Em True Engineering, em um projeto, surgiu a necessidade de alterar a versão do PostgreSQL de 9.6 para 11.1.
Porque O banco de dados no projeto já tem 1,5 Tb de tamanho e está crescendo. O desempenho é um dos principais requisitos do sistema. E a própria estrutura de dados está evoluindo: novas colunas são adicionadas, as existentes são alteradas. A nova versão do Postgres aprendeu a trabalhar eficientemente com a adição de novas colunas com um valor padrão, portanto, não há necessidade de cercar muletas personalizadas no nível do aplicativo. Mesmo na nova versão, várias novas maneiras de particionar tabelas foram adicionadas, o que também é extremamente útil em condições de uma grande quantidade de dados.
Então, está decidido, estamos migrando. Obviamente, você pode criar uma nova versão do servidor PostgreSQL em paralelo com a antiga, interromper o aplicativo, usar dump / restore (ou pg_upgrade) para mover o banco de dados e iniciar o aplicativo novamente. Essa solução não nos convinha, devido ao grande tamanho da base; além disso, o aplicativo funciona no modo de combate, e há apenas alguns minutos para o tempo de inatividade.
Portanto, decidimos tentar a migração usando replicação lógica no PostgreSQL usando um plug-in de terceiros chamado
pglogical .
No processo de "julgamento", encontramos documentação muito fragmentada sobre esse processo (e em russo não é de todo), além de algumas armadilhas e nuances não óbvias. Neste artigo, queremos apresentar nossa experiência na forma de um tutorial.
 TL; DR
TL; DR- Tudo acabou (não sem muletas, um artigo sobre elas).
- Você pode migrar na versão PostgreSQL da 9.4 para a 11.x, de qualquer versão para outra, para baixo ou para cima.
- O tempo de inatividade é igual ao tempo que leva para o seu aplicativo se reconectar ao novo servidor de banco de dados (no nosso caso, foi uma reinicialização de todo o aplicativo, mas no estado selvagem, obviamente, “opções possíveis”).
Por que a solução "testa" não se encaixava em nós
Como já dissemos, a maneira mais fácil é elevar a nova versão do servidor PostgreSQL em paralelo com a antiga, interromper o aplicativo, usar dump / restore (ou pg_upgrade) para mover o banco de dados e iniciar o aplicativo novamente. Para bancos de dados de pequeno volume, em princípio, essa é uma opção bastante adequada (ou, no caso geral, o volume não é importante quando você tem a opção de tempo de inatividade do aplicativo durante o período de "transfusão" do banco de dados do servidor antigo para o novo, não importa quanto tempo seja). Mas, no nosso caso, o banco de dados leva cerca de 1,5 TB no disco, e a movimentação não é questão de minutos, mas de várias horas. O aplicativo, por sua vez, funciona no modo de combate, e eu realmente queria evitar o tempo de inatividade por mais de alguns minutos.
Também contra essa opção foi o fato de usarmos a replicação Master-Slave e não podermos desligar com segurança o servidor Slave do fluxo de trabalho. Portanto, para alternar o aplicativo da versão antiga do PostgreSQL para a nova após a migração do servidor Master, seria necessário preparar um novo servidor Slave antes de iniciar o aplicativo. E são mais algumas horas de inatividade até que o Escravo seja criado (embora muito menos que a migração do Mestre).
Portanto, decidimos tentar a migração usando replicação lógica no PostgreSQL usando um plug-in de terceiros chamado pglogical.
Informação geral
O pglogical é um sistema de replicação lógica que utiliza a decodificação lógica nativa no PostgreSQL e implementada como uma extensão do PostgreSQL. Permite configurar a replicação seletiva usando o modelo de assinatura / publicação. Não requer a criação de gatilhos no banco de dados ou o uso de utilitários externos para replicação.
A extensão funciona em qualquer versão do PostgreSQL, a partir do 9.4 (desde que o Logical Decoding apareceu pela primeira vez no 9.4) e permite migrar entre as versões suportadas do PostgreSQL em qualquer direção.
