
Mais uma vez, dirigindo um carro pela minha cidade natal e percorrendo outro poço, pensei: existiam estradas “boas” em todo o país e decidi que deveríamos avaliar objetivamente a situação com a qualidade das estradas em nosso país.
Formalização de tarefas
Na Rússia, os requisitos para a qualidade das estradas estão descritos no GOST R 50597-2017 “Estradas e estradas. Requisitos para o estado operacional aceitáveis sob as condições de garantir a segurança rodoviária. Métodos de controle ". Este documento define os requisitos para cobrir a faixa de rodagem, estradas, faixas divisórias, calçadas, passarelas para pedestres, etc., além de estabelecer os tipos de danos.
Como a tarefa de determinar todos os parâmetros das estradas é bastante extensa, decidi reduzi-lo para mim e me concentrar apenas no problema de determinar defeitos na cobertura da estrada. No GOST R 50597-2017, os seguintes defeitos no revestimento da pista são distinguidos:
- buracos
- intervalos
- rebaixamentos
- turnos
- pentes
- rastrear
- pasta de transpiração
Eu decidi resolver esses defeitos.
Coleta de dados
Onde posso obter fotografias que retratam seções suficientemente grandes da estrada e mesmo com referência à geolocalização? A resposta veio em strass - panoramas nos mapas do Yandex (ou Google); no entanto, depois de um pouco de pesquisa, encontrei várias outras opções alternativas:
- emissão de mecanismos de pesquisa de imagens para solicitações relevantes;
- fotos em sites para recebimento de reclamações (Rosyama, cidadão irritado, virtude etc.)
- O Opendatascience solicitou um projeto para detectar defeitos na estrada com um conjunto de dados marcado - github.com/sekilab/RoadDamageDetector
Infelizmente, uma análise dessas opções mostrou que elas não são muito adequadas para mim: emitir mecanismos de pesquisa com muito ruído (muitas fotos que não são estradas, várias renderizações etc.), fotos de sites para receber reclamações contêm apenas fotos com grandes violações da superfície do asfalto , há muito poucas fotos com leves violações de cobertura e sem violações nesses sites. O conjunto de dados do projeto RoadDamageDetector é coletado no Japão e não contém amostras com grandes violações de cobertura, bem como estradas sem cobertura.
Como as opções alternativas não são adequadas, usaremos os panoramas Yandex (excluí a opção do panorama do Google, pois o serviço é apresentado em menos cidades da Rússia e é atualizado com menos frequência). Ele decidiu coletar dados em cidades com uma população de mais de 100 mil pessoas, bem como em centros federais. Fiz uma lista de nomes de cidades - havia 176 delas, mais tarde acontece que apenas 149 delas têm panoramas. Não vou me aprofundar nos recursos dos blocos de análise, direi que no final consegui 149 pastas (uma para cada cidade) nas quais havia um total de 1,7 milhões de fotos. Por exemplo, para Novokuznetsk, a pasta era assim:

Pelo número de fotos baixadas, as cidades foram distribuídas da seguinte forma:
QuadroCidade
| Número de fotos, peças
|
|---|
Moscovo
| 86048
|
São Petersburgo
| 41376
|
Saransk
| 18880
|
Podolsk
| 18560
|
Krasnogorsk
| 18208
|
Lyubertsy
| 17760
|
Kaliningrado
| 16928
|
Kolomna
| 16832
|
Mytishchi
| 16192
|
Vladivostok
| 16096
|
Balashikha
| 15968
|
Petrozavodsk
| 15968
|
Ekaterinburg
| 15808
|
Veliky Novgorod
| 15744
|
Naberezhnye Chelny
| 15680
|
Krasnodar
| 15520
|
Nizhny Novgorod
| 15488
|
Khimki
| 15296
|
Tula
| 15296
|
Novosibirsk
| 15264
|
Tver
| 15200
|
Miass
| 15104
|
Ivanovo
| 15072
|
Vologda
| 15008
|
Zhukovsky
| 14976
|
Kostroma
| 14912
|
Samara
| 14880
|
Korolev
| 14784
|
Kaluga
| 14720
|
Cherepovets
| 14720
|
Sebastopol
| 14688
|
Pushkino
| 14528
|
Yaroslavl
| 14464
|
Ulyanovsk
| 14400
|
Rostov do Don
| 14368
|
Domodedovo
| 14304
|
Kamensk-Uralsky
| 14208
|
Pskov
| 14144
|
Yoshkar-Ola
| 14080
|
Kerch
| 14080
|
Murmansk
| 13920
|
Togliatti
| 13920
|
Vladimir
| 13792
|
Águia
| 13792
|
Syktyvkar
| 13728
|
Dolgoprudny
| 13696
|
Khanty-Mansiysk
| 13664
|
Kazan
| 13600
|
Engels
| 13440
|
Arkhangelsk
| 13280
|
Bryansk
| 13216
|
Omsk
| 13120
|
Syzran
| 13088
|
Krasnoyarsk
| 13056
|
Shchelkovo
| 12928
|
Penza
| 12864
|
Chelyabinsk
| 12768
|
Cheboksary
| 12768
|
Nizhny Tagil
| 12672
|
Stavropol
| 12672
|
Ramenskoye
| 12640
|
Irkutsk
| 12608
|
Angarsk
| 12608
|
Tyumen
| 12512
|
Odintsovo
| 12512
|
Ufa
| 12512
|
Magadan
| 12512
|
Perm
| 12448
|
Kirov
| 12256
|
Nizhnekamsk
| 12224
|
Makhachkala
| 12096
|
Nizhnevartovsk
| 11936
|
Kursk
| 11904
|
Sochi
| 11872
|
Tambov
| 11840
|
Pyatigorsk
| 11808
|
Volgodonsk
| 11712
|
Ryazan
| 11680
|
Saratov
| 11616
|
Dzerzhinsk
| 11456
|
Orenburg
| 11456
|
Monte
| 11424
|
Volgogrado
| 11264
|
Izhevsk
| 11168
|
Crisóstomo
| 11136
|
Lipetsk
| 11072
|
Kislovodsk
| 11072
|
Surgut
| 11040
|
Magnitogorsk
| 10912
|
Smolensk
| 10784
|
Khabarovsk
| 10752
|
Kopeysk
| 10688
|
Maykop
| 10656
|
Petropavlovsk-Kamchatsky
| 10624
|
Taganrog
| 10560
|
Barnaul
| 10528
|
Sergiev Posad
| 10368
|
Elista
| 10304
|
Sterlitamak
| 9920
|
Simferopol
| 9824
|
Tomsk
| 9760
|
Orekhovo-Zuevo
| 9728
|
Astracã
| 9664
|
Evpatoria
| 9568
|
Noginsk
| 9344
|
Chita
| 9216
|
Belgorod
| 9120
|
Biysk
| 8928
|
Rybinsk
| 8896
|
Severodvinsk
| 8832
|
Voronezh
| 8768
|
Blagoveshchensk
| 8672
|
Novorossiysk
| 8608
|
Ulan-Ude
| 8576
|
Serpukhov
| 8320
|
Komsomolsk-on-Amur
| 8192
|
Abakan
| 8128
|
Norilsk
| 8096
|
Yuzhno-Sakhalinsk
| 8032
|
Obninsk
