
O tópico de melhorar o desempenho dos sistemas operacionais e encontrar gargalos está ganhando imensa popularidade. Neste artigo, falaremos sobre uma ferramenta para encontrar esses mesmos lugares usando o exemplo da pilha de blocos no Linux e um caso de solução de problemas em um host.
Exemplo 1. Teste
Nada funciona
Os testes em nosso departamento são sintéticos no hardware do produto e, posteriormente - testes de software de aplicativos. Recebemos uma unidade Intel Optane para teste. Já escrevemos sobre o teste de unidades Optane
em nosso blog .
O disco foi instalado em um servidor padrão criado por um tempo relativamente longo em um dos projetos em nuvem.
Durante o teste, o disco não se mostrou da melhor maneira: durante o teste com a profundidade da fila de 1 solicitação por 1 fluxo, em blocos de 4Kbytes sobre ~ 70Kiops. E isso significa que o tempo de resposta é enorme: aproximadamente 13 microssegundos por solicitação!
É estranho, porque a
especificação promete "Latência - Leia 10 µs" e temos 30% a mais, a diferença é bastante significativa. O disco foi reorganizado em outra plataforma, uma montagem mais "nova" usada em outro projeto.
Por que isso funciona?
É engraçado, mas a unidade na nova plataforma funcionou como deveria. Desempenho aumentado, latência diminuída, CPU por prateleira, 1 fluxo por solicitação, blocos de 4K bytes, ~ 106Kiops a ~ 9 microssegundos por solicitação.
E então é hora de
comparar as configurações para obter
desempenho de
pernas largas. Afinal, nos perguntamos por que? Com
perf, você pode:
- Faça leituras de contador de hardware: o número de chamadas de instruções, falhas de cache, ramificações previstas incorretamente etc. (Eventos da PMU)
- Remova as informações dos pontos de negociação estáticos, o número de ocorrências
- Realizar rastreamento dinâmico
Para verificação, usamos a amostragem da CPU.
A conclusão é que o
perf pode compilar todo o rastreamento de pilha de um programa em execução. Naturalmente, a execução do
perf apresentará um atraso na operação de todo o sistema. Mas temos a flag
-F # , onde
# é a frequência de amostragem, medida em Hz.
É importante entender que quanto maior a frequência de amostragem, maior a probabilidade de receber uma chamada para uma função específica, mas mais freios o gerador de perfil acarreta no sistema. Quanto menor a frequência, maior a chance de não vermos parte da pilha.
Ao escolher uma frequência, você precisa ser guiado pelo senso comum e um truque - tente não definir uma frequência uniforme, para não entrar em uma situação em que algum trabalho executado em um timer com essa frequência entre nas amostras.
Outro ponto que é inicialmente enganador - o software deve ser compilado com o sinalizador
-fno-omit-frame-pointer , se isso for, é claro, possível. Caso contrário, no rastreamento, em vez de nomes de funções, veremos sólidos valores
desconhecidos . Para alguns softwares, os símbolos de depuração vêm como um pacote separado, por exemplo,
someutil-dbg . É recomendável que você os instale antes de executar o
perf .
Realizamos as seguintes ações:
- Obtido fio do git: //git.kernel.dk/fio.git, tag fio-3.9
- Adicionada a opção -fno-omit-frame-pointer ao CPPFLAGS no Makefile
- Lançado make -j8
perf record -g ~/fio/fio --name=test --rw=randread --bs=4k --ioengine=pvsync2 --filename=/dev/nvme0n1 --direct=1 --hipri --filesize=1G
A opção -g é necessária para capturar a pilha de rastreios.
Você pode visualizar o resultado pelo comando:
perf report -g fractal
A opção
-g fractal é necessária para que as porcentagens que refletem o número de amostras com esta função e mostradas por
perf sejam relativas à função de chamada, cujo número de chamadas é considerado 100%.
No final da pilha de chamadas longas na plataforma "build nova", veremos:
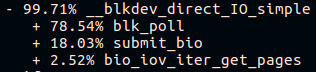
E na plataforma "build antigo":

Ótimo! Mas quero lindos desenhos de flamingo.
Construção de flamegramas
Para ser bonita, existem duas ferramentas:
- Flamegraph relativamente mais estático
- Flamescope , que permite selecionar um período específico de tempo das amostras coletadas. Isso é muito útil quando o código de pesquisa carrega a CPU com rajadas curtas.
Esses utilitários aceitam
resultado perf script> como entrada.
Faça o download do
resultado e envie-o através de pipes para
svg :
FlameGraph/stackcollapse-perf.pl ./result | FlameGraph/flamegraph.pl > ./result.svg
Abra em um navegador e desfrute de uma imagem clicável.
Você pode usar outro método:
- Adicionar resultado ao flamescope / exemplo /
- Execute python ./run.py
- Passamos pelo navegador até a porta 5000 do host local
O que vemos no final?
