Números de latência que todo programador deve saber - uma tabela com "atrasos que todo programador deve conhecer". Ele contém os valores médios de tempo para executar operações básicas do computador em 2012. Existem várias visualizações alternativas para esta tabela, e aqui está uma delas.
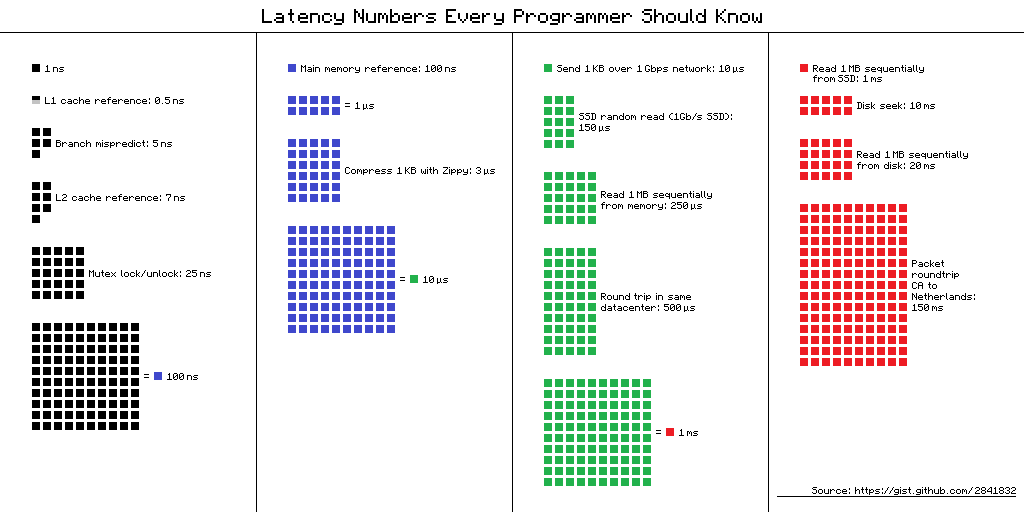 Link para a fonte do esquema
Link para a fonte do esquemaMas qual é o benefício para desenvolvedores móveis dessas informações em 2019? Parece que não, mas
Dmitry Kurkin (
SClown ), da equipe Yandex.Navigator, pensou: “Como seria a mesa para um iPhone moderno?” O que aconteceu, em uma versão de texto revisada do relatório de Dmitry no
AppsConf .
Para que é isso?
Por que os programadores devem conhecer esses números? E eles são relevantes para desenvolvedores móveis? Existem duas tarefas principais que podem ser resolvidas com a ajuda desses números.
Compreendendo a escala de tempo de um computador
Tome uma situação simples - uma conversa telefônica. Podemos dizer com facilidade quando esse processo é rápido e quando é longo: alguns segundos são muito rápidos, alguns minutos são uma conversa comum e uma hora ou mais é muito longa. Com o carregamento das páginas, é semelhante: em menos de um segundo - rapidamente, alguns segundos - suportável e um minuto é um desastre, o usuário pode não esperar pelo download.
Mas e operações como adicionar um número a uma matriz - a inserção rápida que as pessoas às vezes gostam de falar em entrevistas? Quanto custa um smartphone? Nanossegundos, microssegundos ou milissegundos? Eu conheci poucas pessoas que poderiam dizer que 1 milissegundo é muito tempo, mas no nosso caso é assim.
A proporção da velocidade de vários componentes do computador
O tempo de execução das operações em vários dispositivos pode variar em dezenas ou centenas de vezes. Por exemplo, o tempo de acesso à memória principal é 100 vezes diferente do acesso ao cache L1. Esta é uma grande diferença, mas não infinita. Se tivermos um significado específico para isso, ao otimizar nossos aplicativos, podemos avaliar se haverá um ganho de tempo ou não.

"Números de latência" na vida real
Quando vi esses números, fiquei interessado na diferença entre o cache e o acesso à memória. Se eu colocar meus dados com cuidado em 64 Kbytes, que não são tão pequenos, meu código funcionará 100 vezes mais rápido - é rápido, tudo voará!

Eu imediatamente quis verificar tudo, mostrá-lo aos meus colegas e aplicá-lo sempre que possível. Decidi começar com a ferramenta padrão que a Apple oferece - XCTest com measureBlock. O teste foi organizado da seguinte maneira: alocou uma matriz, preencheu-a com números, seus XOR'il e repetiu o algoritmo 10 vezes, com certeza. Depois disso, observei quanto tempo leva para um elemento.
| Tamanho do buffer | Tempo total | Hora da cirurgia |
| 50 kb | 1,5 ms | 30 ns |
| 500 kb | 12 ms | 24 ns |
| 5000 kb | 85 ms | 17 ns |
O tamanho do buffer aumentou 100 vezes, e o tempo para a operação não apenas não aumentou 100 vezes, mas diminuiu quase 2 vezes.
Senhores, oficiais, eles nos traiu ?!Após esse resultado, surgiram grandes dúvidas em mim de que esses números podem ser vistos na vida real. Pode não ser possível para um aplicativo regular perceber essa diferença. Ou talvez na plataforma móvel tudo esteja diferente.
Comecei a procurar uma maneira de ver a diferença no desempenho entre caches e memória principal. Durante a pesquisa, me deparei com um artigo em que o autor reclamou que ele tinha uma referência em execução no seu Mac e iPhone e não mostrou esses atrasos. Peguei essa ferramenta e obtive o resultado - assim como em uma farmácia. O tempo de acesso à memória aumentou bastante quando o tamanho do buffer excedeu o tamanho do cache correspondente.
 O LMbench
O LMbench me ajudou a obter esses resultados. Este é um benchmark criado por Larry McVoy, um dos desenvolvedores do kernel Linux, que permite medir o tempo de acesso à memória, o custo da troca de threads e operações do sistema de arquivos e até o tempo que as principais operações do processador levam: adição, subtração, etc. De acordo com este benchmark A Texas Instruments apresentou
dados de medição
interessantes para seus processadores. O LMBench está escrito em C, por isso não foi difícil executá-lo no iOS.
Custos de memória
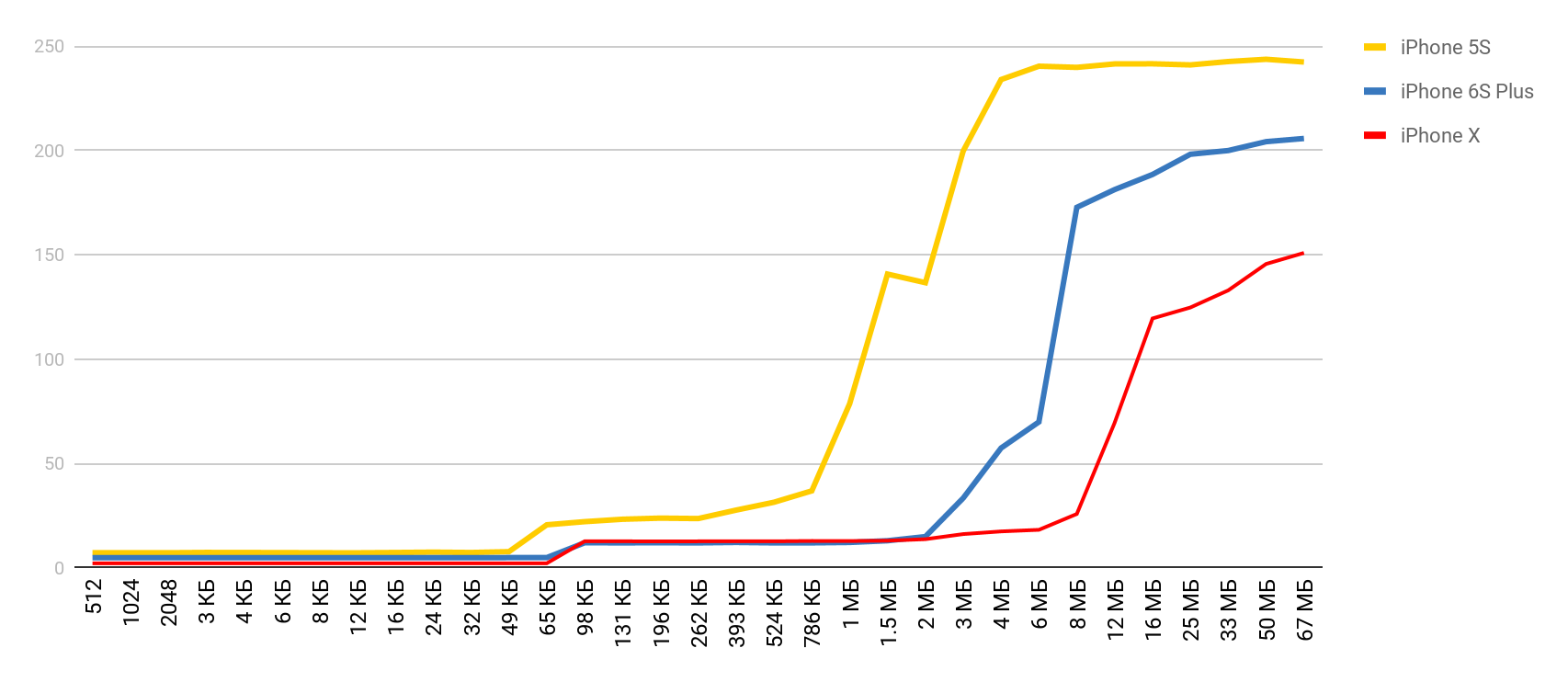
Armado com uma ferramenta tão maravilhosa, decidi fazer medições semelhantes, mas para um dispositivo móvel real - para o iPhone. As principais medidas foram feitas no 5S e, em seguida, obtive os resultados quando outros dispositivos caíram em minhas mãos. Portanto, se o dispositivo não for especificado, será 5S.
Acesso à memória
Para este teste, é usada uma matriz especial, que é preenchida com elementos que se referem um ao outro. Cada um dos elementos é um ponteiro para outro elemento. A matriz não é atravessada pelo índice, mas pelas transições de um nó para outro. Esses elementos estão espalhados por toda a matriz, de modo que, ao acessar um novo elemento, sempre que possível, ele não estava no cache, mas era descarregado da RAM. Esse arranjo interfere nos caches o máximo possível.
Você já viu o resultado preliminar. No caso do cache L1, é inferior a 10 nanossegundos, para L2 são algumas dezenas de nanossegundos e, no caso da memória principal, o tempo aumenta para centenas de nanossegundos.
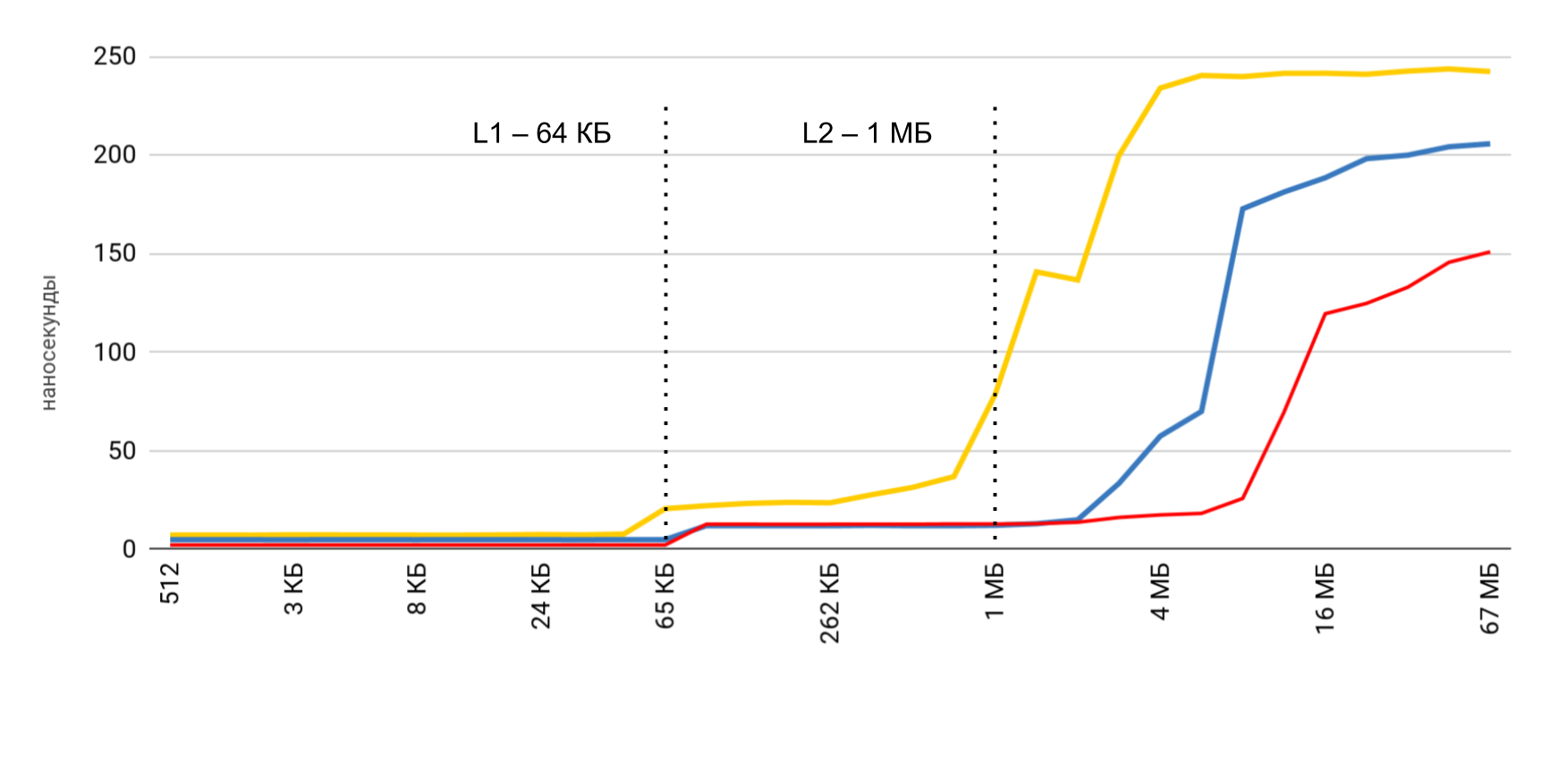
Velocidade de leitura e gravação