| 7904
|
Essentuki
| 7712
|
Bataysk
| 7648
|
Volzhsky
| 7584
|
Novocherkassk
| 7488
|
Berdsk
| 7456
|
Arzamas
| 7424
|
Pervouralsk
| 7392
|
Kemerovo
| 7104
|
Elektrostal
| 6720
|
Derbent
| 6592
|
Yakutsk
| 6528
|
Murom
| 6240
|
Nefteyugansk
| 5792
|
Reutov
| 5696
|
Birobidzhan
| 5440
|
Novokuybyshevsk
| 5248
|
Salekhard
| 5184
|
Novokuznetsk
| 5152
|
Novy Urengoy
| 4736
|
Noyabrsk
| 4416
|
Novocheboksarsk
| 4352
|
Yelets
| 3968
|
Kaspiysk
| 3936
|
Stary Oskol
| 3840
|
Artyom
| 3744
|
Zheleznogorsk
| 3584
|
Salavat
| 3584
|
Prokopyevsk
| 2816
|
Gorno-Altaysk
| 2464
|
Preparando um conjunto de dados para treinamento
E assim, o conjunto de dados é montado, como agora, tendo uma foto da seção da estrada e dos objetos anexos, descobre a qualidade do asfalto mostrado nele? Decidi cortar um pedaço da foto medindo 350 * 244 pixels no centro da foto original, logo abaixo do meio. Em seguida, reduza a peça cortada horizontalmente para um tamanho de 244 pixels. A imagem resultante (tamanho 244 * 244) será a entrada para o codificador convolucional:

Para entender melhor com quais dados eu ligo, as primeiras 2000 fotos que eu mesmo marquei, o restante das fotos foram marcadas pelos funcionários da Yandex.Tolki. Antes deles, fiz uma pergunta com a seguinte redação.
Indique qual superfície da estrada você vê na foto:
- Solo / entulho
- Pedras de pavimentação, azulejo, pavimento
- Trilhos, trilhos de trem
- Água, poças grandes
- Asfalto
- Não há estrada na foto / Objetos estranhos / A cobertura não é visível devido a carros
Se o artista escolheu "Asphalt", apareceu um menu que oferecia a avaliação de sua qualidade:
- Excelente cobertura
- Ligeiras rachaduras / buracos únicos rasos
- Rachaduras grandes / rachaduras na grade / pequenos buracos
- Caldeirões Grandes / Caldeirões Profundos / Revestimento Destruído
Como as execuções de teste das tarefas mostraram, os executores do Y. Toloki não diferem na integridade do trabalho - eles clicam acidentalmente nos campos com o mouse e consideram a tarefa concluída. Eu tive que adicionar perguntas de controle (havia 46 fotografias na tarefa, 12 das quais eram de controle) e permitir aceitação tardia. Como questões de controle, usei as fotos que me marcou. Automatizei a aceitação atrasada - Y. Toloka permite que você carregue os resultados do trabalho em um arquivo CSV e carregue os resultados da verificação de respostas. A verificação das respostas funcionou da seguinte maneira - se a tarefa contiver mais de 5% de respostas incorretas para controlar as perguntas, ela será considerada não realizada. Além disso, se o contratado indicou uma resposta que é logicamente próxima da verdadeira, sua resposta é considerada correta.
