O mercado de serviços em nuvem está crescendo rapidamente no mundo e na Rússia. Mais e mais empresas estão movendo seus aplicativos e dados, incluindo os críticos para os negócios, para a nuvem. Segundo os profissionais de marketing, isso permite que as empresas usem as mais avançadas soluções em nuvem inovadoras, reduzindo os custos de capital (convertendo CAPEX em OPEX), mais rapidamente para trazer novos produtos ao mercado e lançar novos serviços. E esses argumentos não deixam clientes em potencial indiferentes. Não é por acaso que as taxas de crescimento do mercado de nuvem russo estão significativamente à frente do crescimento do mercado de infraestrutura de TI tradicional e clássica.
Gradualmente, as dúvidas sobre a confiabilidade e a segurança das nuvens são dissipadas. Como mostrou um
estudo recente da
iKS-Consulting , quase 40% das empresas russas pesquisadas veem o uso de nuvens públicas como uma oportunidade para melhorar a segurança de seus sistemas de TI. O serviço de nuvem de infraestrutura mais popular é o aluguel de servidores virtuais. Em segundo lugar na popularidade, está o serviço de backup em nuvem (Backup-as-a-Service). Cerca de um terço dos entrevistados usa serviços em nuvem para hospedar infraestrutura de armazenamento e recuperação de desastres.
Enquanto isso, com a crescente dependência dos negócios em TI, os requisitos para a confiabilidade dos serviços de TI, incluindo serviços em nuvem, estão aumentando. E, muitas vezes, é necessário fornecer não apenas confiabilidade de hardware, mas também tolerância a desastres.
Segundo a pesquisa , quase três quartos das organizações no mundo não têm certeza absoluta de que serão capazes de restaurar seus sistemas e dados. O tempo de inatividade não planejado e a perda de dados custam às organizações em todo o mundo anualmente mais de US $ 1,7 bilhões. De acordo com a
pesquisa da Acronis , na Rússia, apenas 2% das empresas pesquisadas têm certeza absoluta de que sua infraestrutura de TI suportará qualquer teste. Metade dos especialistas russos espera longas interrupções em seu trabalho em caso de desastre natural ou acidente. Segundo as estatísticas mundiais, 93% das empresas que perderam seu data center por apenas 10 dias faliram em um ano.
Em qualquer sistema tecnicamente complexo, os acidentes são inevitáveis, mas podem não ser críticos para os negócios. Para evitar tais situações, são criados sistemas de cluster resistentes a desastres que praticamente eliminam o tempo de inatividade em caso de acidentes e falhas.
Outro ponto importante que não deve ser esquecido ao projetar uma infraestrutura de TI resistente a desastres são as estações de trabalho dos usuários. É necessário retomar os processos de negócios, e não apenas mudar para o servidor de backup ou aumentar o banco de dados. A tolerância a desastres começa no escritório do cliente. Mesmo um escritório de backup com trabalhos de funcionários não é a melhor opção. Estações de trabalho virtuais (VDIs) ou outras formas de local de trabalho na nuvem podem ser uma boa solução. O acesso a essa estação de trabalho em uma máquina virtual no datacenter é fácil de organizar a partir de qualquer computador na rede da filial.
Inovação na nuvem
A operadora de telecomunicações russa
MasterTel e Lenovo prepararam e implementaram em conjunto um projeto de nuvem
resistente a desastres chamado
Innovate Cloud Technology . Com base nessa nuvem, serviços IaaS altamente confiáveis são fornecidos a uma ampla gama de clientes que desejam implantar uma infraestrutura de TI crítica na nuvem. A nuvem foi baseada no cluster de metrô espaçado entre dois sites - os data centers DataPro e IXellerate em Moscou.
