
A DeepMind, uma subsidiária da Alphabet, uma empresa de pesquisa no campo da inteligência artificial, anunciou um novo marco nessa grande missão:
pela primeira vez, a IA derrotou a pessoa na estratégia de Starcraft II . Em dezembro de 2018, uma rede neural convolucional chamada
AlphaStar espalhou os jogadores profissionais
TLO (Dario Wünsch, Alemanha) e
MaNa (Grzegorz Kominz, Polônia), marcando dez vitórias. A empresa anunciou este evento ontem em uma
transmissão ao vivo no YouTube e Twitch.
Nos dois casos, as pessoas e o programa jogaram como protoss. Embora o TLO não se especialize nesta corrida, o MaNa resistiu seriamente e até venceu um jogo.
Na popular estratégia em tempo real, os jogadores representam uma das três raças que competem por recursos, constroem estruturas e lutam no grande mapa. É importante observar que a velocidade do programa e sua visibilidade no campo de batalha foram limitadas, de modo que o AlphaStar não obteve uma vantagem injusta sobre as pessoas (correção: aparentemente, a visibilidade foi limitada apenas na última partida). Na verdade, de acordo com as estatísticas, o programa ainda executava menos ações por minuto que as pessoas: uma média de 277 para AlphaStar, 390 para MaNa, 678 para TLO.
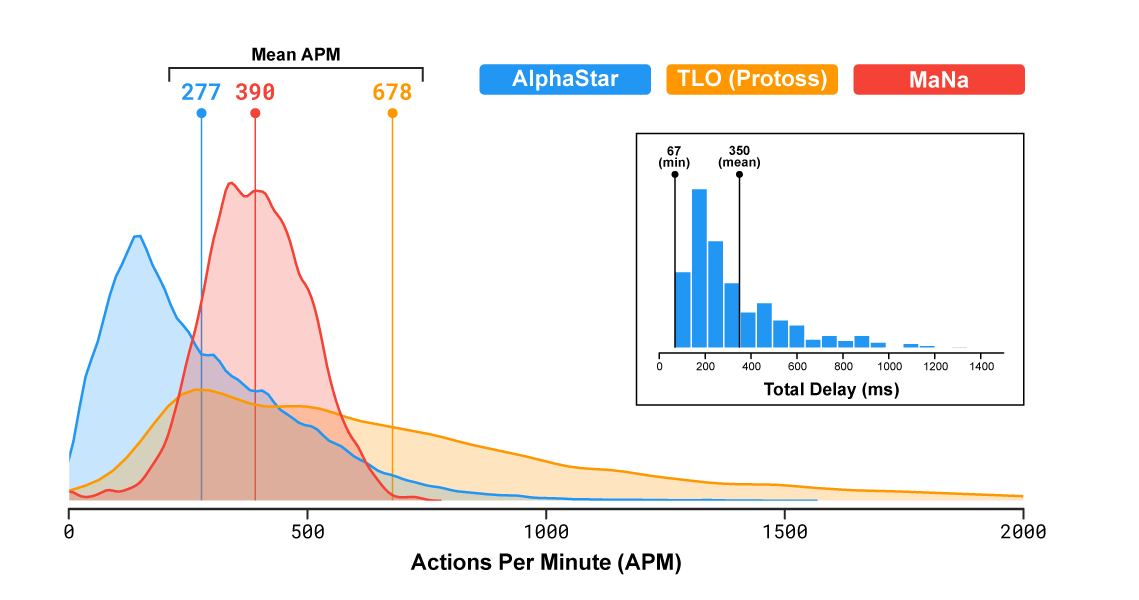
O
vídeo mostra a visão do jogo do ponto de vista do agente de IA na segunda partida contra o MaNa. A visão do lado humano também é mostrada, mas não estava disponível para o programa.
AlphaStar foi treinado para jogar por protoss em um ambiente chamado AlphaStar League. Primeiro, a rede neural passou três dias observando gravações de jogos e depois brincando consigo mesma, usando uma técnica conhecida como treinamento de reforço, aprimorando as habilidades.
Em dezembro, eles organizaram uma sessão de jogo contra o TLO, na qual foram testadas cinco versões diferentes do AlphaStar. Nesta ocasião, o TLO
reclamou que não conseguia se adaptar ao jogo do adversário. O programa venceu com uma pontuação de 5-0.
Após otimizar as configurações da rede neural, uma partida foi organizada uma semana depois contra o MaNa. O programa venceu novamente cinco jogos, mas MaNa se vingou no último jogo contra a versão mais recente do algoritmo ao vivo, então ele tem algo para se orgulhar.