Três operações principais são medidas:
- leitura ( p [i] + ) - lemos os elementos e os adicionamos ao valor total;
- registro ( p [i] = 1 ) - um número constante é escrito em cada elemento;
- leitura e escrita ( p [i] = p [i] * 2 ) - retiramos o elemento, alteramos e escrevemos o novo valor de volta.
Ao trabalhar com o buffer, duas abordagens são usadas: no primeiro caso, apenas cada quarto elemento é usado e, no segundo, todos os elementos são seqüenciais.
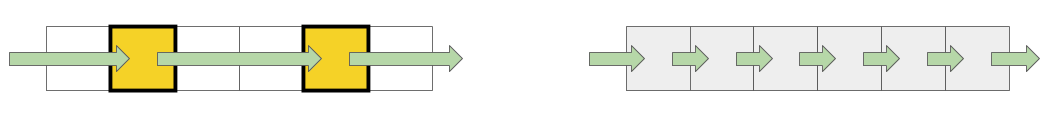
A velocidade mais alta é obtida com um tamanho de buffer pequeno e, em seguida, há etapas claras, de acordo com os tamanhos dos caches L1 e L2. O mais interessante é que, quando os dados são lidos sequencialmente, não ocorre redução de velocidade. Mas no caso de passes, etapas claras são visíveis.
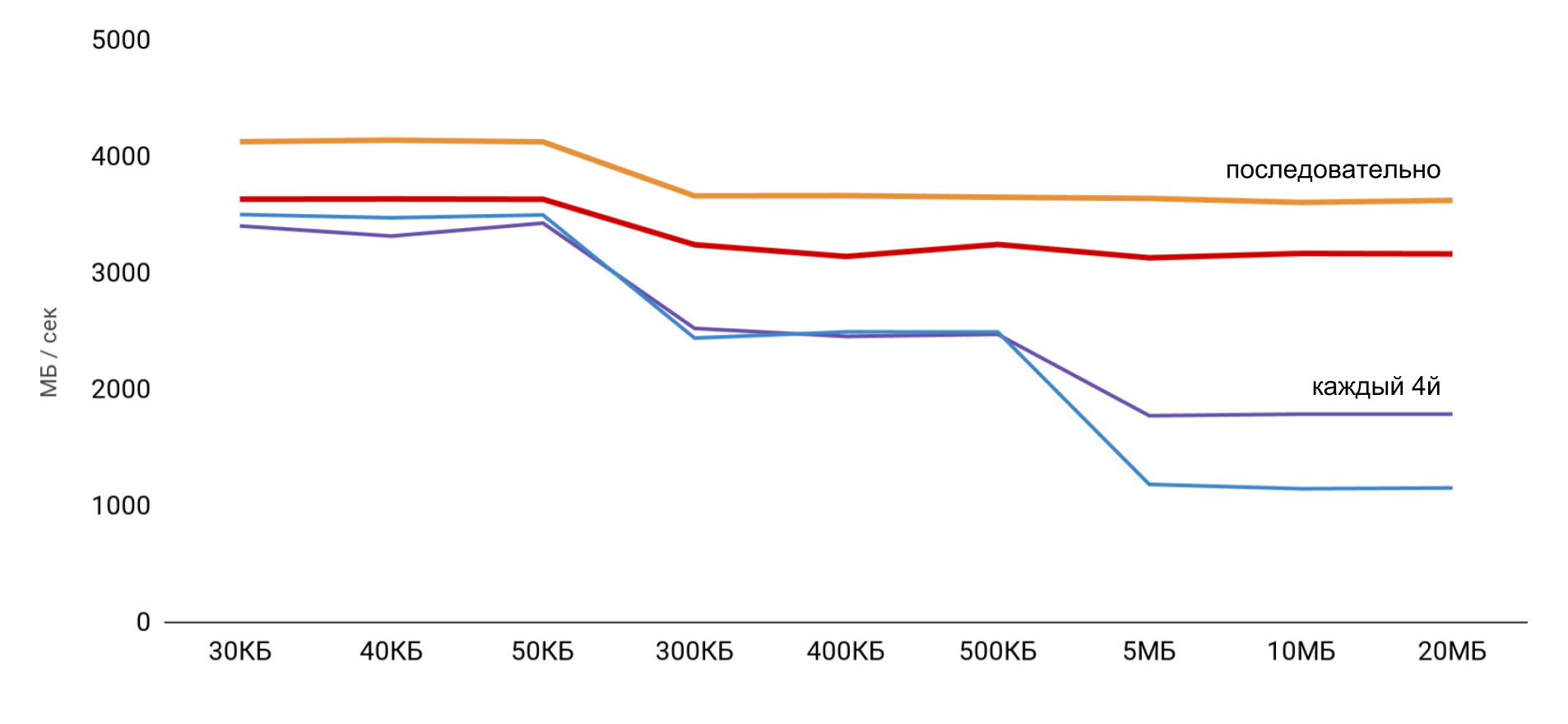
Durante a leitura seqüencial, o sistema operacional consegue carregar os dados necessários no cache, portanto, para qualquer tamanho de buffer, não preciso acessar a memória - todos os dados necessários são obtidos no cache. Isso explica por que não vi a diferença horária no meu teste básico.
Os resultados das medições das operações de leitura e gravação mostraram que em uma aplicação normal é bastante difícil obter a aceleração estimada de 100 vezes. Por um lado, o próprio sistema armazena em cache os dados muito bem e, mesmo com grandes matrizes, é muito provável que encontremos dados no cache. Por outro lado, trabalhar com várias variáveis pode facilmente exigir acesso à memória e a perda de centenas de nanossegundos conquistados.
| L1 | L2 | Memória |
| Números de latência | 1 ns | 7 ns | 100 ns |
| iPhone 5s | 7 ns | 30 ns | 240 ns |
| iPhone 6s Plus | 5 ns | 12 ns | 200 ns |
| iPhone X | 2 ns | 12 ns | 146 ns |
Custos de rosqueamento
Em seguida, queria obter dados semelhantes para trabalhar com threads, a fim de
entender o custo do uso de multithreading : quanto custa criar uma thread e alternar de uma thread para outra. Para nós, essas são operações frequentes e quero entender a perda.
Instrumentos. Rastreio do sistema
O System Trace ajuda muito a rastrear o trabalho dos threads no aplicativo. Esta ferramenta foi descrita em alguns detalhes na
WWDC 2016 . A ferramenta ajuda a ver transições por condições de fluxo e apresenta dados sobre fluxos em três categorias principais: chamadas do sistema, trabalhando com condições de memória e fluxo.
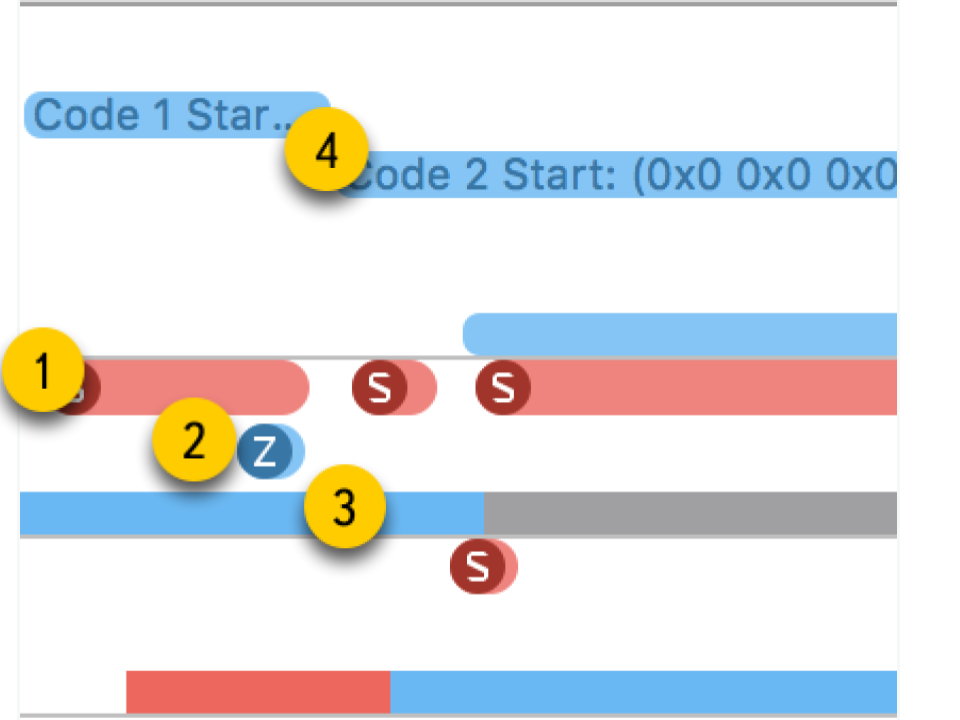
- Chamadas do sistema Eles são apresentados na forma de "salsichas" vermelhas. Quando você os aponta, pode ver o nome do método do sistema e a duração da execução. Freqüentemente, em aplicativos de aplicativos, essa chamada de sistema não ocorre diretamente: usamos algo que, por sua vez, já chama o método de sistema. Você não deve confiar no fato de que aqui os métodos do seu código estarão visíveis.
- Operações de memória . Eles são apresentados na forma de "salsichas" azuis. Isso inclui operações como alocação de memória, liberação, zeramento, etc.
- Status do fluxo . Cor azul - um segmento está sendo executado, algum processador está executando o código desse segmento. Cinza - o encadeamento está bloqueado por algum motivo e não pode continuar a execução. Vermelho - o thread está pronto para funcionar, mas neste momento não há kernel livre para executar seu código. Cor laranja - o fluxo é interrompido para trabalhos com prioridade mais alta.
- Pontos de interesse . Esses são rótulos especiais que podem ser organizados por código chamando
kdebug_signpost . Os rótulos podem ser únicos (um local específico no código) ou como um intervalo (para destacar todo o procedimento). Usando esses rótulos, é muito mais fácil correlacionar microssegundos e chamadas do sistema com seu aplicativo.
Custos de criação de stream
O primeiro teste é a
execução de uma tarefa em um novo thread . Criamos um encadeamento com um determinado procedimento e esperamos que ele conclua seu trabalho. Comparando o tempo total com o tempo do próprio procedimento, obtemos a perda total para iniciar o procedimento em um novo encadeamento.
