Este é um novo artigo de uma
discussão de tarefas de entrevistas no Google . Quando trabalhei lá, ofereci aos candidatos essas tarefas. Houve um vazamento e eles foram banidos. Mas a moeda tem um outro lado: agora posso explicar livremente a solução.
Boas notícias para começar: eu saí do Google! Fico feliz em informar que agora estou trabalhando como gerente técnico do Reddit em Nova York! Mas essa série de artigos ainda continuará.
Isenção de responsabilidade: Embora entrevistar candidatos seja um dos meus deveres profissionais, neste blog compartilho observações pessoais, histórias e opiniões pessoais. Por favor, não considere isso uma declaração oficial do Google, Alphabet, Reddit, qualquer outra pessoa ou organização.Pergunta
Após os
dois últimos artigos sobre o progresso do cavalo na discagem de um número de telefone, recebi críticas de que este não é um problema realista. Não importa o quão útil seja estudar as habilidades de pensamento do candidato, mas devo admitir: a tarefa é realmente um pouco irrealista. Embora eu tenha algumas reflexões sobre a correlação entre as perguntas da entrevista e a realidade, eu as deixarei por enquanto. Certifique-se de ler comentários em todos os lugares e tenho algo a responder, mas não agora.
Mas quando a tarefa de passar o cavalo foi banida há vários anos, levei as críticas ao coração e tentei substituí-lo por uma pergunta um pouco mais relevante para o escopo do Google. E o que pode ser mais relevante para o Google do que a mecânica das consultas de pesquisa? Então, eu encontrei essa pergunta e a usei por um longo tempo antes que ela também se tornasse pública e fosse banida. Como antes, vou formular a pergunta, mergulhar em sua explicação e depois direi como a usei em entrevistas e por que gosto.
Então a questão é.
Imagine que você gerencia um mecanismo de pesquisa popular e vê duas solicitações nos registros: digamos, "índices de aprovação de Obama" e "nível de popularidade de Obama" (se bem me lembro, esses são exemplos reais da base de perguntas, embora estejam um pouco desatualizados agora ...) . Vemos consultas diferentes, mas todos concordam: os usuários procuram essencialmente as mesmas informações, portanto, as consultas devem ser consideradas equivalentes ao contar o número de consultas, exibir resultados etc.
Como você determina se duas consultas são sinônimos?Vamos formalizar a tarefa. Suponha que haja dois conjuntos de pares de cadeias: pares de sinônimos e pares de consulta.
Especificamente, aqui está um exemplo de entrada para ilustrar:
SYNONYMS = [ ('rate', 'ratings'), ('approval', 'popularity'), ] QUERIES = [ ('obama approval rate', 'obama popularity ratings'), ('obama approval rates', 'obama popularity ratings'), ('obama approval rate', 'popularity ratings obama') ]
É necessário produzir uma lista de valores lógicos: as consultas em cada par são sinônimos.
Todas as novas perguntas ...
À primeira vista, esta é uma tarefa simples. Mas quanto mais você pensa, mais difícil se torna. Uma palavra pode ter vários sinônimos? A ordem das palavras importa? As relações sinônimas são transitivas, ou seja, se A é sinônimo de B e B é sinônimo de C, A é sinônimo de C? Os sinônimos podem cobrir algumas palavras: como "EUA" é sinônimo das frases "Estados Unidos da América" ou "Estados Unidos"?
Tal ambiguidade imediatamente torna possível provar-se um bom candidato. A primeira coisa que ele faz é procurar essas ambiguidades e tentar resolvê-las. Todo mundo faz isso de maneiras diferentes: algumas abordam o quadro e tentam resolver manualmente casos específicos, enquanto outras examinam a questão e imediatamente veem as lacunas. De qualquer forma, identificar esses problemas em um estágio inicial é crucial.
A fase de "entender o problema" é de grande importância. Eu gosto de chamar a engenharia de software de disciplina fractal. Como os fractais, a aproximação revela complexidade adicional. Você acha que entende o problema e, em seguida, olha mais de perto - e percebe que perdeu alguma sutileza ou detalhe da implementação que pode ser aprimorada. Ou uma abordagem diferente para o problema.
 Conjunto de MandelbrotO calibre de um engenheiro é amplamente determinado pela profundidade com que ele pode entender o problema.
