Breve conhecimento do kubernetes para desenvolvedores pelo exemplo de implantação de um site de modelo simples, configuração para monitoramento, execução de trabalhos agendados e verificações de integridade (todos os códigos-fonte estão anexados)
-
Instale o Kubernetes-
Instalar interface do usuário-
Inicie seu aplicativo no cluster-
Adicionando métricas personalizadas ao aplicativo-
Coleta de métricas através do Prometheus-
Exibir métricas no Grafana-
Tarefas agendadas-
tolerância a falhas-
Conclusões-
Notas-
ReferênciasInstale o Kubernetes
não é adequado para usuários linux, você deve usar o minikube- Você tem uma área de trabalho de janela de encaixe
- Nele, você precisa encontrar e ativar o cluster de nó único do Kubernetes
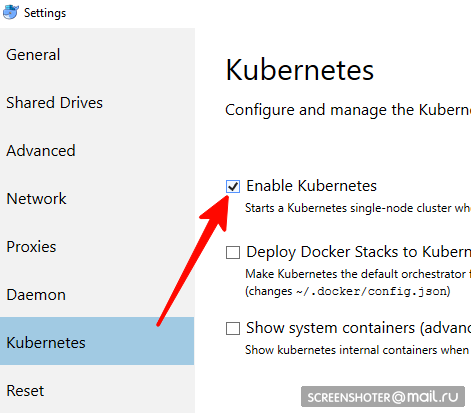
- Agora você tem api http: // localhost: 8001 / para trabalhar com o kubernetis
- A comunicação com ele ocorre através de um utilitário conveniente kubectl
Verifique sua versão com o comando> kubectl version
O mais recente relevante está escrito aqui https://storage.googleapis.com/kubernetes-release/release/stable.txt
Você pode baixá-lo no link apropriado https://storage.googleapis.com/kubernetes-release/release/v1.13.2/bin/windows/amd64/kubectl.exe kubectl cluster-info o cluster está funcionando> kubectl cluster-info
Instalação da interface do usuário
- A interface é implantada no mesmo cluster
kubectl create -f https://raw.githubusercontent.com/kubernetes/dashboard/master/aio/deploy/recommended/kubernetes-dashboard.yaml
- Obtenha um token para acessar a interface
kubectl describe secret
E copiar
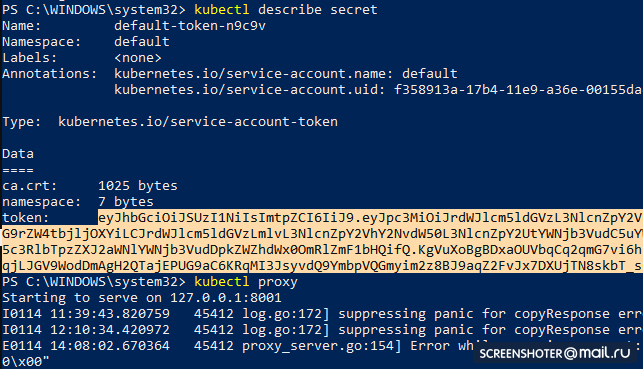
- Agora inicie o proxy
kubectl proxy
- E você pode usar http: // localhost: 8001 / api / v1 / namespaces / kube-system / services / https: kubernetes-dashboard: / proxy /
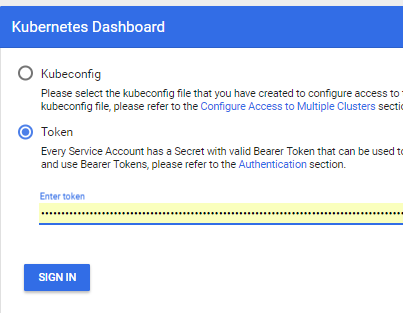
Executando seu Aplicativo em um Cluster
- Criei um aplicativo mvc netcoreapp2.1 padrão no estúdio https://github.com/SanSYS/kuberfirst
- Dockerfile:
FROM microsoft/dotnet:2.1-aspnetcore-runtime AS base WORKDIR /app EXPOSE 80 FROM microsoft/dotnet:2.1-sdk AS build WORKDIR /src COPY ./MetricsDemo.csproj . RUN ls RUN dotnet restore "MetricsDemo.csproj" COPY . . RUN dotnet build "MetricsDemo.csproj" -c Release -o /app FROM build AS publish RUN dotnet publish "MetricsDemo.csproj" -c Release -o /app FROM base AS final WORKDIR /app COPY --from=publish /app . ENTRYPOINT ["dotnet", "MetricsDemo.dll"]
- Reuniu essa coisa com a tag metricsdemo3
docker build -t metricsdemo3 .
