Post preparado por: Alexander Virilin xscrew - autor, chefe do serviço de infraestrutura de rede, Leonid Klyuyev - editor
Continuamos a familiarizá-lo com a estrutura interna do
Yandex.Cloud . Hoje falaremos sobre redes - mostraremos como a infraestrutura de rede funciona, por que ela usa o paradigma MPLS impopular para data centers, que outras decisões complexas tivemos que tomar no processo de construção de uma rede em nuvem, como gerenciamos e que tipo de monitoramento usamos.
A rede na nuvem consiste em três camadas. A camada inferior é a infraestrutura já mencionada. Essa é uma rede física "de ferro" dentro de data centers, entre data centers e em locais de conexão com redes externas. Uma rede virtual é construída sobre a infraestrutura de rede e os serviços de rede são construídos sobre a rede virtual. Essa estrutura não é monolítica: as camadas se cruzam, a rede virtual e os serviços de rede interagem diretamente com a infraestrutura de rede. Como a rede virtual costuma ser chamada de sobreposição, geralmente chamamos de infra-estrutura de rede.

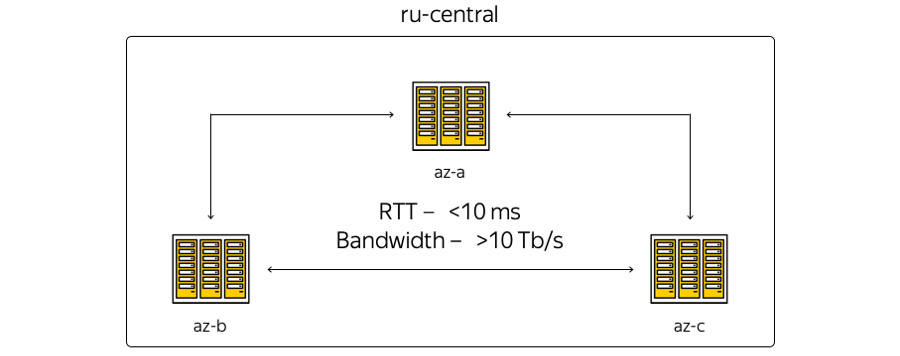
Agora, a infraestrutura em nuvem está baseada na região central da Rússia e inclui três zonas de acesso - ou seja, três data centers independentes distribuídos geograficamente. Independente - independente um do outro no contexto de redes, engenharia e sistemas elétricos, etc.
Sobre as características. A geografia da localização dos data centers é tal que o tempo de ida e volta (RTT) entre eles é sempre de 6 a 7 ms. A capacidade total dos canais já ultrapassou 10 terabits e está em constante crescimento, porque a Yandex possui sua própria rede de fibra ótica entre as zonas. Como não alugamos canais de comunicação, podemos aumentar rapidamente a capacidade da faixa entre os CDs: cada um deles usa equipamento de multiplexação espectral.
Aqui está a representação mais esquemática das zonas:
A realidade, por sua vez, é um pouco diferente:
Aqui está a atual rede de backbone Yandex na região. Todos os serviços Yandex funcionam em cima dele, parte da rede é usada pela nuvem. (Esta é uma imagem para uso interno, portanto, as informações de serviço são deliberadamente ocultas. No entanto, é possível estimar o número de nós e conexões.) A decisão de usar a rede de backbone era lógica: não podíamos inventar nada, mas reutilizar a infraestrutura atual - "sofrida" ao longo dos anos de desenvolvimento.
Qual é a diferença entre a primeira foto e a segunda? Antes de tudo, as zonas de acesso não estão diretamente relacionadas: sites técnicos estão localizados entre elas. Os sites não contêm equipamentos de servidor - apenas dispositivos de rede para garantir a conectividade. Os pontos de presença nos quais o Yandex e o Cloud se conectam ao mundo exterior são conectados a sites técnicos. Todos os pontos de presença funcionam para toda a região. A propósito, é importante observar que, do ponto de vista do acesso externo da Internet, todas as zonas de acesso à nuvem são equivalentes. Em outras palavras, eles fornecem a mesma conectividade - ou seja, a mesma velocidade e taxa de transferência, além de latências igualmente baixas.