Escolhendo um parceiro para este projeto, a empresa MasterTel foi guiada, antes de tudo, pela capacidade do fornecedor de fornecer prontamente a solução mais completa por um preço razoável. Para implementar a nuvem, lançada em outubro de 2018, uma equipe de especialistas em Serviços Profissionais da Lenovo estava envolvida. A MasterTel atua como um provedor de serviços em nuvem e uma operadora de telecomunicações que organiza canais de comunicação seguros e fornece linhas diretas de fibra ótica, sendo responsável pela operação da nuvem e seu suporte.
A Innovate Cloud Technology é uma nuvem privada para clientes corporativos, oferecendo serviços em nuvem em tempo real altamente confiáveis e escalonáveis IaaS, BaaS, DRaaS, VDS, etc. O que o uso dos serviços da Innovate Cloud Technology fornece?
Alta confiabilidade
Atualmente, a maioria dos projetos de nuvem, de fato, fornece capacidade de aluguel. Como regra, isso é a criação de servidores virtuais (o serviço comercial de data center mais comum na Rússia) e o acesso a um pool de recursos já formado. No caso da Innovate Cloud Technology, o cliente pode fazer todas as configurações on-line, os recursos são alocados e liberados dinamicamente e pagos após o fato, exclusivamente pelos recursos utilizados, como convém a um serviço em nuvem clássico.
Mas talvez o recurso mais importante da Innovate Cloud Technology seja sua alta confiabilidade. Os clientes podem aproveitar a infraestrutura de nuvem de alta disponibilidade e armazenar dados altamente críticos em data centers geograficamente dispersos DataPro e IXcellelle. Somente esses sites garantem confiabilidade e um alto nível de segurança física e de informações. Canais de comunicação confiáveis de alta velocidade e acesso aos dois data centers são fornecidos pela MasterTel.
Innovate Cloud Technology é um recurso de nuvem com disponibilidade garantida de 99,99% de SLA. No entanto, essa nuvem não se distingue apenas pela alta confiabilidade, mas também pela tolerância a desastres, porque é um cluster de virtualização geograficamente disperso em dois sites de nível III.
Data Center DataPro
Este data center Tier III na rua. O Aviamotornaya em Moscou é um dos poucos data centers comerciais russos que receberam a certificação Uptime Design and Facility. Todas as tecnologias e soluções usadas no data center são certificadas, o que significa tolerância máxima a falhas, disponibilidade garantida de recursos e é seguro contra situações inesperadas.
Centro de Gerenciamento do DataPro Data Center. A certificação internacional do Uptime Design and Facility significa que ele foi projetado e construído de acordo com todos os padrões aplicáveis para a categoria de confiabilidade Tier III.
A segurança é responsável pela segurança do próprio data center e da área circundante. O sistema de segurança inclui mais de 350 câmeras de rede. Para fonte de alimentação ininterrupta e garantida, são utilizadas fontes de alimentação ininterrupta (UPS), grupos geradores a diesel (DGU) que suportam a operação do centro de dados durante um acidente prolongado na rede de fonte de alimentação.
No data center DataPro, existem duas entradas independentes de 10 kV da subestação Mosenergo e os cabos são colocados em diferentes coletores, fornecendo a energia elétrica necessária para a instalação. A fonte de alimentação do data center é realmente reservada de acordo com o esquema 2N.
IXcellerate Moscow One
O data center Moscow One do IXcellerate também possui uma certificação do Tier III Uptime Institute na categoria Design. A instalação também atende ao nível de confiabilidade do Nível 3 nas categorias "projeto", "construção" e "operação", de acordo com a metodologia IBM Reliability Rating System. O IXcellerate Moscow One é tecnicamente implementado e garantido no nível do SLA, com um indicador de disponibilidade de 99,999%. A área total do data center do IXcellerate Moscow One em Degunino é de 15.741 metros quadrados. m) A capacidade de projeto da instalação atinge 13,7 MW. Os clientes do data center incluem cerca de cem empresas internacionais e russas.
