Continuamos a falar sobre projetos de pesquisa conjuntos entre nossos alunos e a JetBrains Research. Neste artigo, falaremos sobre algoritmos de aprendizado profundo de reforço usados para simular o aparato motor humano.
Simular todos os movimentos humanos possíveis e descrever todos os cenários de comportamento é uma tarefa bastante difícil. Se aprendermos a entender como uma pessoa se move e conseguir reproduzir seus movimentos "à imagem e semelhança" - isso facilitará muito a introdução de robôs em muitas áreas. Apenas para que os robôs aprendam a repetir e analisar os próprios movimentos, e o aprendizado de máquina é aplicado.

Sobre mim
Meu nome é Alexandra Malysheva, sou graduada em Matemática Aplicada e Ciência da Computação na Universidade Acadêmica de São Petersburgo e, desde o outono deste ano, sou estudante do primeiro ano do HSE de São Petersburgo em Programação e Análise de Dados. Além disso, trabalho no laboratório de Sistemas de Agente e Aprendizagem Reforçada da JetBrains Research e também conduzo aulas - palestras e práticas - no programa de graduação do HSE de São Petersburgo.
No momento, estou trabalhando em vários projetos no campo do aprendizado profundo com reforço (começamos a falar sobre o que é isso no artigo anterior). E hoje quero mostrar meu primeiro projeto, que fluiu suavemente da minha tese.
Descrição da tarefa

Para simular o aparato motor humano, são criados ambientes especiais que tentam simular o mundo físico com a maior precisão possível para resolver um problema específico. Por exemplo, a competição do
NIPS 2017 focada na criação de um robô humanóide que simula a caminhada humana.
Para resolver esse problema, geralmente são usados métodos de aprendizado profundo com reforço, que levam a uma estratégia boa, mas não ótima. Além disso, na maioria dos casos, o tempo de treinamento é muito longo.
Como foi corretamente observado no
artigo anterior , o principal problema na transição de tarefas ficcionais / simples para tarefas reais / práticas é que as recompensas nesses problemas são geralmente muito raras. Por exemplo, podemos avaliar a passagem de uma longa distância somente quando o agente alcançou a linha de chegada. Para fazer isso, ele precisa executar uma sequência complexa e correta de ações, o que nem sempre é o caso. Esse problema pode ser resolvido fornecendo ao agente exemplos iniciais de como "tocar" - as chamadas demonstrações especializadas.
Eu usei essa abordagem para resolver esse problema. Acabou por melhorar significativamente a qualidade do treinamento, podemos usar vídeos que mostram os movimentos de uma pessoa durante a execução. Em particular, você pode tentar usar as coordenadas do movimento de partes específicas do corpo (por exemplo, pés) tiradas de um vídeo no YouTube.
O meio ambiente
Nas tarefas de aprendizado por reforço, a interação do agente e do ambiente é considerada. Um dos ambientes modernos para modelar o aparato motor humano é o ambiente de simulação OpenSim usando o mecanismo de física Simbody.
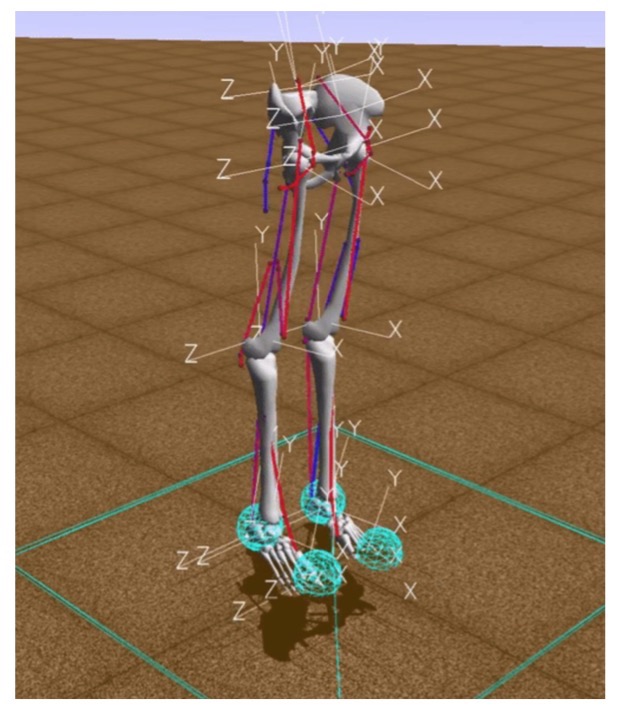
Nesse ambiente, "ambiente" é um mundo tridimensional com obstáculos, "agente" é um robô humanóide com seis articulações (tornozelo, joelhos e quadris nas duas pernas) e músculos que simulam o comportamento muscular humano e "ação do agente" é valores reais de 0 a 1, que especificam a tensão dos músculos existentes.
