Carros não tripulados não podem prescindir do que está ao redor e onde exatamente. Em dezembro do ano passado, o desenvolvedor Viktor Otliga
vitonka fez uma apresentação sobre a detecção de objetos 3D na
árvore de dados-Natal . Victor trabalha na direção de veículos não tripulados Yandex, no grupo que lida com a situação do trânsito (e também ensina na SHAD). Ele explicou como resolvemos o problema de reconhecer outros usuários da estrada em uma nuvem de pontos tridimensional, como esse problema difere do reconhecimento de objetos em uma imagem e como se beneficiar do compartilhamento de diferentes tipos de sensores.
- Olá pessoal! Meu nome é Victor Otliga, trabalho no escritório da Yandex em Minsk e estou desenvolvendo veículos não tripulados. Hoje vou falar sobre uma tarefa bastante importante para os drones - o reconhecimento de objetos 3D ao nosso redor.

Para pedalar, você precisa entender o que está ao redor. Vou lhe dizer brevemente quais sensores e sensores são usados em veículos não tripulados e quais usamos. Vou lhe dizer qual é a tarefa de detectar objetos 3D e como medir a qualidade da detecção. Então vou lhe dizer em que medida essa qualidade pode ser medida. Depois, farei uma breve revisão de bons algoritmos modernos, incluindo aqueles nos quais nossas soluções se baseiam. E no final - pequenos resultados, uma comparação desses algoritmos, incluindo o nosso.

É assim que o nosso protótipo de trabalho de um carro não tripulado se parece agora. Esse táxi pode ser alugado por qualquer pessoa sem motorista na cidade de Innópolis, na Rússia, e também em Skolkovo. E se você olhar de perto, há um grande dado no topo. O que tem lá dentro?

Dentro de um conjunto simples de sensores. Existe uma antena GNSS e GSM para determinar onde o carro está e se comunicar com o mundo exterior. Onde sem um sensor tão clássico como uma câmera. Mas hoje estaremos interessados em lidares.


Lidar produz aproximadamente uma nuvem de pontos ao seu redor, com três coordenadas. E você tem que trabalhar com eles. Vou lhe dizer como, usando uma imagem de câmera e uma nuvem lidar, para reconhecer qualquer objeto.
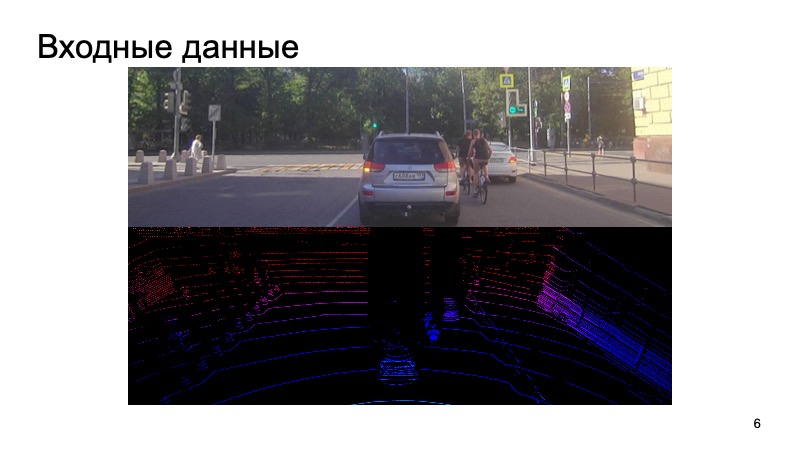
Qual é o desafio? A imagem da câmera entra na entrada, a câmera é sincronizada com o lidar. Seria estranho usar a imagem da câmera um segundo atrás, tirar a nuvem do lidar de um momento completamente diferente e tentar reconhecer objetos nela.