No System Trace, você pode ver claramente como tudo realmente acontece:
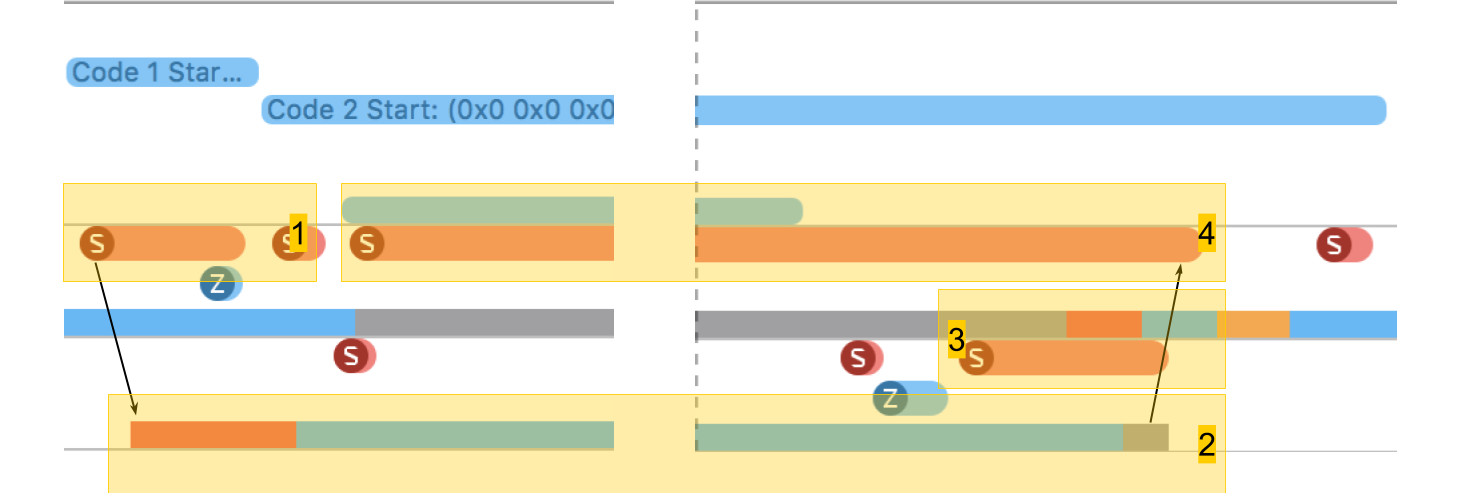
- Crie fluxo.
- O novo encadeamento no qual nosso procedimento é executado. A zona vermelha no início diz que o encadeamento foi criado, mas por algum tempo não pôde ser executado, pois não havia núcleo livre.
- A conclusão do fluxo. Curiosamente, o próprio procedimento de conclusão de encadeamento é ainda maior que sua criação. Embora pareça que a exclusão seja sempre mais rápida.
- Aguardando a conclusão do procedimento, que estava no esquema original, e termina após o término do fluxo - por um tempo o método percebe isso e, depois disso, relatórios. Esse tempo é um pouco mais longo que a conclusão do fluxo.
Como resultado, a criação de um fluxo requer custos bastante significativos: iPhone 5S - 230 microssegundos, 6S - 50 microssegundos.
A conclusão do fluxo leva quase duas vezes mais tempo que a criação ; a junção também leva um tempo tangível. Ao trabalhar com memória, obtivemos centenas de nanossegundos, que são 100 vezes menos que dezenas de microssegundos.
| sobrecarga | criar | fim | juntar |
| iPhone 5s | 230 μs | 40 μs | 70 μs | 30 μs |
| iPhone 6s Plus | 50 μs | 12 μs | 20 μs | 7 μs |
Tempo de comutação do semáforo
O próximo teste é
medições no trabalho do semáforo . Temos 2 threads pré-criados, e para cada um deles existe um semáforo. Os córregos sinalizam alternadamente o semáforo do vizinho e esperam pelo seu. Passando sinais um para o outro, os fluxos jogam pingue-pongue, revivem um ao outro. Essa iteração dupla fornece tempo de comutação de semáforo duplo.
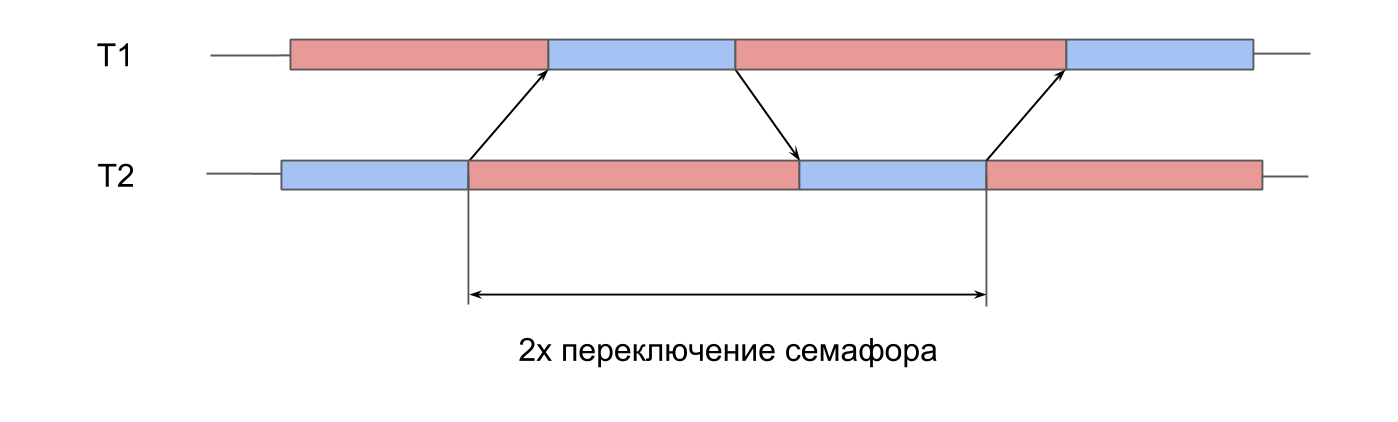
No System Trace, tudo parece semelhante:
- Um sinal é dado para o semáforo do segundo fluxo. Pode-se ver que esta operação é muito curta.
- O segundo segmento é desbloqueado, a espera no seu semáforo termina.
- Um sinal é dado para o semáforo do primeiro fluxo.
- O primeiro encadeamento é desbloqueado, a espera em seu semáforo termina.
