Os jogos são usados há décadas como uma das principais maneiras de testar e avaliar o sucesso dos sistemas de inteligência artificial. À medida que as oportunidades cresciam, os pesquisadores procuravam jogos com complexidade cada vez maior, o que refletia os vários elementos de pensamento necessários para resolver problemas científicos ou aplicados do mundo real. Nos últimos anos, o StarCraft é considerado uma das estratégias mais versáteis e complexas em tempo real e uma das mais populares na cena de esportes eletrônicos da história, e agora o StarCraft também se tornou o principal desafio da pesquisa em IA.
AlphaStar é o primeiro sistema de inteligência artificial capaz de derrotar os melhores jogadores profissionais. Em uma série de partidas que ocorreram em 19 de dezembro, o AlphaStar conquistou uma vitória esmagadora sobre o Grzegorz Komincz (
MaNa ) da equipe
Liquid , um dos
jogadores mais fortes do mundo , com uma pontuação de 5: 0. Antes disso, uma partida de demonstração bem-sucedida também foi disputada contra seu companheiro de equipe Dario Wünsch (
TLO ). As partidas foram realizadas de acordo com todas as regras profissionais em um
cartão de torneio especial e sem restrições.
Apesar dos sucessos significativos em jogos como
Atari ,
Mario ,
Quake III Arena e
Dota 2 , os técnicos da IA lutaram sem sucesso com a complexidade do StarCraft. Os melhores
resultados foram alcançados construindo manualmente os elementos básicos do sistema, impondo várias restrições às regras do jogo, fornecendo ao sistema habilidades sobre-humanas ou jogando em mapas simplificados. Mas mesmo essas nuances tornaram impossível se aproximar do nível dos jogadores profissionais. Ao contrário disso, o AlphaStar joga um jogo completo usando redes neurais profundas, treinadas com base em dados brutos do jogo, usando métodos de
ensino com um professor e
aprendendo com reforço .
Desafio principal
StarCraft II é um universo de fantasia fictícia com uma rica jogabilidade em vários níveis. Junto com a edição original, este é o maior e mais bem-sucedido jogo de todos os tempos, disputado em torneios há mais de 20 anos.

Existem muitas maneiras de jogar, mas o mais comum nos esportes eletrônicos é o torneio individual, composto por 5 partidas. Para começar, o jogador deve escolher uma das três corridas - zergs, protoss ou terrans, cada uma com suas próprias características e capacidades. Portanto, jogadores profissionais costumam se especializar em uma corrida. Cada jogador começa com várias unidades de trabalho que extraem recursos para a construção de edifícios, outras unidades ou o desenvolvimento de tecnologia. Isso permite que o jogador aproveite outros recursos, construa bases mais sofisticadas e desenvolva novas habilidades para enganar o oponente. Para vencer, o jogador deve equilibrar delicadamente a imagem da economia geral, chamada de "macro", e o controle de baixo nível de unidades individuais, chamado de "micro".
A necessidade de equilibrar as metas de curto e longo prazo e de se adaptar a situações imprevistas representa um grande desafio para os sistemas que, de fato, costumam se mostrar completamente inflexíveis. A solução desse problema requer uma inovação em várias áreas da IA:
Teoria dos Jogos : StarCraft é um jogo em que, como em “Pedra, Tesoura, Papel”, não existe uma única estratégia vencedora. Portanto, no processo de aprendizagem, a IA deve constantemente explorar e expandir os horizontes de seu conhecimento estratégico.
Informações incompletas : ao contrário do xadrez ou da partida, onde os jogadores veem tudo o que acontece, no StarCraft informações importantes geralmente são ocultas e devem ser ativamente extraídas por meio da inteligência.
Planejamento a longo prazo : como nas tarefas do mundo real, os relacionamentos de causa e efeito podem não ser instantâneos. Um jogo também pode durar uma hora ou mais, portanto, as ações executadas no início de um jogo podem não ter absolutamente nenhum significado a longo prazo.