De alguma forma, sincronizamos câmeras e lidares, essa é uma tarefa difícil, mas conseguimos lidar com isso com êxito. Esses dados entram na entrada e, no final, queremos obter caixas, caixas delimitadoras que limitam o objeto: pedestres, ciclistas, carros e outros usuários da estrada e não apenas.
A tarefa foi definida. Como vamos avaliar isso?

O problema do reconhecimento 2D de objetos em uma imagem tem sido amplamente estudado.
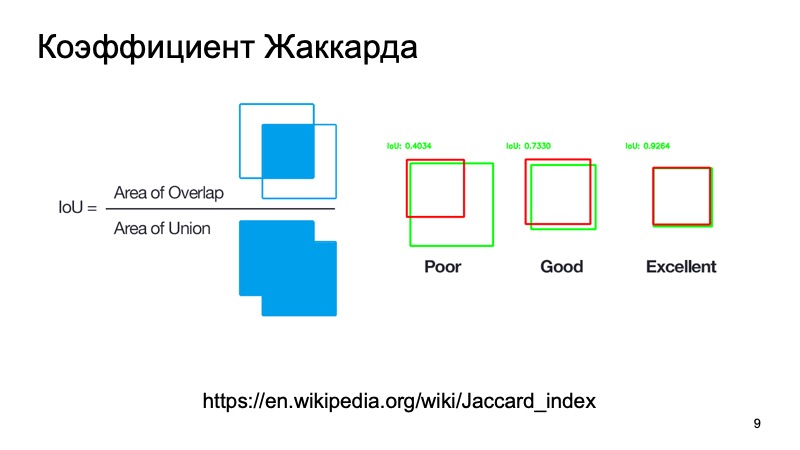
Você pode usar métricas padrão ou seus análogos. Existe um coeficiente de jacquard ou interseção sobre a união, um maravilhoso coeficiente que mostra o quão bem detectamos um objeto. Podemos pegar uma caixa onde, como supomos, o objeto está localizado e uma caixa onde ele está realmente localizado. Conte essa métrica. Existem limiares padrão - digamos que para carros, eles costumam ter um limiar de 0,7. Se esse valor for maior que 0,7, acreditamos que detectamos com sucesso o objeto, que o objeto está lá. Nós somos ótimos, podemos ir mais longe.
Além disso, para detectar um objeto e entender que ele está em algum lugar, gostaríamos de ter algum tipo de confiança de que realmente vemos o objeto lá e medi-lo também. Você pode medir de forma simples, considerar a precisão média. Você pode pegar a curva de recuperação de precisão e a área abaixo dela e dizer: quanto maior, melhor.
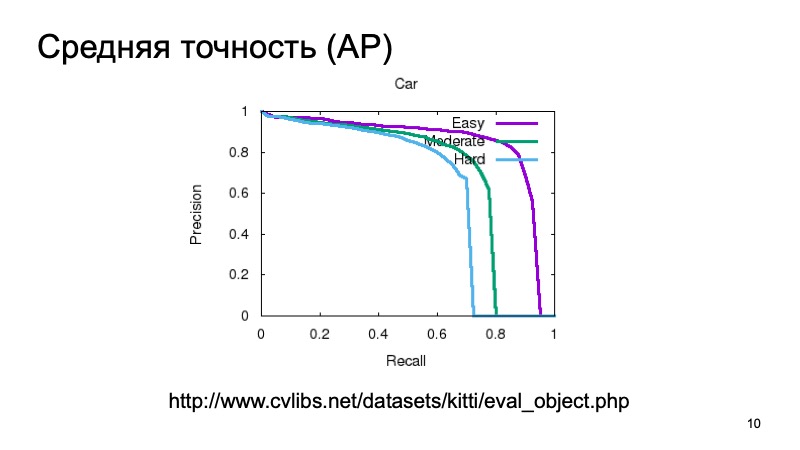
Geralmente, para medir a qualidade da detecção 3D, eles pegam um conjunto de dados e o dividem em várias partes, porque os objetos podem ser próximos ou mais distantes, podem ser parcialmente obscurecidos por outra coisa. Portanto, a amostra de validação geralmente é dividida em três partes. Objetos fáceis de detectar, de média complexidade e complexos, distantes ou muito ocultos. E eles medem separadamente em três partes. E nos resultados da comparação, também faremos essa partição.
Você pode medir a qualidade como em 3D, um análogo da interseção sobre a união, mas não a proporção de áreas, mas, por exemplo, volumes. Mas, por regra, um carro não tripulado não se importa com o que está acontecendo na coordenada Z. Podemos ter uma visão aérea de cima e usar algum tipo de métrica, como se estivéssemos assistindo tudo em 2D. O homem é navegado mais ou menos em 2D, e um veículo não tripulado é o mesmo. Qual a altura da caixa não é muito importante.