Conjunto de MandelbrotO calibre de um engenheiro é amplamente determinado pela profundidade com que ele pode entender o problema. Transformar uma declaração vaga do problema em um conjunto detalhado de requisitos é o primeiro passo desse processo, e o eufemismo deliberado permite avaliar o grau de adequação do candidato a novas situações.
Deixamos de lado questões triviais, como “As letras maiúsculas são importantes?” Isso não afeta o algoritmo principal. Eu sempre dou a resposta mais simples para essas perguntas (neste caso, "Suponha que todas as letras já tenham sido pré-processadas e convertidas em minúsculas")Parte 1. (Não é bem) um caso simples
Se os candidatos fazem perguntas, sempre começo pelo caso mais simples: uma palavra pode ter vários sinônimos, a ordem das palavras é importante, os sinônimos não são transitivos. Isso fornece ao mecanismo de pesquisa uma funcionalidade bastante limitada, mas possui sutilezas suficientes para uma entrevista interessante.
Uma visão geral de alto nível é a seguinte: divida a consulta em palavras (por exemplo, por espaços) e compare os pares correspondentes para procurar palavras e sinônimos idênticos. Visualmente, fica assim:
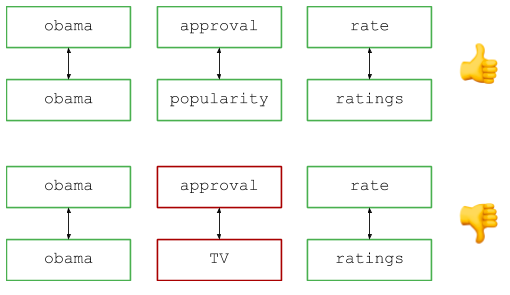
No código:
def synonym_queries(synonym_words, queries): ''' synonym_words: iterable of pairs of strings representing synonymous words queries: iterable of pairs of strings representing queries to be tested for synonymous-ness ''' output = [] for q1, q2 in queries: q1, q2 = q1.split(), q2.split() if len(q1) != len(q2): output.append(False) continue result = True for i in range(len(q1)): w1, w2 = q1[i], q2[i] if w1 == w2: continue elif words_are_synonyms(w1, w2): continue result = False break output.append(result) return output
Fácil né? Algoritmicamente, é bem simples. Sem programação dinâmica, recursão, estruturas complexas, etc. Manipulação simples da biblioteca padrão e um algoritmo que funciona em tempo linear, certo?
Mas há mais nuances do que parece à primeira vista. Obviamente, o componente mais difícil é a comparação de sinônimos. Embora o componente seja fácil de entender e descrever, há muitas maneiras de cometer um erro. Vou falar sobre os erros mais comuns.
Para maior clareza: nenhum erro desqualificará um candidato; se isso, eu apenas aponto um erro na implementação, ele corrige, e seguimos em frente. No entanto, uma entrevista é, antes de tudo, uma luta contra o tempo. Você fará, notará e corrigirá erros, mas leva tempo que pode ser gasto com outra pessoa, por exemplo, para criar uma solução mais ideal. Quase todo mundo comete erros, isso é normal, mas os candidatos que os tornam menores apresentam melhores resultados simplesmente porque passam menos tempo corrigindo-os.
É por isso que eu gosto desse problema. Se o movimento de um cavaleiro exige uma compreensão do entendimento do algoritmo e, depois, (espero) uma implementação simples, a solução aqui é de muitos passos na direção certa. Cada passo representa um pequeno obstáculo através do qual o candidato pode pular graciosamente ou tropeçar e subir. Graças à experiência e intuição, bons candidatos evitam essas pequenas armadilhas - e obtêm uma solução mais detalhada e correta, enquanto os mais fracos gastam tempo e energia com erros e geralmente ficam com o código errado.
Em cada entrevista, vi uma combinação diferente de sucesso e fracasso, esses são os erros mais comuns.
Assassinos de desempenho aleatório
Primeiro, alguns candidatos implementaram a detecção de sinônimos simplesmente percorrendo a lista de sinônimos:
... elif (w1, w2) in synonym_words: continue ...
