Olá Meu nome é Ivan Davydov, estou envolvido em pesquisa de desempenho no Yandex.Money.
Imagine que você possui servidores poderosos, cada um dos quais hospeda vários aplicativos. Se não há muitos deles, eles não interferem no trabalho um do outro - são confortáveis e acolhedores. Quando você chega aos microsserviços e retira parte da funcionalidade "pesada" em aplicativos separados.
Aqui você pode se deixar levar e haverá muitos microsserviços, como resultado, será difícil gerenciá-los e garantir a tolerância a falhas. Como resultado, uma dúzia de aplicativos que lutam por recursos compartilhados será "empacotada" em cada servidor. Será uma "grande família", mas em uma grande família não clique com o bico!
Uma vez também enfrentamos isso. Minha história será sobre noites pesadas e sem dormir, quando eu me sentei sob uma lâmpada durante a noite e atirei no golpe. Tudo começou com o fato de começarmos a perceber problemas de rede nos servidores de batalha.
Eles influenciaram muito o desempenho e fizeram rebaixamentos significativos. Ao mesmo tempo, verificou-se que os mesmos erros ocorrem com um fluxo de usuário comum, mas em uma extensão muito menor.
O problema estava na utilização de soquetes TCP em mais de 100%. Isso acontece quando todos os soquetes nos servidores estão constantemente abrindo e fechando. Por esse motivo, existem problemas de interação na rede entre aplicativos e vários tipos de erros aparecem - o host remoto não está disponível, a conexão HTTP / HTTPS (tempo limite de conexão / leitura, tempo limite de SSL desligado incorretamente) e outros.
Mesmo se você não tiver seu próprio serviço de pagamento eletrônico, não é muito difícil avaliar a extensão da dor durante uma venda regular - o tráfego aumenta várias vezes e a degradação do desempenho pode levar a perdas significativas. Então, chegamos a duas conclusões - precisamos avaliar como as capacidades atuais são usadas e isolar as aplicações umas das outras.
Para isolar aplicativos, decidimos recorrer à conteinerização. Para fazer isso, usamos um hypervisor que contém muitos contêineres separados com aplicativos. Isso permite isolar os recursos do processador, memória, dispositivos de entrada / saída, redes, bem como árvores de processo, usuários, sistemas de arquivos e assim por diante.
Com essa abordagem, cada aplicativo tem seu próprio ambiente, que fornece flexibilidade, isolamento, confiabilidade e melhora o desempenho geral do sistema. Esta é uma solução bonita e elegante, mas antes disso você precisa responder a uma série de perguntas:
- Qual margem de desempenho uma instância de aplicativo possui atualmente?
- Como o aplicativo é dimensionado e há redundância de recursos na configuração atual?
- É possível melhorar o desempenho de uma instância e qual é o gargalo?
Com essas perguntas, os colegas vieram até nós - uma equipe de pesquisadores de desempenho.
O que estamos fazendo?
Fazemos tudo para garantir o desempenho do nosso serviço e, antes de tudo, pesquisamos e aprimoramos os processos de negócios de nossa produção. Cada processo comercial, seja pagando por mercadorias em uma loja com carteira ou transferindo dinheiro entre usuários, em essência, representa para nós uma cadeia de solicitações no sistema.
Realizamos experimentos e preparamos relatórios para avaliar o desempenho do sistema com alta intensidade de solicitações recebidas. Os relatórios contêm métricas de desempenho e uma descrição detalhada dos problemas e gargalos identificados. Com a ajuda dessas informações, melhoramos e otimizamos nosso sistema.
A avaliação do potencial de cada aplicativo é complicada pelo fato de que vários microsserviços que usam o poder de todas as instâncias envolvidas participam da organização da sequência de solicitações de processos de negócios.
Metaforicamente falando, conhecemos o poder do nosso exército, mas não sabemos o potencial de cada um dos combatentes. Portanto, além das pesquisas em andamento, é necessário avaliar os recursos utilizados como parte do processo de gerenciamento de capacidade. Esse processo é chamado de Gerenciamento de capacidade.
Nossa pesquisa ajuda a identificar e prevenir a falta de recursos, prever compras de ferro e ter dados precisos sobre as capacidades atuais e potenciais do sistema. Como parte desse processo, o desempenho real do aplicativo (mediano e máximo) é monitorado e são fornecidos dados sobre o estoque atual.