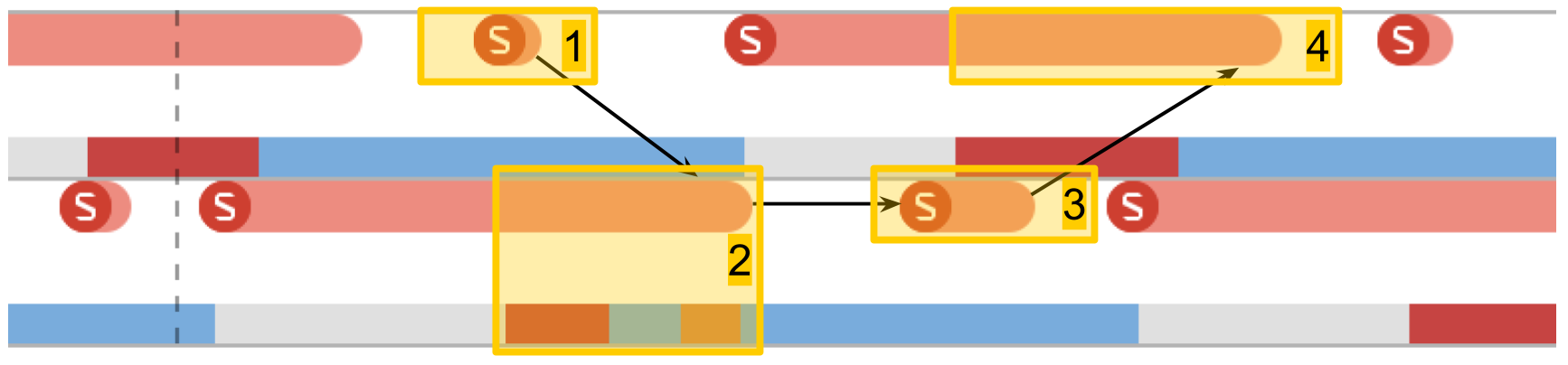
O tempo de troca foi de 10 microssegundos. A diferença de criar um encadeamento 50 vezes é exatamente o motivo pelo qual os conjuntos de encadeamentos são criados, e não um novo encadeamento para cada procedimento.
Perdas na alternância de contexto do encadeamento do sistema
Nos dois testes anteriores, a transferência de controle entre os threads foi completamente controlada - entendemos claramente onde e onde a transição deveria ocorrer. No entanto, muitas vezes acontece que o próprio sistema alterna de um thread para outro. Quando executamos mais tarefas em paralelo do que os núcleos do dispositivo, o sistema operacional deve poder mudar automaticamente para fornecer a todos tempo de processador.
Neste teste, eu queria medir a perda de iniciar muitos threads. Para isso, é criado um pool de 16 threads, cada um aguardando um semáforo e, assim que recebe um sinal, executa um determinado procedimento e sinaliza o semáforo de volta. O thread principal inicia o pool inteiro, emitindo 16 sinais e depois espera 16 sinais em resposta.
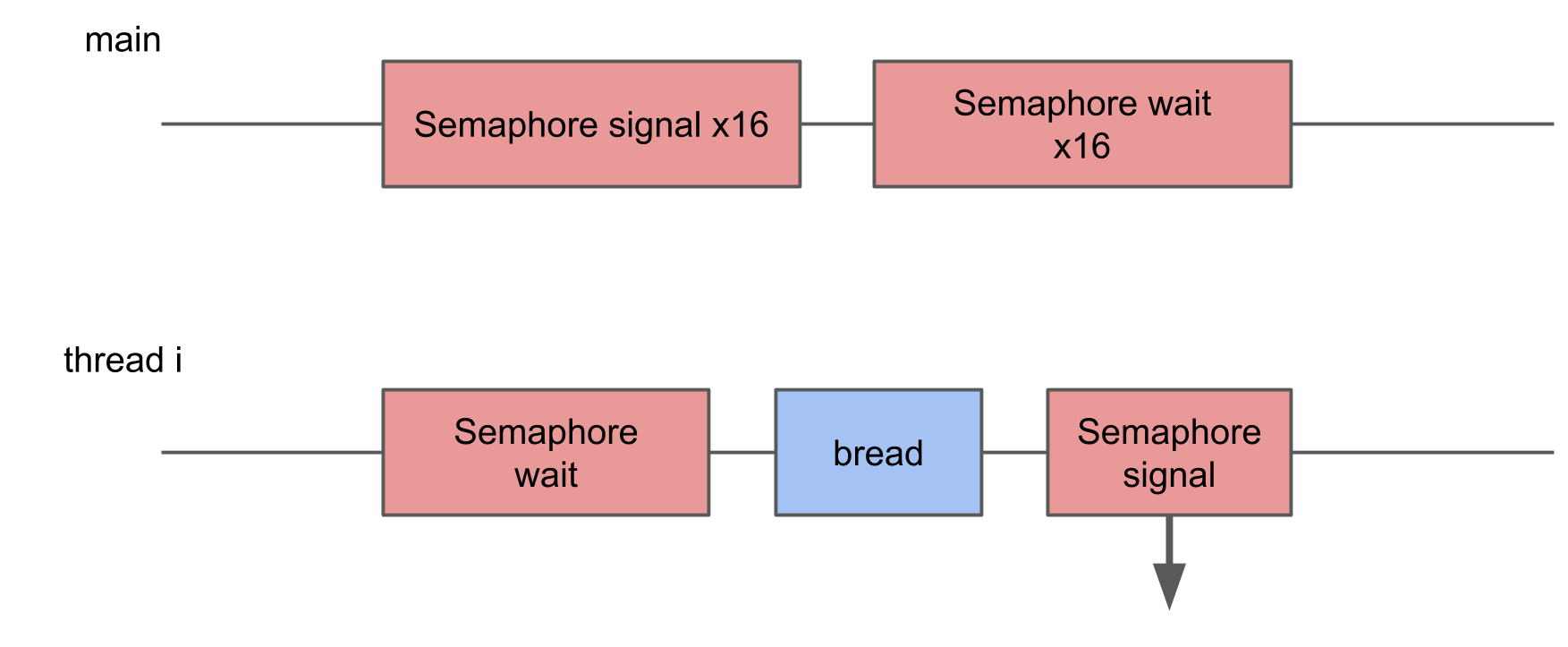
No System Trace, você pode ver que os blocos estão espalhados aleatoriamente, alguns deles são muito mais longos que os demais. Se várias comutações levarem a um aumento no tempo de execução da operação, o tempo médio de execução deverá aumentar como resultado.