À primeira vista, isso parece razoável. Mas, após uma inspeção mais minuciosa, a idéia é muito, muito ruim. Para aqueles que não conhecem o Python, a palavra-chave in é açúcar sintático para o método
contains e funciona em todos os contêineres padrão do Python. Esse é um problema porque o
synonym_words é uma lista que implementa a palavra-chave in usando a pesquisa linear. Os usuários de Python são especialmente sensíveis a esse erro porque a linguagem oculta tipos, mas os usuários de C ++ e Java às vezes também cometem erros semelhantes.
Ao longo da minha carreira, escrevi apenas algumas vezes com código de pesquisa linear e cada uma em uma lista de não mais do que duas dúzias de elementos. E mesmo nesse caso, ele escreveu um longo comentário explicando por que escolheu uma abordagem aparentemente subótima. Suspeito que alguns candidatos o usaram simplesmente porque não sabiam como a palavra-chave in funciona em listas da biblioteca padrão do Python. Este é um erro simples, não fatal, mas o mau conhecimento do seu idioma favorito não é muito bom.
Na prática, esse erro é facilmente evitado. Primeiro, nunca esqueça seus tipos de objetos, mesmo se você usar uma linguagem não tipada como Python! Em segundo lugar, lembre-se de que quando você usa a palavra-chave
in na lista, uma pesquisa linear é iniciada. Se não houver garantia de que essa lista sempre permaneça muito pequena, isso prejudicará o desempenho.
Para que o candidato volte a si, normalmente basta lembrá-lo de que a estrutura de entrada é uma lista. É muito importante observar como o candidato responde à solicitação. Os melhores candidatos imediatamente tentam pré-processar os sinônimos, o que é um bom começo. No entanto, essa abordagem não deixa de ter suas armadilhas ...
Use a estrutura de dados correta
A partir do código acima, é imediatamente claro que, para implementar esse algoritmo em tempo linear, é necessário encontrar rapidamente sinônimos. E quando falamos de pesquisas rápidas, é sempre um mapa ou uma variedade de hashes.
Não importa para mim se o candidato escolhe um mapa ou uma matriz de hashes. O importante é que ele o coloque lá (a propósito, nunca use dict / hashmap com a transição para
True ou
False ). A maioria dos candidatos escolhe algum tipo de dict / hashmap. O erro mais comum é a suposição subconsciente de que cada palavra não tem mais que um sinônimo:
... synonyms = {} for w1, w2 in synonym_words: synonyms[w1] = w2 ... elif synonyms[w1] == w2: continue
Não castigo candidatos por esse erro. A tarefa é especialmente formulada para não se concentrar no fato de que as palavras podem ter vários sinônimos, e alguns candidatos simplesmente não encontraram essa situação. O mais rapidamente corrige um erro quando eu aponto para ele. Bons candidatos percebem isso em um estágio inicial e geralmente não passam muito tempo.
Um problema um pouco mais sério é a falta de consciência de que a relação de sinônimos se espalha nas duas direções. Observe que no código acima isso é levado em consideração. Mas há implementações com um erro:
... synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].append(w2) synonyms[w2].append(w1) ... elif w2 in synonyms.get(w1, tuple()): continue
Por que duas inserções e usam o dobro de memória?
... synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].append(w2) ... elif (w2 in synonyms.get(w1, tuple()) or w1 in synonyms.get(w2, tuple())): continue
Conclusão:
sempre pense em como otimizar o código ! Em retrospecto, a permutação das funções de busca é uma otimização óbvia, caso contrário, podemos concluir que o candidato não pensou nas opções de otimização. Novamente, fico feliz em dar uma dica, mas é melhor adivinhar por si mesmo.
Classificar?
Alguns candidatos inteligentes desejam classificar a lista de sinônimos e usar a pesquisa binária. De fato, essa abordagem tem uma vantagem importante: não requer espaço adicional, exceto a lista de sinônimos (desde que a lista possa ser alterada).
Infelizmente, a complexidade do tempo interfere: classificar uma lista de sinônimos requer tempo de
Nlog(N) e, em seguida, outro
log(N) para procurar cada par de sinônimos, enquanto a solução de pré-processamento descrita ocorre em tempo linear e, em seguida, constante. Além disso, sou categoricamente contra forçar o candidato a implementar classificação e pesquisa binária no quadro, porque: 1) os algoritmos de classificação são bem conhecidos; portanto, até onde eu sei, o candidato pode emiti-lo sem pensar; 2) esses algoritmos são diabolicamente difíceis de implementar corretamente, e muitas vezes até os melhores candidatos cometem erros que não dizem nada sobre suas habilidades de programação.