Um bom fio gasta muito tempo na
pesquisa :
Um fio ruim passa tempo em qualquer lugar, mas não nas pesquisas:
À primeira vista, parece que a pesquisa não funciona no host antigo, mas em todos os lugares o kernel 4.15 é do mesmo conjunto e a pesquisa é ativada por padrão nos discos NVMe. Verifique se a pesquisa está ativada no
sysfs :
Durante os testes,
as chamadas
preadv2 com o sinalizador
RWF_HIPRI são
usadas - uma condição necessária para que a pesquisa funcione. E, se você estudar cuidadosamente o gráfico de chama (ou a captura de tela anterior da saída do
relatório perf ), poderá encontrá-lo, mas isso leva uma quantidade muito pequena de tempo.
A segunda coisa que é visível é a pilha de chamadas diferente para a função submit_bio () e a falta de chamadas io_schedule (). Vamos dar uma olhada na diferença dentro de submit_bio ().
Plataforma lenta "build antigo":
Plataforma rápida "fresca":
Parece que em uma plataforma lenta, a solicitação percorre um longo caminho até o dispositivo, ao mesmo tempo em que
entra no agendador kyber . Você pode ler mais sobre agendadores de E / S em
nosso artigo .
Depois que o
kyber foi desligado, o mesmo teste de fio mostrou uma latência média de cerca de 10 microssegundos, exatamente como declarado na especificação. Ótimo!
Mas de onde vem a diferença em outro microssegundo?
E se um pouco mais profundo?
Como já mencionado, o
perf permite coletar estatísticas de contadores de hardware. Vamos tentar ver o número de falhas de cache e instruções por ciclo:
perf stat -e cycles,instructions,cache-references,cache-misses,bus-cycles /root/fio/fio --clocksource=cpu --name=test --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=10


Pode-se ver pelos resultados que uma plataforma rápida executa mais instruções para o ciclo da CPU e tem uma porcentagem menor de erros de cache durante a execução. Obviamente, não entraremos em detalhes da operação de diferentes plataformas de hardware na estrutura deste artigo.
Exemplo 2. Mercearia
Algo está errado
No trabalho de um sistema de armazenamento distribuído, foi observado um aumento na carga da CPU em um dos hosts com um aumento no tráfego de entrada. Hosts são pares, pares e têm hardware e software idênticos.
Vejamos a carga da CPU:
~
O problema surgiu às 09:23:46 e vemos que o processo funcionou no espaço do kernel exclusivamente por todo o segundo. Vamos ver o que estava acontecendo lá dentro.
Por que tão lento?
Nesse caso, coletamos amostras de todo o sistema:
perf record -a -g -- sleep 22 perf script > perf.results
A opção
-a é necessária aqui para o
perf remover traços de todas as CPUs.
Abra
perf.results com
flamescope para rastrear o momento de aumento da carga da CPU.
À nossa frente está um "mapa de calor", cujos dois eixos (X e Y) representam o tempo.
No eixo X, o espaço é dividido em segundos e, no eixo Y, em segmentos de 20 milissegundos em X segundos. O tempo é executado de baixo para cima e da esquerda para a direita. Os quadrados mais brilhantes têm o maior número de amostras. Ou seja, a CPU no momento trabalhava mais ativamente.
Na verdade, estamos interessados na mancha vermelha no meio. Selecione-o com o mouse, clique e veja o que oculta:
Em geral, já é evidente que o problema é a operação lenta
tcp_recvmsg e
skb_copy_datagram_iovec .
Para maior clareza, compare com amostras de outro host em que a mesma quantidade de tráfego de entrada não causa problemas:
Com base no fato de termos a mesma quantidade de tráfego recebido, plataformas idênticas que funcionam há muito tempo sem parar, podemos assumir que os problemas surgiram do lado do ferro. A função
skb_copy_datagram_iovec copia dados da estrutura do kernel para a estrutura no espaço do usuário para transmitir ao aplicativo. Provavelmente há problemas com a memória do host. Ao mesmo tempo, não há erros nos logs.
Nós reiniciamos a plataforma. Ao carregar o BIOS, vemos uma mensagem sobre uma barra de memória quebrada. Substituição, o host inicia e o problema com uma CPU sobrecarregada não é mais reproduzido.
Postscript
Desempenho do sistema com perf
De um modo geral, em um sistema ocupado, a execução do
perf pode apresentar um atraso no processamento de solicitações. O tamanho desses atrasos também depende da carga no servidor.
Vamos tentar encontrar esse atraso:
~
A diferença não é muito perceptível, apenas cerca de ~ 8 nanossegundos.
Vamos ver o que acontece se você aumentar a carga:
~
Aqui a diferença já está se tornando perceptível. Pode-se dizer que o sistema diminuiu a velocidade em menos de 1%, mas essencialmente a perda de 7Kiops em um sistema muito carregado pode levar a problemas.
É claro que este exemplo é sintético, no entanto, é muito revelador.
Vamos tentar executar outro teste sintético que calcula números primos -
sysbench :
~
Aqui você pode ver que mesmo o tempo mínimo de processamento aumentou em 270 microssegundos.
Em vez de uma conclusão
O Perf é uma ferramenta muito poderosa para analisar o desempenho e a depuração do sistema. No entanto, como em qualquer outra ferramenta, você precisa manter-se no controle e lembrar que qualquer sistema carregado sob supervisão rigorosa funciona pior.
Links relacionados: