1. Introdução
Em um artigo anterior (
“Parte 2: Usando blocos Cypress PSoC UDB para reduzir o número de interrupções em uma impressora 3D” ), observei um fato muito interessante: se uma máquina no UDB removeu os dados do FIFO muito rapidamente, conseguiu perceber o estado de que havia novas não há dados no FIFO, após o qual entra em um estado falso
ocioso . Claro, eu estava interessado nesse fato. Mostrei os resultados abertos a um grupo de conhecidos. Uma pessoa respondeu que tudo isso era óbvio, e até citou os motivos. O resto não ficou menos surpreso do que eu estava no início da pesquisa. Portanto, alguns especialistas não encontrarão nada de novo aqui, mas seria bom levar essas informações ao público em geral, para que todos os programadores de microcontroladores tenham isso em mente.
Não que fosse um colapso de algum tipo de cobertura. Descobriu-se que tudo isso está bem documentado, mas o problema é que não está no principal, mas em documentos adicionais. E, pessoalmente, fiquei feliz na ignorância, acreditando que o DMA é um subsistema muito ágil que pode aumentar drasticamente a eficiência dos programas, pois há uma transferência sistemática de dados sem distrair o incremento do registro e organizar o ciclo com os mesmos comandos. Quanto à melhoria da eficiência - tudo é verdade, mas devido a coisas ligeiramente diferentes.
Mas as primeiras coisas primeiro.
Experiências com Cypress PSoC
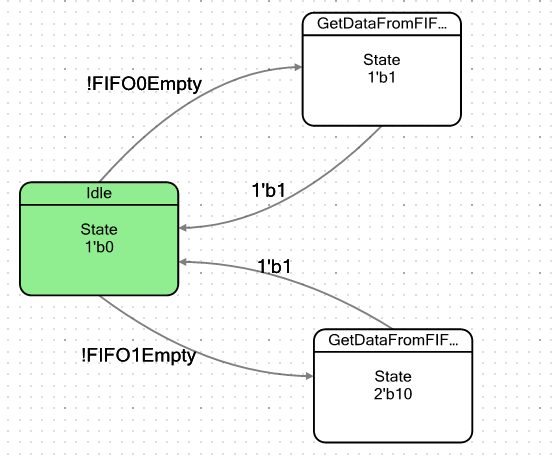
Vamos fazer uma máquina simples. Ele terá dois estados condicionalmente: o estado ocioso e o estado em que cairá quando houver pelo menos um byte de dados no FIFO. Ao entrar nesse estado, ele simplesmente pega esses dados e depois cai novamente em um estado de descanso. A palavra "condicional" não citei acidentalmente. Como temos dois FIFOs, farei dois desses estados, um para cada FIFO, para garantir que eles tenham comportamento completamente idêntico. O gráfico de transição para a máquina ficou assim:
Os sinalizadores para sair do estado ocioso são definidos da seguinte maneira:
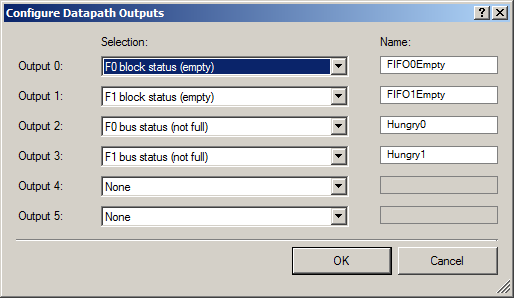
Não esqueça de enviar os bits do número de status para as entradas do Datapath:

Para o exterior, emitimos dois grupos de sinais: um par de sinais de que o FIFO possui espaço livre (para que o DMA possa começar a enviar dados para eles) e alguns sinais de que o FIFO está vazio (para exibir esse fato em um osciloscópio).

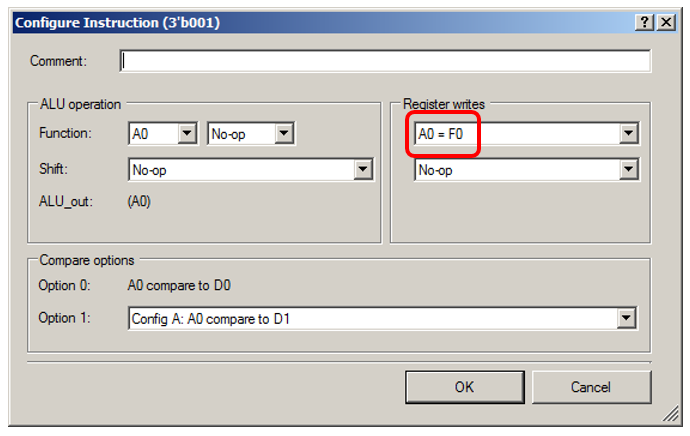
A ALU simplesmente obterá ficcionalmente os dados do FIFO:

Deixe-me mostrar os detalhes do estado "0001":
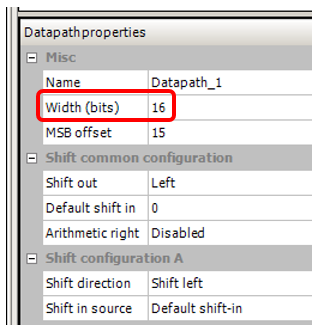
Também defini a largura do barramento, que estava no projeto no qual notei esse efeito, 16 bits:
Passamos para o esquema do próprio projeto. Externamente, dou não apenas sinais de que o FIFO está vazio, mas também pulsos de clock. Isso me permitirá ficar sem medições do cursor em um osciloscópio. Eu posso apenas tomar medidas com o dedo.
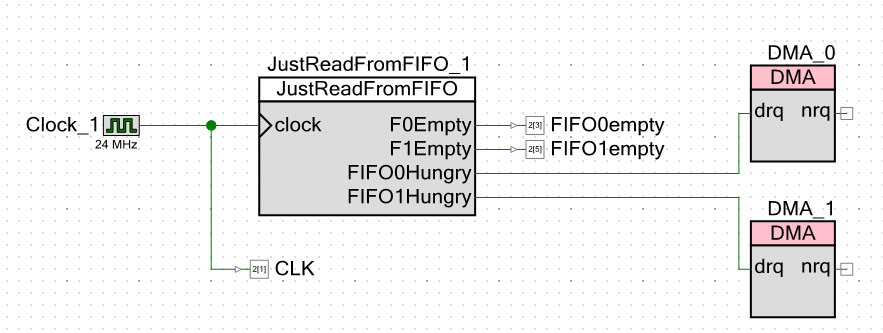
Aparentemente, fiz 24 clock megahertz. A frequência do núcleo do processador é exatamente a mesma. Quanto menor a frequência, menor a interferência em um osciloscópio chinês (oficialmente tem uma banda de 250 MHz, mas depois megahertz chinês) e todas as medições serão realizadas com relação aos pulsos de clock. Qualquer que seja a frequência, o sistema ainda funcionará com relação a eles. Eu definiria um megahertz, mas o ambiente de desenvolvimento me proibiu de inserir um valor de frequência de núcleo do processador inferior a 24 MHz.
Agora o material de teste. Para escrever em FIFO0, criei esta função:
void WriteTo0FromROM() { static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; // DMA , uint8 channel = DMA_0_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(JustReadFromFIFO_1_Datapath_1_F0_PTR)); CyDmaChRoundRobin (channel,1); // , uint8 td = CyDmaTdAllocate(); // . , . CyDmaTdSetConfiguration(td, sizeof(steps), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR / TD_AUTO_EXEC_NEXT); // CyDmaTdSetAddress(td, LO16((uint32)steps), LO16((uint32)JustReadFromFIFO_1_Datapath_1_F0_PTR)); // CyDmaChSetInitialTd(channel, td); // CyDmaChEnable(channel, 1); }
A palavra ROM no nome da função deve-se ao fato de que o array a ser enviado é armazenado na área ROM, e o Cortex M3 possui uma arquitetura Harvard. A velocidade de acesso ao barramento RAM e ao barramento ROM pode variar, eu queria verificá-lo, por isso tenho uma função semelhante para enviar uma matriz da RAM (a matriz de
etapas não possui um modificador
const estático no corpo). Bem, há o mesmo par de funções para enviar para FIFO1, o registro do receptor é diferente lá: não F0, mas F1. Caso contrário, todas as funções são idênticas. Como não notei muita diferença nos resultados, considerarei os resultados da chamada exatamente da função acima. Um raio-relógio amarelo pulsa, saída azul
FIFO0 vazia .