Tempo real : Ao contrário dos jogos de tabuleiro tradicionais, onde os participantes se revezam, no StarCraft, os jogadores realizam ações continuamente, juntamente com o passar do tempo.
Enorme espaço de ação : Centenas de unidades e edifícios diferentes devem ser monitorados simultaneamente, em tempo real, o que oferece um espaço combinatório verdadeiramente enorme de oportunidades. Além disso, muitas ações são hierárquicas e podem mudar e complementar ao longo do caminho. Nossa parametrização do jogo fornece uma média de 10 a 26 ações por unidade de tempo.
Em vista desses desafios, o StarCraft se tornou um grande desafio para os pesquisadores de IA. As competições em andamento de StarCraft e StarCraft II têm suas raízes no lançamento da
API BroodWar em 2009. Entre eles estão a
Competição AIIDE StarCraft AI ,
CIG StarCraft Competition ,
Student StarCraft AI Tournament e
Starcraft II AI Ladder .
Nota : Em 2017, o PatientZero publicou em Habré uma excelente tradução de " A história das competições de IA em Starcraft ".Para ajudar a comunidade a explorar ainda mais esses problemas, nós,
trabalhando com a Blizzard em 2016 e 2017, publicamos o
kit de ferramentas PySC2 , que inclui a maior variedade de replays anônimos já publicados. Com base neste trabalho, combinamos nossas conquistas de engenharia e algoritmos para criar o AlphaStar.
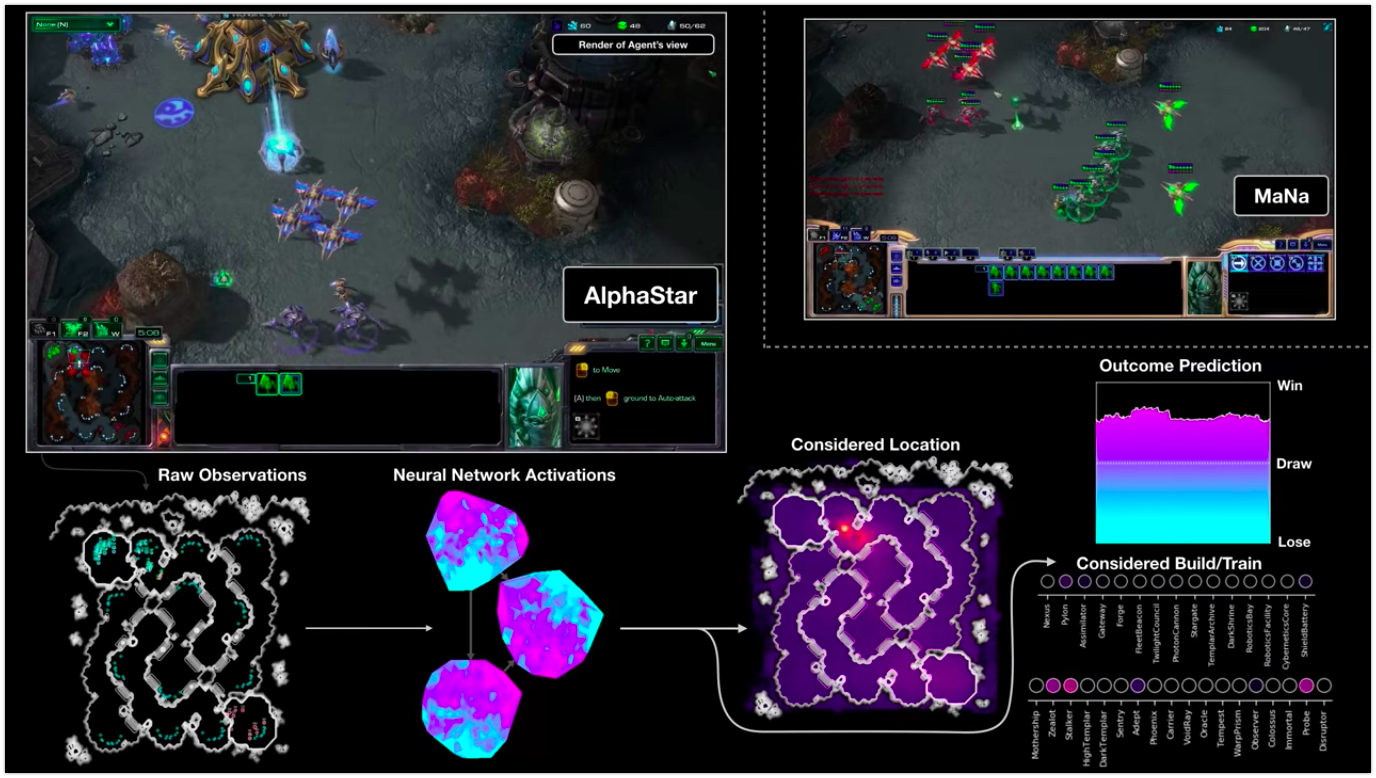
 A visualização do AlphaStar durante a luta contra o MaNa demonstra o jogo em nome do agente - os dados iniciais observados, a atividade da rede neural, algumas das ações propostas e as coordenadas necessárias, bem como o resultado estimado da partida. A visualização do player MaNa também é mostrada, mas é claro que não é acessível ao agente.