Além disso, há equipamentos nos pontos de presença, aos quais - se houver recursos locais e um desejo de expandir a infraestrutura local com instalações em nuvem - os clientes podem se conectar por meio de um canal garantido. Isso pode ser feito com a ajuda de parceiros ou por conta própria.
A rede principal é usada pela nuvem como um transporte MPLS.
MPLS
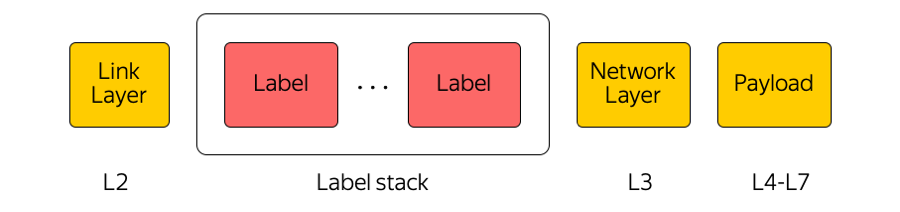
A comutação de etiquetas multiprotocolo é uma tecnologia amplamente usada em nossa indústria. Por exemplo, quando um pacote é transferido entre zonas de acesso ou entre uma zona de acesso e a Internet, o equipamento de transporte presta atenção apenas ao rótulo superior, "sem pensar" no que está por baixo. Dessa maneira, o MPLS permite ocultar a complexidade da nuvem da camada de transporte. Em geral, nós na nuvem gostamos muito do MPLS. Até fizemos parte do nível mais baixo e o usamos diretamente na fábrica de comutação no data center:

(Na verdade, existem muitos links paralelos entre comutadores Leaf e Spines.)
Por que MPLS?
É verdade que o MPLS geralmente não é encontrado em redes de data center. Muitas vezes, tecnologias completamente diferentes são usadas.
Usamos o MPLS por vários motivos. Primeiro, achamos conveniente unificar as tecnologias do plano de controle e do plano de dados. Ou seja, em vez de alguns protocolos na rede do data center, outros na rede principal e a junção desses protocolos - um único MPLS. Assim, unificamos a pilha tecnológica e reduzimos a complexidade da rede.
Em segundo lugar, na nuvem, usamos vários dispositivos de rede, como o Cloud Gateway e o Network Load Balancer. Eles precisam se comunicar, enviar tráfego para a Internet e vice-versa. Esses dispositivos de rede podem ser dimensionados horizontalmente com o aumento da carga e, como a nuvem é construída de acordo com o modelo de hiperconvergência, eles podem ser iniciados em absolutamente qualquer lugar do ponto de vista da rede no data center, ou seja, em um pool de recursos comum.
Portanto, esses dispositivos podem iniciar atrás de qualquer porta do comutador de rack em que o servidor está localizado e começar a se comunicar via MPLS com o restante da infraestrutura. O único problema na construção dessa arquitetura era o alarme.
Alarme
A pilha de protocolos MPLS clássica é bastante complexa. A propósito, essa é uma das razões da não proliferação do MPLS nas redes de data center.
Por sua vez, não usamos IGP (Interior Gateway Protocol), LDP (Label Distribution Protocol) ou outros protocolos de distribuição de etiquetas. Somente o Label-Unicast BGP (Border Gateway Protocol) é usado. Cada dispositivo, que é executado, por exemplo, como uma máquina virtual, cria uma sessão BGP antes do comutador Leaf montado em rack.