Sempre que um candidato propunha essa solução, eu estava interessado no tempo de execução do programa e perguntava se havia uma opção melhor. Para obter informações: se o entrevistador perguntar se existe uma opção melhor, a resposta é quase sempre sim. Se alguma vez eu fizer essa pergunta, a resposta certamente será essa.
Finalmente solução
No final, o candidato oferece algo correto e razoavelmente ideal. Aqui está uma implementação em tempo linear e espaço linear para determinadas condições:
def synonym_queries(synonym_words, queries): ''' synonym_words: iterable of pairs of strings representing synonymous words queries: iterable of pairs of strings representing queries to be tested for synonymous-ness ''' synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].add(w2) output = [] for q1, q2 in queries: q1, q2 = q1.split(), q2.split() if len(q1) != len(q2): output.append(False) continue result = True for i in range(len(q1)): w1, w2 = q1[i], q2[i] if w1 == w2: continue elif ((w1 in synonyms and w2 in synonyms[w1]) or (w2 in synonyms and w1 in synonyms[w2])): continue result = False break output.append(result) return output
Algumas notas rápidas:
- Observe o uso de
dict.get() . Você pode implementar uma verificação para ver se a chave está no dict e depois obtê-la, mas essa é uma abordagem complicada, embora desta maneira você mostre seu conhecimento da biblioteca padrão. - Pessoalmente, não sou fã de código com
continue frequente e alguns guias de estilo os proíbem ou não os recomendam . Na primeira edição deste código, eu mesmo esqueci a instrução continue após verificar a duração da solicitação. Esta não é uma abordagem ruim, apenas saiba que é propensa a erros.
Parte 2: Ficando mais difícil!
Bons candidatos, depois de resolver o problema, ainda têm dez a quinze minutos de tempo. Felizmente, existem várias perguntas adicionais, embora seja improvável que escrevamos muito código durante esse período. No entanto, isso não é necessário. Quero saber duas coisas sobre o candidato: ele é capaz de desenvolver algoritmos e é capaz de codificar? O problema com o movimento do cavaleiro responde primeiro à pergunta sobre o desenvolvimento do algoritmo e depois verifica a codificação, e aqui obtemos as respostas na ordem inversa.
Quando o candidato completou a primeira parte da pergunta, ele já havia resolvido o problema com a codificação (surpreendentemente não trivial). Nesse estágio, posso falar com confiança sobre sua capacidade de desenvolver algoritmos rudimentares e traduzir idéias em código, bem como conhecer seu idioma favorito e sua biblioteca padrão. Agora a conversa está se tornando muito mais interessante, porque os requisitos de programação podem ser relaxados, e vamos mergulhar nos algoritmos.
Para esse fim, retornamos aos postulados principais da primeira parte: a ordem das palavras é importante, os sinônimos não são transitivos e, para cada palavra, pode haver vários sinônimos. À medida que a entrevista avança, altero cada uma dessas restrições e, nesta nova fase, o candidato e eu temos uma discussão puramente algorítmica. Aqui darei exemplos de código para ilustrar meu ponto de vista, mas em uma entrevista real, estamos falando apenas de algoritmos.
Antes de começar, explicarei minha posição: todas as ações subseqüentes nesta fase da entrevista são principalmente "pontos de bônus". Minha abordagem pessoal é identificar candidatos que passam exatamente pela primeira etapa e são adequados para o trabalho. A segunda etapa é necessária para destacar o melhor. A primeira classificação já é muito forte e significa que o candidato é bom o suficiente para a empresa, e a segunda classifica que o candidato é excelente e sua contratação será uma grande vitória para nós.
Transitividade: Abordagens ingênuas
Primeiro, gosto de remover a restrição de transitividade; portanto, se os pares A - B e B - C são sinônimos, as palavras A e C também são sinônimos. Candidatos inteligentes entenderão rapidamente como adaptar sua solução anterior, embora, com a remoção adicional de outras restrições, a lógica básica do algoritmo pare de funcionar.
No entanto, como adaptá-lo? Uma abordagem comum é manter um conjunto completo de sinônimos para cada palavra com base em relacionamentos transitivos. Cada vez que inserimos uma palavra em um conjunto de sinônimos, também a adicionamos aos conjuntos correspondentes para todas as palavras desse conjunto:
synonyms = defaultdict(set) for w1, w2 in synonym_words: for w in synonyms[w1]: synonyms[w].add(w2) synonyms[w1].add(w2) for w in synonyms[w2]: synonyms[w].add(w1) synonyms[w2].add(w1)
Observe que, ao criar o código, já nos aprofundamos nessa solução.Esta solução funciona, mas está longe de ser ótima. Para entender os motivos, estimamos a complexidade espacial desta solução. Cada sinônimo deve ser adicionado não apenas ao conjunto da palavra inicial, mas também ao conjunto de todos os seus sinônimos. Se houver um sinônimo, uma entrada será adicionada. Mas se tivermos 50 sinônimos, você deverá adicionar 50 entradas. Na figura, fica assim:
Observe que passamos de três chaves e seis registros para quatro chaves e doze registros. Uma palavra com 50 sinônimos exigirá 50 chaves e quase 2500 entradas. O espaço necessário para representar uma palavra cresce quadraticamente com um aumento no conjunto de sinônimos, o que é um desperdício.
Existem outras soluções, mas não irei muito fundo para não inflar o artigo. O mais interessante deles é o uso da estrutura de dados de sinônimos para a construção de um gráfico direcionado e, em seguida, uma pesquisa abrangente para encontrar o caminho entre duas palavras. Essa é uma ótima solução, mas a pesquisa se torna linear no tamanho do conjunto de sinônimos da palavra. Como realizamos essa pesquisa para cada solicitação várias vezes, essa abordagem não é ideal.
Transitividade: Usando conjuntos disjuntos
Acontece que a busca por sinônimos é possível por um tempo (quase) constante, graças a uma estrutura de dados chamada conjuntos disjuntos. Essa estrutura oferece possibilidades ligeiramente diferentes de um conjunto de dados comum.
A estrutura de conjunto usual (hashset, conjunto de árvores) é um contêiner que permite determinar rapidamente se um objeto está dentro ou fora dele. Conjuntos disjuntos resolvem um problema completamente diferente: em vez de definir um elemento específico, eles permitem determinar
se dois elementos pertencem ao mesmo conjunto . Além disso, a estrutura faz isso por um tempo ofuscantemente rápido
O(a(n)) , onde
a(n) é a função inversa de Ackerman. Se você não estudou algoritmos avançados, talvez não conheça essa função, que para todas as entradas razoáveis é realmente executada em tempo constante.
Em um nível alto, o algoritmo funciona da seguinte maneira. Os conjuntos são representados por árvores com os pais para cada elemento. Como cada árvore possui uma raiz (um elemento que é seu próprio pai), podemos determinar se dois elementos pertencem ao mesmo conjunto rastreando seus pais na raiz. Se dois elementos tiverem uma raiz, eles pertencerão a um conjunto. Combinar conjuntos também é fácil: basta encontrar os elementos raiz e tornar um deles a raiz do outro.
Até agora tudo bem, mas até agora nenhuma velocidade deslumbrante foi vista. O gênio dessa estrutura está em um procedimento chamado
compressão . Suponha que você tenha a seguinte árvore:
Imagine que você quer saber se
veloz e
apressado são sinônimos. Analise cada pai - e encontre a mesma raiz
rápida . Agora, suponha que realizamos uma verificação semelhante para as palavras
veloz e
veloz . Novamente, subimos à raiz e,
rapidamente , seguimos o mesmo caminho. A duplicação de trabalho pode ser evitada?
Acontece que você pode. Em certo sentido, todos os elementos nesta árvore estão destinados a chegar
rapidamente . Em vez de percorrer toda a árvore toda vez, por que não mudar o pai para que todos os descendentes
rápidos reduzam o caminho para a raiz? Esse processo é chamado de compactação e, em conjuntos separados, é incorporado na operação de pesquisa raiz. Por exemplo, após a primeira operação de comparação
rápida e
rápida , a estrutura entenderá que são sinônimos e comprimirá a árvore da seguinte maneira:
Para todas as palavras entre veloz e rápido, o pai foi atualizado, o mesmo aconteceu com o apressadoAgora todas as chamadas subsequentes ocorrerão em tempo constante, porque cada nó nesta árvore aponta para
rápido . Não é muito fácil avaliar a complexidade do tempo das operações: na verdade, não é constante, porque depende da profundidade das árvores, mas é quase constante, porque a estrutura é rapidamente otimizada. Por simplicidade, assumimos que o tempo é constante.