Como resultado, recebi cerca de 30 mil fotos marcadas, que decidi distribuir em três aulas para treinamento:
- “Bom” - fotos rotuladas como “Asfalto: excelente revestimento” e “Asfalto: pequenas rachaduras simples”
- “Médio” - fotos rotuladas como “Pedras de pavimentação, ladrilhos, calçadas”, “Trilhos, trilhos” e “Asfalto: grandes rachaduras / rachaduras na grade / pequenos buracos”
- “Grande” - fotos rotuladas como “Solo / pedra britada”, “Água, poças grandes” e “Asfalto: um grande número de buracos / buracos profundos / pavimento destruído”
- As fotos marcadas com “Não há estrada na foto / Objetos estranhos / A cobertura não é visível devido aos carros” eram muito poucas (22 peças). Excluí-as de outros trabalhos
Desenvolvimento e treinamento do classificador
Assim, como os dados são coletados e rotulados, prosseguimos para o desenvolvimento do classificador. Normalmente, para as tarefas de classificação de imagens, especialmente quando o treinamento é feito em pequenos conjuntos de dados, é usado um codificador convolucional pronto para a saída à qual um novo classificador está conectado. Decidi usar um classificador simples sem uma camada oculta, uma camada de entrada do tamanho 128 e uma camada de saída do tamanho 3. Decidi usar imediatamente várias opções prontas, treinadas no ImageNet como codificadores:
- Xception
- Resnet
- Iniciação
- Vgg16
- Densenet121
- Mobilenet
Aqui está a função que cria o modelo Keras com o codificador fornecido:
def createModel(typeModel): conv_base = None if(typeModel == "nasnet"): conv_base = keras.applications.nasnet.NASNetMobile(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "xception"): conv_base = keras.applications.xception.Xception(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "resnet"): conv_base = keras.applications.resnet50.ResNet50(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "inception"): conv_base = keras.applications.inception_v3.InceptionV3(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "densenet121"): conv_base = keras.applications.densenet.DenseNet121(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "mobilenet"): conv_base = keras.applications.mobilenet_v2.MobileNetV2(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "vgg16"): conv_base = keras.applications.vgg16.VGG16(include_top=False, input_shape=(224,224,3), weights='imagenet') conv_base.trainable = False model = Sequential() model.add(conv_base) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_regularizer=regularizers.l2(0.0002))) model.add(Dropout(0.3)) model.add(Dense(3, activation='softmax')) model.compile(optimizer=keras.optimizers.Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy']) return model
Para o treinamento, usei um gerador com aumento (uma vez que as possibilidades de aumento incorporadas ao Keras me pareciam insuficientes, usei a biblioteca
Augmentor ):
- Encostas
- Distorção aleatória
- Turns
- Troca de cores
- Turnos
- Alterar contraste e brilho
- Adicionando ruído aleatório
- Colheita
Após o aprimoramento, as fotos ficaram assim:

Código do gerador:
def get_datagen(): train_dir='~/data/train_img' test_dir='~/data/test_img' testDataGen = ImageDataGenerator(rescale=1. / 255) train_generator = datagen.flow_from_directory( train_dir, target_size=img_size, batch_size=16, class_mode='categorical') p = Augmentor.Pipeline(train_dir) p.skew(probability=0.9) p.random_distortion(probability=0.9,grid_width=3,grid_height=3,magnitude=8) p.rotate(probability=0.9, max_left_rotation=5, max_right_rotation=5) p.random_color(probability=0.7, min_factor=0.8, max_factor=1) p.flip_left_right(probability=0.7) p.random_brightness(probability=0.7, min_factor=0.8, max_factor=1.2) p.random_contrast(probability=0.5, min_factor=0.9, max_factor=1) p.random_erasing(probability=1,rectangle_area=0.2) p.crop_by_size(probability=1, width=244, height=244, centre=True) train_generator = keras_generator(p,batch_size=16) test_generator = testDataGen.flow_from_directory( test_dir, target_size=img_size, batch_size=32, class_mode='categorical') return (train_generator, test_generator)
O código mostra que o aumento não é usado para dados de teste.
Com um gerador sintonizado, você pode começar a treinar o modelo, nós o realizaremos em duas etapas: primeiro, apenas treine nosso classificador e, em seguida, completamente o modelo inteiro.