A visualização do AlphaStar durante a luta contra o MaNa demonstra o jogo em nome do agente - os dados iniciais observados, a atividade da rede neural, algumas das ações propostas e as coordenadas necessárias, bem como o resultado estimado da partida. A visualização do player MaNa também é mostrada, mas é claro que não é acessível ao agente.Como está o treinamento
O comportamento do AlphaStar é gerado
por uma rede neural de aprendizado profundo, que recebe dados brutos através da interface (uma lista de unidades e suas propriedades) e fornece uma sequência de instruções que são ações no jogo. Mais especificamente, a arquitetura da rede neural usa a abordagem do "torso do
transformador para as unidades, combinada com um
núcleo LSTM profundo , um
chefe de política auto-regressivo com uma
rede de ponteiros e uma
linha de base de valor centralizada "
(para a precisão dos termos deixados sem tradução) . Acreditamos que esses modelos ajudarão ainda mais a lidar com outras tarefas importantes de aprendizado de máquina, incluindo modelagem de sequência de longo prazo e grandes espaços de saída, como tradução, modelagem de linguagem e representações visuais.
O AlphaStar também usa o novo algoritmo de aprendizado multi-agente. Essa rede neural foi originalmente treinada usando um método de aprendizado baseado em professor, com repetições anônimas
disponíveis na Blizzard. Isso permitiu ao AlphaStar estudar e simular as micro e macro estratégias básicas usadas pelos jogadores nos torneios. Este agente derrotou o nível de inteligência artificial incorporado "Elite", que é equivalente ao nível de um jogador na liga de ouro em 95% dos jogos de teste.