O que medir?

Provavelmente todos que pelo menos de alguma forma enfrentaram a tarefa de detectar em 3D pela nuvem lidar ouviram sobre um conjunto de dados como o KITTI.

Em algumas cidades da Alemanha, um conjunto de dados foi gravado, um carro equipado com sensores foi, tinha sensores GPS, câmeras e lidares. Em seguida, foram marcadas cerca de 8000 cenas e divididas em duas partes. Uma parte é o treinamento, no qual todos podem treinar, e a segunda é a validação, para medir os resultados. A amostra de validação KITTI é considerada uma medida de qualidade. Em primeiro lugar, existe um quadro de líderes no site do conjunto de dados KITTI, você pode enviar sua decisão para lá, seus resultados no conjunto de dados de validação e comparar com as decisões de outros players ou pesquisadores do mercado. Mas também esse conjunto de dados está disponível publicamente, você pode fazer o download, não contar a ninguém, verificar o seu, comparar com os concorrentes, mas não fazer o upload publicamente.

Conjuntos de dados externos são bons, você não precisa gastar seu tempo e recursos com eles, mas, como regra, um carro que viajou para a Alemanha pode ser equipado com sensores completamente diferentes. E é sempre bom ter seu próprio conjunto de dados interno. Além disso, é mais difícil expandir um conjunto de dados externo à custa de outros, mas é mais fácil gerenciar o seu próprio. Portanto, usamos o maravilhoso serviço Yandex.Tolok.