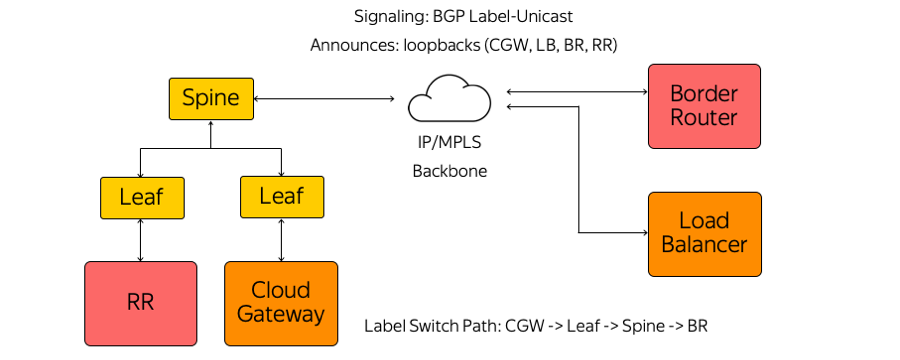
Uma sessão BGP é construída em um endereço pré-conhecido. Não há necessidade de configurar automaticamente o comutador para executar cada dispositivo. Todos os comutadores são pré-configurados e consistentes.
Dentro de uma sessão BGP, cada dispositivo envia seu próprio loopback e recebe loopbacks do restante dos dispositivos com os quais precisará trocar tráfego. Exemplos de tais dispositivos são vários tipos de refletores de rota, roteadores de borda e outros dispositivos. Como resultado, informações sobre como entrar em contato aparecem nos dispositivos. Do Cloud Gateway através do comutador Leaf, do comutador Spine e da rede até o roteador de borda, é criado um caminho de comutador de etiqueta. Os comutadores são comutadores L3 que se comportam como um roteador de comutador de etiquetas e não conhecem a complexidade que os cerca.
O MPLS em todos os níveis da nossa rede, entre outras coisas, nos permitiu usar o conceito de Coma seu próprio alimento para cães.
Coma seu próprio alimento para cães
Do ponto de vista da rede, esse conceito implica que vivemos na mesma infraestrutura que fornecemos ao usuário. Aqui estão diagramas de racks nas áreas de acessibilidade:

O host da nuvem leva a carga do usuário, contém suas máquinas virtuais. E, literalmente, um host vizinho em um rack pode transportar a carga da infraestrutura do ponto de vista da rede, incluindo refletores de rota, gerenciamento, servidores de monitoramento etc.
Por que isso foi feito? Houve uma tentação de executar refletores de rota e todos os elementos de infraestrutura em um segmento tolerante a falhas separado. Então, se o segmento de usuários quebrasse em algum lugar do data center, os servidores de infraestrutura continuariam a gerenciar toda a infraestrutura de rede. Mas essa abordagem nos pareceu cruel - se não confiamos em nossa própria infraestrutura, como podemos fornecê-la aos nossos clientes? Afinal, absolutamente toda a nuvem, todas as redes virtuais, serviços de usuário e nuvem trabalham em cima dela.
Portanto, abandonamos um segmento separado. Nossos elementos de infraestrutura são executados na mesma topologia e conectividade de rede. Naturalmente, eles são executados em uma instância tripla - assim como nossos clientes lançam seus serviços na nuvem.
Fábrica IP / MPLS
Aqui está um exemplo de diagrama de uma das zonas de disponibilidade:
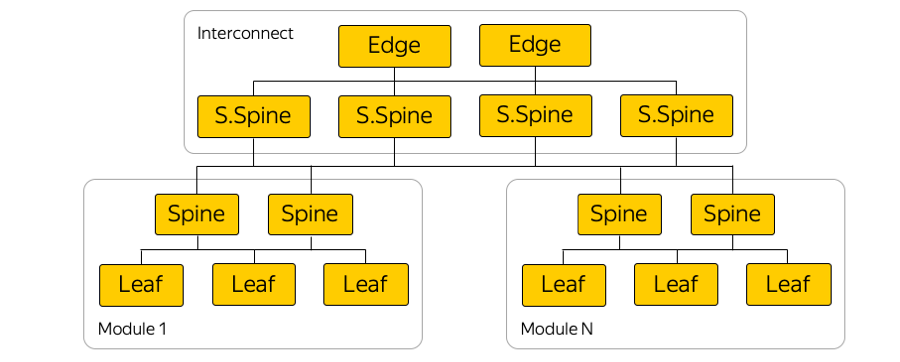
Em cada zona de disponibilidade, existem cerca de cinco módulos e, em cada módulo, cerca de cem racks. Switches montados em rack, em folha, são conectados em seu módulo pelo nível Spine, e a conectividade entre módulos é fornecida por meio da rede Interconnect. Este é o próximo nível, que inclui os chamados comutadores Super-Spines e Edge, que já conectam as zonas de acesso. Nós deliberadamente abandonamos o L2, estamos falando apenas da conectividade L3 IP / MPLS. O BGP é usado para distribuir informações de roteamento.