Configurar manualmente a replicação usando pglogical manualmente não é muito trivial, embora, em princípio, seja bem possível. Felizmente, existe um utilitário
pgrepup de
terceiros para automatizar o processo de configuração, que usaremos.
Memorando de espaço em disco
Como planejamos elevar a nova versão do PostgreSQL nos mesmos servidores em paralelo com a antiga, os requisitos de disco para o banco de dados nos servidores Mestre e Escravo são duplicados. Parece que isso é óbvio, mas ... Apenas cuide de espaço livre suficiente antes de iniciar a replicação para não se arrepender dos anos passados sem rumo.
No nosso caso, foram necessárias modificações no banco de dados, além do formato de armazenamento durante a migração entre 9.6 e 11 "swells", não a favor da versão mais recente; portanto, o espaço em disco teve que ser aumentado não em 2, mas em cerca de 2,2 vezes. Elogie o LVM, isso pode ser feito no processo de migração em tempo real.
Em geral, cuide disso.
Instale o PostgreSQL 11 no Master
Nota: Usamos o Oracle Linux e todos os itens a seguir serão aprimorados para esta distribuição. É possível que outras distribuições Linux exijam uma pequena revisão de um arquivo, mas é improvável que seja significativo.
O datadir antigo está localizado em
/var/lib/pgsql/9.6/data , o novo, portanto, está em
/ var / lib / pgsql / 11 / dataCopie as configurações de acesso (
pg_hba.conf ) e as configurações do servidor (
postgresql.conf ) de 9.6 para 11.
Para executar dois servidores PostgreSQL na mesma máquina, na configuração do
postgresql.conf 11, altere a porta para 15432 (port = 15432).
Aqui você precisa pensar cuidadosamente no que mais você precisa fazer na nova versão do PostgreSQL especificamente no seu caso, para que ele comece com o
postgresql.conf (e seu aplicativo poderá eventualmente funcionar com ele). No nosso caso, foi necessário instalar as extensões do PostgreSQL usadas por nós na nova versão. Isso está além do escopo do artigo, basta fazer o novo PostgreSQL iniciar, funcionar e se adequar a você :)
Examinamos
/ var / lib / pgsql / 11 / data / pg_log / . Está tudo bem? Nós continuamos!
Instale e configure o pgrepup

Nuances:
- Como app_owner, especificamos o usuário sob o qual os servidores PostgreSQL estão em execução.
- Para Banco de Dados, especifique template1 .
- Nome de usuário e senha - dados para acesso de superusuário. No nosso caso, o método trust foi especificado em pg_hba.conf para conexões locais do usuário do postgres , para que você possa especificar uma senha arbitrária.
Configurar replicação
Obtemos a saída de uma lista de muitos parâmetros que devem ser configurados conforme necessário.
Resultados de verificação de exemplo:
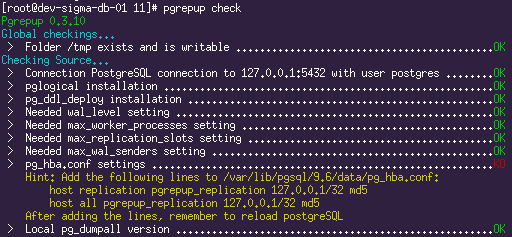

Todos os erros durante a verificação precisarão ser eliminados. Nas configurações de ambos os servidores, deve-se definir
wal_level = LOGICAL (para que a Decodificação lógica funcione), as configurações necessárias para o mecanismo de replicação (número de slots e
wal_senders ). As dicas do utilitário pgrepup são bastante informativas; as perguntas não devem surgir na maioria dos pontos.
Nós fazemos todas as configurações necessárias que o pgrepup solicita.
Nos dois arquivos
pg_hba.conf , adicionamos permissões para o usuário que fará a replicação, tudo no prompt pgrepup:
host replication pgrepup_replication 127.0.0.1/32 md5 host all pgrepup_replication 127.0.0.1/32 md5
Adicionar chaves primárias
Para que a replicação funcione, uma Chave Primária deve ser definida em todas as tabelas.
No nosso caso, o PK não estava em todo lugar; portanto, no momento da replicação, você deve adicioná-lo e, no final da replicação, se necessário, excluí-lo.