Finalizamos nosso sistema de tarefas especiais. Para o usuário que deseja ajudar com a marcação e receber uma recompensa por isso, distribuímos uma foto da câmera, distribuímos uma nuvem Lidar que você pode girar, ampliar, reduzir e pedir a ele que coloque caixas que limitam nossas caixas delimitadoras para que um carro ou um pedestre entre nelas ou outra coisa. Assim, coletamos amostras internas para uso pessoal.
Suponha que tenhamos decidido qual tarefa resolveremos, como assumiremos que fizemos bem ou mal. Levamos para algum lugar os dados.
Quais são os algoritmos? Vamos começar com o 2D. A tarefa de detecção 2D é muito bem conhecida e estudada.
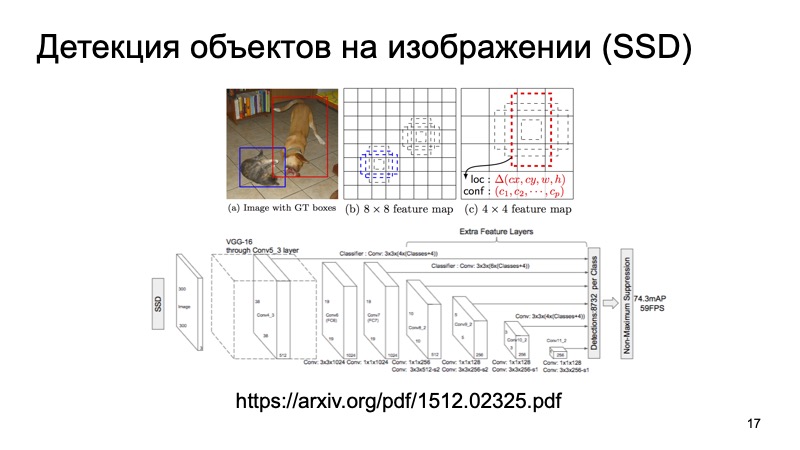
Certamente muitas pessoas conhecem o algoritmo SSD, que é um dos métodos mais avançados para detectar objetos 2D e, em princípio, podemos assumir que, de alguma forma, o problema de detectar objetos na imagem está bem resolvido. Se alguma coisa, podemos usar esses resultados como algum tipo de informação adicional.
Mas nossa nuvem lidar tem suas próprias características que a diferenciam muito da imagem. Em primeiro lugar, é muito escasso. Se a imagem é uma estrutura densa, os pixels estão próximos, tudo é denso, a nuvem é muito fina, não há muitos pontos e não possui uma estrutura regular. Puramente fisicamente, existem muito mais pontos próximos do que à distância, e quanto mais você avança, menos pontos, menor precisão, mais difícil é determinar algo.
Bem, os pontos, em princípio, da nuvem vêm em uma ordem incompreensível. Ninguém garante que um ponto será sempre anterior a outro. Eles vêm em ordem relativamente aleatória. De alguma forma, você pode concordar em classificá-los ou reordená-los antecipadamente, e só então enviar os modelos para a entrada, mas isso será bastante inconveniente, você precisará gastar tempo para alterá-los e assim por diante.
Gostaríamos de criar um sistema que seja invariável aos nossos problemas, resolva todos esses problemas. Felizmente, no ano passado, a CVPR apresentou esse sistema. Havia uma arquitetura desse tipo - PointNet. Como ela trabalha?

Uma nuvem de n pontos chega à entrada, cada um com três coordenadas. Então, cada ponto é de alguma forma padronizado por uma pequena transformação especial. Além disso, é conduzido através de uma rede totalmente conectada para enriquecer esses pontos com sinais. Então, novamente, a transformação ocorre e, no final, é enriquecida adicionalmente. Em algum momento, n pontos são obtidos, mas cada um tem aproximadamente 1024 recursos, eles são de alguma forma padronizados. Mas até agora não resolvemos o problema referente à invariância de turnos, voltas e assim por diante. Aqui, propõe-se fazer o pool máximo, obter o máximo entre os pontos em cada canal e obter um vetor de 1024 sinais, que será um descritor da nossa nuvem, que conterá informações sobre toda a nuvem. E então, com este descritor, você pode fazer muitas coisas diferentes.
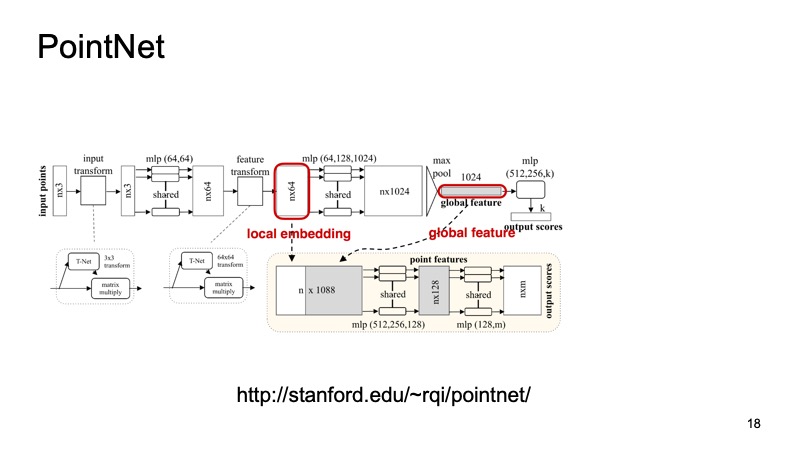
Por exemplo, você pode colá-lo aos descritores de pontos individuais e resolver o problema de segmentação, para cada ponto para determinar a qual objeto ele pertence. É apenas uma estrada ou uma pessoa ou um carro. E aqui estão os resultados do artigo.