Passar nos testes de certificação do Uptime Institute prova que o complexo de computação IXcellerate foi projetado de acordo com as práticas modernas do mundo na construção de data centers.
Tolerância a desastres
A distribuição em dois sites requer a organização de canais de comunicação redundantes, replicação de dados entre armazenamentos. Precisamos de um mecanismo de sincronização de dados para garantir sua relevância no caso de falha de um dos nós e para suportar a operação dos sistemas de informação que requerem essa sincronização.
Muitas vezes, no coração de um data center resistente a desastres está uma configuração de servidor de cluster geograficamente distribuída com uma conexão a uma rede de área de armazenamento comum (SAN). Os nós desse cluster espaçado estão localizados nos sites principal e de reserva, formando um único sistema. Isso garante disponibilidade ininterrupta de serviço, mesmo no caso de perda de um dos data centers. Com a ajuda do cluster, é possível fornecer alternância automática de carga entre os sites de um data center distribuído em caso de acidente.
Os sistemas de armazenamento de dados nesses sites podem se duplicar completamente, e os próprios sites são conectados por canais de comunicação redundantes de alta velocidade, o que permite implementar projetos com os mais altos requisitos para a confiabilidade da transferência de dados e sua disponibilidade, incluindo replicação síncrona de dados.
Exemplo de configuração do Metrocluster baseado no VMware vSphere. baseia-se na duplicação de sistemas de armazenamento em dois sites geograficamente separados com replicação de dados e possível balanceamento de carga no nível da rede do datacenter. Se um dos data centers não estiver disponível, as máquinas virtuais serão iniciadas automaticamente na segunda plataforma. Um cluster intermediário tem quase zero tempo de inatividade, o trabalho é interrompido apenas durante a inicialização de máquinas virtuais quando o VMware High Availability (HA) reinicia a VM em um site remoto com armazenamento localizado no cluster.
Se você usar mecanismos de balanceamento de carga de DR (Global Server Load Balancing, GSLB), poderá alternar automaticamente os usuários para o site de backup no caso de uma falha primária. Para os usuários, esse processo será transparente.
Ao contrário do DR com replicação de dados, no caso de um cluster metro, apenas os mesmos tipos de discos são usados para espelhamento, uma configuração idêntica é necessária nos dois sites.
A nuvem Innovate Cloud Technology baseada em VMware é criada dessa maneira. Ele fornece operação contínua de aplicativos e dados críticos na nuvem. Todos os elementos do cluster de virtualização são duplicados em dois sites, distantes uns dos outros por quase 30 km. Entre eles, o espelhamento de dados é configurado no nível do sistema de armazenamento. Por esse motivo, os dados e serviços estarão disponíveis em caso de falhas em um dos sites: falta de energia, falha parcial dos sistemas de armazenamento, controladores, canais de comunicação entre o data center e até mesmo no caso de uma inoperabilidade completa de um dos sites.
Se um dos datacenters estiver indisponível, as máquinas virtuais serão migradas para o site de backup. A inicialização de uma máquina virtual em um site de backup (Objetivo do Tempo de Recuperação, RTO) leva cerca de 3 minutos.
É oferecido aos clientes um SLA (Contrato de nível de serviço) detalhado. Seus principais indicadores: disponibilidade de serviço em 99,99%; simples - não mais que 4,38 minutos por mês, parâmetros garantidos de desempenho do processador (MIPS / 1 vCPU), sistema de disco (IOPS, GB / s), atrasos no acesso aos sistemas de armazenamento. Por sua conformidade, o provedor é responsável financeiramente.
Metro Cluster Anatomy
A nuvem é construída de acordo com o modelo arquitetural clássico, que envolve a compra de todo o complexo de hardware e software necessário: servidores com organização de acesso físico e lógico, armazenamento, componentes de rede, software de virtualização, soluções de segurança.