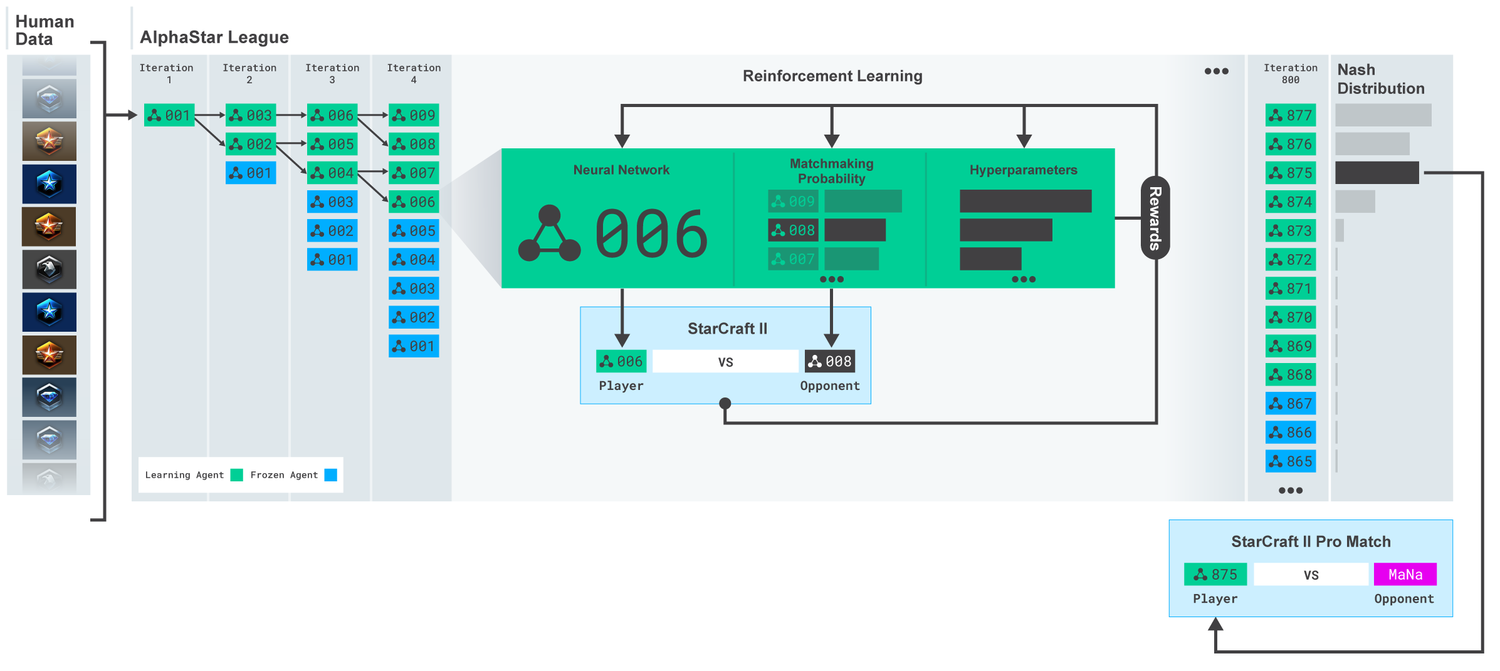 Liga AlphaStar. Os agentes foram treinados inicialmente com base em repetições de partidas humanas e, depois, com partidas competitivas entre si. A cada iteração, novos oponentes se ramificam e os originais congelam. A probabilidade de encontrar outros oponentes e hiperparâmetros determina os objetivos de aprendizado de cada agente, o que aumenta a complexidade e retém a diversidade. Os parâmetros do agente são atualizados com o treinamento de reforço com base no resultado do jogo contra os adversários. O agente final é selecionado (sem substituição) com base na distribuição de Nash.
Liga AlphaStar. Os agentes foram treinados inicialmente com base em repetições de partidas humanas e, depois, com partidas competitivas entre si. A cada iteração, novos oponentes se ramificam e os originais congelam. A probabilidade de encontrar outros oponentes e hiperparâmetros determina os objetivos de aprendizado de cada agente, o que aumenta a complexidade e retém a diversidade. Os parâmetros do agente são atualizados com o treinamento de reforço com base no resultado do jogo contra os adversários. O agente final é selecionado (sem substituição) com base na distribuição de Nash.Esses resultados são usados para iniciar um processo de aprendizado por reforço de múltiplos agentes. Para isso, foi criada uma liga onde os agentes oponentes jogam um contra o outro, assim como as pessoas ganham experiência jogando torneios. Novos rivais foram adicionados por meio da liga, pela duplicação de agentes atuais. Essa nova forma de treinamento, emprestando algumas idéias do método de aprendizado por reforço com elementos de algoritmos genéticos (
baseados na população ), permite criar um processo contínuo de explorar o vasto espaço estratégico de jogo do StarCraft e garantir que os agentes sejam capazes de suportar as estratégias mais poderosas, não esquecendo os antigos.
 Score MMR (Match Making Rating) - um indicador aproximado da habilidade do jogador. Para rivais na liga AlphaStar durante o treinamento, em comparação com as ligas online da Blizzard.
Score MMR (Match Making Rating) - um indicador aproximado da habilidade do jogador. Para rivais na liga AlphaStar durante o treinamento, em comparação com as ligas online da Blizzard.À medida que a liga se desenvolvia e novos agentes foram criados, surgiram contra-estratégias que foram capazes de derrotar as anteriores. Enquanto alguns agentes apenas aprimoraram as estratégias que haviam encontrado anteriormente, outros agentes criaram completamente novos, incluindo novas ordens de construção incomuns, composição da unidade e gerenciamento de macros. Por exemplo, logo no início, os "queijos" floresceram - rápido avanço com a ajuda de
canhões de
fótons ou
templários das trevas . Mas, à medida que o processo de aprendizado avançava, essas estratégias arriscadas foram descartadas, dando lugar a outras. Por exemplo, a produção de um número excessivo de trabalhadores para obter um influxo adicional de recursos ou a doação de dois
oráculos para atacar os trabalhadores do inimigo e prejudicar sua economia. Esse processo é semelhante ao modo como os jogadores comuns descobriram novas estratégias e derrotaram as antigas abordagens populares, durante os muitos anos desde o lançamento do StarCraft.
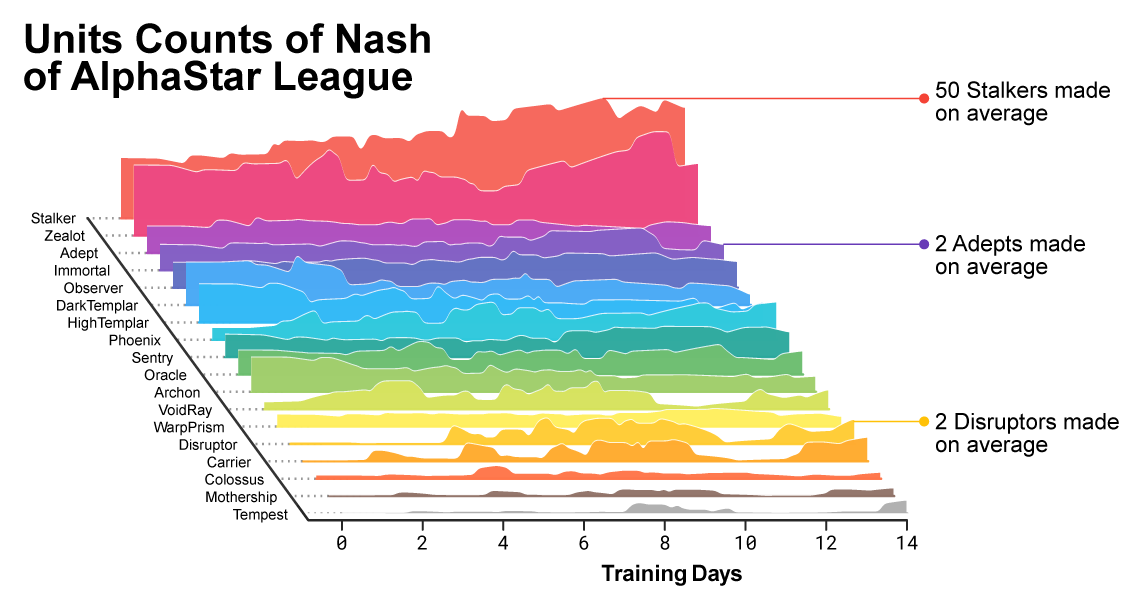 À medida que o treinamento avançava, notava-se como a composição das unidades utilizadas pelos agentes estava mudando.
À medida que o treinamento avançava, notava-se como a composição das unidades utilizadas pelos agentes estava mudando.Para garantir a diversidade, cada agente foi dotado de seu próprio objetivo de aprendizado. Por exemplo, quais oponentes esse agente deve derrotar ou qualquer outra motivação intrínseca que determine o jogo do agente. Um determinado agente pode ter o objetivo de derrotar um oponente específico e o outro uma seleção inteira de oponentes, mas apenas unidades específicas. Esses objetivos mudaram ao longo do processo de aprendizagem.