A essência do gerenciamento de capacidade é encontrar um equilíbrio entre recursos consumidos e produtividade.
Prós:
- A qualquer momento, sabe-se o que acontece com o desempenho de cada aplicativo.
- Menos risco ao adicionar novos microsserviços.
- Custos mais baixos na compra de novos equipamentos.
- Essas capacidades que já existem são usadas de maneira mais inteligente.
Como o gerenciamento de capacidade funciona
Vamos voltar à nossa situação com muitos aplicativos. Realizamos um estudo cujo objetivo era avaliar como as capacidades são usadas nos servidores de produção.
Em resumo, o plano de ação é o seguinte:
- Defina a intensidade do usuário em aplicativos específicos.
- Faça um perfil de filmagem.
- Avalie o desempenho de cada instância do aplicativo.
- Escalabilidade de taxa.
- Compile relatórios e conclusões sobre o número mínimo necessário de instâncias para cada aplicativo em um ambiente de combate.
E agora com mais detalhes.
As ferramentas
Usamos Heka e Zabbix para coletar métricas de intensidade personalizadas. O Grafana é usado para visualizar as métricas coletadas.
O Zabbix é necessário para monitorar os recursos do servidor, como: CPU, Memória, Conexões de rede, DB e outros. A Heka fornece dados sobre o número e o tempo de execução das solicitações de entrada / saída, coleta de métricas nas filas internas de aplicativos e uma quantidade interminável de outros dados. O Grafana é uma ferramenta de visualização flexível usada por diferentes equipes do Yandex.Money. Nós não somos exceção.
A Grafana pode mostrar, por exemplo, essas coisas
O Apache JMeter é usado como um gerador de tráfego. Com sua ajuda, é compilado um cenário de filmagem, que inclui a implementação de solicitações, monitorando a validade da resposta, controle flexível do fluxo de feed e muito mais. Essa ferramenta tem seus prós e contras, mas para aprofundar "por que esse produto em particular?" Eu não vou.
Além do JMeter, a estrutura do yandex-tank é usada - uma ferramenta para teste de estresse e análise do desempenho de serviços e aplicativos da web. Permite conectar seus módulos para obter as funções desejadas e exibir os resultados no console ou na forma de gráficos. Os resultados de nossos disparos são exibidos no Lunapark (análogo a https://overload.yandex.net ), onde podemos observá-los em detalhes em tempo real, até segundos segundos, fornecendo a discrição necessária e suficiente e, assim, responder mais rapidamente às explosões, decorrentes do disparo. No graphane, também é possível ajustar a discrição, mas essa solução é mais cara em termos de recursos físicos e lógicos. E, às vezes, até carregamos dados brutos e os visualizamos através do Jmeter da GUI. Mas apenas - shhh!