def evalModelstep1(typeModel): K.clear_session() gc.collect() model=createModel(typeModel) traiGen,testGen=getDatagen() model.fit_generator(generator=traiGen, epochs=4, steps_per_epoch=30000/16, validation_steps=len(testGen), validation_data=testGen, ) return model def evalModelstep2(model): early_stopping_callback = EarlyStopping(monitor='val_loss', patience=3) model.layers[0].trainable=True model.trainable=True model.compile(optimizer=keras.optimizers.Adam(lr=1e-5), loss='binary_crossentropy', metrics=['accuracy']) traiGen,testGen=getDatagen() model.fit_generator(generator=traiGen, epochs=25, steps_per_epoch=30000/16, validation_steps=len(testGen), validation_data=testGen, callbacks=[early_stopping_callback] ) return model def full_fit(): model_names=[ "xception", "resnet", "inception", "vgg16", "densenet121", "mobilenet" ] for model_name in model_names: print("#########################################") print("#########################################") print("#########################################") print(model_name) print("#########################################") print("#########################################") print("#########################################") model = evalModelstep1(model_name) model = evalModelstep2(model) model.save("~/data/models/model_new_"+str(model_name)+".h5")
Ligue para full_fit () e aguarde. Estamos esperando por um longo tempo.
Como resultado, teremos seis modelos treinados, verificaremos a precisão desses modelos em uma parte separada dos dados rotulados; recebi o seguinte:
Nome do modelo
| % De precisão
|
Xception
| 87,3
|
Resnet
| 90,8
|
Iniciação
| 90,2
|
Vgg16
| 89,2
|
Densenet121
| 90,6
|
Mobilenet
| 86,5
|
Em geral, não muito, mas com uma amostra de treinamento tão pequena, não se pode esperar mais. Para aumentar um pouco a precisão, combinei as saídas dos modelos calculando a média:
def create_meta_model(): model_names=[ "xception", "resnet", "inception", "vgg16", "densenet121", "mobilenet" ] model_input = Input(shape=(244,244,3)) submodels=[] i=0; for model_name in model_names: filename= "~/data/models/model_new_"+str(model_name)+".h5" submodel = keras.models.load_model(filename) submodel.name = model_name+"_"+str(i) i+=1 submodels.append(submodel(model_input)) out=average(submodels) model = Model(inputs = model_input,outputs=out) model.compile(optimizer=keras.optimizers.Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy']) return model
A precisão resultante foi de 91,3%. Neste resultado, eu decidi parar.
Usando Classificador
Finalmente, o classificador está pronto e pode ser colocado em ação! Preparo os dados de entrada e executo o classificador - um pouco mais de um dia e 1,7 milhão de fotos foram processadas. Agora, a parte divertida são os resultados. Traga imediatamente a primeira e a última dez cidades no número relativo de estradas com boa cobertura:

Tabela completa (imagem clicável) E aqui está a classificação da qualidade da estrada por sujeitos federais:
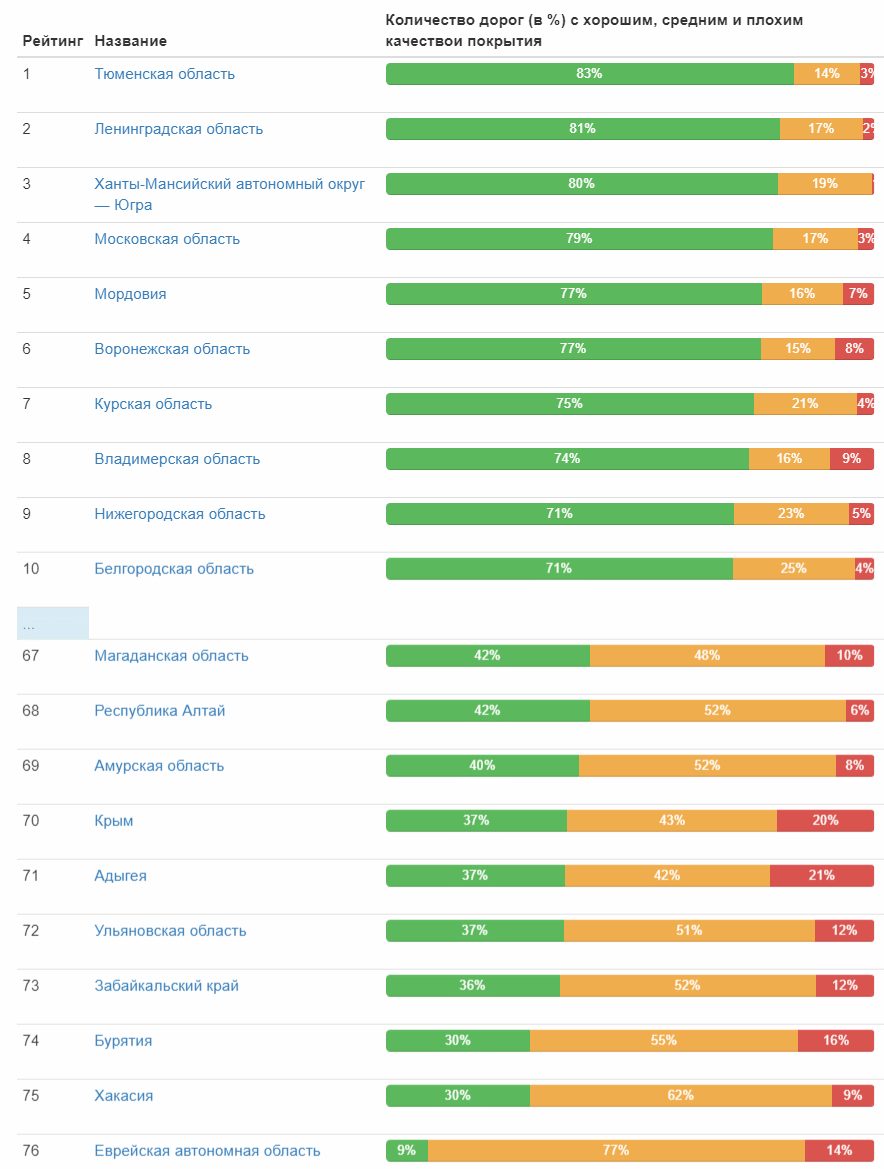
Classificação por distritos federais:
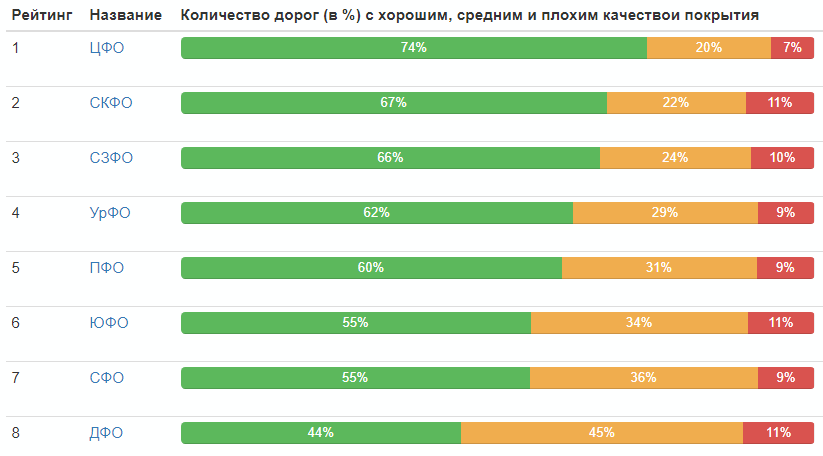
Distribuição da qualidade das estradas na Rússia como um todo:

Bem, isso é tudo, todos podem tirar conclusões pessoalmente.
Por fim, darei as melhores fotos de cada categoria (que receberam o valor máximo em sua classe):
PS Nos comentários, apontou com razão a falta de estatísticas sobre os anos de recebimento das fotografias. Eu corrijo e dou uma mesa:
Ano
| Número de fotos, peças
|
| 2008 | 37. |
| 2009 | 13 |
| 2010 | 157030 |
| 2011 | 60724 |
| 2012 | 42387 |
| 2013 | 12148
|
| 2014 | 141021
|
| 2015 | 46143
|
| 2016 | 410385
|
| 2017 | 324279
|
| 2018 | 581961
|