Em 2016, devido ao sonho de longa data dos videogames e ao "hype" em torno da IA, comecei a aprender Python.
A ciência da computação é divertida porque há apenas uma semana eu treinei o primeiro modelo de reconhecimento, mas sem usar o Python (há muitas tentações na ciência da computação). Como previsto por Andrei Sebrant (Yandex), uma nova revolução tecnológica aconteceu. Porque Facilitando um aplicativo de reconhecimento de imagem que um jogo de computador. O suficiente por uma hora ou duas.

Eu segui o caminho "difícil" - não escolhi entre quatro modelos já treinados, mas treinei o meu. A biblioteca Core ML da Apple permite fazer isso com 6 linhas de código ou através da GUI nos playgrounds.
import CreateMLUI let builder = MLImageClassifierBuilder() builder.showInLiveView()
Passava a maior parte do tempo coletando e filtrando dados para treinamento, 70 fotos de cães, gatos e pessoas, mas um script rapidamente escrito, tornava esse processo semi-automático.
Eu costumava ler sobre aprendizado de máquina. Quando tentei, encontrei três problemas / conclusões esperados:
- Dados são a parte mais importante.
- Interface amigável (CoreML). Tudo simplesmente funciona e eu realmente não quero entrar no código-fonte para descobrir os detalhes. O aprendizado de máquina é acessível a qualquer usuário, mas os engenheiros da Apple tentaram ocultar detalhes complexos.
- O modelo é uma caixa preta. Não conheço as regras pelas quais o modelo acredita que dois por cento do "gato" na fotografia.
O experimento com o reconhecimento de "gatos humanos" levou à idéia de que o algoritmo de classificação lidaria com o "estilo".
Selecionei quatro fotógrafos e cerca de cem fotografias de cada. Não tentei escolher cuidadosamente exemplos, mas simplesmente copiei da minha coleção as primeiras ou últimas cem imagens de
Evgeny Mokhorev e
Oleg Videnin . Não havia fotografias suficientes de
Maxim Shumilin , porque não apenas os retratos foram selecionados. Mas as fotos de
Yegor Voinov foram escolhidas com mais cuidado, pois baixei duas seções dedicadas ao retrato em seu site.
Comecei a treinar o algoritmo e, em média, obtive 80% de precisão no reconhecimento (resultados dos testes durante a criação).
Houve um momento estranho. Dobrei o número de fotos de Oleg Videnin e o sistema aprendeu apenas 30%, e a precisão do reconhecimento diminuiu para 20%.
O sistema teve que ser verificado para, de alguma forma, evitar preconceitos, pedi a Yegor Voinov para enviar fotos que não estão no site. Como resultado, o algoritmo confirmou que 20 das 26 fotos são semelhantes a como Yegor Voinov tira um retrato.
Isso confirmou a precisão de reconhecimento de 77% obtida ao criar o classificador.