Dois data centers em Moscou têm zonas fechadas dedicadas para quatro racks com nós de computação e rede. A solução é construída sobre componentes fabricados pela Lenovo. Como sistemas de computação de hardware, são utilizados servidores Lenovo ThinkSystem SR530 / SR570 / SR630 1U com adaptadores HBA de porta dupla Emulex 16Gb Gen6 FC, matrizes Lenovo Storage V3700 V2 XP para armazenamento de dados e comutadores de rack de 10 portas Gigabit de 32 portas são usados para transferência de dados com o Lenovo ThinkSystem NE1032 RackSwitch. O pacote inclui o software VMware ESXi 6.5 instalado de fábrica nos servidores. Os sites são conectados por dois canais FC de 8 Gbit / s e dois canais Ethernet de 10 Gbit / s.
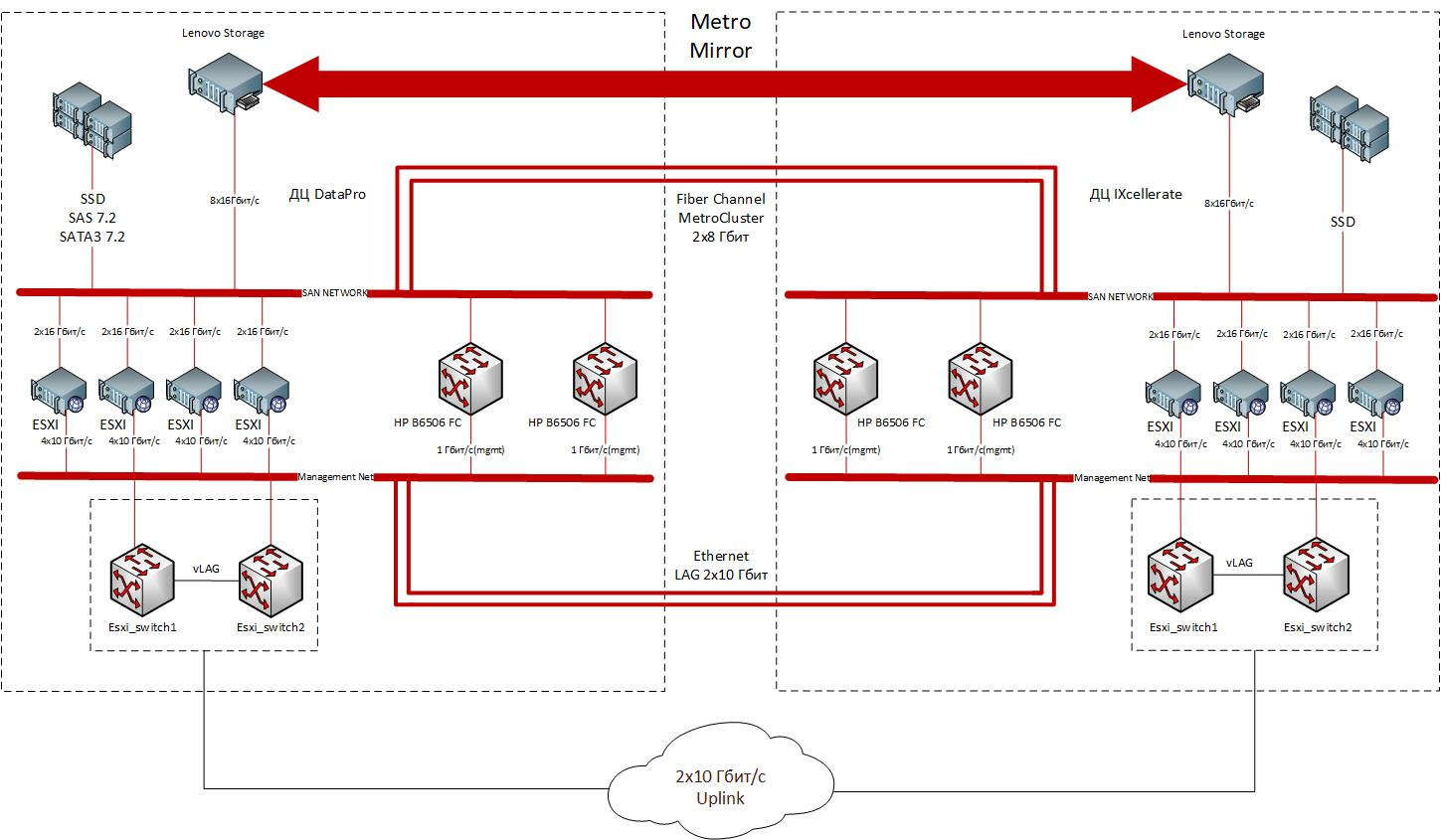
A estrutura de um cluster geograficamente distribuído. Espaçado entre os dois sites, o cluster metro fornece tolerância a desastres e possibilita o fornecimento de serviços IaaS confiáveis a uma ampla variedade de clientes. Os sites são conectados por canais redundantes Ethernet (2x10 Gbit / s) e FC (2x8 Gbit / s).