 Visualização interativa (recursos interativos estão disponíveis no artigo original ), que mostra os rivais da AlphaStar League. O agente que jogou contra TLO e MaNa é marcado separadamente.
Visualização interativa (recursos interativos estão disponíveis no artigo original ), que mostra os rivais da AlphaStar League. O agente que jogou contra TLO e MaNa é marcado separadamente.Os coeficientes (pesos) da rede neural de cada agente foram atualizados usando treinamento de reforço baseado em jogos com oponentes, a fim de otimizar seus objetivos específicos de aprendizagem. A regra para atualizar o peso é um novo algoritmo de aprendizado eficaz: “algoritmo de aprendizado por reforço
crítico fora do critério político, com
repetição de experiência ,
aprendizado auto-imitado e
destilação de critério ”
(para a precisão dos termos deixados sem tradução) .
 A imagem mostra como um agente (ponto preto), selecionado como resultado do jogo contra o MaNa, desenvolveu sua estratégia em comparação com os oponentes (pontos coloridos) no processo de treinamento. Cada ponto representa um oponente na liga. A posição do ponto mostra a estratégia e o tamanho - a frequência com que é escolhido como oponente do agente MaNa no processo de aprendizado.
A imagem mostra como um agente (ponto preto), selecionado como resultado do jogo contra o MaNa, desenvolveu sua estratégia em comparação com os oponentes (pontos coloridos) no processo de treinamento. Cada ponto representa um oponente na liga. A posição do ponto mostra a estratégia e o tamanho - a frequência com que é escolhido como oponente do agente MaNa no processo de aprendizado.Para treinar o AlphaStar, criamos um sistema distribuído escalável baseado no
Google TPU 3, que fornece o processo de treinamento paralelo de toda uma população de agentes com milhares de cópias em execução do StarCraft II. A AlphaStar League durou 14 dias usando 16 TPUs para cada agente. Durante o treinamento, cada agente teve até 200 anos de experiência jogando StarCraft em tempo real. A versão final do AlphaStar Agent contém componentes de
distribuição Nash de todas as ligas. Em outras palavras, a mistura mais eficaz de estratégias que foram descobertas durante os jogos. E essa configuração pode ser executada em uma GPU de desktop padrão. Uma descrição técnica completa está sendo preparada para publicação em uma revista científica revisada por pares.
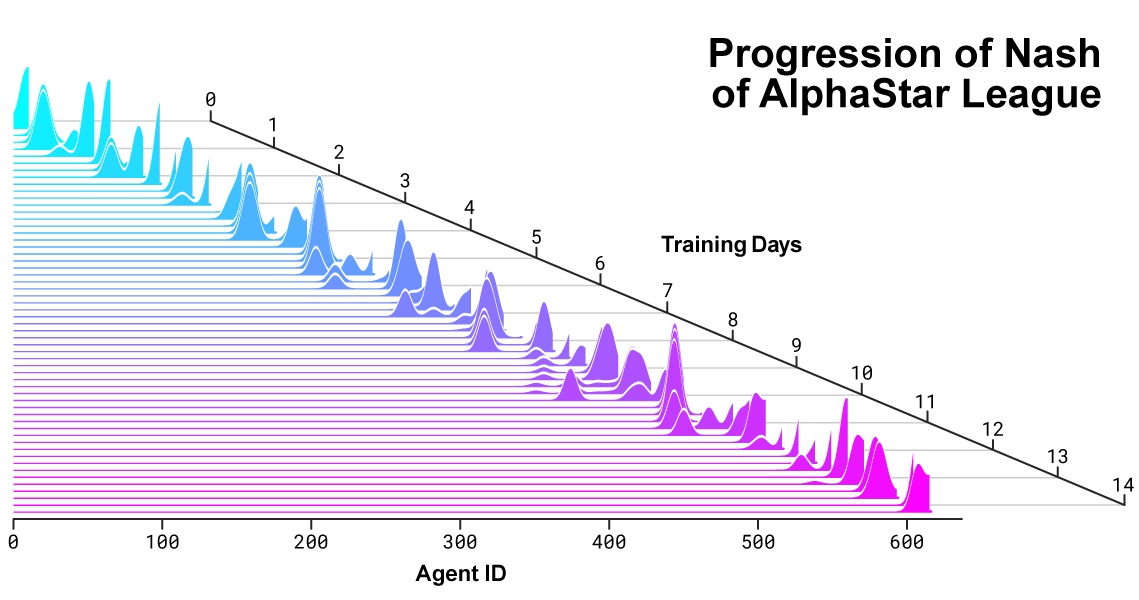 Distribuição de Nash entre rivais durante o desenvolvimento da liga e a criação de novos oponentes. A distribuição de Nash, que é o conjunto menos explorável de concorrentes complementares, aprecia novos players, demonstrando assim progresso contínuo em relação a todos os concorrentes anteriores.
