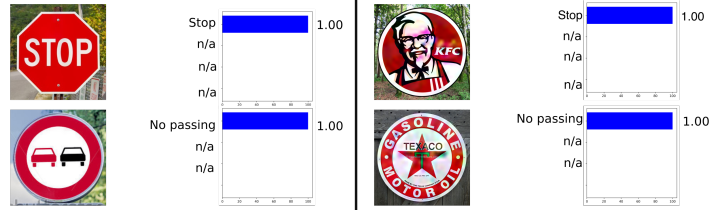
Muitos poderiam duvidar do uso de exemplos contraditórios no mundo real, já que os exemplos anteriores foram testados em um computador, enquanto na vida real esse objeto dificilmente é possível obter. Mas isso não é verdade. A síntese de exemplos adversos robustos mostrou que um exemplo contraditório feito em um computador pode ser impresso com êxito em uma impressora 3D e o algoritmo cometerá os mesmos erros que em uma simulação por computador.

Aqui você vê uma tartaruga impressa em uma impressora 3D que não foi reconhecida como tartaruga em nenhum ângulo.
O exemplo a seguir mostra o que pode ser feito se formos além do entendimento usual de ataques adversários. Ou seja, reprograme a rede de origem para usar sua própria carga útil. Em outras palavras, aprendemos a usar a rede neural de outra pessoa para resolver o problema apresentado pelo invasor. Por exemplo, a Reprogramação Adversrial da Rede Neural demonstrou como uma rede treinada no ImageNet calculava perfeitamente o número de quadrados em uma imagem e reconhecia os números do conjunto MNIST.
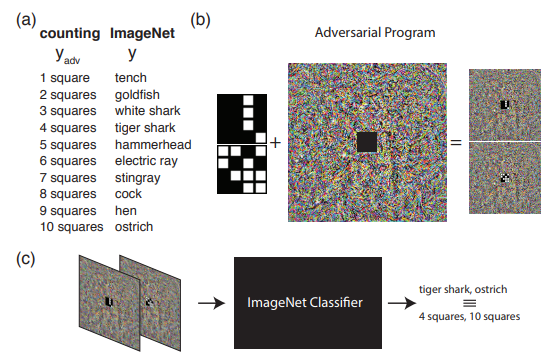
A imagem demonstra o algoritmo para trabalhar com a reprogramação adversa, que é recomendada para conhecer melhor o artigo original.
Neste artigo, gostaria de falar especificamente sobre métodos para gerar exemplos adversos e, no segundo artigo, passaremos para métodos de proteção e teste de algoritmos de aprendizado de máquina.
Classificação de Ataque
Todos os ataques podem ser divididos em 2 classes: WhiteBox (WB) e BlackBox (BB) . No caso do WB, conhecemos todas as informações sobre o modelo treinado do algoritmo, enquanto no BB temos acesso apenas à entrada e saída do modelo. De fato, a opção GrayBox ainda é possível quando não conhecemos as informações sobre o modelo treinado, mas há informações sobre o tipo de algoritmo e seus hiperparâmetros. Mas esse tipo não se destaca em uma classe separada, pois informações adicionais não são suficientes para acessar o WB, o que significa que esse é apenas um conjunto adicional de informações para a realização de um ataque de BB.
Em seguida, vale a pena classificar os ataques direcionados e não direcionados . Ataques direcionados significam que o ataque é realizado em uma determinada direção. Por exemplo, no conjunto de dados MNIST, treinamos a rede neural e obtemos a imagem 0 do conjunto de testes. Uma rede neural treinada produz uma probabilidade de classe 0 de 1,00 nesse objeto. Se queremos que o exemplo adversário seja reconhecido como classe 1 após aplicar o ataque adversário, usaremos o ataque direcionado. Caso contrário, se não for particularmente importante para nós para qual classe a rede neural receberá a imagem (o principal é que ela não é mais a classe 0), esse ataque será não direcionado.
Além disso, os ataques são divididos em uma métrica segundo a qual 2 objetos são considerados semelhantes - normas. norma - o número de parâmetros alterados. Distância euclidiana entre dois vetores. diferença máxima entre elementos entre dois vetores.
Bibliotecas Python
As bibliotecas de dados Python permitem que você trabalhe com exemplos adversos. Estes são FoolBox, CleverHans e ART-IBM.
| Foolbox | Cleverhans | ART-IBM |
|---|
| Estruturas suportadas | TensorFlow, Keras, Theano, PyTorch, Lasanha, MXNet | TensorFlow, Keras | TensorFlow, Keras, promessa MXNet, PyTorch |
Agora vamos ver os ataques com mais detalhes e começar com os ataques do WhiteBox.
Ataque L-BFGS
A declaração do método L-BFGS pode ser escrita da seguinte maneira.
