Gostaria de compartilhar minha história sobre o aplicativo monolítico de migração em microsserviços. Por favor, lembre-se de que foi durante o período de 2012 a 2014. É a transcrição da minha apresentação no dotnetconf (RU) . Vou compartilhar uma história sobre como alterar todas as partes da infraestrutura.
Descrição do projeto

A principal idéia do projeto era rastrear artigos da Internet, analisá-los, salvar e criar feeds de usuários. Por um lado, nossa infraestrutura precisava ser confiável, mas, por outro lado, estávamos com um orçamento limitado. Como resultado, concordamos que:
- A degradação do desempenho do sistema é permitida.
- Algumas partes da nossa infraestrutura podem ficar inoperantes por 30 minutos.
- Em caso de desastre, o tempo de inatividade pode demorar alguns dias.
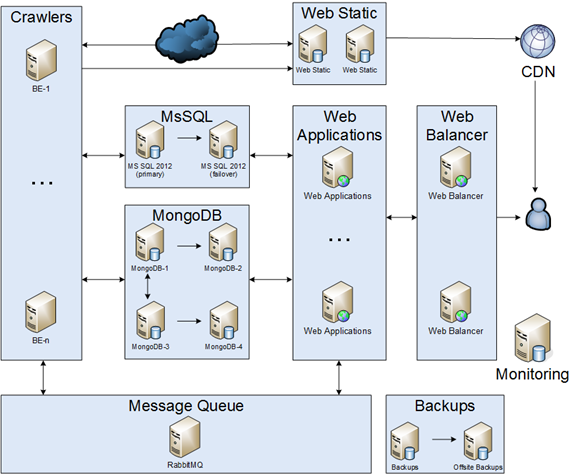
Rastreadores
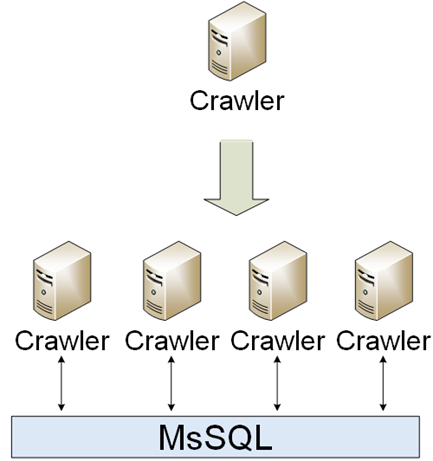
Era uma parte simples da infraestrutura. Os rastreadores devem baixar, analisar e salvar. A primeira implementação foi um único rastreador, no entanto, o mundo estava mudando e muitos rastreadores diferentes apareceram. Os rastreadores estavam se comunicando pelo MsSQL.
O tempo de inatividade não foi um problema para os rastreadores, por isso foi muito fácil dimensioná-los:
- Automatize a provisão.
- Adicione métricas de negócios.
- Colete erros.
Msql
Nosso banco de dados tinha cerca de 1 TB.
Cluster MsSQL
Havia maneiras diferentes de criar um cluster:
- Espelhamento de SQL.
- Cluster de failover do Windows - não foi o caso porque não havia san / Nas.
- AlwaysOn - era completamente novo para nós e não havia experiência nisso; portanto, não era um caso para nós.
Como resultado, decidimos usar o primeiro. Gostaria de notar que não usamos testemunha por causa do modo assíncrono, por isso criamos scripts para o comutador automático master -> slave & manual slave -> master.
Desempenho do MsSQL

O tempo estava passando, o desempenho estava se deteriorando, estávamos procurando gargalos. Às vezes, não era fácil, ou seja, otimizar as consultas SQL por disco io, quando descobrimos que o desempenho era baixo devido à falta de RAM. No entanto, não foi suficiente, como solução temporária, migramos do HDD para o SSD. Por um lado, aumentou drasticamente o desempenho, mas, por outro lado, não era uma solução a longo prazo.
Fila de mensagens
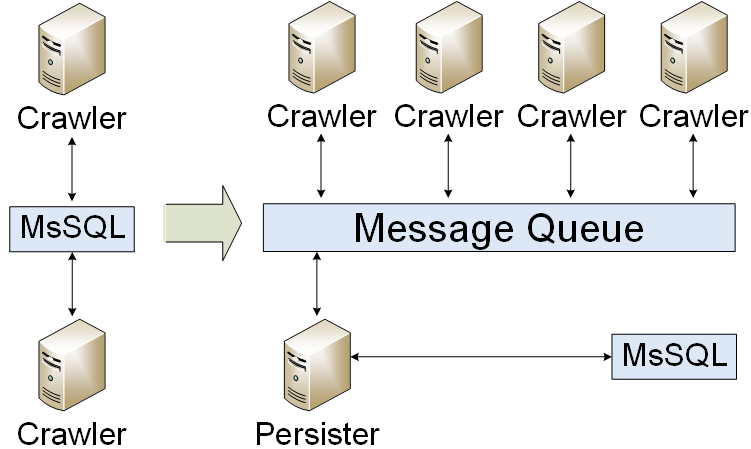
Nosso aplicativo foi migrado para uma fila de mensagens. Estávamos escrevendo apenas resultados no banco de dados. Como resultado, reduzimos a carga do banco de dados. Mas enfrentamos um problema: como organizar um cluster de fila de mensagens? No primeiro, criamos uma espera fria.
WEB