Distribuição de Nash entre rivais durante o desenvolvimento da liga e a criação de novos oponentes. A distribuição de Nash, que é o conjunto menos explorável de concorrentes complementares, aprecia novos players, demonstrando assim progresso contínuo em relação a todos os concorrentes anteriores.Como o AlphaStar age e vê o jogo
Jogadores profissionais como TLO ou MaNa podem executar centenas de ações por minuto (
APM ). Mas isso é muito menor do que a maioria
dos bots existentes que controlam independentemente cada unidade e geram milhares, se não dezenas de milhares de ações.
Em nossos jogos contra o TLO e o MaNa, o AlphaStar manteve o APM em uma média de 280, o que é muito menor que o dos jogadores profissionais, embora suas ações possam ser mais precisas. Um APM tão baixo se deve, em particular, ao fato de o AlphaStar começar a estudar com base em repetições de jogadores comuns e tentar imitar a maneira de jogar em seres humanos. Além disso, o AlphaStar reage com um atraso entre a observação e a ação de uma média de cerca de 350 ms.
 Distribuição do APM AlphaStar em partidas contra o MaNa e o TLO, e o atraso geral entre a observação e a ação.
Distribuição do APM AlphaStar em partidas contra o MaNa e o TLO, e o atraso geral entre a observação e a ação.Durante partidas contra TLO e MaNa, AlphaStar interagia com o mecanismo de jogo StarCraft por meio de uma interface simples, ou seja, ele podia ver os atributos de suas unidades inimigas visíveis no mapa diretamente, sem ter que mover a câmera - jogar de forma eficaz com uma visão reduzida de todo o território . Ao contrário, as pessoas vivas devem gerenciar claramente a “economia da atenção” para decidir constantemente onde focar a câmera. No entanto, uma análise dos jogos AlphaStar revela que controla implicitamente o foco. Em média, um agente muda seu contexto de atenção cerca de 30 vezes por minuto, como MaNa e TLO.
Além disso, desenvolvemos a segunda versão do AlphaStar. Como jogadores humanos, esta versão do AlphaStar escolhe claramente quando e para onde mover a câmera. Nesta modalidade, sua percepção é limitada a informações na tela e ações também são permitidas apenas na área visível da tela.
 Desempenho do AlphaStar ao usar a interface base e a interface da câmera. O gráfico mostra que o novo agente que trabalha com a câmera está obtendo rapidamente um desempenho comparável para o agente usando a interface básica.