De fato, há muito mais conexões paralelas do que na figura. Um número tão grande de conexões ECMP (caminhos múltiplos de custo igual) impõe requisitos especiais de monitoramento. Além disso, há limites inesperados, à primeira vista, no equipamento - por exemplo, o número de grupos ECMP.
Conexão com o servidor
Devido a investimentos poderosos, o Yandex cria serviços de tal maneira que a falha de um servidor, rack de servidor, módulo ou mesmo de um datacenter inteiro nunca leva a uma parada completa do serviço. Se houver algum tipo de problema de rede - suponha que um switch de montagem em rack esteja quebrado - os usuários externos nunca verão isso.
Yandex.Cloud é um caso especial. Não podemos ditar ao cliente como criar seus próprios serviços e decidimos nivelar esse possível ponto único de falha. Portanto, todos os servidores na nuvem estão conectados a dois comutadores de montagem em rack.
Também não usamos protocolos de redundância no nível L2, mas imediatamente começamos a usar apenas L3 com BGP - novamente, por razões de unificação de protocolo. Essa conexão fornece a cada serviço conectividade IPv4 e IPv6: alguns serviços funcionam em IPv4 e alguns serviços em IPv6.
Fisicamente, cada servidor é conectado por duas interfaces de 25 gigabit. Aqui está uma foto do data center:

Aqui você vê dois comutadores de montagem em rack com portas de 100 gigabit. Cabos de interrupção divergentes são visíveis, dividindo a porta de 100 gigabit do switch em 4 portas de 25 gigabits por servidor. Chamamos esses cabos de "hidra".
Gerenciamento de infraestrutura
A infraestrutura de rede em nuvem não contém nenhuma solução de gerenciamento proprietária: todos os sistemas são de código aberto com personalização para a nuvem ou completamente auto-escritos.
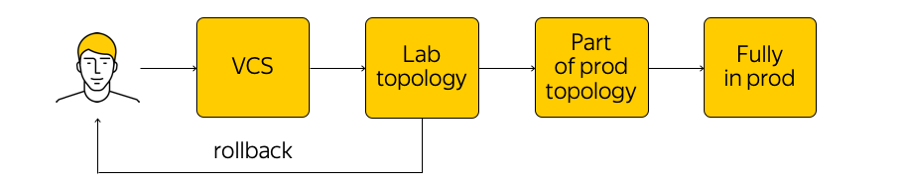
Como essa infraestrutura é gerenciada? Não é proibido na nuvem, mas é altamente desencorajado ir a um dispositivo de rede e fazer quaisquer ajustes. Existe o estado atual do sistema e precisamos aplicar as alterações: chegue a um novo estado de destino. “Executar um script” através de todas as glândulas, mude algo na configuração - você não deve fazer isso. Em vez disso, fazemos alterações nos modelos, em uma única fonte de sistema de verdade e comprometemos nossa alteração no sistema de controle de versão. Isso é muito conveniente, porque você sempre pode reverter o histórico, descobrir quem é responsável pelo commit, etc.
Quando fizemos as alterações, as configurações são geradas e as lançamos na topologia de teste de laboratório. Da perspectiva da rede, essa é uma pequena nuvem que repete completamente toda a produção existente. Veremos imediatamente se as alterações desejadas quebram algo: primeiro, pelo monitoramento e, segundo, pelo feedback de nossos usuários internos.
Se o monitoramento diz que tudo está calmo, continuamos implementando - mas aplicamos a alteração apenas a parte da topologia (duas ou mais acessibilidades “não têm o direito” de interromper pelo mesmo motivo). Além disso, continuamos a monitorar de perto o monitoramento. Este é um processo bastante complicado, sobre o qual falaremos abaixo.