Segue-se que queremos minimizar a função de perda na direção da classe de destino com a restrição de que as alterações introduzidas foram mínimas. Ao mesmo tempo, foi proposto resolver esse problema no artigo original usando o método L-BFGS, daí o nome desse ataque.
Artigo original - Propriedades intrigantes de redes neurais
Este ataque é apresentado em 2 de 3 bibliotecas dubladas anteriormente - FoolBox e CleverHans.
E a aplicação desse ataque no FoolBox leva 3 linhas de código em Python:
from foolbox.attacks import LBFGSAttack attack = LBFGSAttack(fmodel) adversarial = attack(image, label)
O uso do L-BFGS o ajudará a encontrar os melhores exemplos contraditórios com base em suas limitações, mas, primeiro, procurar um exemplo desse tipo pode levar muito tempo e, segundo, é bem possível que o método simplesmente não converja.
Ataque FGSM
O próximo estágio de desenvolvimento foi o FGSM (Fast Sign Gradient Method), que pode ser mostrado usando a fórmula:
Este método funciona muito mais rápido que o L-BFGS. Aqui, simplesmente pegamos os sinais da função gradiente da função de perda original, multiplicando o sinal por alguns , adicione à imagem original.

Aqui está um exemplo de como esse método funciona. Um mapa de ruído com igual a 0,007, e acontece que a foto do panda agora é reconhecida como Gibbon, com uma probabilidade de 99,3%
Esse método é simples de implementar, mas, ao mesmo tempo, o resultado desse método é muito barulhento.
Artigo original - Explicando e aproveitando exemplos adversos
Você pode encontrar a implementação desse método nas bibliotecas, e o uso do foolbox também não levará muito tempo.
from foolbox.attacks import FGSM attack = FGSM(fmodel) adversarial = attack(image, label)
Ataque do Deepfool
O DeepFool é um método não direcionado. Sua principal diferença em relação aos métodos anteriores é que ele tenta criar um mapa de ruído mínimo, o que enganará o algoritmo. O método não permite que você faça uma classe específica fora de uma classe, mas qualquer outra que esteja mais próxima da imagem original.

Um exemplo mostra a imagem original, na linha inferior - o método FGSM e no meio - apenas um ataque do DeepFool. Pode-se ver que a placa de ruído é muito menor do que com o FGSM.
Artigo original - DeepFool: um método simples e preciso para enganar redes neurais profundas
Esse ataque pode ser realizado usando qualquer uma das bibliotecas listadas e a implementação no ART-IBM leva apenas 3 linhas de código:
from art.attacks import DeepFool attack = DeepFool(model) img_adv = attack.generate(img)
Ataque jacobiano do mapa de saliência
No método JSMA, uma derivada direta é considerada, com base na qual um mapa de gradiente é construído. No mapa, cada parâmetro do objeto de fato corresponde à contribuição desse parâmetro para alterar o resultado final do algoritmo. Assim, o método permite alterar o menor número possível de parâmetros no objeto atacado. E, consequentemente, funciona em normal.
Artigo original - As limitações da aprendizagem profunda em ambientes adversos
Esse ataque pode ser realizado usando o CleverHans ou o ART-IBM. E no CleverHans, fica assim:
from cleverhans.attacks import SaliencyMapMethod jsma = SaliencyMapMethod(model, sees=sees) jsma_params = { 'theta' : 1., 'gamma' : 0.1, 'clip_min' : 0., 'clip_max' : 1., 'y_target' : None} adv_x = jsma.generate_np(img, **jsma_params)
Ataque de um pixel
A questão lógica é: qual número mínimo de pixels deve ser alterado para realizar um ataque ao algoritmo e, como muitos já imaginaram pelo nome do ataque, 1 pixel é suficiente.

Por exemplo, a imagem de um cavalo com apenas um pixel alterado se torna um sapo com uma probabilidade de 99,9%
Artigo original - Ataque de um pixel para enganar redes neurais profundas
Este ataque é suportado apenas no FoolBox, e sua implementação é a seguinte:
from foolbox.attacks import SinglePixelAttack attack = SinglePixelAttack(fmodel) adversarial = attack(image,max_pixel=1)
Aqui vale a pena fazer uma reserva e dizer que a implementação do algoritmo no Foolbox, em comparação com o artigo original, embora tenha um objetivo comum (alterar o número específico de pixels na imagem), mas difere no método de obtenção da imagem.
Métodos baseados na generalização do modelo BlackBox
A maioria dos métodos requer um entendimento de como a arquitetura do modelo é estruturada, o conhecimento dos valores exatos de seus parâmetros, mas na prática isso raramente é possível. E é por isso que uma direção de ataque separada aparece - ataques BlacBox / GrayBox. Para tais ataques, basta ter acesso à entrada e saída do modelo.
Um dos métodos para implementar um ataque ao modelo BlackBox é generalizar esse modelo para o modelo Student (na imagem Substitute).
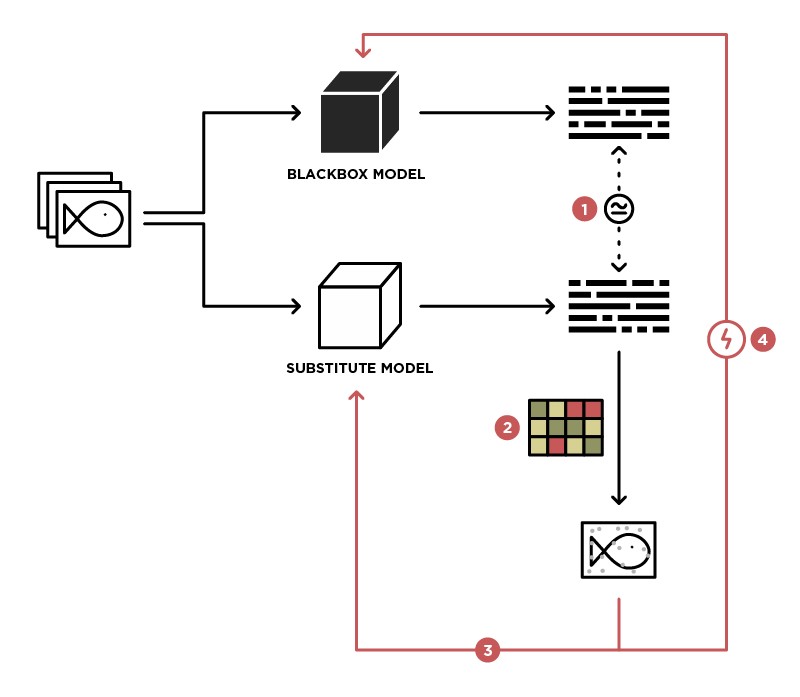
Tendo acesso para enviar dados para o modelo BlackBox (Teacher) e acesso à saída desse modelo, podemos criar um conjunto de dados no qual é possível treinar nosso próprio modelo (Student), generalizando o modelo Teacher. Depois disso, você pode usar o ataque WhiteBox no modelo Student, e com um alto grau de probabilidade, esse ataque também ocorrerá no modelo Teacher. A probabilidade de tal ataque é maior, mais conhecimento sobre o modelo de professor que temos. Por exemplo, sabemos que o modelo do professor processa imagens, na maioria das vezes arquiteturas pré-treinadas (ResNet, Inception) com pesos do ImageNet são usadas para o processamento de imagens. Com base no modelo Student com a mesma arquitetura, a probabilidade de um ataque bem-sucedido será maximizada.
Artigo original - Ataques práticos de caixa preta contra aprendizado de máquina
Este método não é apresentado em nenhuma das bibliotecas e requer implementação independente do modelo Student, e ataques a ele podem ser realizados usando os métodos descritos acima.
Métodos baseados em GAN
O próximo estágio no desenvolvimento de ataques do BlackBox foram ataques baseados na incorporação do modelo BlackBox na arquitetura de uma rede generativa-adversária (GAN), uma rede que permite gerar novos objetos, que serão posteriormente transferidos para o modelo Black-Box.
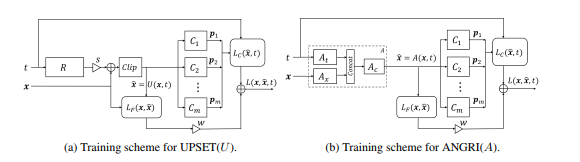
Esse método permitiu a geração de exemplos contraditórios para quase qualquer arquitetura. Também requer acesso à entrada e saída do modelo atacado.
Leia mais sobre esse método no artigo original - UPSET e ANGRI: Quebrando os Classificadores de Imagem de Alto Desempenho
Como você deve ter adivinhado, esses métodos não estão representados em nenhuma das bibliotecas.
Conclusão
De fato, há um grande número de ataques. Este artigo abrange apenas alguns deles. Esperamos que este material tenha ajudado você a entender os conceitos básicos de exemplos contraditórios e seus algoritmos de geração. Para uma revisão mais detalhada, recomendamos que você leia os artigos e materiais originais da lista de referências.
Vejo você no próximo artigo, que se concentrará em métodos de proteção e teste de algoritmos de aprendizado de máquina.
Referências
- Ameaça de ataques adversos à aprendizagem profunda em visão computacional: uma pesquisa - uma ótima visão geral dos métodos de ataque em algoritmos de aprendizagem profunda em visão computacional
- Atacando o aprendizado de máquina com exemplos adversos - um blog da OpenAI dedicado a exemplos adversários
- Awesome Adversarial Machine Learning - github com links para muitos materiais úteis sobre tópicos de Adversarial
- Apresentação sobre aprendizado de máquina adversário - Apresentação da conferência MoscowPythonConf2018 sobre aprendizado de máquina adversário