Falando em degradação. Quase todas as falhas que ocorrem no aplicativo com um grande fluxo de tráfego são analisadas rapidamente usando o Kibana . Mas isso também não é uma panacéia - alguns problemas de rede podem ser analisados apenas removendo e analisando o tráfego.
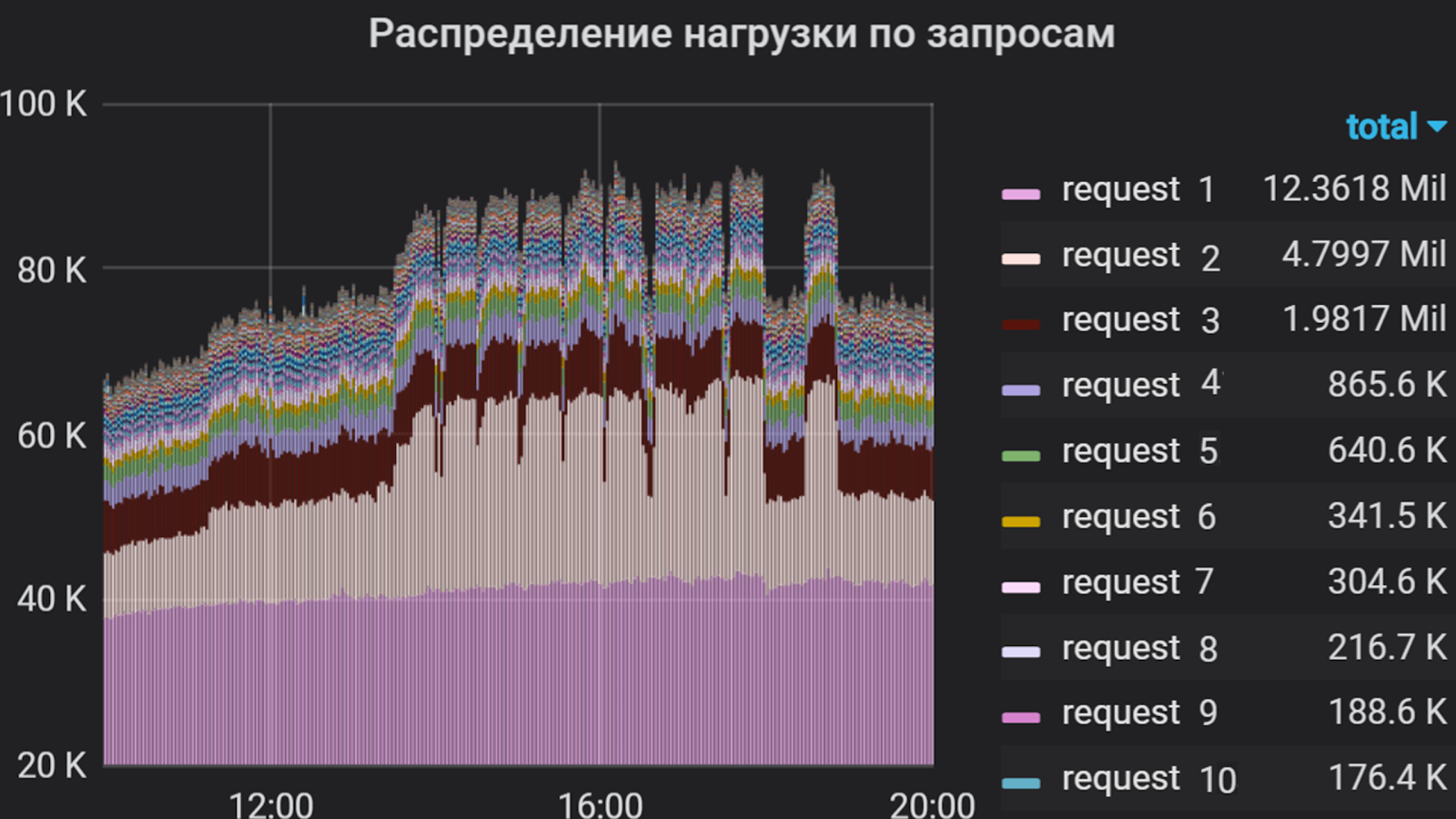
Usando o Grafana, analisamos a intensidade do usuário no aplicativo por vários meses. Decidimos levar o tempo total do processador para executar solicitações como uma unidade de medida, ou seja, o número de solicitações e o tempo de sua execução foram levados em consideração. Por isso, compilamos uma lista das solicitações mais "pesadas", que compõem a maior parte do fluxo para o aplicativo. Foi essa lista que formou a base do perfil de filmagem.

Intensidade do usuário por aplicativo por vários meses
Perfil de tiro e mira
Chamamos de disparar um lançamento de script como parte de um experimento. O perfil é composto de duas partes.
A primeira parte é escrever um script de consulta. Durante a implementação, é necessário analisar a intensidade do usuário para cada solicitação de aplicativo recebida e estabelecer uma proporção percentual entre eles para identificar as principais chamadas de mais longa duração. A segunda parte é a seleção dos parâmetros de crescimento do fluxo: com que intensidade e por quanto tempo carregar.
Para maior clareza, a metodologia para compilar um perfil é melhor demonstrada pelo exemplo.
A Grafana cria um gráfico que reflete a intensidade do usuário e o compartilhamento de cada solicitação no fluxo total. Com base nesta distribuição e tempo de resposta para cada solicitação, grupos são criados no JMeter, cada um dos quais é um gerador de tráfego independente. O cenário baseia-se apenas nas solicitações mais "pesadas", pois é difícil implementar tudo (em algumas aplicações há mais de cem), e isso nem sempre é necessário devido à sua intensidade relativamente baixa.

Porcentagem de consultas
Este estudo examina a intensidade do usuário em um fluxo constante, e as "explosões" periódicas são mais frequentemente consideradas em particular.