- Mas! O Coober, por padrão, puxa imagens do hub, então eu levanto o registro local
- nota - não tentou executar no kubernetis
docker create -p 5000:5000 --restart always --name registry registry:2
- E eu prescrevo isso como inseguro autorizado:
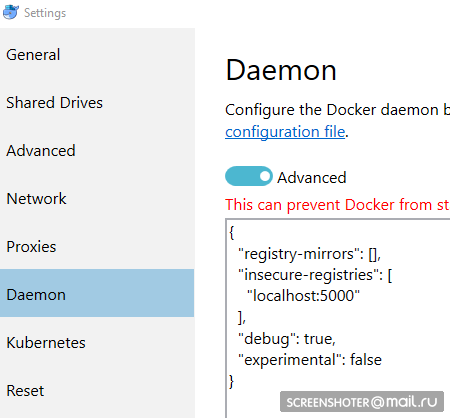
{ "registry-mirrors": [], "insecure-registries": [ "localhost:5000" ], "debug": true, "experimental": false }
- Antes de entrar no registro mais alguns gestos
docker start registry docker tag metricsdemo3 localhost:5000/sansys/metricsdemo3 docker push localhost:5000/sansys/metricsdemo3
- Será algo parecido com isto:

Iniciar via interface do usuário
Se começar, tudo está bem e você pode começar a operar
Crie um arquivo de implantação
1-deployment-app.yaml kind: Deployment apiVersion: apps/v1 metadata: name: metricsdemo labels: app: web spec: replicas: 2
Descrição pequena
- Tipo - indica que tipo de entidade é descrito através do arquivo yaml
- apiVersion - para qual API o objeto é transferido
- etiquetas - essencialmente apenas etiquetas (as teclas à esquerda e os valores podem ser pensados por você)
- seletor - permite associar serviços à implantação, por exemplo, através de rótulos
Seguinte:
kubectl create -f .\1-deployment-app.yaml
E você deve ver sua implantação na interface
http: // localhost: 8001 / api / v1 / namespaces / kube-system / services / https: kubernetes-dashboard: / proxy / #! / Deployment? Namespace = defaultDentro do qual existe um conjunto de réplicas, mostrando que o aplicativo está sendo executado em duas instâncias (Pods) e existe um serviço relacionado com um endereço externo para abrir um aplicativo duplicado no navegador
Adicionando métricas personalizadas ao aplicativo
Adicionado o pacote
https://www.app-metrics.io/ ao aplicativo
Não descreverei em detalhes como os adicionarei, por enquanto brevemente - registro o middleware para aumentar os contadores de chamadas para os métodos api
Aqui está o middleware private static void AutoDiscoverRoutes(HttpContext context) { if (context.Request.Path.Value == "/favicon.ico") return; List<string> keys = new List<string>(); List<string> vals = new List<string>(); var routeData = context.GetRouteData(); if (routeData != null) { keys.AddRange(routeData.Values.Keys); vals.AddRange(routeData.Values.Values.Select(p => p.ToString())); } keys.Add("method"); vals.Add(context.Request.Method); keys.Add("response"); vals.Add(context.Response.StatusCode.ToString()); keys.Add("url"); vals.Add(context.Request.Path.Value); Program.Metrics.Measure.Counter.Increment(new CounterOptions { Name = "api",
E as métricas coletadas estão disponíveis em