Você pode perceber que esse algoritmo faz um bom trabalho. Gosto particularmente da mesinha em que alguns dados sobre a bancada foram jogados fora, e ele mesmo assim determinou onde estão as pernas e onde fica a bancada. E esse algoritmo, em particular, pode ser usado como um bloco para construir outros sistemas.
Uma abordagem que usa isso é a abordagem Frustum PointNets ou a abordagem de pirâmide truncada. A ideia é mais ou menos assim: vamos reconhecer objetos em 2D, somos bons em fazer isso.
Então, sabendo como a câmera funciona, podemos estimar em qual área o objeto de interesse para nós, a máquina, pode estar. Para projetar, recorte apenas essa área e já resolva o problema de encontrar um objeto interessante, por exemplo, uma máquina. Isso é muito mais fácil do que procurar qualquer número de carros na nuvem. Procurar um carro exatamente na mesma nuvem parece ser muito mais claro e mais eficiente.
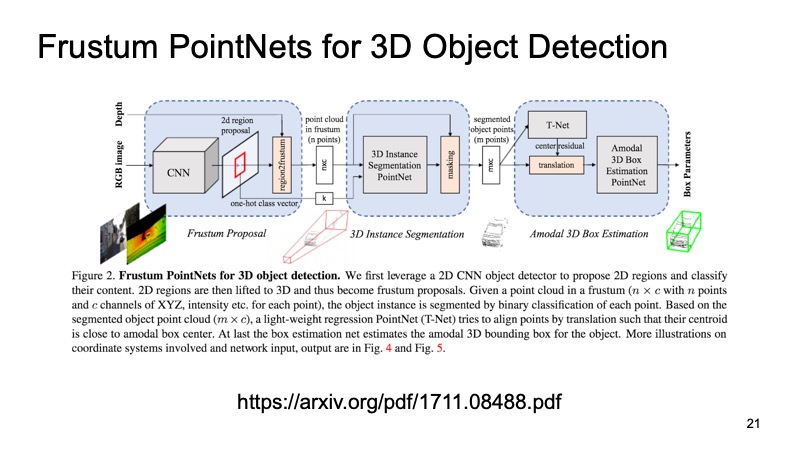
A arquitetura se parece com isso. Primeiro, de alguma forma, selecionamos as regiões que nos interessam, em cada região que fazemos segmentação, e depois resolvemos o problema de encontrar uma caixa delimitadora que limita o objeto de interesse para nós.