No nosso exemplo, dois grupos são considerados. O primeiro grupo incluiu “solicitação 1” e “solicitação 2” na proporção de 1 para 2. Da mesma forma, o segundo grupo incluiu solicitações 3 e 4. As solicitações restantes para o componente são muito menos intensas, portanto, não as incluímos no script.

Agrupando consultas no Jmeter
Com base no tempo médio de resposta de cada grupo, o desempenho é estimado pela fórmula:
x = 1000 / t, em que t é o tempo médio, ms
Obtemos o resultado do cálculo e estimamos a intensidade aproximada com o aumento do número de threads:
TPS = x * p, onde p é o número de encadeamentos, TPS é a transação por segundo ex é o resultado do cálculo anterior.
Se a solicitação for processada em 500 ms, em um fluxo teremos 2 Tps e, com 100 threads, o ideal é ter 200 Tps. Com base nos resultados obtidos, os parâmetros de crescimento inicial podem ser selecionados. Após a primeira iteração da pesquisa, esses parâmetros geralmente são ajustados.
Quando o cenário de gravação estiver pronto, iniciaremos a filmagem - por um minuto em um fluxo. Isso é feito para verificar a operacionalidade do script com um fluxo constante, avaliar o tempo de resposta às solicitações em cada grupo e obter uma taxa percentual de solicitações.
Ao executar esse perfil, descobrimos que, na mesma intensidade, a porcentagem de solicitações é preservada, pois o tempo médio de resposta no segundo grupo é maior que no primeiro. Portanto, definimos a mesma vazão para os dois grupos. Em outros casos, seria necessário selecionar experimentalmente os parâmetros para cada grupo separadamente.
Neste exemplo, a intensidade foi aplicada gradualmente, ou seja, um certo número de fluxos foi adicionado ao longo de um determinado intervalo.

Opções de crescimento de intensidade
Os parâmetros de intensidade de crescimento foram os seguintes:
- O número alvo de threads é 100 (determinado durante a observação).
- Crescimento por 1000 segundos (~ 16 min.).
- 100 passos.
Assim, a cada 10 segundos, adicionamos um fluxo. O intervalo entre a adição de threads e o número de threads adicionados varia dependendo do comportamento do sistema em uma etapa específica. Freqüentemente, a intensidade é fornecida com um crescimento suave, para que você possa acompanhar o status do sistema em cada estágio.
Disparo
Normalmente, o disparo começa à noite a partir de servidores remotos. No momento, o tráfego do usuário é mínimo - isso significa que o disparo dificilmente afetará os usuários e o erro nos resultados será menor.
De acordo com os resultados do primeiro disparo em um exemplo, ajustamos o número de threads e o tempo de crescimento, analisamos o comportamento do sistema como um todo e descobrimos desvios no trabalho. Após todos os ajustes, o disparo repetido em uma instância é iniciado. Nesta fase, determinamos o desempenho máximo e monitoramos o uso de recursos de hardware do servidor com o aplicativo e tudo o que está por trás dele.
De acordo com os resultados das filmagens, o desempenho de uma instância de nosso aplicativo foi de cerca de 1000 Tps. Ao mesmo tempo, um aumento no tempo de resposta para todas as solicitações foi registrado sem aumentar a produtividade, ou seja, alcançamos a saturação, mas não a degradação.
No próximo estágio, comparamos os resultados obtidos de outras instâncias. Isso é importante, pois o hardware pode ser diferente, o que significa que instâncias diferentes podem fornecer indicadores muito diferentes. O mesmo aconteceu conosco - alguns dos servidores se mostraram em uma ordem de magnitude mais produtiva devido à geração e às características. Portanto, identificamos um grupo de servidores com os melhores resultados e investigamos a escalabilidade neles.