A recompensa é calculada como a mudança na posição da pelve ao longo do eixo x menos a penalidade pelo uso de ligamentos. Assim, por um lado, você precisa ir o mais longe possível em um determinado período de tempo e, por outro lado, fazer seus músculos trabalharem o mínimo possível. O episódio de treinamento termina se forem obtidas 1000 iterações ou se a altura pélvica estiver abaixo de 0,65 metros, o que significa que o modelo da pessoa cai.
Implementação básica
O principal objetivo do treinamento por reforço é ensinar o robô a se mover de maneira rápida e eficiente no ambiente.
Para testar a hipótese sobre se o treinamento em demonstrações ajuda, era necessário implementar um algoritmo básico que aprendesse a correr rápido, mas abaixo do ideal, como muitos exemplos existentes.
Para fazer isso, aplicamos alguns truques:
- Para começar, foi necessário adaptar o ambiente OpenSim para poder usar efetivamente algoritmos de aprendizado por reforço. Em particular, na descrição do ambiente, adicionamos coordenadas bidimensionais das posições das partes do corpo em relação à pelve.
- O número de exemplos de passagem da distância devido à simetria do meio foi aumentado. Na posição inicial, o agente é absolutamente simétrico em relação aos lados esquerdo e direito do corpo. Portanto, após uma distância, você pode adicionar dois exemplos ao mesmo tempo: o que ocorreu e o espelho simétrico em relação ao lado esquerdo ou direito do corpo do agente.
- Para aumentar a velocidade do algoritmo, os quadros foram ignorados: o algoritmo para selecionar a próxima ação do agente foi iniciado apenas a cada terceira iteração; em outros casos, a última ação selecionada foi repetida. Assim, o número de iterações do lançamento do algoritmo de seleção de ação do agente foi reduzido de 1000 para 333, o que reduziu o número de cálculos necessários.
- As modificações anteriores aceleraram acentuadamente o aprendizado, mas o processo de aprendizado ainda era lento. Portanto, um método de aceleração foi implementado adicionalmente, associado a uma diminuição na precisão dos cálculos: o tipo de valores usados no vetor de estado do agente foi alterado de duplo para flutuante.

Este gráfico mostra a melhoria após cada uma das otimizações descritas acima, mostra a recompensa recebida por uma era a partir do momento do treinamento.
Então, o que o YouTube tem a ver com isso?
Após desenvolver o modelo base, adicionamos geração de recompensa com base na função potencial. Uma função potencial é introduzida para fornecer ao robô informações úteis sobre o mundo ao nosso redor: dizemos que algumas posições corporais que o personagem em execução no vídeo tomou são mais "lucrativas" (ou seja, ele recebe uma recompensa maior por elas) do que outras.
Criamos a função com base nos dados de vídeo retirados dos vídeos do YouTube, representando a execução de pessoas reais e personagens humanos de desenhos animados e jogos de computador. A função potencial total foi definida como a soma das funções potenciais de cada parte do corpo: a pelve, dois joelhos e dois pés. Seguindo a abordagem baseada em potencial para a formação de remuneração, a cada iteração do algoritmo, o agente recebe uma remuneração adicional correspondente a uma mudança nos potenciais do estado anterior e atual. As funções potenciais de partes individuais do corpo foram construídas usando as distâncias inversas entre a coordenada correspondente da parte do corpo nos dados gerados por vídeo e o robô humanóide.
Examinamos três fontes de dados:
 Becker Alan. Animação de ciclos de caminhada - 2010
Becker Alan. Animação de ciclos de caminhada - 2010 ProcrastinatorPro. QWOP Speedrun - 2010
ProcrastinatorPro. QWOP Speedrun - 2010 ShvetsovLeonid.HumanSpeedrun - 2015
ShvetsovLeonid.HumanSpeedrun - 2015... e três funções diferentes de distância:
Aqui dx (dy) é a diferença absoluta entre a coordenada x (y) das partes do corpo correspondentes retiradas dos dados de vídeo e a coordenada x (y) do agente.
A seguir, os resultados obtidos comparando várias fontes de dados para uma função potencial com base no PF2:

Resultados
Comparação da produtividade entre o nível base e a abordagem para a formação da remuneração:

Verificou-se que a formação da remuneração acelera significativamente o aprendizado, atingindo velocidade dupla em 12 horas de treinamento. O resultado final após 24 horas ainda mostra uma vantagem significativa da abordagem usando o método de funções potenciais.
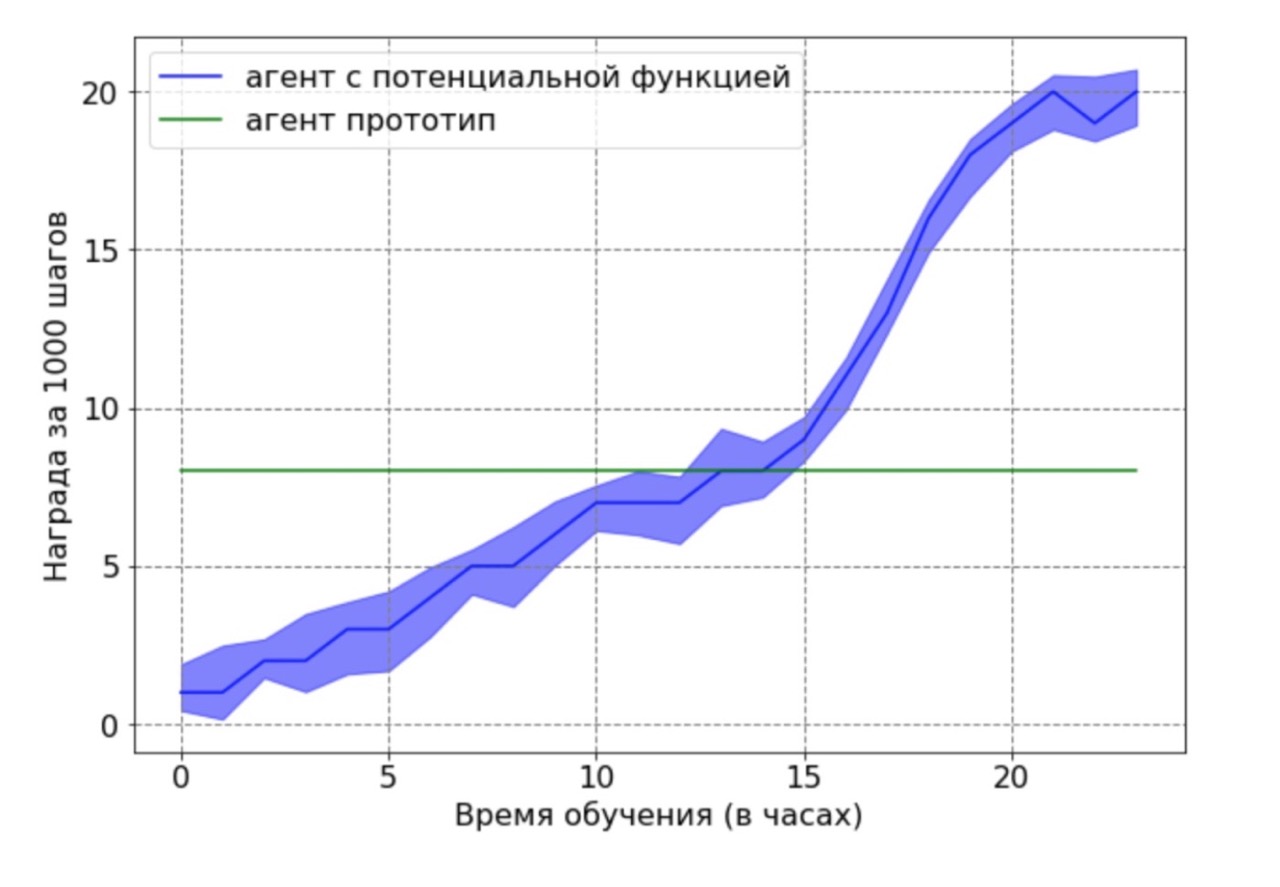
Separadamente, quero observar o seguinte resultado importante: fomos capazes de provar teoricamente que a remuneração baseada em uma função potencial não piora uma política ideal. Para demonstrar essa vantagem nesse contexto, usamos um agente subótimo gerado pelo agente base após 12 horas de treinamento. O agente protótipo resultante foi usado como fonte de dados para uma função potencial. Obviamente, o agente obtido com esta abordagem não funcionará da melhor maneira possível, e as posições dos pés e joelhos na maioria dos casos não estarão em ótimas posições. Em seguida, o agente treinado pelo algoritmo DDPG, usando a função potencial, foi treinado nos dados obtidos. Em seguida, foi feita uma comparação dos resultados de aprendizagem de um agente com uma função potencial com um agente protótipo. O agendamento de treinamento do agente demonstra que o agente RL é capaz de superar o desempenho abaixo do ideal da fonte de dados.