Com esse conceito, implementamos conjuntos não relacionados para o nosso problema:
class DisjointSet(object): def __init__(self): self.parents = {} def get_root(self, w): words_traversed = [] while self.parents[w] != w: words_traversed.append(w) w = self.parents[w] for word in words_traversed: self.parents[word] = w return w def add_synonyms(self, w1, w2): if w1 not in self.parents: self.parents[w1] = w1 if w2 not in self.parents: self.parents[w2] = w2 w1_root = self.get_root(w1) w2_root = self.get_root(w2) if w1_root < w2_root: w1_root, w2_root = w2_root, w1_root self.parents[w2_root] = w1_root def are_synonymous(self, w1, w2): return self.get_root(w1) == self.get_root(w2)
Usando essa estrutura, você pode pré-processar sinônimos e resolver o problema em tempo linear.Classificação e notas
A essa altura, chegamos ao limite do que um candidato pode mostrar em 40 a 45 minutos de uma entrevista. A todos os candidatos que lidaram com a parte introdutória e fizeram progressos significativos na descrição (não implementando) de conjuntos não relacionados, designei uma classificação de “Altamente recomendado para contratar” e permiti que fizessem qualquer pergunta. Eu nunca vi um candidato chegar tão longe e ainda tenho muito tempo.Em princípio, ainda existem variantes do problema com transitividade: por exemplo, remova a restrição na ordem das palavras ou em vários sinônimos de uma palavra. Cada decisão será difícil e agradável, mas eu as deixarei para mais tarde.O mérito dessa tarefa é que ela permite que os candidatos cometam erros. O desenvolvimento diário do software consiste em ciclos intermináveis de análise, execução e refinamento. Esse problema possibilita que os candidatos demonstrem suas habilidades em cada estágio. Considere as habilidades necessárias para obter a pontuação máxima nesta questão:- Analise a afirmação do problema e determine onde ele não está claramente formulado , desenvolva uma formulação inequívoca. Continue fazendo isso à medida que você resolve e novas perguntas surgem. Para obter a máxima eficiência, execute essas operações o mais cedo possível, pois quanto mais o trabalho for realizado, mais tempo levará para corrigir o erro.
- , . , .
- . , , .
- , . ,
continue , , .
- , : , , , . , , , .
- . — , . — .
Nenhuma dessas habilidades pode ser aprendida nos livros didáticos (com a possível exceção de estruturas e algoritmos de dados). A única maneira de adquiri-las é uma prática regular e abrangente, que está de acordo com o que o empregador precisa: candidatos experientes, capazes de aplicar efetivamente seus conhecimentos. O objetivo das entrevistas foi encontrar essas pessoas, e a tarefa deste artigo me ajudou muito por um longo tempo.Planos futuros
Como você pode entender, a tarefa acabou se tornando pública . Desde então, tenho usado várias outras perguntas, dependendo do que os entrevistadores anteriores fizeram e do meu humor (fazer uma pergunta é chato o tempo todo). Ainda uso algumas perguntas, por isso vou mantê-las em segredo, mas outras não! Você pode encontrá-los nos seguintes artigos.No futuro próximo, planejo dois artigos. Primeiro, como prometido acima, explicarei a solução para os dois problemas restantes para esta tarefa. Eu nunca perguntei a eles em entrevistas, mas eles são interessantes em si mesmos. Além disso, compartilharei meus pensamentos e opiniões pessoais sobre o procedimento para encontrar funcionários em TI, no qual estou particularmente interessado agora, porque estou procurando engenheiros para minha equipe no Reddit.Como sempre, se você quiser saber sobre o lançamento de novos artigos, siga-me no Twitter ou no Medium . Se você gostou deste artigo, não se esqueça de votar ou deixar um comentário.Obrigado pela leitura!PS: Você pode examinar o código de todos os artigos no GitHub repositório ou brincar com eles vivos graças aos meus bons amigos de repl.it .