Desempenho do AlphaStar ao usar a interface base e a interface da câmera. O gráfico mostra que o novo agente que trabalha com a câmera está obtendo rapidamente um desempenho comparável para o agente usando a interface básica.Treinamos dois novos agentes, um usando a interface base e outro que deveria aprender a controlar a câmera, jogando contra a liga AlphaStar. Cada agente no início foi treinado com um professor com base em partidas humanas, seguido de treinamento com o reforço descrito acima. A versão AlphaStar, que usa a interface da câmera, alcançou quase os mesmos resultados que a versão com a interface base, excedendo a marca de 7000 MMR em nosso ranking interno. Em uma partida de demonstração, o MaNa derrotou o protótipo AlphaStar usando uma câmera. Nós treinamos esta versão apenas 7 dias. Esperamos poder avaliar uma versão totalmente treinada com uma câmera em um futuro próximo.
Esses resultados mostram que o sucesso do AlphaStar em partidas contra o MaNa e o TLO é principalmente o resultado de um bom gerenciamento de macro e micro, e não apenas uma grande taxa de cliques, reação rápida ou acesso a informações na interface básica.
Resultados do jogo AlphaStar vs jogadores profissionais
O StarCraft permite que os jogadores escolham uma das três corridas - terrans, zerg ou protoss. Decidimos que o AlphaStar atualmente se especializaria em uma corrida específica, a protoss, a fim de reduzir o tempo de treinamento e as variações na avaliação dos resultados de nossa liga nacional. Mas deve-se notar que um processo de aprendizado semelhante pode ser aplicado a qualquer raça. Nossos agentes foram treinados para jogar o StarCraft II versão 4.6.2 no modo protoss versus protoss no mapa CatalystLE. Para avaliar o desempenho do AlphaStar, inicialmente testamos nossos agentes em partidas contra o TLO - um jogador profissional para zerg e um jogador para o nível protoss "GrandMaster". O AlphaStar venceu partidas com uma pontuação de 5: 0, usando uma grande variedade de unidades e ordens de construção. "Fiquei surpreso com a força do agente", disse ele. “AlphaStar pega estratégias conhecidas e as vira de cabeça para baixo. O agente mostrou estratégias nas quais eu nunca pensei. E isso mostra que ainda existem maneiras de jogar que ainda não são totalmente compreendidas. ”
Após uma semana extra de treinamento, jogamos contra o MaNa, um dos jogadores mais poderosos de StarCraft II do mundo e um dos 10 principais jogadores de protoss. Desta vez, o AlphaStar venceu por 5 a 0, demonstrando fortes habilidades de microgerenciamento e macroestratégia. "Fiquei surpreso ao ver o AlphaStar usando as abordagens mais avançadas e estratégias diferentes em cada jogo, mostrando um estilo de jogo muito humano que eu nunca esperava ver", disse ele. “Percebi o quão forte meu estilo de jogo depende do uso de erros baseados nas reações humanas. E isso coloca o jogo em um nível totalmente novo. Todos esperamos entusiasticamente ver o que acontece a seguir ".
AlphaStar e outros problemas difíceis
Apesar do StarCraft ser apenas um jogo, mesmo que seja muito difícil, acreditamos que as técnicas subjacentes ao AlphaStar podem ser úteis na solução de outros problemas. Por exemplo, esse tipo de arquitetura de rede neural é capaz de simular seqüências muito longas de ações prováveis, em jogos geralmente com duração de até uma hora e contendo dezenas de milhares de ações com base em informações incompletas. Cada quadro no StarCraft é usado como uma etapa de entrada. Nesse caso, a rede neural de cada uma dessas etapas prevê a sequência esperada de ações para todo o jogo restante. A tarefa fundamental de fazer previsões complexas para sequências de dados muito longas é encontrada em muitos problemas do mundo real, como previsão do tempo, modelagem climática, compreensão do idioma etc. Estamos muito satisfeitos em reconhecer o enorme potencial que pode ser aplicado nessas áreas, usando a experiência adquirida. no projeto AlphaStar.
Também achamos que alguns de nossos métodos de ensino podem ser úteis no estudo da segurança e confiabilidade da IA. Um dos problemas mais difíceis no campo da IA é o número de opções nas quais o sistema pode estar errado. , . AlphaStar, , . , - . , , , .
StarCraft - . , , ,
AlphaZero AlphaFold , , .
11MaNa
AlphaStar MaNa