Ao adquirir componentes de infraestrutura de um fornecedor, a confiabilidade e a resiliência de todo o complexo são aumentadas, os conflitos entre elementos, padrões e protocolos são eliminados.
Os esforços conjuntos das duas equipes realizaram trabalhos sobre a criação do projeto, preparação e desenvolvimento de especificações técnicas, instalação de equipamentos, comissionamento, teste de estresse e comissionamento do cluster metropolitano.
O Lenovo Metrocluster fornece um backup completo de todos os seus elementos: servidores, armazenamento, controladores, adaptadores FC, comutadores ópticos. A replicação de dados síncrona no nível de armazenamento fornece zero RPO (objetivo do ponto de recuperação).
A alta disponibilidade sempre foi alcançada garantindo a redundância - isso também é verdade no caso de preparação para situações extremas, quando todo o data center deve ser protegido contra falta de energia ou desastres naturais. Se um dos sites falhar, um cluster geograficamente disperso automaticamente e sem interromper os processos de trabalho muda para um segundo data center. De fato, o cluster metro é um cluster local com um sistema de armazenamento espelhado, espaçado entre dois sites.
Clusters distribuídos geograficamente não têm pontos críticos de falha. O cluster metro implementa replicação mútua de dados síncronos entre sites. Se ocorrer um problema, a mudança para outro site é completamente transparente e sem intervenção do administrador. A automação desse processo garante a operação contínua de todos os aplicativos. Os clusters Metro também não precisam ser interrompidos para atualizar seu hardware ou software.
Por exemplo, no caso de uma falha completa do servidor, suas responsabilidades são transferidas para um segundo servidor localizado no mesmo site em alguns segundos. A interrupção de curto prazo da entrada e saída de dados que ocorre nesse caso não afetará a operação dos aplicativos, pois os dados são espelhados de forma síncrona para a segunda plataforma. Se houver um problema na operação do comutador, cabo ou HBA Fibre Channel, a alternância de backup para o segundo datacenter não será necessária e o usuário final não sofrerá nenhuma redução no desempenho do aplicativo.
No caso de uma falha de todo o nó de serviço, ocorre uma interrupção de curto prazo (vários segundos) dos fluxos de E / S: os serviços são transferidos primeiro para os nós vizinhos e a necessidade de mudar para um nó geograficamente remoto surge apenas se o site for completamente interrompido.
Nessa situação, um cluster geograficamente disperso usa redundância no nível do datacenter para superar a falha, e os sistemas localizados no segundo site assumem o suporte de todos os serviços. Assim, os servidores de aplicativos mantêm acesso a todos os serviços, mas com desempenho limitado.
Quando o site em que a falha ocorreu voltar a entrar no modo operacional, será necessário transferir para ele apenas os dados que foram alterados durante o tempo de inatividade; portanto, após eliminar os problemas locais, o data center afetado poderá retornar rapidamente à operação normal.