No entanto, com um aumento no número de threads, o tempo médio de operação não aumenta.Em teoria, o tempo médio deve ser mantido enquanto a carga corresponder à potência de processamento. Ou seja, o número de tarefas corresponde ao número de núcleos.
Se você executar muitas tarefas em paralelo, o sistema operacional, alternando de uma tarefa para outra, apresentará atrasos adicionais. Isso deve se refletir no resultado.
Na prática, não apenas nosso aplicativo funciona no dispositivo, mas ainda possui muitos processos paralelos e de sistema. Até o único thread em nosso aplicativo será afetado pela alternância, o que leva a interrupções e atrasos. Portanto, em todas as situações, há atrasos e não há diferença entre criar tarefas em série ou executar em paralelo.

Abaixo está nossa tabela de números de latência com dados sobre fluxos e semáforos.
| L1 | L2 | Memória | Semáforo |
| Números de latência | 1 ns | 7 ns | 100 ns | 25 ns |
| iPhone 5s | 7 ns | 30 ns | 240 ns | 8 μs |
| iPhone 6s Plus | 5 ns | 12 ns | 200 ns | 5 μs |
| iPhone X | 2 ns | 12 ns | 146 ns | 3,2 μs |
Custos de arquivo
Já temos memória e threads - para completar, precisamos apenas de operações do sistema de arquivos.
Ler arquivo
O primeiro teste é a
velocidade de leitura - quanto custa ler um arquivo. O teste consiste em duas partes. Na primeira,
medimos a velocidade de leitura, levando em consideração a abertura, leitura e fechamento do arquivo. No segundo,
assumimos que o arquivo está constantemente aberto : nos posicionamos em algum lugar e lemos o quanto queremos.
Os resultados são exibidos corretamente de dois pontos de vista.
Quando o arquivo é pequeno , há um tempo mínimo para ler os dados do arquivo. Até um kilobyte é de 5,3 microssegundos - não importa: 1 byte, 2 ou 1 KB - para todos os 5,3 μs. Portanto, você pode falar sobre velocidade apenas no caso de arquivos grandes, quando o tempo fixo já pode ser negligenciado. A operação para abrir e fechar o arquivo leva aproximadamente o mesmo tempo para qualquer tamanho de arquivo - no caso do 5S, cerca de 50 microssegundos.
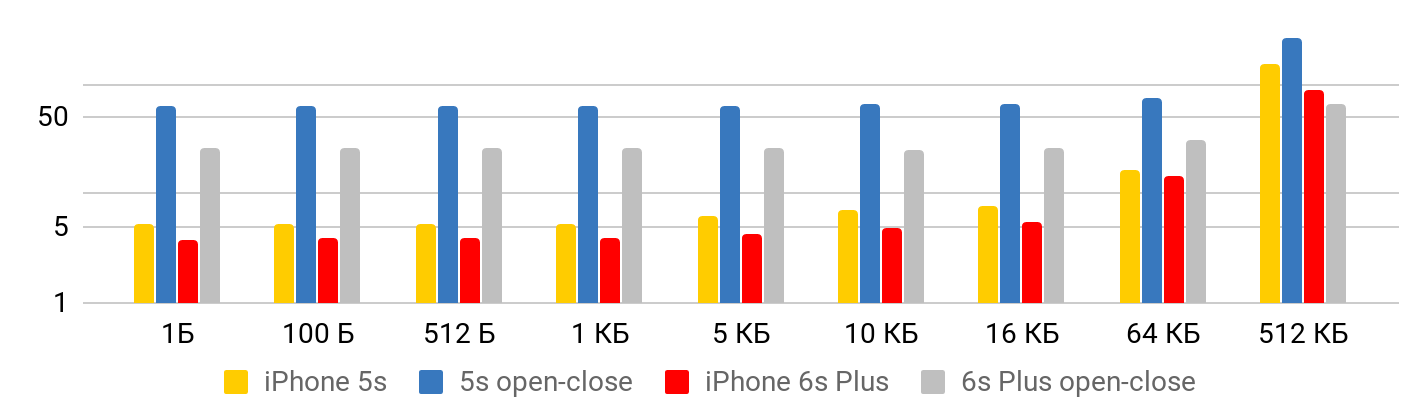
Para velocidade de leitura, esses gráficos são obtidos.
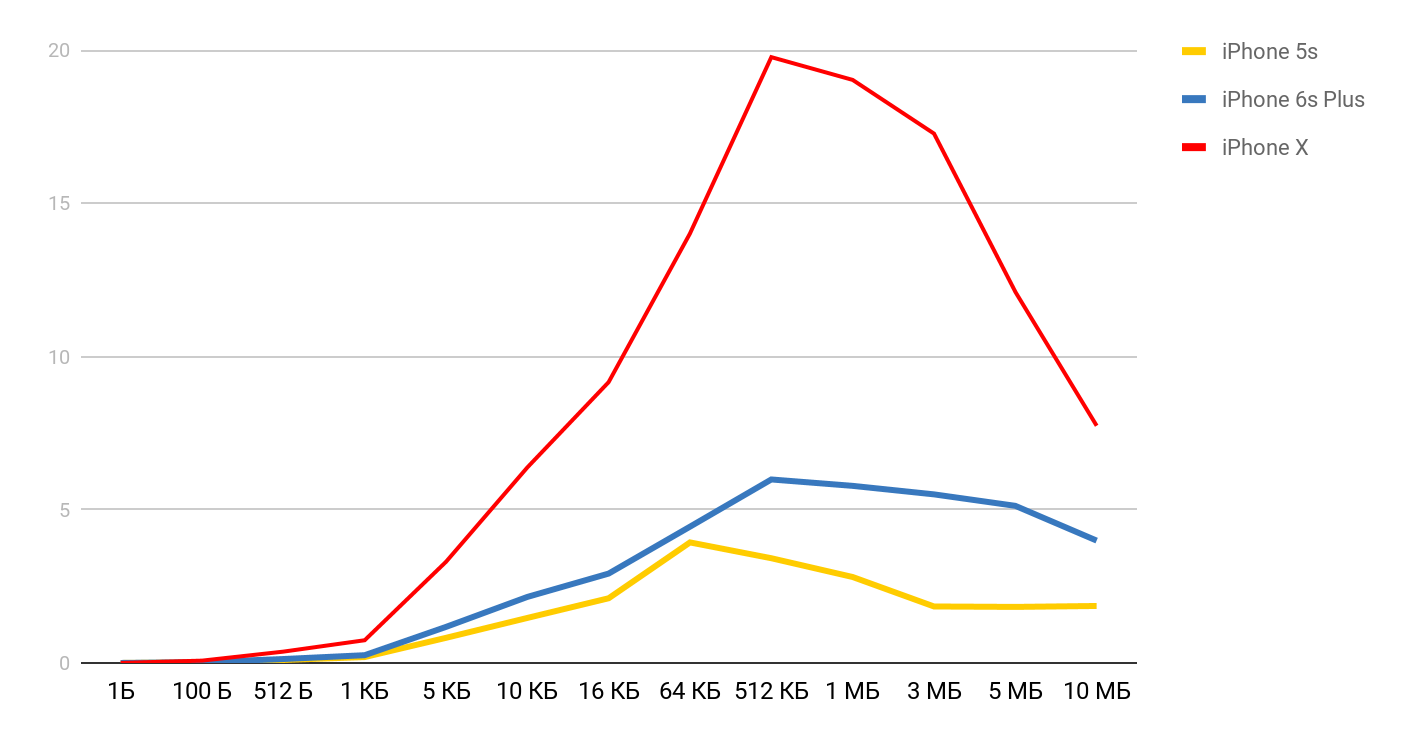
Para o iPhone X e um arquivo de 1 MB, a velocidade pode chegar a 20 MB / s. Curiosamente, a leitura de um arquivo de 1 MB é mais eficiente. Com tamanhos grandes de arquivo, os tamanhos de cache parecem ser afetados. É por isso que a velocidade diminui ainda mais e se equilibra na região de 10 Mb.