Primeiro, verifique a plausibilidade do motivo pelo qual o FIFO é preenchido em dois ciclos de clock. Vamos ver este site em mais detalhes:
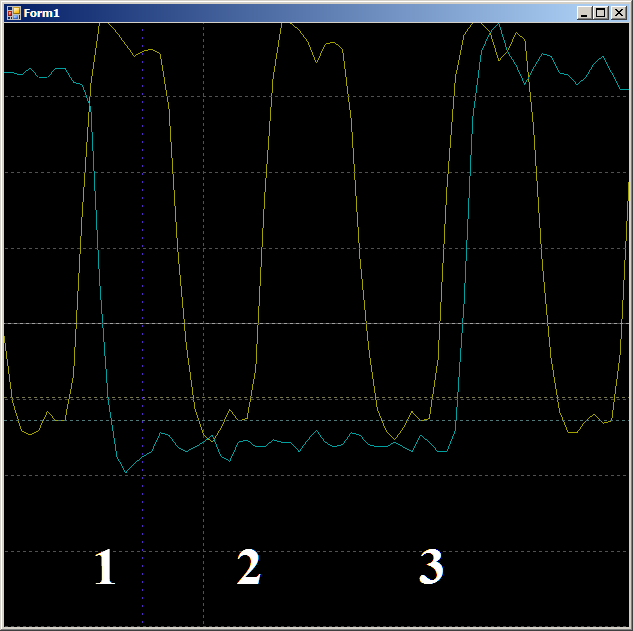
Na borda 1, os dados se enquadram no FIFO, o sinalizador
FIFO0enmpty cai. Na borda 2, o autômato entra no estado
GetDataFromFifo1 . Na borda 3, nesse estado, os dados do FIFO são copiados para o registro da ALU, o FIFO é esvaziado, o sinalizador
FIFO0vaz é
levantado novamente. Ou seja, a forma de onda se comporta de maneira plausível, você pode contar com ela no ciclo do relógio. Temos 9 peças.
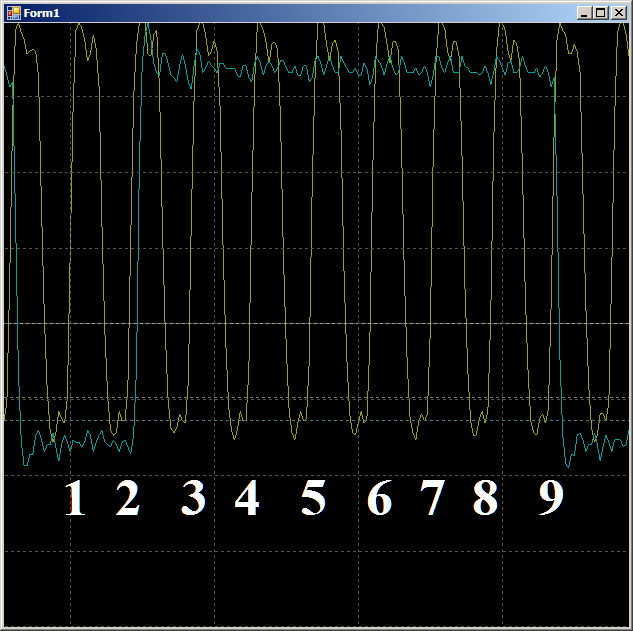 No total, na área inspecionada, são necessários 9 ciclos de relógio para copiar uma palavra de dados da RAM para o UDB usando DMA.
No total, na área inspecionada, são necessários 9 ciclos de relógio para copiar uma palavra de dados da RAM para o UDB usando DMA.E agora a mesma coisa, mas com a ajuda do núcleo do processador. Primeiro, um código ideal dificilmente possível de ser alcançado na vida real:
volatile uint16_t* ptr = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; ptr[0] = 0; ptr[0] = 0;
o que se transformará em código de montagem:
ldr r3, [pc, #8] ; (90 <main+0xc>) movs r2, #0 strh r2, [r3, #0] strh r2, [r3, #0] bn 8e <main+0xa> .word 0x40006898
Sem pausas, sem ciclos extras. Dois pares de medidas seguidas ...
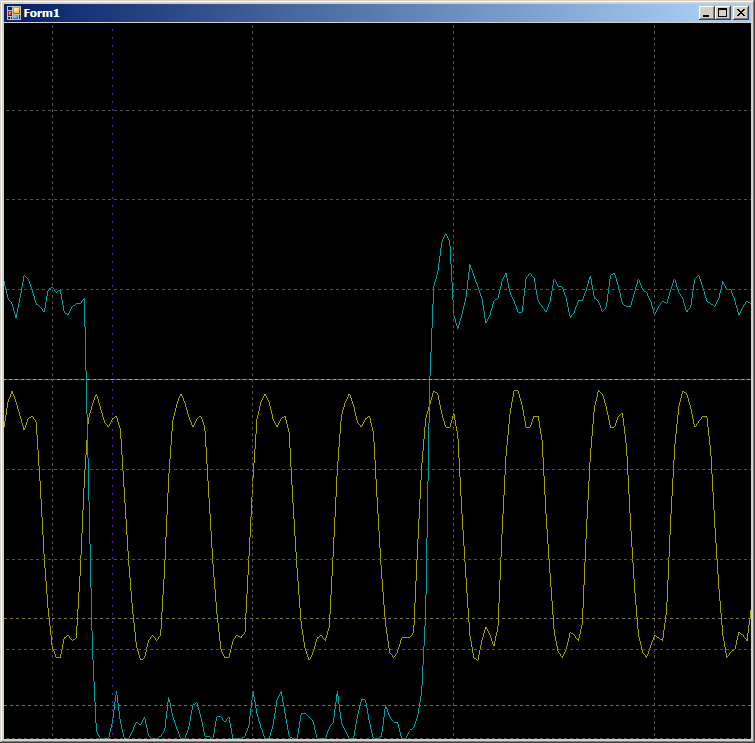
Vamos tornar o código um pouco mais real (com a sobrecarga de organizar o ciclo, buscar dados e aumentar os ponteiros):
void SoftWriteTo0FromROM() { // . // static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; uint16_t* src = steps; volatile uint16_t* dest = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; for (int i=sizeof(steps)/sizeof(steps[0]);i>0;i--) { *dest = *src++; } }
código assembler recebido:
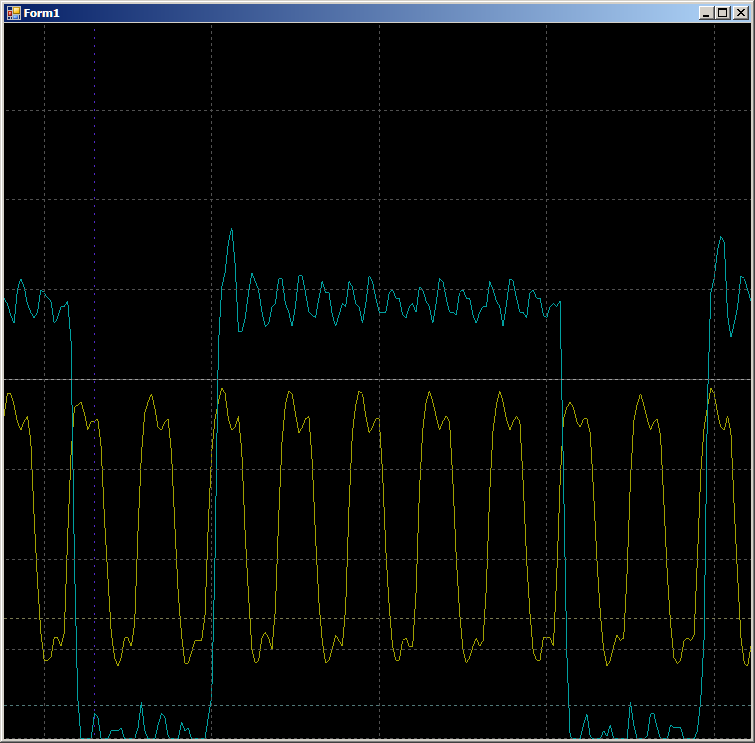
ldr r3, [pc, #14] ; (9c <CYDEV_CACHE_SIZE>) ldr r0, [pc, #14] ; (a0 <CYDEV_CACHE_SIZE+0x4>) add.w r1, r3, #28 ; 0x28 ldrh.w r2, [r3], #2 cmp r3, r1 strh r2, [r0, #0] bne.n 8e <main+0xa>
No oscilograma, vemos apenas 7 ciclos por ciclo versus nove no caso de DMA:
Um pouco sobre mito
Para ser sincero, para mim foi originalmente um choque. De alguma forma, estou acostumado a acreditar que o mecanismo DMA permite transferir dados de maneira rápida e eficiente. 1/9 da frequência do barramento não é tão rápido. Mas aconteceu que ninguém estava escondendo isso. O documento TRM para o PSoC 5LP contém várias considerações teóricas, e o documento "Tópicos avançados de DMA AN84810 - PSoC 3 e PSoC 5LP" descreve em detalhes o processo de acesso ao DMA. A latência é a culpa. O ciclo de troca com o ônibus leva um certo número de ticks. Na verdade, são essas medidas que desempenham um papel decisivo na ocorrência de um atraso. Em geral, ninguém esconde nada, mas você precisa saber disso.
Se o famoso GPIF usado no FX2LP (outra arquitetura fabricada pela Cypress) não limita nada, então aqui o limite de velocidade é devido às latências que ocorrem ao acessar o barramento.Verificação de DMA no STM32
Fiquei tão impressionado que decidi realizar um experimento no STM32. Um STM32F103 com o mesmo núcleo do processador Cortex M3 foi obtido como um coelho experimental. Ele não possui UDB do qual os sinais de serviço podem ser derivados, mas é bem possível verificar o DMA. O que é um GPIO? Este é um conjunto de registros em um espaço de endereço comum. Tudo bem. Configuramos o DMA no modo de cópia “memory-memory”, especificando a memória real (ROM ou RAM) como fonte e o registro de dados GPIO sem o incremento de endereço como receptor. Enviaremos para lá alternadamente 0 ou 1 e corrigiremos o resultado com um osciloscópio. Para começar, escolhi a porta B, era mais fácil conectar-se a ela na placa de ensaio.

