
Meu nome é Elena Rastorgueva, sou responsável pelo produto Factor da
HFLabs . O Fator é uma empresa algorítmica complexa, que processa dados em escala industrial.
Neste artigo, mostrarei como começamos a testar o “Fator”, como os autotestes foram desenvolvidos e por que chegamos às estruturas auto-escritas.
Que tipo de produto é esse - "Fator"
"Fator" limpa dados em bancos de dados com milhões de clientes: remove erros de digitação no nome, telefone e email, verifica passaportes, faz muito mais. O mais difícil é corrigir os endereços de correspondência.
 Os endereços são escritos de centenas de maneiras, por isso o Fator possui um aparato algorítmico forte sob o capô
Os endereços são escritos de centenas de maneiras, por isso o Fator possui um aparato algorítmico forte sob o capôO "fator" funciona como um serviço: dados de entrada - dados de saída.
Este é um sistema sem estado em que cada chamada é independente das anteriores. O stateless simplifica bastante a vida do testador. É muito mais difícil testar um sistema estável quando uma sequência de ações é importante.
O produto deve ser confiável como o ISS, porque é usado por bancos, operadoras de telefonia móvel, seguros e varejistas do nível Lenta. Respondemos por erros com a cabeça, na medida em que a ausência de erros faz parte do SLA no contrato com o cliente.
Devido aos requisitos de confiabilidade dos autotestes, escrevemos desde o início do desenvolvimento. Um dos critérios para a prontidão da tarefa é "Testes automáticos adicionados".
Iniciado com verificações manuais e autotestes
Lançamos o Fator em 2005 e o testamos com nossas mãos. De manhã, o testador executou autotestes em um arquivo com casos e comparou o resultado do processamento de dados com o resultado do dia anterior: o que mudou após a confirmação do código de ontem.
O processo pode demorar meio dia, esse alinhamento não foi bom. Portanto, fizemos o conjunto mínimo de testes para a funcionalidade principal e agrupados em testes de unidade. Esses testes são rápidos e o próprio desenvolvedor os executou antes de confirmar.
Os testes de unidade são tão convenientes e tão rápidos que adicionamos milhares deles. E então nos deparamos com ele: quando os testes parecem uma folha de milhares de partes de código, não é fácil rolar para o lugar certo. Sem mencionar a adição ou atualização.
 Teste de unidade para verificar o formato SNILS
Teste de unidade para verificar o formato SNILSAlém disso, algo inesperado aparece repentinamente nos dados industriais que não cobrem testes de unidade. Por exemplo, um novo cliente veio com novos recursos nos endereços; os testes de unidade não cobrem esses recursos. Você precisa sentar e ver quais testes adicionar para novos dados. Ainda fizemos isso manualmente.
Crie sua própria estrutura
Nos testes de unidade tradicionais, dados e código são misturados; é difícil encontrar as peças certas.
Portanto, tentamos autotestes no paradigma
Data Driven Testing (DDT) . DDT é quando os dados para teste são armazenados separadamente do código para teste.
Os casos foram carregados a partir de um arquivo excel, nas colunas "Dados brutos" e "Resultado esperado". O DDT foi um avanço: atualizar casos no "exelnik" é inexplicavelmente mais simples.
Pouco a pouco, desenvolvemos uma abordagem e desenvolvemos nossa própria estrutura de teste. Ele recebe arquivos de texto como entrada, dentro deles estão os dados de origem e o resultado esperado.
 Recusamos os arquivos do Excel como armazenamento: os arquivos de texto abrem mais rapidamente, não alteram o conteúdo, é mais fácil coletar dados deles
Recusamos os arquivos do Excel como armazenamento: os arquivos de texto abrem mais rapidamente, não alteram o conteúdo, é mais fácil coletar dados delesA estrutura é ajudada por ferramentas padrão:
- O TeamCity executa testes automaticamente todas as noites;
- testNG compara os resultados esperados e reais.
 Se o resultado for diferente do esperado, no TeamCity o teste fica vermelho. Se tudo estiver como deveria, o teste é verde
Se o resultado for diferente do esperado, no TeamCity o teste fica vermelho. Se tudo estiver como deveria, o teste é verdeModificou a estrutura para si mesmo
12 anos se passaram desde então. Durante esse período, a estrutura ficou repleta de recursos que não estão em soluções padrão.
Contabilizando o status da tarefa no Jira. O HFLabs adere ao
desenvolvimento orientado a
testes : primeiro, escrevemos um teste ou adicionamos casos de teste para um novo comportamento e só então mudamos a funcionalidade.
Desativamos novos casos comentando a linha. Caso contrário, eles primeiro caíram e interferiram, porque os casos adicionavam recursos ou correções antes.
Mas a tarefa pode não ser capaz de concluir o caso de teste correspondente: o erro será extremamente raro ou o cliente trará algo mais importante. Algumas tarefas foram suspensas por meses com baixa prioridade e casos desconectados acumulados. Ao mesmo tempo, não está claro a qual tarefa cada caso pertence, se esse caso pode ser excluído.
Portanto, adicionamos um número de tarefa aos casos desconectados e danificamos um pouco a automação. Agora tudo funciona assim:
- o caso de teste é desativado combinando-o com uma tarefa aberta no Jira;

Para anexar um caso a uma tarefa, escreva na frente # e número da tarefa
- a estrutura executa testes mesmo em casos com deficiência. Mas ignora falhas enquanto a tarefa está aberta em Jira;
- assim que a tarefa é encerrada, o teste começa a cair nos casos anexados a ela. Isso é um sinal: eles passaram na tarefa, mas esqueceram de ligar os casos;
- se de repente o teste para o caso desconectado começar a passar com uma tarefa aberta, a estrutura também informará sobre isso. Talvez seja hora de ativar o caso ou fechar a tarefa anexada (além de atualizar as notas de versão e informar os clientes).

A estrutura diz que o caso desconectado está passando. Talvez alguém tenha corrigido o código como parte de outra tarefa e agora tudo funcione
Então, salvamos o TDD e derrotamos o esquecimento ao gerenciar casos de teste.
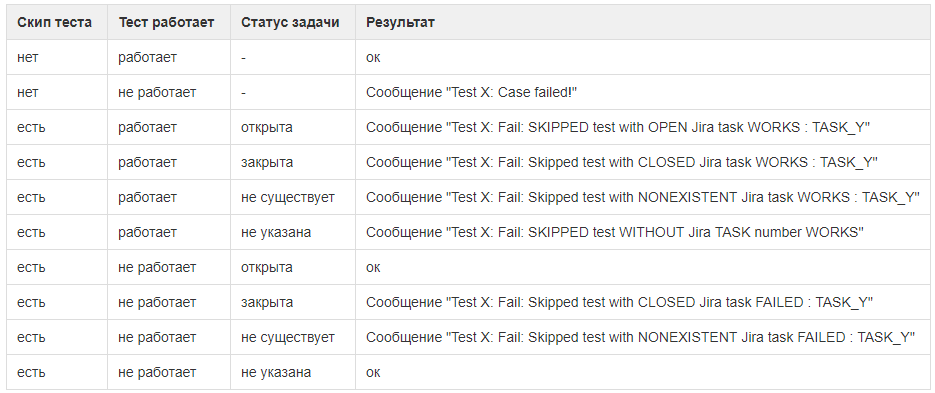 Documentamos todas as opções com o status de casos de teste e tarefas relacionadas, para não esquecerAtualizando casos de teste no modo semiautomático.
Documentamos todas as opções com o status de casos de teste e tarefas relacionadas, para não esquecerAtualizando casos de teste no modo semiautomático. Parece que, se o teste falhar, procure um erro no código. Mas para nós nem sempre é esse o caso. Às vezes acontece que os casos de teste precisam ser atualizados, porque os requisitos para o resultado foram alterados.
Por exemplo, antes que o cliente no endereço limpo desejasse "g. Moscou ”em um campo. Agora ele mudou a arquitetura do banco de dados, ele quer a "cidade" em um campo, "Moscou" em outro. É hora de mudar os casos de teste.
Para o teste finalizado, o TeamCity mostra a diferença entre os resultados esperados e reais. Anteriormente, copiamos essa diferença e atualizamos casos de teste com nossas mãos. Para grandes mudanças - um evento muito caro.
 Um exemplo vivo: ensinamos o “Fator” a determinar um país por número de telefone, os testes no TeamCity caíram. Uma nova referência pode ser obtida do resultado real, mas leva muito tempo
Um exemplo vivo: ensinamos o “Fator” a determinar um país por número de telefone, os testes no TeamCity caíram. Uma nova referência pode ser obtida do resultado real, mas leva muito tempoFizemos com que o framework atualizasse o próprio benchmark. Para fazer isso, após a execução dos testes, ele substitui os resultados de limpeza esperados no padrão pelos resultados reais onde eles não coincidem. O resultado é salvo em artefatos como um arquivo de atualização de caso.
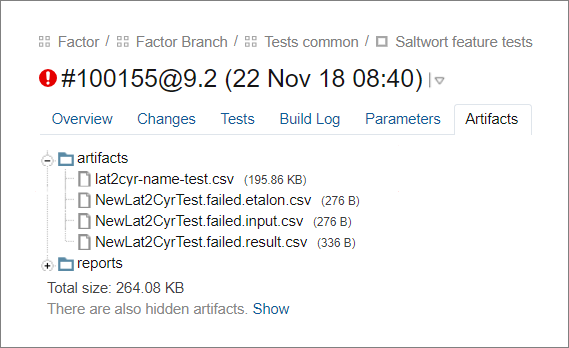 O primeiro arquivo é uma nova referência em que a estrutura atualizou os resultados esperados. Os arquivos restantes são os dados de entrada, o padrão antigo e os dados reais para os casos eliminados.
O primeiro arquivo é uma nova referência em que a estrutura atualizou os resultados esperados. Os arquivos restantes são os dados de entrada, o padrão antigo e os dados reais para os casos eliminados.Com o novo benchmark, o testador atualiza os casos em três etapas.
- Faça o download do arquivo gerado.
- Verifica através de qualquer ferramenta de mesclagem quais mudanças estão no novo benchmark. Deixa apenas o necessário.
- Confirmar
 O testador verifica se as atualizações no novo padrão estão corretas e as confirma
O testador verifica se as atualizações no novo padrão estão corretas e as confirmaSim, se atualizado sem pensar, nada de bom resultará disso. Mas há um risco de atualização imprudente ao trabalhar manualmente.
Estabilização de dados de teste com stubs. "Fator" retorna dados processados em dezenas de campos. Há vários componentes em um único endereço: índice, região, tipo de região, tipo de cidade, cidade, tipo de rua, casa, prédio, prédio, apartamento. Para eles, o “Fator” captura IFTS, OKATO, OKTMO e até as pequenas coisas. Portanto, a partir de uma linha na entrada, dezenas de valores são obtidos.
Nem todos os campos do resultado precisam ser verificados com casos de teste. Por exemplo, o reconhecimento do mesmo endereço depende diretamente do diretório de estado - FIAS. E nele os campos mudam regularmente, pois nossas tarefas são completamente estranhas. A atualização de alguns códigos CLADR para casas eliminou centenas de casos de teste.
Adicionamos stubs ao resultado esperado quando percebemos que estávamos desperdiçando nosso tempo analisando quedas sem importância.
Quando o campo não precisa ser verificado, o testador grava um símbolo no resultado esperado:
$$ DNV $$ . Quando o campo deve ser preenchido, mas o valor em si não é importante:
$$ NE $$ .
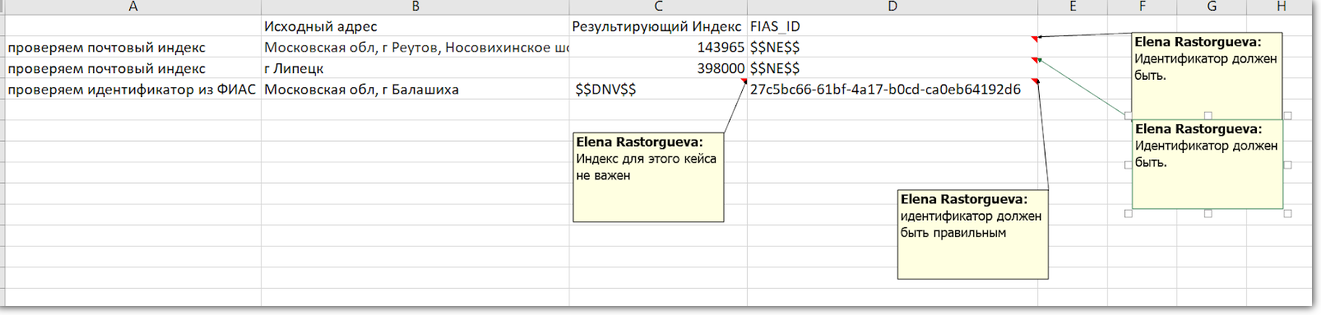 O ID do FIAS está sempre no endereço, portanto, verificamos em todos os testes. Se o campo estiver vazio, algo está errado. Mas o índice pode não ser, portanto, ao verificar o ID do FIAS, ignoramos o índice
O ID do FIAS está sempre no endereço, portanto, verificamos em todos os testes. Se o campo estiver vazio, algo está errado. Mas o índice pode não ser, portanto, ao verificar o ID do FIAS, ignoramos o índiceVocê poderia seguir o outro caminho e separar os testes: cada campo tem o seu. Mas é difícil, porque nem tudo pode ser isolado. Por exemplo, "cidade" e "rua" são partes de um endereço e sem o outro não fazem sentido.
Uma estrutura auto-escrita é mais conveniente
Portanto, não considero absolutamente criar minha própria estrutura uma tarefa estúpida. Se não tivéssemos criado nossa própria ferramenta, não teríamos recebido tantas novas oportunidades e tanta flexibilidade.
Desativar a caixa de texto por status da tarefa, gerar uma nova referência e stubs para o resultado são as coisas que nossos testadores agora estão pedindo em outras estruturas. Se adotássemos soluções padrão, nunca conseguiríamos fazer isso.
Se você gosta de fazer coisas complexas na empresa, venha até nós. Agora , estamos à procura de um desenvolvedor java , salário de 135.000 ₽ sem imposto de renda pessoal.