A abordagem se provou. Nas imagens, você pode ver que funciona muito bem, mas também tem desvantagens. A abordagem é de dois níveis, por isso pode ser lenta. Precisamos primeiro aplicar redes e reconhecer objetos 2D, depois cortar e depois resolver o problema de segmentação e alocação da caixa delimitadora em um pedaço da nuvem, para que possa funcionar um pouco devagar.
Outra abordagem. Por que não transformamos nossa nuvem em algum tipo de estrutura que se parece com uma imagem? A idéia é a seguinte: vejamos de cima e experimente a nossa nuvem lidar. Temos cubos de espaços.
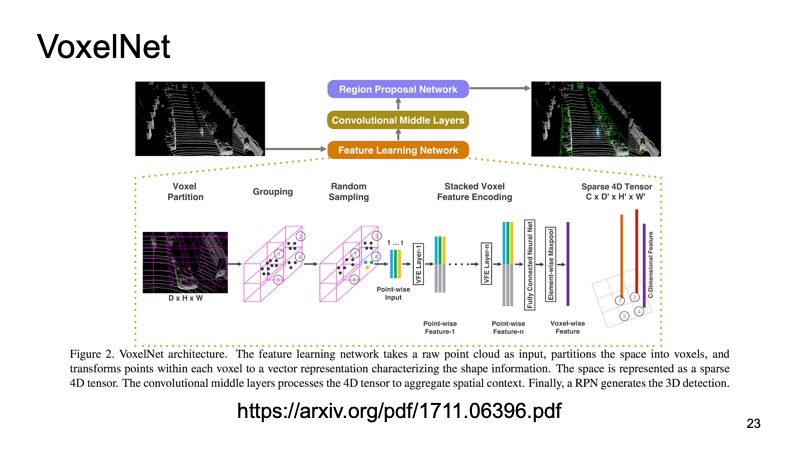
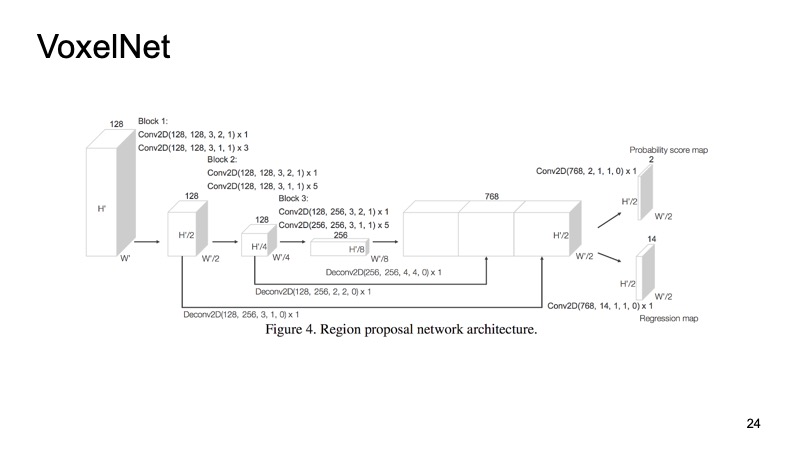
Dentro de cada cubo, temos alguns pontos. Podemos contar com alguns recursos, mas podemos usar o PointNet, que para cada parte do espaço contará algum tipo de descritor. Obteremos um voxel, cada voxel tem uma descrição característica e parecerá mais ou menos com uma estrutura densa, como uma imagem. Já podemos fazer arquiteturas diferentes, por exemplo, arquitetura semelhante a SSD para detectar objetos.
A última abordagem, que foi uma das primeiras abordagens para combinar dados de vários sensores. Seria um pecado usar apenas dados do Lidar quando também temos dados da câmera. Uma dessas abordagens é chamada de Rede de detecção de objetos 3D com várias visualizações. Sua idéia é a seguinte: alimente três canais de dados de entrada para a entrada de uma rede grande.
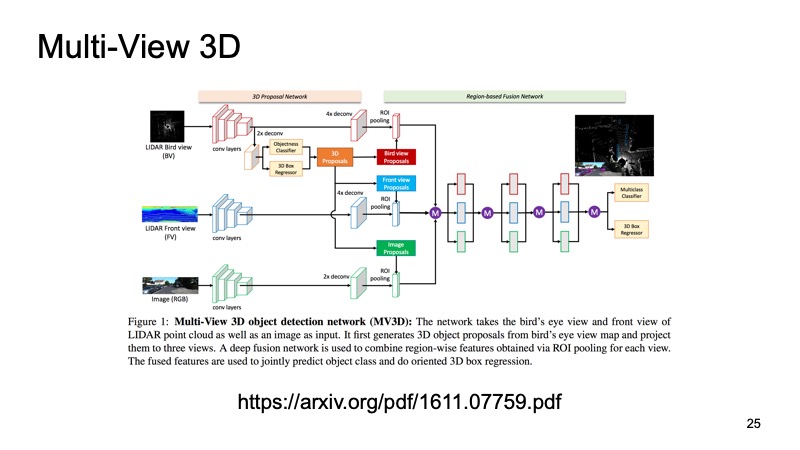
Esta é uma foto da câmera e, em duas versões, uma nuvem lidar: de cima, com uma vista aérea e algum tipo de vista frontal, o que vemos à nossa frente. Submetemos isso à entrada do neurônio, e ele configurará tudo dentro de si, nos dará o resultado final - o objeto.
Eu quero comparar esses modelos. No conjunto de dados KITTI, nas unidades de validação, a qualidade é avaliada como uma porcentagem na precisão média.
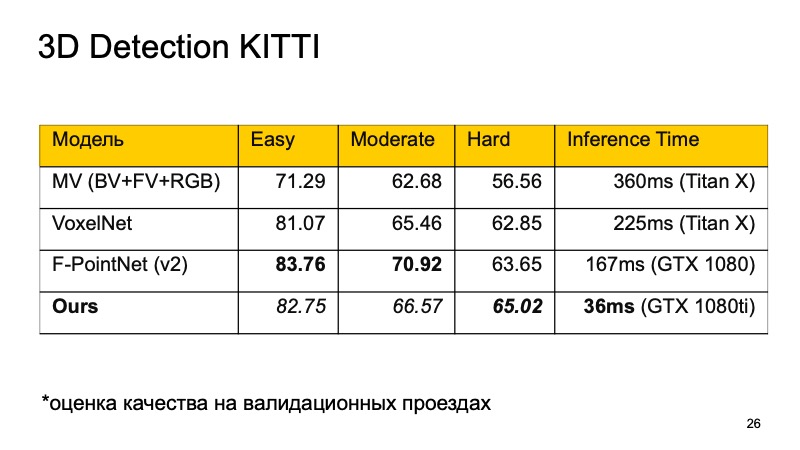
Você pode notar que o F-PointNet funciona muito bem e rápido o suficiente, supera todos os outros em diferentes áreas - pelo menos de acordo com os autores.
Nossa abordagem é baseada em mais ou menos todas as idéias que listei. Se você comparar, você obtém a seguinte imagem. Se não ocuparmos o primeiro lugar, pelo menos o segundo. Além disso, nos objetos difíceis de detectar, entramos nos líderes. E o mais importante, nossa abordagem é rápida o suficiente. Isso significa que ele já é bastante aplicável aos sistemas em tempo real e é especialmente importante para um veículo não tripulado monitorar o que está acontecendo na estrada e destacar todos esses objetos.