Em caso de perda do host, o VMware High Availability (HA) reinicia imediatamente a VM em um site remoto. Se um dos sistemas de armazenamento falhar, o sistema de armazenamento em outro site anunciará os caminhos de disco para os hosts restantes. As VMs perdidas são reiniciadas, tudo acontece automaticamente.
Se a conexão entre os sites for perdida, tudo continuará funcionando e, assim que a conexão for restaurada, o processo de sincronização será iniciado.
Composição da solução
Oito servidores Lenovo ThinkSystem SR630 com 2 processadores Intel Xeon Gold 6132 14C 140W 2,6 GHz, memória TruDDR4 de 2666 MHz (RDIMM) de 32 GB, 10 compartimentos de 2,5 ", unidades SSD SATA M.2 de 32 GB e software VMware ESXi 6.5 instalado de fábrica.
| O servidor de processador duplo no formato 1U possui flexibilidade e desempenho devido ao suporte de discos rígidos e unidades de estado sólido (HDD e SSD) com interfaces SAS ou SATA (12 SFF ou 4 LFF). Com a capacidade de conectar unidades NVMe, oferece altas velocidades de leitura e gravação. O software Lenovo XClarity Administrator simplifica o gerenciamento e a manutenção da infraestrutura. Esta solução de design está focada em um equilíbrio de desempenho e preço para suportar uma ampla gama de cargas de trabalho, projetadas para operação contínua a uma temperatura de 45 ° C.
|
Dois sistemas de armazenamento Lenovo Storage V3700 V2 XP com SSD SAS de 1,92 TB 2,5 "e HDD de 1,2 TB 2,5" 10K, com software Easy Tier, FlashCopy e espelhamento remoto.
| Um conjunto de ferramentas funcionais de armazenamento permite resolver com eficiência problemas com grandes volumes de dados e acesso multithread aos recursos de informação.O V3700 V2 XP oferece a capacidade de consolidar cargas, suporta a formação de sistemas de armazenamento capazes de suportar inúmeras aplicações exigentes. O sistema nos processadores Intel é caracterizado por alto desempenho e velocidade de troca de dados por meio do barramento SAS, ferramentas funcionais que antes estavam disponíveis apenas em dispositivos de última geração. O armazenamento oferece uma interface baseada na Web com funções de gerenciamento integradas, fornece a formação de configurações de trabalho flexíveis e sua rápida implantação usando virtualização, aplicativos de backup usando o FlashCopy. Ele suporta dimensionamento vertical de até 240 unidades de 2,5 polegadas ou 120 unidades em um formato de 3,5 polegadas. Você pode usar nove unidades de expansão para dimensionar.
|
Armazenamento para Lenovo V3700 V2 com 20 unidades HD de 2 TB com 2,5 "e 7.2"
| O sistema fornece um conjunto de ferramentas que fornecem virtualização, dimensionamento e gerenciamento unificados. É uma solução híbrida com recursos de virtualização. Armazenamento O Lenovo Storage V3700 V2 possui dois controladores RAID, permite usar qualquer formato de armazenamento - discos rígidos de 3,5 "e formato HDD ou SSD de 2,5". O SHD vem de fábrica com o software do sistema com as funções de virtualização de armazenamento interno, thin provisioning, migração de dados unidirecional, FlashCopy (64 cópias). Recursos adicionais - FlashCopy (2048 cópias), Easy Tier, Espelhamento Remoto.
|
32- Ethernet 10 / Lenovo ThinkSystem NE1032 SFP+ SR.
| 24 10GBase-T 8 SFP+ 10 / . Lenovo Cloud NOS, . NE1032 . L2/L3 IP-, BGP, , Lenovo XClarity.
|
Fibre Channel Lenovo B6505 FC SAN c 12 SFP 16 /.
| Fibre Channel 5- -. - 16 /.
|