Uma lista de tabelas sem PK, entre outras coisas, produz
pgrepup check . Para todas as tabelas desta lista, você precisa adicionar uma chave primária da maneira que melhor lhe convier. No nosso caso, era algo como:
ALTER TABLE %s ADD COLUMN temporary_pk BIGSERIAL NOT NULL PRIMARY KEY
O utilitário pgrepup possui um comando
pgrepup fix para executar esta operação (
pgrepup fix ) e, quando usado, fica implícito que, após uma replicação bem-sucedida, essas colunas temporárias serão excluídas automaticamente. Mas, infelizmente, essa funcionalidade era tão ilusória e encantadora em bugs em bases grandes que decidimos não usá-la, mas fazer essa operação manualmente, pois é conveniente para nós.
Instalar extensão pglogical
Instruções para instalar a extensão podem ser encontradas
aqui . A extensão deve ser instalada nos dois servidores.
Adicione a carga da biblioteca no
postgresql.conf dos dois servidores:
shared_preload_libraries = 'pglogical'
Instale a extensão pgl_ddl_deploy
Essa é uma extensão auxiliar que o pgrepup usa para replicação lógica de DDL.
Adicione a carga da biblioteca no
postgresql.conf dos dois servidores:
shared_preload_libraries = 'pglogical,pgl_ddl_deploy'
Verificando alterações
Agora, usando o
pgrepup check você precisa se certificar de que tudo ficou bem com o servidor de destino e que todos os comentários sobre o servidor de destino foram completamente eliminados.
Se tudo estiver bem, você poderá reiniciar o servidor antigo. Aqui você precisa pensar em como seu aplicativo reagirá à reinicialização do servidor de banco de dados, talvez você deva pará-lo primeiro.
Agora, na saída do comando, todos os itens devem estar marcados como OK.
Parece que você pode iniciar a migração, mas ...
Corrigir erros do pgrepup
Existem vários erros na versão atual do pgrepup que tornam a migração impossível. As solicitações pull foram enviadas, mas, infelizmente, elas são ignoradas; portanto, você precisará fazer correções manualmente.
Vamos para a pasta de instalação do pgrepup (nosso caso é
/usr/lib/python2.7/site-packages/pgrepup/commands/ ).
Faça isso uma vez. Em cada arquivo
* .py , adicione os
**kwargs ausentes na descrição da função. Uma imagem é melhor que mil palavras:
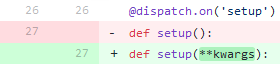
Confirme
aqui .
Faça dois. No
setup.py , fazemos uma busca por “sh -c”, duas entradas, todos os comandos do shell de várias linhas precisam ser feitos de linha única.
Confirme
aqui .
Iniciar a migração
Com este comando, o pgrepup prepara os dois servidores para iniciar a replicação, cria um usuário, configura o pglogical, transfere o esquema do banco de dados.
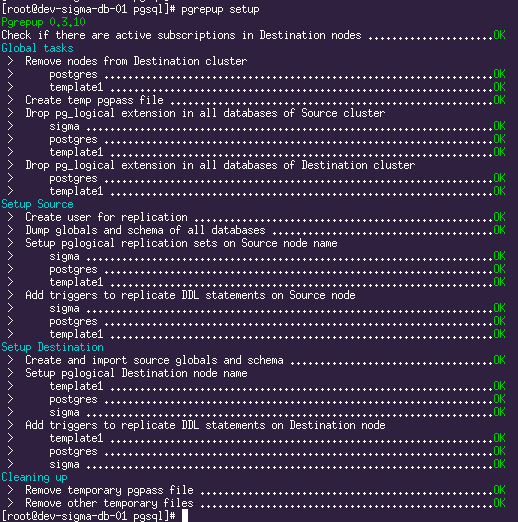
Ele disse: "Vamos!" e acenou com a mão:

A replicação está em execução. A situação atual pode ser vista usando o comando
pgrepup status :
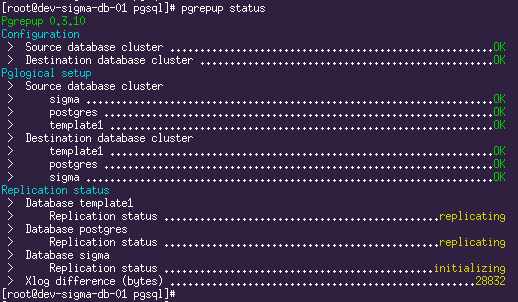
Aqui vemos que dois bancos de dados já foram movidos e a replicação está em andamento, e um ainda está em processo de mudança. Agora resta apenas tomar café e aguardar até que todo o volume do banco de dados original seja bombeado.