Uma web part consistia em duas partes: conteúdo estático e conteúdo dinâmico do usuário.
WEB estático

A parte estática da WEB da infraestrutura era de cerca de 2 TB, era necessário:
- Armazene imagens.
- Converta imagens.
- Rastrear imagem de origem e cortar, se necessário.

Havia dois problemas principais: como sincronizar arquivos e como criar um cluster da web. Havia algumas maneiras de sincronizar arquivos: comprar um armazenamento, usar o DFS e salvar arquivos em cada servidor. Foi uma decisão difícil, no entanto, decidimos escolher a terceira via. Para o cluster da web, decidimos usar NLB e CDN.
Balanceador WEB

Não é realmente uma boa idéia usar um único servidor para um projeto de alta carga; você precisa equilibrar o tráfego de alguma forma. Havia quatro maneiras no nosso caso:
- Balanceador de hardware - era muito caro para nós.
- IIS e ARR - era muito complicado de suportar.
- Nginx - foi bom o suficiente, no entanto, enfrentamos alguns problemas com exames de saúde.
- Haproxy - era uma solução com a menor sobrecarga.
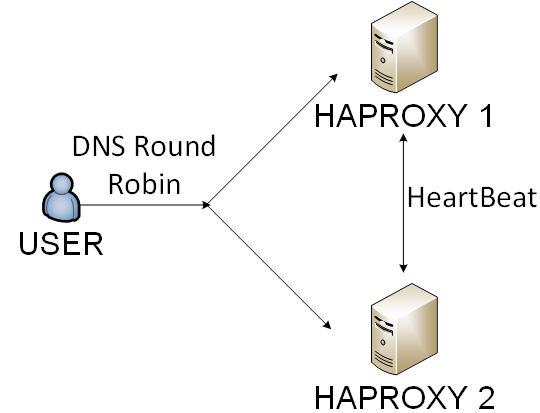
Nós escolhemos o quarto caminho. Estávamos equilibrando haproxy por rodízio de DNS e usuários por cookie.
Mongodb

Alguns meses depois, enfrentamos que o desempenho do SQL não era bom o suficiente novamente. Era uma questão sofisticada, no entanto, após longas conversas, decidimos escolher a tolerância Disponibilidade e Partição no teorema do CAP . Como resultado, implementamos um cluster MongoDB (fragmentação e réplica). Houve uma experiência interessante: como criar backup do MongoDB, como atualizar e muitos bugs do MongoDB.
Backups e monitoramento
Implementamos a regra 3-2-1:
- Pelo menos 3 cópias.
- Pelo menos 2 tipos de armazenamento diferentes.
- Pelo menos 1 cópia deve ser armazenada em algum lugar externo.
Além disso, criamos e testamos o plano de recuperação de desastres. Você pode ler sobre o monitoramento aqui .
Atualizações de aplicativos
Como você pode ver, a infraestrutura não era tão fácil quanto a torta. Tivemos que atualizá-lo de alguma forma. A atualização casual parecia:
- Faça alguma preparação.
- Ran migração.
- Atualize aplicativos da web.
- Atualize aplicativos de back-end.
Todas as etapas lógicas eram idênticas para ambientes de preparação / pré-produção / produção, no entanto, era um pouco diferente nos detalhes. Então, criamos scripts do PowerShell com magia OOP. Foi um processo contínuo de melhoria de nossa infraestrutura de CI / CD.
Conclusão
| 2012 | 2014 |
|---|
| Servidores | 3 | 60 |
| RAM GB | 72 | 800 |
| SSD GB | 200 | 10.000 |
| MsSQL gb | 150 | 700 |
| MongoDB GB | 0 0 | 700 |
| Artigos por dia | 10.000 | 150.000 |
Foi uma história incrível sobre como mover 3 PCs de mesa para uma infraestrutura confiável. Seja paciente e faça planos.
PS