Gostei muito de contar medidas com um dedo, não com cursores. É possível fazer o mesmo neste controlador? Bastante! Pegue a frequência do relógio de referência para o osciloscópio da perna do MCO, que está conectada à porta PA8 no STM32F10C8T6. A escolha das fontes para este cristal barato não é ótima (o mesmo STM32F103, mas mais impressionante, oferece muito mais opções); enviaremos o sinal SYSCLK para essa saída. Como a frequência no MCO não pode ser superior a 50 MHz, reduziremos a velocidade geral do clock do sistema para 48 MHz. Multiplicaremos a frequência do quartzo 8 MHz, não por 9, mas por 6 (já que 6 * 8 = 48):

Mesmo texto: void SystemClock_Config(void) { RCC_OscInitTypeDef RCC_OscInitStruct; RCC_ClkInitTypeDef RCC_ClkInitStruct; RCC_PeriphCLKInitTypeDef PeriphClkInit; /**Initializes the CPU, AHB and APB busses clocks */ RCC_OscInitStruct.OscillatorType = RCC_OSCILLATORTYPE_HSE; RCC_OscInitStruct.HSEState = RCC_HSE_ON; RCC_OscInitStruct.HSEPredivValue = RCC_HSE_PREDIV_DIV1; RCC_OscInitStruct.HSIState = RCC_HSI_ON; RCC_OscInitStruct.PLL.PLLState = RCC_PLL_ON; RCC_OscInitStruct.PLL.PLLSource = RCC_PLLSOURCE_HSE; // RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL9; RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL6; if (HAL_RCC_OscConfig(&RCC_OscInitStruct) != HAL_OK) { _Error_Handler(__FILE__, __LINE__); }
Vamos programar o MCO usando a biblioteca
mcucpp de Konstantin Chizhov (a partir de agora, conduzirei todas as chamadas para o equipamento através desta maravilhosa biblioteca):
// MCO Mcucpp::Clock::McoBitField::Set (0x4); // MCO Mcucpp::IO::Pa8::SetConfiguration (Mcucpp::IO::Pa8::Port::AltFunc); // Mcucpp::IO::Pa8::SetSpeed (Mcucpp::IO::Pa8::Port::Fastest);
Bem, agora configuramos a saída da matriz de dados no GPIOB:
typedef Mcucpp::IO::Pb0 dmaTest0; typedef Mcucpp::IO::Pb1 dmaTest1; ... // GPIOB dmaTest0::ConfigPort::Enable(); dmaTest0::SetDirWrite(); dmaTest1::ConfigPort::Enable(); dmaTest1::SetDirWrite(); uint16_t dataForDma[]={0x0000,0x8001,0x0000,0x8001,0x0000, 0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001}; typedef Mcucpp::Dma1Channel1 channel; // dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set(); // , DMA channel::Init (channel::Mem2Mem|channel::MSize16Bits|channel::PSize16Bits|channel::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); while (1) { } }
A forma de onda resultante é muito semelhante à do PSoC.

No meio é uma grande corcunda azul. Este é o processo de inicialização do DMA. Os pulsos azuis à esquerda foram recebidos puramente pelo software no PB1. Amplie-os mais:

2 medidas por pulso. A operação do sistema é conforme o esperado. Mas agora vamos olhar para a área maior marcada na forma de onda principal com um fundo azul escuro. Neste ponto, o bloco DMA já está em execução.
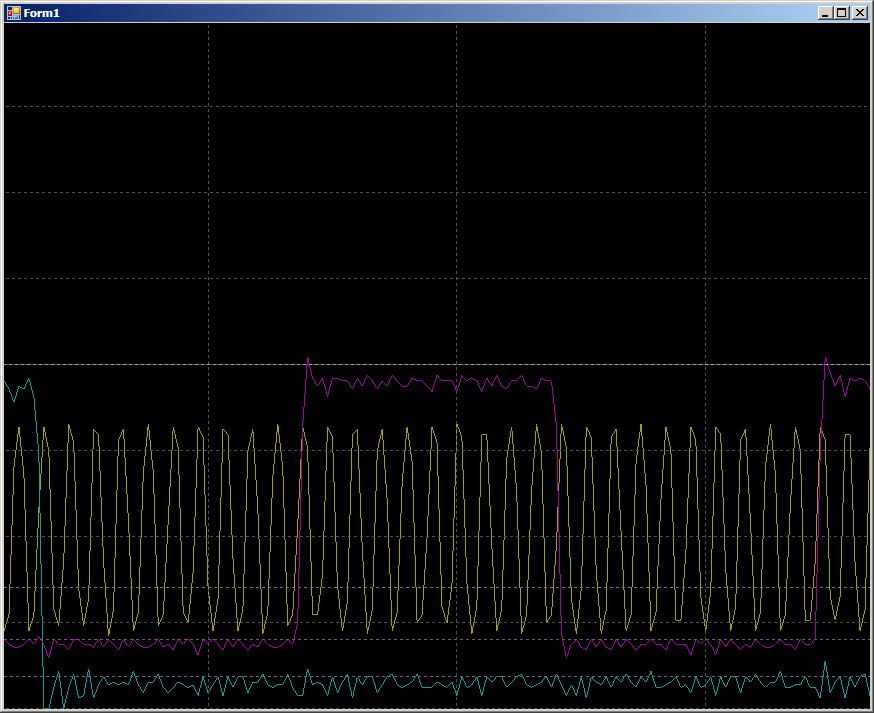
10 ciclos por mudança de linha GPIO. Na verdade, o trabalho segue com a RAM e o programa é repetido em um ciclo constante. Não há chamadas para RAM a partir do núcleo do processador. O barramento está completamente à disposição da unidade DMA, mas 10 ciclos. Mas, na verdade, os resultados não são muito diferentes daqueles observados no PSoC; portanto, comece a procurar por Notas de aplicativos relacionadas ao DMA no STM32. Havia vários deles. Há AN2548 em F0 / F1, há AN3117 em L0 / L1 / L3, há AN4031 em F2 / F4 / F77. Talvez haja mais alguns ...
Mas, no entanto, a partir deles, vemos que aqui também a culpa é da latência. Além disso, o acesso em lote do F103 ao barramento com DMA é impossível. Eles são possíveis para F4, mas não mais do que quatro palavras. Então, novamente, o problema de latência surgirá.
Vamos tentar executar as mesmas ações, mas com a ajuda de um registro do programa. Acima, vimos que a gravação direta nas portas é instantânea. Mas havia um registro perfeito. Linhas:
// dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set();
sujeito a essas configurações de otimização (você deve especificar a otimização por tempo):