http: // localhost: 9376 / metrics
* IMetricRoot ou sua abstração podem ser facilmente registrados nos serviços e utilizados no aplicativo (
services.AddMetrics (Program.Metrics); )
Coleta de métricas através do Prometheus
A configuração mais básica do prometheus: adicione um novo trabalho à sua configuração (prometheus.yml) e alimente-o com um novo destino:
global: scrape_interval: 15s evaluation_interval: 15s rule_files:
Mas o prometheus tem suporte nativo para coletar métricas do kubernetis
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_configQuero monitorar cada serviço, filtrando individualmente por apptype: business label
Tendo se familiarizado com a doca, o trabalho é o seguinte:
- job_name: business-metrics
No kubernetis, há um local especial para armazenar arquivos de configuração -
ConfigMapEu salvo esta configuração lá:
2-prometheus-configmap.yaml apiVersion: v1 kind: ConfigMap
Partida para kubernetis
kubectl create -f .\2-prometheus-configmap.yaml
Agora você precisa implantar o prometheus com este arquivo de configuração
kubectl create -f. \ 3-deployment-prometheus.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: prometheus namespace: default spec: replicas: 1 template: metadata: labels: app: prometheus-server spec: containers: - name: prometheus image: prom/prometheus args: - "--config.file=/etc/config/prometheus.yml" - "--web.enable-lifecycle" ports: - containerPort: 9090 volumeMounts: - name: prometheus-config-volume
Preste atenção - o arquivo prometheus.yml não está especificado em nenhum lugar
Todos os arquivos especificados no mapa de configuração se tornam arquivos na seção prometheus-config-volume, que é montada no diretório / etc / config /
Além disso, o contêiner possui argumentos de inicialização com o caminho para a configuração
--web.enable-lifecycle - diz que você pode puxar o POST / - / recarregar, o que aplicará novas configurações (útil se a configuração mudar "on the fly" e você não desejar reiniciar o contêiner)
Realmente implantar
kubectl create -f .\3-deployment-prometheus.yaml
Siga as pequenas etapas e vá para o endereço
http: // localhost: 9090 / target , você deve ver os pontos finais do seu serviço lá
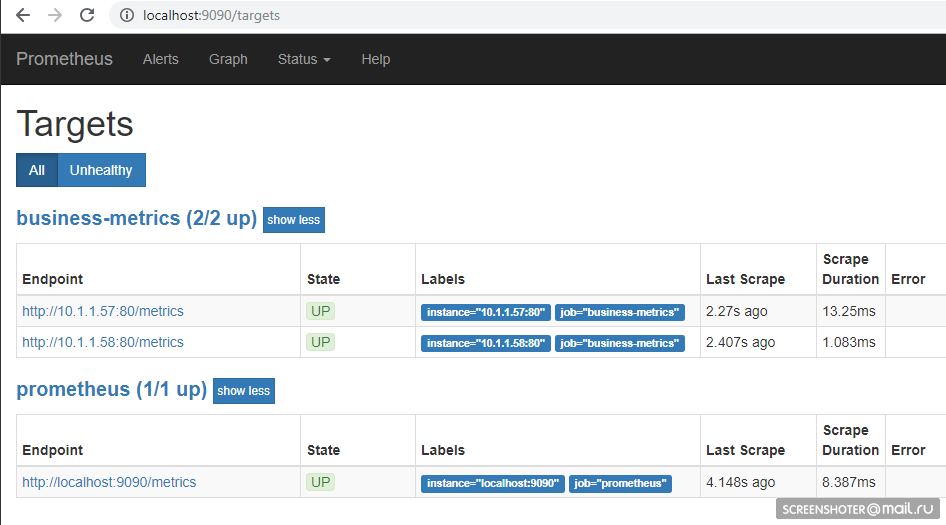
E na página principal você pode escrever pedidos para o prometheus
sum by (response, action, url, app) (delta(application_api[15s]))
Desde que alguém esteja visitando o site, ele ficará assim Idioma de consulta -
https://prometheus.io/docs/prometheus/latest/querying/basics/Exibir métricas no Grafana