Primeiros passos na ciência
Terminei o projeto de graduação bem cedo. Gostaria de observar que temos uma abordagem muito responsável para proteger um diploma. Desde setembro, os alunos conhecem o tópico, critérios de avaliação, o que e quando fazer. Quando tudo está tão claro, é muito conveniente trabalhar, não há a sensação de que "tenho um ano inteiro pela frente, posso começar a trabalhar na próxima semana / mês / seis meses". Como resultado, se você trabalhar com eficiência, poderá obter os resultados finais da tese até o Ano Novo e gastar o tempo restante na criação do modelo, coletando resultados estatisticamente significativos e escrevendo o texto do diploma. Foi exatamente o que aconteceu comigo.
Dois meses antes da defesa do diploma, eu já tinha o texto do trabalho pronto e meu consultor científico, Aleksey Aleksandrovich Shpilman, sugeriu a redação de um artigo no
Workshop sobre Agentes Adaptativos e de Aprendizagem (ALA) no ICML-AAMAS. A única coisa que eu precisava fazer era traduzir e reembalar minha tese. Como resultado, enviamos um artigo para a conferência e ... foi aceito! Esta foi a minha primeira publicação e fiquei extremamente feliz quando vi uma carta com a palavra "Aceito" no meu e-mail. Infelizmente, ao mesmo tempo, treinei na Coréia do Sul e não pude comparecer pessoalmente à conferência.
Além de
publicar e reconhecer o trabalho realizado, a primeira conferência me trouxe outro resultado agradável. Alexey Alexandrovich começou a me atrair para escrever uma resenha do trabalho de outras pessoas. Parece-me que isso é muito útil para ganhar experiência na avaliação de novas idéias: dessa forma, você pode aprender a analisar o trabalho existente, verificar a ideia quanto à originalidade e relevância.
Escrever um artigo sobre workshop é bom, mas na pista principal é melhor
Depois da Coréia, eu estagiei na JetBrains Research e continuei trabalhando no projeto. Foi nesse ponto que testamos três fórmulas diferentes para uma função potencial e fizemos uma comparação. Queríamos realmente compartilhar os resultados do nosso trabalho, por isso decidimos escrever um artigo completo na
conferência principal da
ICARCV em Cingapura.
Escrever um artigo em uma oficina é bom, mas na faixa principal é melhor. E, é claro, fiquei muito feliz ao saber que o artigo foi aceito! Além disso, nossos colegas e patrocinadores da JetBrains concordaram em pagar pela minha viagem à conferência. Um grande bônus foi a oportunidade de se familiarizar com Cingapura.
Quando os ingressos já foram comprados, o hotel foi reservado e eu só podia obter um visto, recebi uma carta pelo correio:

Eu não recebi um visto, apesar de ter documentos confirmando meu discurso na conferência! Acontece que a Embaixada de Cingapura não aceita solicitações de meninas solteiras e desempregadas com menos de 35 anos de idade. E mesmo se a menina trabalha, mas não é casada, a chance de obter uma recusa ainda é muito grande.
Felizmente, aprendi que os cidadãos da Federação Russa que viajam em trânsito podem ficar em Cingapura por até 96 horas. Como resultado, voei para a Malásia via Singapura, onde passei quase oito dias no total. A conferência durou seis dias. Devido a restrições, participei dos quatro primeiros e tive que sair para voltar para fechar. Após a conferência, decidi me sentir um turista e apenas andei pela cidade por dois dias e visitei museus.
Eu preparei um discurso com antecedência no ICARCV, em São Petersburgo. Ensaiou-o em uma oficina de treinamento de reforço. Portanto, falar na conferência foi emocionante, mas não assustador. A apresentação durou 15 minutos, mas depois havia uma seção de perguntas que me pareceu muito útil.
Fiz algumas perguntas bastante interessantes que suscitaram novas idéias. Por exemplo, sobre como marcamos os dados. Em nosso trabalho, marcamos os dados manualmente e nos foi oferecido o uso de uma biblioteca que entende automaticamente onde estão as partes do corpo humano. Agora, começamos a implementar essa ideia. Você pode ler todo o trabalho
aqui .
No ICARCV, gostei de me comunicar com cientistas e aprendi muitas novas idéias. O número de artigos interessantes que conheci nesses poucos dias foi mais do que nos quatro anos anteriores. Agora, existe um "hype" para o aprendizado de máquina no mundo, e todos os dias dezenas de novos artigos aparecem na Internet, entre os quais é muito difícil encontrar algo que valha a pena. Parece-me que vale a pena ir a conferências: encontrar comunidades que discutam novos tópicos interessantes, aprender novas idéias e compartilhar suas próprias. E faça amigos!