Ao longo do caminho, você pode olhar mais fundo na fachada do pgrepup e ver o que acontece sob o capô. Para mentes curiosas, aqui está uma lista de perguntas como ponto de partida:
SELECT * FROM pg_replication_origin_status ORDER BY remote_lsn DESC; SELECT *,pg_xlog_location_diff(s.sent_location,s.replay_location) byte_lag FROM pg_stat_replication s; SELECT query FROM pg_stat_activity WHERE application_name='subscription_copy'
Tendo bastante café (no servidor de teste ao escrever este artigo, a migração de ~ 700Gb de dados durou cerca de um dia), finalmente vemos a seguinte imagem:
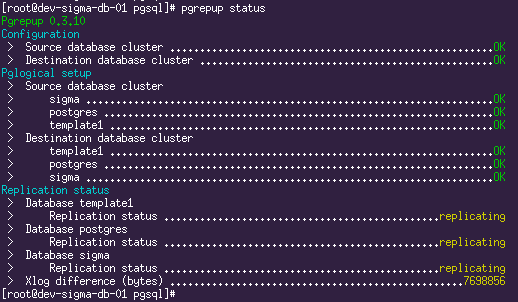
E isso significa que é hora de preparar um novo escravo.
Instale o PostgreSQL 11 no Slave
Aqui tudo é simples e, de acordo com o livro, sem nuances.
Copie as configurações de acesso (
pg_hba.conf ) e as configurações do servidor (
postgresql.conf ) de 9.6 para 11. Na configuração da versão
postgresql.conf 11, altere a porta para 15432 (port = 15432)
# Master SELECT *,pg_wal_lsn_diff(s.sent_lsn,s.replay_lsn) AS byte_lag FROM pg_stat_replication s; # Slave SELECT now()-pg_last_xact_replay_timestamp();
Subtotais
Após todos esses procedimentos, obtemos este esquema de replicação complicado:

Aqui, como uma última verificação (e, no final, é simplesmente bonito), você pode fazer algumas atualizações no banco de dados 9.6 Master e observar como é replicado nos outros três servidores.

Mudando o aplicativo para a nova versão do PostgreSQL
Até agora, nosso aplicativo não suspeitava de nada sobre a nova versão do PostgreSQL, é hora de corrigi-lo. As opções aqui dependem fundamentalmente de apenas duas coisas:
Você superará os novos serviços nas mesmas portas em que os antigos trabalhavam,
e se seu aplicativo requer uma reinicialização ao reiniciar o servidor de banco de dados.
Por diversão, responderemos às duas perguntas “sim” e prosseguiremos.
Paramos a aplicação.
# , , : SELECT * FROM pg_stat_activity;

Retornamos a porta padrão na configuração
postgresql.conf da nova versão para Master e Slave.
No novo escravo, também alteramos a porta para a porta padrão no
recovery.conf .
Ao longo do caminho, há uma sugestão do pecado para alterar ainda mais a porta na versão antiga se tornar inativa:
Nós expomos a porta não padrão no
postgresql.conf da versão antiga para Master e Slave.
No antigo Slave, também alteramos a porta para uma não-padrão no
recovery.conf .
Verifique os logs.
Verifique o status da replicação no mestre.
SELECT *,pg_wal_lsn_diff(s.sent_lsn,s.replay_lsn) AS byte_lag FROM pg_stat_replication s;
Iniciamos o aplicativo. Estamos felizes por meia hora.
E, finalmente, literatura útil sobre o tema:Boa sorte