Tivemos sorte - até a versão 5, as configurações do painel só podiam ser transferidas pela API HTTP, mas agora você pode fazer o mesmo truque do Prometeus
Por padrão, o Grafana na inicialização
pode exibir
configurações e painéis da fonte de dados
/etc/grafana/provisioning/datasources/ - configs de origem (configurações para acesso ao prometeus, postgres, zabbiks, elastic, etc.)/etc/grafana/provisioning/dashboards/ - configurações de acesso ao /etc/grafana/provisioning/dashboards//var/lib/grafana/dashboards/ - aqui vou armazenar os próprios painéis na forma de arquivos json
Acabou assim apiVersion: v1 kind: ConfigMap metadata: creationTimestamp: null name: grafana-provisioning-datasources namespace: default data: all.yml: | datasources: - name: 'Prometheus' type: 'prometheus' access: 'proxy' org_id: 1 url: 'http://prometheus:9090' is_default: true version: 1 editable: true --- apiVersion: v1 kind: ConfigMap metadata: creationTimestamp: null name: grafana-provisioning-dashboards namespace: default data: all.yml: | apiVersion: 1 providers: - name: 'default' orgId: 1 folder: '' type: file disableDeletion: false updateIntervalSeconds: 10
Implantação em si, nada de novo apiVersion: extensions/v1beta1 kind: Deployment metadata: name: grafana namespace: default labels: app: grafana component: core spec: replicas: 1 template: metadata: labels: app: grafana component: core spec: containers: - image: grafana/grafana name: grafana imagePullPolicy: IfNotPresent resources: limits: cpu: 100m memory: 100Mi requests: cpu: 100m memory: 100Mi env: - name: GF_AUTH_BASIC_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ORG_ROLE value: Admin readinessProbe: httpGet: path: /login port: 3000
Expandir
kubectl create -f .\4-grafana-configmap.yaml kubectl create -f .\5-deployment-grafana.yaml
Lembre-se de que o graphan não sobe imediatamente, é um pouco atenuado pelas migrações sqlite, que você pode
verAgora vá para
http: // localhost: 3000 /E clique no painel
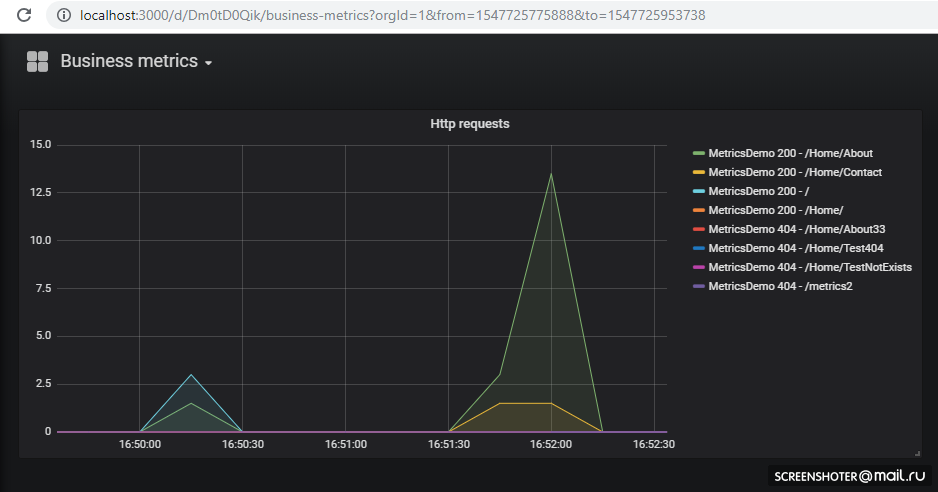
Se você deseja adicionar uma nova visualização ou alterar uma existente - altere-a diretamente na interface e clique em Salvar, você receberá uma janela modal com json, que você precisará colocar no mapa de configuração
Tudo é implantado e funciona muito bem Tarefas agendadas
Para executar tarefas na coroa no cubo, existe o conceito de CronJob
Com o CronJob, você pode definir um agendamento para qualquer tarefa, o exemplo mais simples:
A seção de programação define a regra clássica para a coroa
O gatilho inicia o pod do container (busybox) no qual puxo o método api do serviço metricsdemo
Você pode usar o comando para rastrear o trabalho.