E então começa a diversão.
Primeiro, o sistema pode ser treinado adicionando novamente “erros” ao conjunto de treinamento. Os resultados mudam, mas o sistema não se lembra das fotografias, mas encontra sinais comuns para um autor em particular. Algumas fotos depois de “trabalhar com erros” foram reconhecidas pelo sistema como fotos de Yegor Voinov, e outras não.
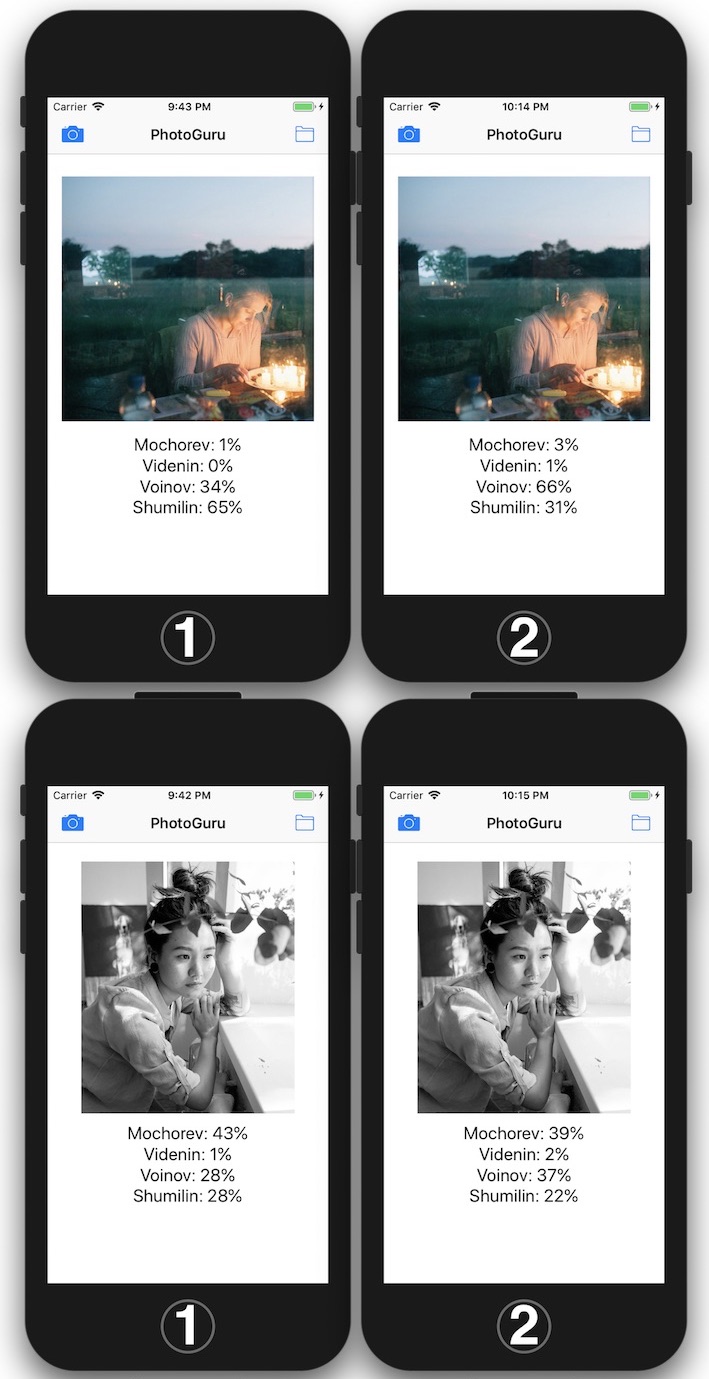
Em segundo lugar, o sistema está inclinado a atribuir o "nu" às fotografias de Yevgeny Mokhorev, portanto ele escreve sob o raro "nu" de Oleg Videnin que essas são fotografias de Mokhorev. E assim que você mostra o "Mokhorev vestido", o sistema pode "ver Voinov". E reconheça a foto de Yegor Voynov como uma foto de Oleg Videnin.

A seleção das fotografias de Maxim Shumilin mostrou-se bastante heterogênea. Portanto, pequenas figuras e retratos com um pronunciado "desfoque" o sistema se refere às fotografias de Maxim.

Em terceiro lugar, o sistema pode dar uma olhada na foto do Mestre Yoda.
E você pode simplesmente tirar uma foto rápida e descobrir em qual "estilo" a foto foi tirada
E aqui está o momento da verdade. Carreguei meus retratos para descobrir o quanto Mokhorev, Videnin, Voinov e Shumilin estão em mim.

O rascunho do aplicativo
PhotoGuru está pronto. Até agora, parece-me que este é um brinquedo divertido, mas vou trabalhar no design e expandir as amostras de treinamento.
Em uma palavra, você precisa escolher uma estrutura para um estudo mais aprofundado da ML.