transformado no seguinte código do assembler:
STR r6,[r2,#0x00] MOV r0,#0x20000 STR r0,[r2,#0x00] STR r6,[r2,#0x00]
Na cópia real, haverá uma chamada para a fonte, para o receptor, uma alteração na variável do loop, ramificação ... Em geral, muita sobrecarga (que, como se acredita, elimina apenas o DMA). Qual será a velocidade das mudanças no porto? Então, escrevemos:
uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; }
Esse código C ++ se transforma em um código de montagem:
MOVS r1,#0x0E LDRH r3,[r0],#0x02 STRH r3,[r2,#0x00] LDRH r3,[r0],#0x02 SUBS r1,r1,#2 STRH r3,[r2,#0x00] CMP r1,#0x00 BGT 0x080032A8
E temos:
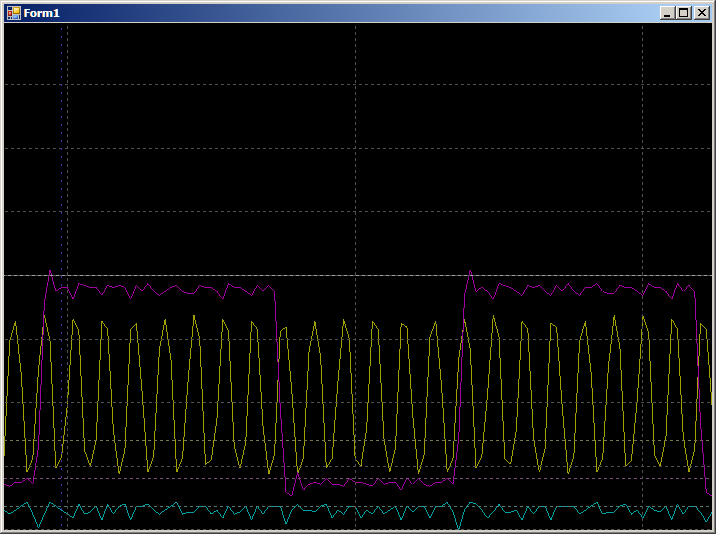
8 medidas no meio-ciclo superior e 6 na metade inferior (verifiquei, o resultado é repetido para todos os semestres). A diferença surgiu porque o otimizador fez 2 cópias por iteração. Portanto, duas medidas em um dos períodos semestrais são adicionadas à operação da filial.
Grosso modo, com a cópia de software, 14 medidas são gastas na cópia de duas palavras contra 20 medidas na mesma, mas pelo DMA. O resultado é bastante documentado, mas muito inesperado para quem ainda não leu a literatura extensa.Bom Mas o que acontece se você começar a gravar dados em dois fluxos de DMA ao mesmo tempo? Quanta velocidade cairá? Conecte o blue ray ao PA0 e reescreva o programa da seguinte maneira:
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; // , DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
Primeiro, vamos examinar a natureza dos pulsos:
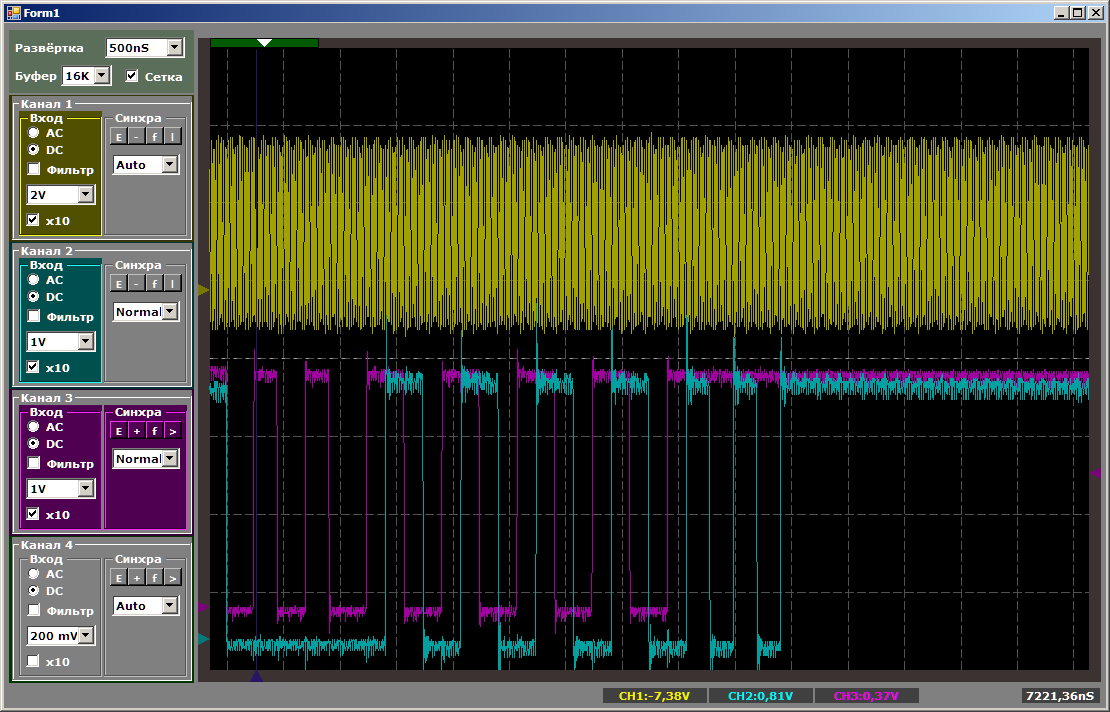
Enquanto o segundo canal está sendo sintonizado, a velocidade de cópia do primeiro é mais alta. Então, ao copiar em pares, a velocidade diminui. Quando o primeiro canal termina, o segundo começa a funcionar mais rapidamente. Tudo é lógico, resta apenas descobrir exatamente quanto a velocidade cai.
Enquanto houver apenas um canal, a gravação leva de 10 a 12 compassos (os dígitos estão flutuando).