kubectl.exe get cronjob runapijob --watch
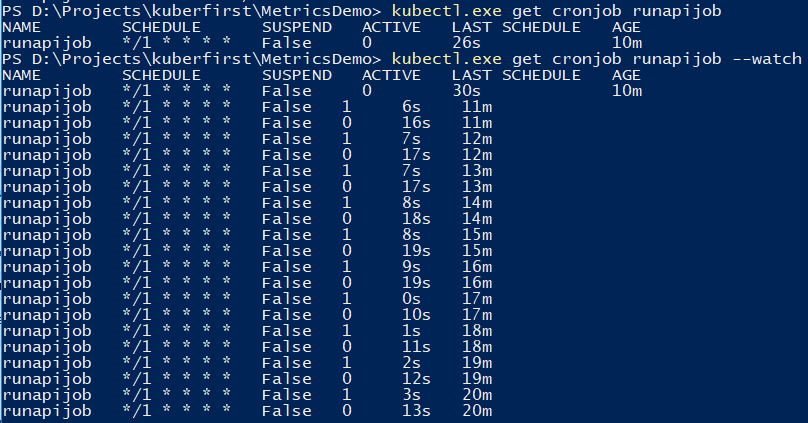
O serviço principal que sai do trabalho é iniciado em várias instâncias, porque a chamada para o serviço vai para um dos lares com uma distribuição aproximadamente uniforme
Para depurar o trabalho, você pode acionar manualmente Uma pequena demonstração no exemplo de cálculo do número de π, sobre a diferença de lançamentos no console
Tolerância a falhas
Se o aplicativo terminar inesperadamente, o cluster reiniciará o pod
Por exemplo, eu criei um método que descarta API
[HttpGet("kill/me")] public async void Kill() { throw new Exception("Selfkill"); }
* A exceção que ocorreu na API no método async void é considerada uma exceção sem tratamento, que trava completamente o aplicativoEu apelo para
http: // localhost: 9376 / api / job / kill / meA lista de lareiras mostra que uma das lareiras do serviço foi reiniciada
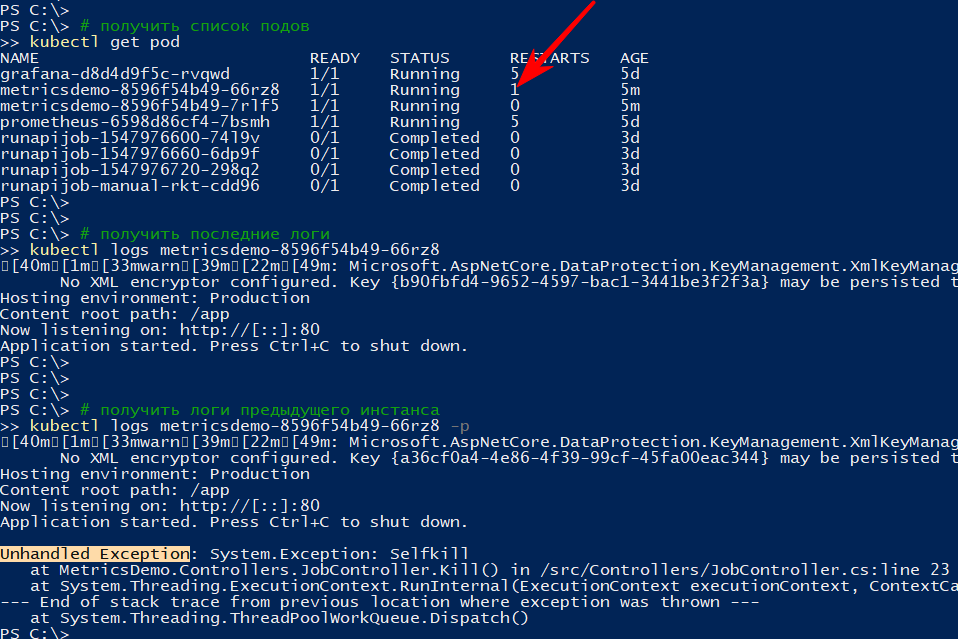
O comando logs exibe a saída atual e, com a opção -p, exibe os logs da instância anterior. Dessa forma, você pode descobrir o motivo da reinicialização.
Eu acho que com uma simples queda tudo fica claro: caiu - rosa
Mas o aplicativo pode ser condicionalmente ativo, ou seja, não caído, mas não fazendo nada, ou fazendo seu trabalho, mas lentamente
De acordo com a
documentação, existem pelo menos dois tipos de verificações de "capacidade de sobrevivência" de aplicativos em pods
- prontidão - esse tipo de verificação é usado para entender se é possível iniciar o tráfego neste pod. Caso contrário, o pod é desregulado até retornar ao normal.