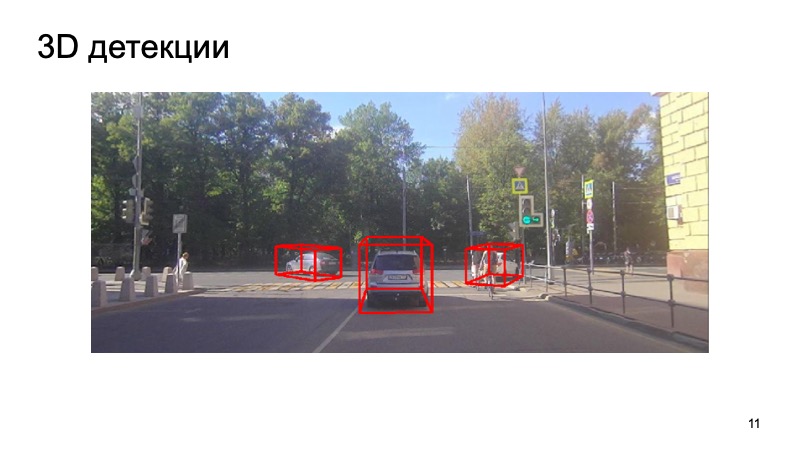
Em conclusão - um exemplo do nosso detector:
Percebe-se que a situação é complicada: alguns objetos estão fechados e outros não são visíveis para a câmera. Pedestres, ciclistas. Mas o detector lida bem o suficiente. Obrigada