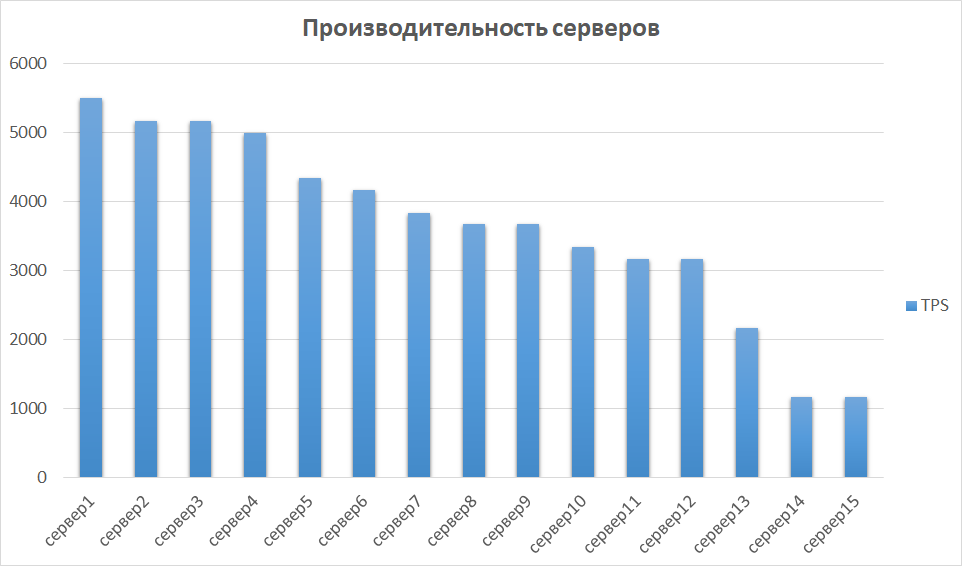
Comparação de desempenho do servidor
Escalabilidade e gargalo
A próxima etapa é investigar o desempenho nas instâncias 2, 3 e 4. Em teoria, o desempenho deve crescer linearmente com o aumento do número de instâncias. Na prática, esse geralmente não é o caso.
No nosso exemplo, acabou sendo uma opção quase perfeita.

O motivo para saturar o crescimento da produtividade foi o esgotamento dos conjuntos de conectores antes do back-end subsequente. Isso é resolvido através do controle do tamanho dos pools no lado de saída e de entrada e leva a um aumento no desempenho do aplicativo.
Em outros estudos, descobrimos coisas mais interessantes. Experimentos mostraram que, juntamente com o desempenho, a utilização de conexões de CPU e banco de dados está crescendo rapidamente. No nosso caso, isso aconteceu porque, na configuração com uma instância, encontramos nossas próprias configurações para pools de aplicativos e, com duas instâncias, dobramos esse número, dobrando o fluxo de saída. O banco de dados não estava pronto para esse volume. Por esse motivo, os pools do banco de dados começaram a ficar obstruídos, a porcentagem de CPU consumida atingiu uma marca crítica de 99%, o tempo de processamento das solicitações aumentou e parte do tráfego caiu completamente. E já obtivemos esses resultados em duas instâncias!
Para finalmente nos convencer dos nossos medos, disparamos em 3 instâncias. Os resultados foram aproximadamente os mesmos dos dois primeiros, exceto que eles rapidamente chegaram a um distúrbio.
Há outro exemplo de "plugs", que, na minha opinião, é o mais doloroso - esse é um código mal escrito. Pode haver o que você quiser, começando com consultas ao banco de dados que são executadas em minutos, terminando com código que aloca incorretamente a memória de uma máquina Java.
Sumário
Como resultado, a margem do aplicativo investigada em nosso aplicativo de exemplo tem uma margem de desempenho superior a 5 vezes.
Para aumentar a produtividade, é necessário calcular um número suficiente de conjuntos de processadores nas configurações do aplicativo. Duas instâncias para um aplicativo específico são suficientes e o uso de todas as 15 disponíveis é redundante.
Após o estudo, foram obtidos os seguintes resultados:
- A intensidade do usuário por 1 mês foi determinada e monitorada.
- A margem de desempenho de uma instância do aplicativo foi identificada.
- Os resultados são obtidos sobre erros que ocorrem em um fluxo grande.
- Foram identificados gargalos para mais trabalhos sobre o aumento da produtividade.
- O número mínimo suficiente de instâncias para a operação correta do aplicativo foi identificado. E, como resultado, o uso excessivo de capacidades foi revelado.
Os resultados do estudo formaram a base do projeto de transferência de componentes para contêineres, que discutiremos nos artigos a seguir. Agora podemos dizer com certeza quantos contêineres e com quais características é necessário ter, como usar racionalmente suas capacidades e quais devem ser trabalhadas para garantir o desempenho adequado.
Venha para a nossa acolhedora sala de bate-papo por telegrama, onde você sempre pode pedir conselhos, ajudar colegas e apenas falar sobre pesquisa de produtividade.
Isso é tudo por hoje. Faça perguntas nos comentários e assine o blog Yandex.Money - em breve falaremos sobre phishing e como evitá-lo.