Durante a colaboração, obtemos 16 ciclos por registro em cada porta:
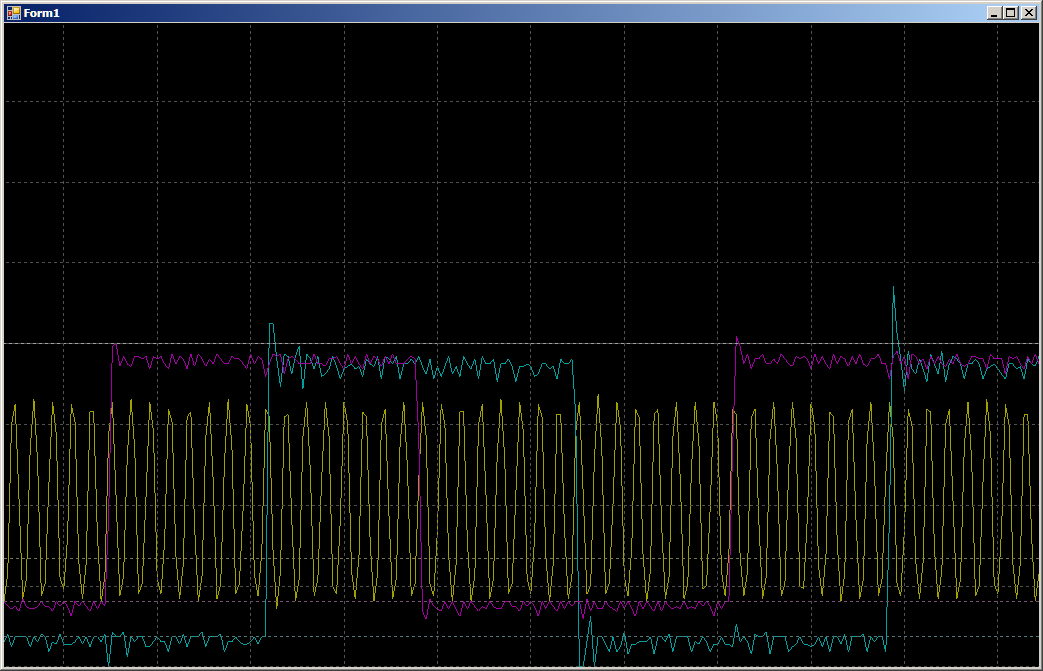
Ou seja, a velocidade não é reduzida pela metade. Mas e se você começar a escrever em três tópicos ao mesmo tempo? Adicionamos trabalho ao PC15, pois PC0 não é emitido (é por isso que 0, 1, 0, 1 ..., mas 0x0000,0x8001, 0x0000, 0x8001 ... são emitidos na matriz).
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; typedef Mcucpp::Dma1Channel3 channel3; // , DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2);
Aqui o resultado é tão inesperado que desligo o feixe que exibe a frequência do relógio. Não temos tempo para medições. Nós olhamos para a lógica do trabalho.

Até o primeiro canal terminar o trabalho, o terceiro não começou. Três canais ao mesmo tempo não funcionam! Alguma coisa sobre esse tópico pode ser deduzida do AppNote para o DMA, que diz que o F103 possui apenas dois mecanismos em um bloco (e copiamos usando um bloco de DMA, o segundo está ocioso agora e o volume do artigo já é tal que eu posso usá-lo Eu não vou). Reescrevemos o programa de amostra para que o terceiro canal inicie mais cedo do que todos os outros:

Mesmo texto: // , DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
A imagem mudará da seguinte forma:

O terceiro canal foi lançado, até trabalhou em conjunto com o primeiro, mas quando o segundo entrou no negócio, o terceiro foi suplantado até a conclusão do primeiro canal.
Um pouco sobre prioridades
Na verdade, a imagem anterior está relacionada às prioridades da DMA, existem algumas. Se todos os canais em funcionamento tiverem a mesma prioridade, seus números entrarão em jogo. Dentro de uma determinada prioridade, quem tem um número menor é aquele que tem prioridade. Vamos tentar o terceiro canal para indicar uma prioridade global diferente, elevando-a acima de todos os outros (ao longo do caminho, também aumentaremos a prioridade do segundo canal):