Depois de garantir que tudo está bem, aplicamos a alteração a toda a produção. A qualquer momento, você pode reverter e retornar ao estado anterior da rede, rastrear e corrigir rapidamente o problema.
Monitoramento
Precisamos de um monitoramento diferente. Um dos mais procurados é o monitoramento da conectividade de ponta a ponta. A qualquer momento, cada servidor deve poder se comunicar com qualquer outro servidor. O fato é que, se houver um problema em algum lugar, queremos descobrir exatamente onde o mais cedo possível (ou seja, quais servidores têm problemas para acessar um ao outro). Garantir a conectividade de ponta a ponta é a nossa principal preocupação.
Cada servidor lista um conjunto de todos os servidores com os quais deve poder se comunicar a qualquer momento. O servidor pega um subconjunto aleatório desse conjunto e envia pacotes ICMP, TCP e UDP para todas as máquinas selecionadas. Isso verifica se há perdas na rede, se o atraso aumentou etc. A rede inteira é "chamada" dentro de uma das zonas de acesso e entre elas. Os resultados são enviados para um sistema centralizado que os visualiza para nós.
Aqui está a aparência dos resultados quando tudo não é muito bom:
Aqui você pode ver quais segmentos de rede há um problema entre (neste caso, A e B) e onde está tudo bem (A e D). Servidores específicos, comutadores montados em rack, módulos e zonas de disponibilidade inteiras podem ser exibidas aqui. Se alguma das alternativas acima se tornar a fonte do problema, nós a veremos em tempo real.
Além disso, há monitoramento de eventos. Monitoramos de perto todas as conexões, níveis de sinal nos transceptores, sessões BGP, etc. Suponha que três sessões BGP sejam construídas a partir de um segmento de rede, um dos quais foi interrompido à noite. Se configurarmos o monitoramento para que a queda de uma sessão do BGP não seja crítica para nós e possamos esperar até a manhã seguinte, o monitoramento não ativará os engenheiros de rede. Mas se a segunda das três sessões cair, um engenheiro liga automaticamente.
Além do monitoramento de ponta a ponta e de eventos, usamos uma coleção centralizada de logs, suas análises em tempo real e análises subsequentes. Você pode ver as correlações, identificar problemas e descobrir o que estava acontecendo no equipamento de rede.
O tópico de monitoramento é grande o suficiente, há uma enorme margem para melhorias. Eu quero trazer o sistema para uma maior automação e autocura verdadeira.
O que vem a seguir?
Temos muitos planos. É necessário melhorar os sistemas de controle, monitoramento, comutação de fábricas IP / MPLS e muito mais.
Também estamos buscando ativamente os interruptores de caixa branca. Este é um dispositivo "de ferro" pronto, um interruptor no qual você pode rolar o software. Em primeiro lugar, se tudo for feito corretamente, será possível "tratar" os comutadores da mesma maneira que nos servidores, criar um processo de CI / CD realmente conveniente, implementar configurações progressivamente, etc.
Em segundo lugar, se houver algum problema, é melhor manter um grupo de engenheiros e desenvolvedores que resolverão esses problemas do que esperar muito tempo por uma correção do fornecedor.
Para que tudo dê certo, o trabalho está em andamento em duas direções:
- Reduzimos significativamente a complexidade da fábrica de IP / MPLS. Por um lado, o nível da rede virtual e das ferramentas de automação disso, pelo contrário, se tornou um pouco mais complicado. Por outro lado, a própria rede subjacente ficou mais fácil. Em outras palavras, há uma certa "quantidade" de complexidade que não pode ser salva. Pode ser "lançado" de um nível para outro - por exemplo, entre níveis de rede ou do nível da rede para o nível do aplicativo. E você pode distribuir corretamente essa complexidade, o que estamos tentando fazer.
- E, claro, estamos finalizando nosso conjunto de ferramentas para gerenciar toda a infraestrutura.
Isso é tudo que queríamos falar sobre nossa infraestrutura de rede.
Aqui está um link para o canal Cloud Telegram com notícias e dicas.