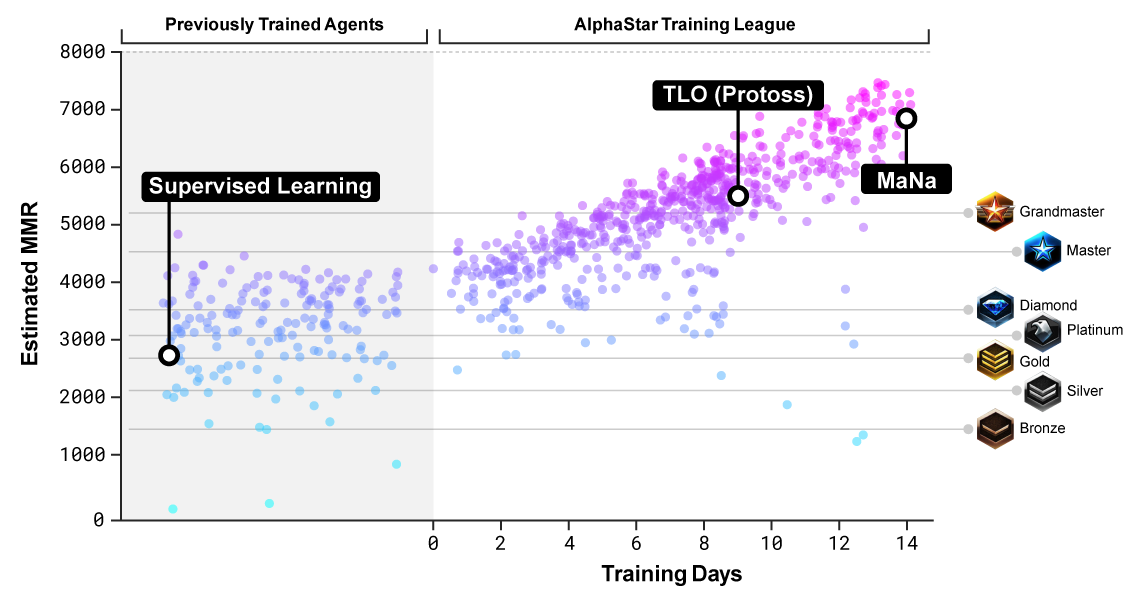 Avaliação do nível de oponentes em que a rede neural foi treinada
Avaliação do nível de oponentes em que a rede neural foi treinadaPara entender os princípios do planejamento estratégico, o AlphaStar teve que dominar o pensamento especial. Os métodos desenvolvidos para este jogo podem ser úteis em muitas situações práticas, quando uma estratégia complexa é necessária: por exemplo, planejamento comercial ou militar.
Starcraft II não é apenas um jogo extremamente desafiador. Este também é um jogo com informações incompletas, onde os jogadores nem sempre podem ver as ações de seu oponente. Também não possui uma estratégia ideal. E leva tempo para que os resultados das ações do jogador se tornem claros: isso também dificulta o aprendizado. A equipe do DeepMind usou uma arquitetura de rede neural muito especializada para resolver esses problemas.
Aprendizagem limitada em jogos
O DeepMind é conhecido como desenvolvedor de software que venceu os melhores profissionais de xadrez e xadrez do mundo. Antes disso, a empresa desenvolveu vários algoritmos que aprenderam a jogar jogos simples da Atari. Os videogames são uma ótima maneira de medir os avanços na inteligência artificial e comparar computadores com pessoas. No entanto, esta é uma área de teste muito estreita. Como os programas anteriores, o AlphaStar realiza apenas uma tarefa, embora incrivelmente bem.
Podemos dizer que uma IA fraca para fins restritos domina as habilidades de planejamento estratégico e táticas de operações de combate. Teoricamente, essas habilidades podem ser úteis no mundo real. Mas, na prática, esse não é necessariamente o caso.
Alguns especialistas acreditam que essas aplicações altamente especializadas de IA não têm nada a ver com IA forte: “Os programas que aprenderam a jogar com maestria um videogame ou jogo de tabuleiro específico no nível“ sobre-humano ”são
completamente perdidos quando há a menor alteração nas condições (alterar o plano de fundo na tela ou alterar a posição) "plataforma" virtual para bater a "bola"), - diz o professor de ciência da computação na Universidade Estadual de Portland, Melanie Mitchell no artigo
"ran inteligência artificial em um ponima barreira ções " . - Esses são apenas alguns exemplos que demonstram a falta de confiabilidade dos melhores programas de IA, se a situação for ligeiramente diferente daquela em que eles foram treinados. Os erros nesses sistemas variam de ridículos e inofensivos a potencialmente catastróficos. ”
O professor acredita que a corrida de comercialização da IA exerceu enorme pressão sobre os pesquisadores para criar sistemas que funcionam "razoavelmente bem" em tarefas limitadas. Mas, finalmente, o desenvolvimento de IA confiável exige um estudo mais profundo de nossas próprias habilidades e uma nova compreensão dos mecanismos cognitivos que nós mesmos usamos:
Nosso próprio entendimento das situações que enfrentamos é baseado em “conceitos de senso comum” amplos e intuitivos sobre como o mundo funciona e os objetivos, motivos e comportamento provável de outros seres vivos, especialmente de outras pessoas. Além disso, nossa compreensão do mundo é baseada em nossas habilidades básicas para generalizar o que sabemos, formar conceitos abstratos e fazer analogias - em suma, adaptar nossos conceitos de maneira flexível a novas situações. Por décadas, os pesquisadores experimentaram ensinar à IA o senso comum intuitivo e as habilidades humanas sustentáveis para generalizar, mas pouco progresso foi feito nessa questão muito difícil.
A rede neural AlphaStar só pode reproduzir protoss até agora. Os desenvolvedores anunciaram planos para treiná-la no futuro para jogar em outras corridas.