Mesmo texto: channel3::Init (channel3::PriorityVeryHigh|channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel1::PriorityVeryHigh|channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
Agora, o primeiro que costumava ser o mais legal ficará em desvantagem.
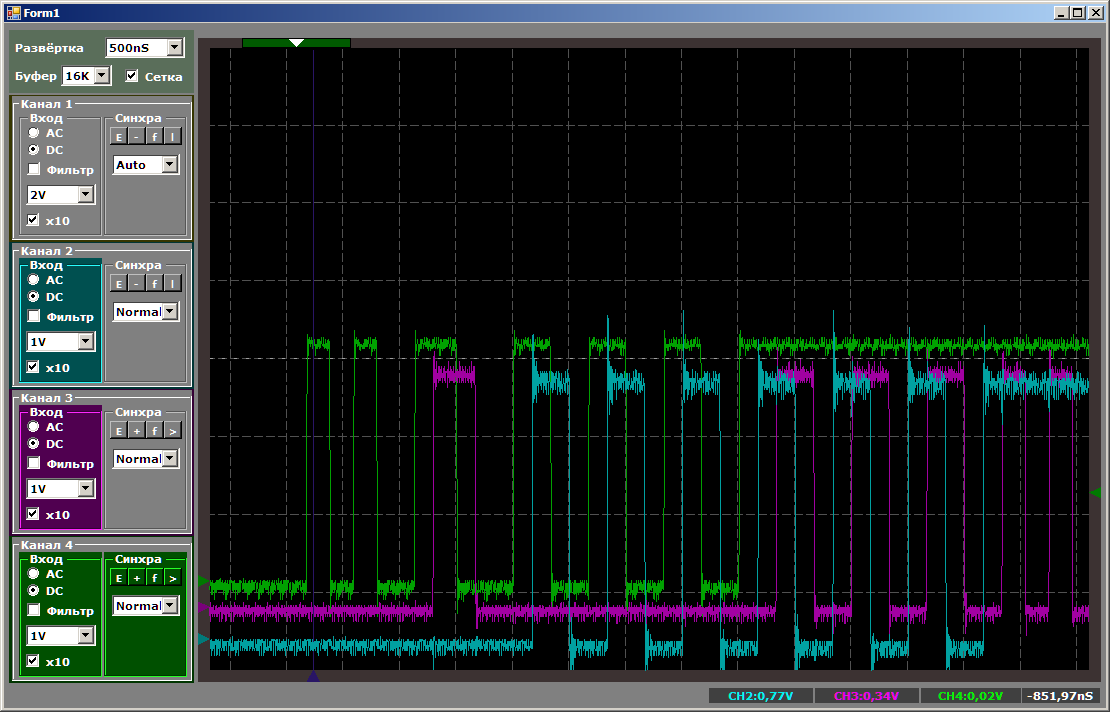
No total, vemos que, mesmo reproduzindo prioridades, o STM32F103 não pode iniciar mais de dois threads em um bloco DMA. Em princípio, o terceiro segmento pode ser executado no núcleo do processador. Isso nos permitirá comparar o desempenho.
// , DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; }
Primeiro, a imagem geral, que mostra que tudo funciona em paralelo e o núcleo do processador tem a maior velocidade de cópia:
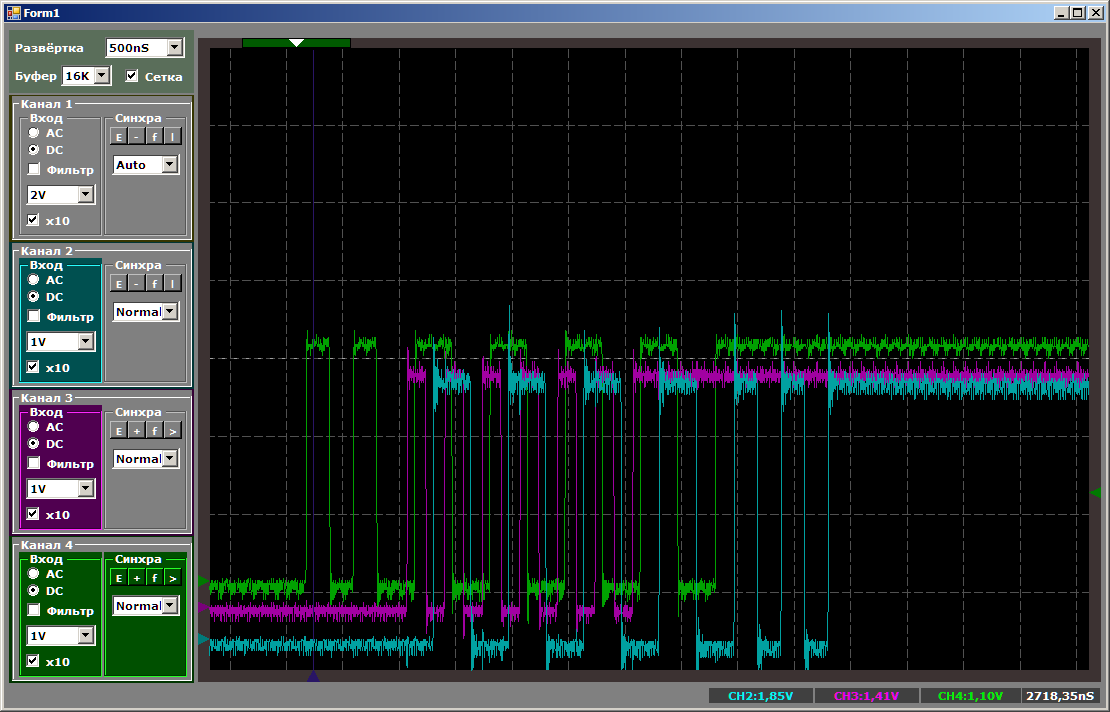
E agora darei a todos a oportunidade de contar as medidas no momento em que todos os fluxos de cópias estiverem ativos:
O núcleo do processador prioriza todos
Agora, voltemos ao fato de que, durante a operação de dois segmentos, enquanto o segundo canal foi sintonizado, o primeiro forneceu dados para um número diferente de ciclos de clock. Esse fato também está bem documentado no AppNote no DMA. O fato é que, durante a instalação do segundo canal, as solicitações à RAM eram enviadas periodicamente e o núcleo do processador tem maior prioridade ao acessar a RAM do que o núcleo do DMA. Quando o processador solicitou alguns dados, o DMA retirou os ciclos do relógio, recebeu os dados com um atraso e, portanto, copiou mais lentamente. Vamos fazer o último experimento de hoje. Vamos trazer o trabalho para um mais real. Após iniciar o DMA, não entraremos em um ciclo vazio (quando definitivamente não houver acesso à RAM), mas executaremos uma operação de cópia da RAM para a RAM, mas essa operação não estará relacionada à operação dos núcleos do DMA:
channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint32_t src1[0x200]; uint32_t dest1 [0x200]; while (1) { uint32_t* src = src1; uint32_t* dest = dest1; for (int i=sizeof(src1)/sizeof(src1[0]);i>0;i--) { *dest++ = *src++; } }

Em alguns lugares, o ciclo aumentou de 16 para 17 medidas. Eu tinha medo que fosse pior.
Comece a tirar conclusões
Na verdade, nos voltamos para o que eu queria dizer.
Vou começar de longe. Alguns anos atrás, quando comecei a estudar o STM32, estudei as versões do MiddleWare para USB existentes naquele momento e me perguntei por que os desenvolvedores removeram a transferência de dados por meio do DMA. Era evidente que inicialmente essa opção estava à vista, depois foi removida para os quintais e, no final, havia apenas rudimentos. Agora estou começando a suspeitar que entendo os desenvolvedores.
No
primeiro artigo sobre o UDB, eu disse que, embora o UDB possa trabalhar com dados paralelos, é improvável que ele possa substituir o GPIF por si mesmo, já que o barramento USB do PSoC roda em velocidade máxima versus alta velocidade para FX2LP. Acontece que há um fator limitante mais sério. O DMA simplesmente não tem tempo para fornecer dados na mesma velocidade que o GPIF, mesmo dentro do controlador, sem levar em consideração o barramento USB.
Como você pode ver, não há DMA de entidade única. Em primeiro lugar, cada fabricante faz o seu próprio caminho. Não apenas isso, mesmo um fabricante para famílias diferentes pode variar a abordagem de criação de DMA. Se você planeja carregar seriamente esta unidade, considere cuidadosamente se as necessidades serão atendidas.
Provavelmente, é necessário diluir o fluxo pessimista com uma observação otimista. Vou até destacá-la.
O DMA dos controladores Cortex M permite aumentar o desempenho do sistema com base no princípio dos famosos Javelins: "Iniciar e esquecer". Sim, a cópia de dados de software é um pouco mais rápida. Porém, se você precisar copiar vários encadeamentos, nenhum otimizador poderá fazer com que o processador os conduza sem a sobrecarga de recarregar e girar loops de registro. Além disso, para portas lentas, o processador ainda deve aguardar disponibilidade e o DMA faz isso no nível do hardware.Mas mesmo aqui várias nuances são possíveis. Se a porta for relativamente lenta ... Bem, digamos, um SPI operando na frequência mais alta possível, existem teoricamente possíveis situações em que o DMA não tem tempo para coletar dados do buffer e ocorre um estouro. Ou vice-versa - coloque os dados no registro do buffer. Quando o fluxo de dados é único, é improvável que isso aconteça, mas quando existem muitos deles, vimos que sobreposições incríveis podem ocorrer. Para lidar com isso, você deve desenvolver tarefas não separadamente, mas em combinação. E os testadores tentam provocar esses problemas (um trabalho destrutivo para os testadores).
Mais uma vez, ninguém oculta esses dados. Mas, por alguma razão, tudo isso geralmente não está contido no documento principal, mas nas Notas sobre o Aplicativo. Portanto, minha tarefa era chamar a atenção dos programadores para o fato de que o DMA não é uma panacéia, mas apenas uma ferramenta conveniente.
Mas, é claro, não apenas programadores, mas também desenvolvedores de hardware. Digamos, em nossa organização, um grande complexo de software e hardware esteja sendo desenvolvido para depuração remota de sistemas embarcados. A idéia é que alguém esteja desenvolvendo um dispositivo, mas queira solicitar o "firmware" ao lado. E por algum motivo, não pode fornecer equipamentos para o lado. Pode ser volumoso, pode ser caro, pode ser único e "precisar de você", diferentes grupos podem trabalhar com ele em fusos horários diferentes, fornecendo uma espécie de trabalho em vários turnos, que pode ser constantemente lembrado ... Em geral, você pode apresentar razões muito, nosso grupo simplesmente deixou essa tarefa como garantida.
Dessa forma, o complexo de depuração deve ser capaz de simular o maior número possível de dispositivos externos, da simulação trivial de pressionamento de botão a vários protocolos SPI, I2C, CAN, 4-20 mA e outras outras coisas, para que através deles os emuladores possam recriar um comportamento diferente blocos conectados ao equipamento que está sendo desenvolvido (eu pessoalmente fiz vários simuladores para depuração em terra de acessórios para helicópteros, em nosso
site os casos correspondentes são pesquisados pela palavra Cassel Aero ).
E assim, nos requisitos técnicos para o desenvolvimento de certos requisitos. Tanto SPI, tanto I2C, tanto GPIO. Eles devem operar em tais e tais frequências extremas. Tudo parece estar claro. Colocamos STM32F4 e ULPI para trabalhar com USB no modo HS. A tecnologia é comprovada. Mas aqui chega um longo fim de semana com as férias de novembro, que eu descobri com o UDB. Vendo que algo estava errado, à noite eu obtive os resultados práticos que são dados no começo deste artigo. E percebi que tudo, é claro, é ótimo, mas não para este projeto. Como já observei, quando o possível desempenho máximo do sistema se aproxima do limite superior, tudo deve ser projetado não separadamente, mas em um complexo.
Mas aqui o design integrado de tarefas não pode ser em princípio.
Hoje estamos trabalhando com um equipamento de terceiros, amanhã - com completamente diferente. Os ônibus serão usados pelos programadores para cada caso de emulação, a seu critério. Portanto, a opção foi rejeitada, várias pontes FTDI diferentes foram adicionadas ao circuito. Dentro da ponte, uma, duas ou quatro funções serão resolvidas de acordo com um esquema rígido e, entre as pontes, o host USB resolverá tudo. Infelizmente.
Nesta tarefa, não posso confiar no DMA. É claro que você pode dizer que os programadores sairão, mas as horas para o processo de truque são custos de mão-de-obra que devem ser evitados.Mas isso é um extremo. Na maioria das vezes, você só precisa ter em mente as limitações do subsistema DMA (por exemplo, introduza um fator de correção 10: se precisar de um fluxo de 1 milhão de transações por segundo, considere que não são 1 milhão, mas 10 milhões de ciclos) e considere o desempenho em conjunto.