Crie e exclua arquivos
O teste consiste na etapa de
criação de um arquivo, gravação de dados e
exclusão dos arquivos criados. O resultado é gradual: em tamanhos pequenos, o tempo é estável - cerca de 7 μs e continua crescendo. A escala é logarítmica.
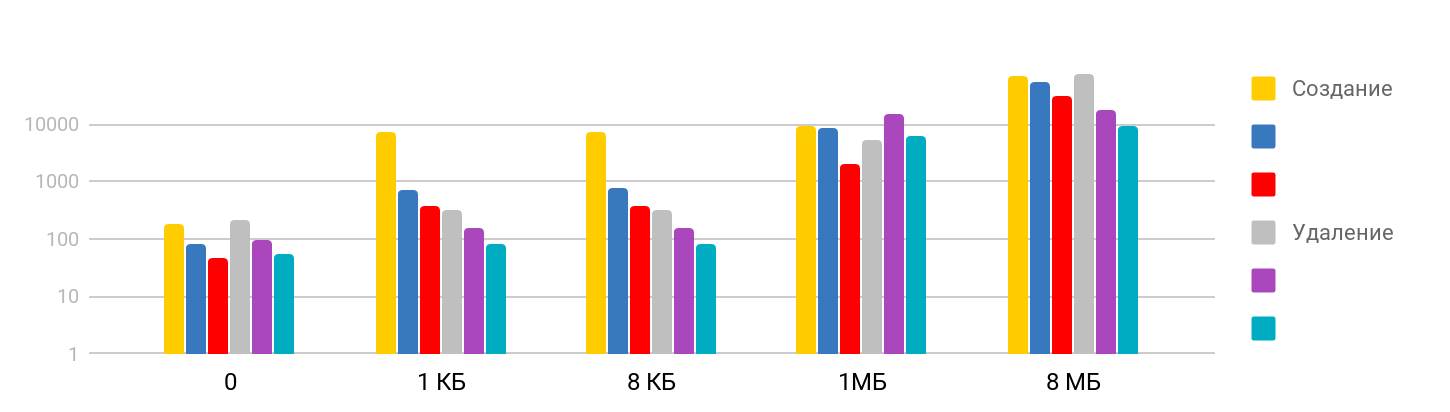
Fiquei surpreso que o tempo necessário para excluir um arquivo grande seja proporcional ao tempo necessário para criar, pois eu supus que a exclusão seja uma operação rápida. Acontece que não, para o iPhone, a exclusão a tempo é comparável à criação de um arquivo. A tabela de resumo fica assim.
| L1 | L2 | Memória | Semáforo | Disco |
| Números de latência | 1 ns | 7 ns | 100 ns | 25 ns | 150 μs |
| iPhone 5s | 7 ns | 30 ns | 240 ns | 8 μs | 5 μs |
| iPhone 6s Plus | 5 ns | 12 ns | 200 ns | 5 μs | 4 μs |
| iPhone X | 2 ns | 12 ns | 146 ns | 3,2 μs | 1,3 μs |
Conclusão
Com base nessas medições, agora temos uma idéia de quanto tempo as operações básicas do iOS exigem: acessar a memória em nanossegundos, trabalhar com arquivos em microssegundos, criar um fluxo em dezenas de microssegundos e alternar em apenas alguns microssegundos.
Para obter uma interrupção fisicamente visível no aplicativo, o tempo de execução do procedimento deve exceder 15 milissegundos (o tempo necessário para atualizar a tela a 60fps). Isso é quase mil vezes maior que a maioria das medições feitas no artigo. Nessa escala, um milissegundo é bastante, e um segundo já é "para sempre".
Os testes mostraram que, apesar da grande diferença no tempo de acesso à memória e aos caches, o uso direto dessa taxa é bastante difícil. Antes de compilar todos os seus dados no L1, você precisa garantir que, no seu caso, realmente dê um resultado.
De acordo com os testes de operações com encadeamentos, fomos capazes de garantir que a criação e destruição de encadeamentos demandem um tempo considerável, mas a execução de um grande número de operações paralelas não gera custos adicionais.
Bem, para concluir, gostaria de lembrá-lo da regra mais importante ao trabalhar no desempenho -
primeiras medições e somente então otimização !
Orador de perfil Dmitry Kurkin no
GitHub .
A conversão e transformação dos relatórios do AppsConf 2018 em artigos é paralela à preparação da nova conferência de 2019. Até o momento, existem apenas 7 tópicos na lista de relatórios aceitos , mas essa lista será expandida o tempo todo para que ocorra uma conferência interessante para desenvolvedores móveis nos dias 22 e 23 de abril .
Siga as publicações, assine o canal do youtube e o boletim informativo, e dessa vez voará rapidamente.