- vivacidade - verifique o aplicativo "quanto à capacidade de sobrevivência". Em particular, se não houver acesso a um recurso vital ou se o aplicativo não responder (por exemplo, deadlock e, portanto, um tempo limite), o contêiner será reiniciado. Todos os códigos http entre 200 e 400 são considerados bem-sucedidos, o restante falha
Vou verificar a reinicialização por tempo limite, para isso adicionarei um novo método api, que de acordo com um determinado comando começará a desacelerar o método de verificação de sobrevivência por 123 s
static bool deadlock; [HttpGet("alive/{cmd}")] public string Kill(string cmd) { if (cmd == "deadlock") { deadlock = true; return "Deadlocked"; } if (deadlock) Thread.Sleep(123 * 1000); return deadlock ? "Deadlocked!!!" : "Alive"; }
Adicionei algumas seções ao arquivo 1-deployment-app.yaml no contêiner:
containers: - name: metricsdemo image: localhost:5000/sansys/metricsdemo3:6 ports: - containerPort: 80 readinessProbe:
Redefinir, tenho certeza de que o aplicativo foi iniciado e se inscreveu em eventos
kubectl get events --watch
Eu pressiono o menu Deadlock me (
http: // localhost: 9376 / api / job / alive / deadlock )

E em cinco segundos começo a observar o problema e sua solução
1s Warning Unhealthy Pod Liveness probe failed: Get http://10.1.0.137:80/api/job/alive/check: net/http: request canceled (Client.Timeout exceeded while awaiting headers) 1s Warning Unhealthy Pod Liveness probe failed: Get http://10.1.0.137:80/api/job/alive/check: net/http: request canceled (Client.Timeout exceeded while awaiting headers) 0s Warning Unhealthy Pod Liveness probe failed: Get http://10.1.0.137:80/api/job/alive/check: net/http: request canceled (Client.Timeout exceeded while awaiting headers) 0s Warning Unhealthy Pod Readiness probe failed: Get http://10.1.0.137:80/health: dial tcp 10.1.0.137:80: connect: connection refused 0s Normal Killing Pod Killing container with id docker://metricsdemo:Container failed liveness probe.. Container will be killed and recreated. 0s Normal Pulled Pod Container image "localhost:5000/sansys/metricsdemo3:6" already present on machine 0s Normal Created Pod Created container 0s Normal Started Pod Started container
Conclusões
- Por um lado, o limite de entrada acabou sendo muito menor do que eu pensava; por outro, não é um cluster de kubernetes real, mas apenas um computador de desenvolvedor. E os limites de recursos, aplicativos com estado, teste a / b etc. não foram considerados.
- O Prometeus tentou pela primeira vez, mas a leitura de vários documentos e exemplos durante a revisão do cubador deixou claro que é muito bom para coletar métricas do cluster e aplicativos
- É tão bom que permite ao desenvolvedor implementar um recurso em seu computador e anexar, além das informações à implantação, a implantação da programação no graphan. Como resultado, novas métricas automaticamente, sem adicionais. esforços começarão a ser exibidos no palco e no prod. Conveniente
Anotações
- Os aplicativos podem entrar em contato entre si pelo
: , que foi o que foi feito com grafana → prometeus. Para aqueles familiarizados com o docker-compose, não há nada de novo kubectl create -f file.yml - cria uma entidadekubectl delete -f file.yml - exclui uma entidadekubectl get pod - obtenha uma lista de todos os lares (serviço, pontos de extremidade ...)--namespace=kube-system - filtrando por espaço de nome-n kube-system - similarmente
kubectl -it exec grafana-d8d4d9f5c-cvnkh -- /bin/bash - anexo na parte inferiorkubectl delete service grafana - exclui um serviço, pod. implantação (--all - excluir tudo)kubectl describe - descreva a entidade (você pode fazer tudo de uma vez)kubectl edit service metricsdemo - edite todos os yamls em tempo real através do lançamento do bloco de notaskubectl --help - grande ajuda)- Um problema típico é que existe um pod (considere a imagem em execução), algo deu errado e não há opções, exceto que não há como depurar dentro (via tcpdump / nc etc.). - Yuzai kubectl-debug habr.com/en/company/flant/blog/436112
Referências
- O que são métricas de aplicativos?
- Kubernetes
- Prometeu
- Configuração grafana pré-preparada
- Para ver como as pessoas se saem (mas já existem algumas coisas desatualizadas) - existem, em princípio, também sobre logs, alertas etc.
- Helm - O gerenciador de pacotes do Kubernetes - através dele era mais fácil organizar o prometeus + grafana, mas manualmente - mais compreensão aparece
- Cubos para Prometeu de Coober
- Histórias de falha do Kubernetes
- Kubernetes-HA. Implantar o cluster de failover do Kubernetes com 5 assistentes
 Código-fonte e atolamentos disponíveis no github
Código-fonte e atolamentos disponíveis no github