Este artigo foi escrito em conjunto com ananaskelly .
1. Introdução
Olá pessoal, Habr! Trabalhando no Centro de Tecnologia da Fala de São Petersburgo, adquirimos um pouco de experiência na solução de problemas de classificação e detecção de eventos acústicos e decidimos que estamos prontos para compartilhá-lo com você. O objetivo deste artigo é apresentar algumas tarefas e falar sobre o concurso de processamento automático de som DCASE 2018 . Falando sobre o concurso, ficaremos sem fórmulas e definições complexas relacionadas ao aprendizado de máquina, para que o significado geral do artigo seja entendido por um amplo público .
Para aqueles que estavam interessados na montagem do classificador , preparamos um pequeno código python e, usando o link no github, você pode encontrar um notebook, onde usamos o exemplo da segunda faixa do concurso DCASE para criar uma rede convolucional simples em keras para classificar arquivos de áudio. Falamos um pouco sobre a rede e os recursos usados para o treinamento, e como usar uma arquitetura simples para obter um resultado próximo da linha de base ( MAP @ 3 = 0,6).
Além disso, abordagens básicas para solução de problemas (linha de base) propostas pelos organizadores serão descritas aqui. Também no futuro, haverá vários artigos nos quais falaremos com mais detalhes e detalhes, tanto sobre nossa experiência em participar da competição quanto sobre as soluções propostas por outros participantes da competição. Os links para esses artigos aparecerão gradualmente aqui.
Certamente, muitas pessoas não têm absolutamente nenhuma idéia sobre algum tipo de "DCASE" , então vamos descobrir que tipo de fruta é e com que é consumida. A competição “ DCASE ” é realizada anualmente, e todos os anos várias tarefas são dedicadas à resolução de problemas no campo da classificação de gravações de áudio e detecção de eventos acústicos. Qualquer pessoa pode participar da competição, é gratuita, basta basta se cadastrar no site como participante. Como resultado da competição, é realizada uma conferência sobre os mesmos tópicos, mas, diferentemente da competição em si, a participação já é paga, e não falaremos mais sobre isso. Geralmente, as recompensas pelas melhores decisões não são confiáveis, mas há exceções (por exemplo, a terceira tarefa em 2018). Este ano, os organizadores propuseram as 5 tarefas a seguir:
- Classificação de cenas acústicas (subdivididas em 3 subtarefas)
A. Conjuntos de dados de treinamento e teste registrados no mesmo dispositivo
B. conjuntos de dados de treinamento e teste registrados em diferentes dispositivos
C. O treinamento é permitido usando dados não fornecidos pelos organizadores - Classificação de Eventos Acústicos
- Detecção de canto de pássaros
- Detecção de eventos acústicos em casa usando um conjunto de dados com etiquetas fracas
- Classificação da atividade doméstica na sala de acordo com a gravação multicanal
Sobre detecção e classificação
Como podemos ver, os nomes de todas as tarefas contêm uma de duas palavras: "detecção" ou "classificação". Vamos esclarecer qual é a diferença entre esses conceitos para que não haja confusão.
Imagine que temos uma gravação de áudio na qual um cachorro late em um momento, e um gato mia em outro, e simplesmente não há outros eventos por lá. Então, se queremos entender exatamente quando esses eventos ocorrem, precisamos resolver o problema de detectar um evento acústico. Ou seja, precisamos descobrir os horários de início e fim de cada evento. Tendo resolvido o problema de detecção, descobrimos exatamente quando os eventos ocorrem, mas não sabemos quem exatamente faz os sons encontrados - precisamos resolver o problema de classificação, ou seja, determinar o que exatamente aconteceu em um determinado período de tempo.
Para entender a descrição das tarefas da competição, esses exemplos serão suficientes, o que significa que a parte introdutória está concluída e podemos prosseguir com uma descrição detalhada das próprias tarefas.
Faixa 1. Classificação de cenas acústicas
A primeira tarefa é determinar o ambiente (cena acústica) em que o áudio foi gravado, por exemplo, "Estação de Metrô", "Aeroporto" ou "Rua de Pedestres". A solução para esse problema pode ser útil na avaliação do ambiente com um sistema de inteligência artificial, por exemplo, em carros com piloto automático.
Nesta tarefa, os conjuntos de dados TUT Urban Acoustic Scenes 2018 e TUT Urban Acoustic Scenes 2018 Mobile, que foram preparados pela Universidade de Tecnologia de Tampere (Finlândia), foram apresentados para treinamento. Uma descrição detalhada da preparação do conjunto de dados, bem como a solução básica, é descrita no artigo .
No total, 10 cenas acústicas foram apresentadas para a competição, que os participantes tiveram que prever.
Subtarefa A
Como já dissemos, a tarefa é dividida em três subtarefas, cada uma das quais difere na qualidade das gravações de áudio. Por exemplo, na subtarefa A, foram usados microfones especiais para gravação, localizados nos ouvidos humanos. Assim, a gravação estéreo foi aproximada da percepção humana do som. Os participantes tiveram a oportunidade de usar essa abordagem para gravar, a fim de melhorar a qualidade do reconhecimento da cena acústica.
Subtarefa B
Na subtarefa B, outros dispositivos (por exemplo, telefones celulares) também foram usados para gravação. Os dados da subtarefa A foram convertidos para um formato mono, a frequência de amostragem foi reduzida, não há simulação da “audibilidade” do som por uma pessoa no conjunto de dados para esta tarefa, mas há mais dados para treinamento.
Subtarefa C
O conjunto de dados da subtarefa C é o mesmo da subtarefa A, mas, ao resolver esse problema, é permitido o uso de quaisquer dados externos que o participante possa encontrar. O objetivo de resolver esse problema é descobrir se é possível melhorar o resultado obtido na subtarefa A usando dados de terceiros.
A qualidade das decisões nessa trilha foi avaliada pela métrica Precisão .
A linha de base para esta tarefa é uma rede neural convolucional de duas camadas que aprende com os logaritmos de pequenos espectrogramas dos dados de áudio originais. A arquitetura proposta usa as técnicas padrão de BatchNormalization e Dropout. O código no GitHub pode ser visto aqui .
Faixa 2. Classificação de Eventos Acústicos
Nesta tarefa, propõe-se criar um sistema que classifique eventos acústicos. Esse sistema pode ser um complemento para residências inteligentes, aumentar a segurança em locais lotados ou facilitar a vida de pessoas com deficiência auditiva.
O conjunto de dados para esta tarefa consiste em arquivos retirados do conjunto de dados Freesound e marcados com tags do AudioSet do Google. Mais detalhadamente, o processo de preparação do conjunto de dados é descrito por um artigo preparado pelos organizadores do concurso.
Vamos voltar à tarefa em si, que possui vários recursos.
Primeiramente, os participantes tiveram que criar um modelo capaz de identificar diferenças entre eventos acústicos de natureza muito diferente. O conjunto de dados é dividido na classe 41, apresenta vários instrumentos musicais, sons produzidos por humanos, animais, sons domésticos e muito mais.
Em segundo lugar, além da marcação usual dos dados, também há informações adicionais sobre a verificação manual do rótulo. Ou seja, os participantes sabem quais arquivos do conjunto de dados foram verificados pela pessoa quanto à conformidade com o rótulo e quais não são. Como a prática demonstrou, os participantes que de alguma forma usaram essas informações adicionais receberam prêmios na solução desse problema.
Além disso, deve-se dizer que a duração dos registros no conjunto de dados varia muito: de 0,3 segundos a 30 segundos. Nesse problema, a quantidade de dados por classe, na qual o modelo precisa ser treinado, também varia bastante. Isso é melhor representado como um histograma, o código de construção que é retirado daqui .
Como você pode ver no histograma, a marcação manual para as aulas apresentadas também é desequilibrada, o que aumenta a dificuldade se você quiser usar essas informações ao treinar modelos.
Os resultados nesta trilha foram avaliados usando a métrica de precisão média (Mean Mean Precision, MAP @ 3), uma demonstração bastante simples do cálculo dessa métrica com exemplos e código pode ser encontrada aqui .
Faixa 3. Detecção de canto de pássaros
A próxima faixa é a detecção do canto dos pássaros. Um problema semelhante surge, por exemplo, em vários sistemas de monitoramento automático da vida selvagem - este é o primeiro passo no processamento de dados antes, por exemplo, da classificação. Tais sistemas geralmente precisam de ajuste, são instáveis a novas condições acústicas, portanto, o objetivo desta faixa é recorrer ao poder do aprendizado de máquina para resolver esses problemas.
Esta faixa é uma versão estendida do concurso "Desafio de detecção de áudio de pássaros" , organizado pela Universidade de St Mary em Londres em 2017/2018. Para os interessados , você pode ler o artigo dos autores da competição, que fornece detalhes sobre a formação dos dados, a organização da própria competição e uma análise das decisões tomadas.
No entanto, de volta à tarefa DCASE. Os organizadores forneceram seis conjuntos de dados - três para treinamento e três para teste - todos eles são muito diferentes - gravados em diferentes condições acústicas, usando vários dispositivos de gravação, e no fundo existem vários ruídos. Portanto, a mensagem principal é que o modelo não deve depender do ambiente ou ser capaz de se adaptar a ele. Apesar de o nome significar “detecção”, a tarefa não é determinar os limites do evento, mas em uma classificação simples - a solução final é um tipo de classificador binário que recebe uma entrada curta de áudio e decide se há ou não canto de pássaro. . A métrica da AUC foi usada para avaliar a precisão.
Principalmente, os participantes tentaram obter generalização e adaptação através de vários aprimoramentos de dados. Um dos comandos descreve a aplicação de várias técnicas - alteração da resolução de frequência nos recursos extraídos, redução preliminar de ruído, um método de adaptação baseado no alinhamento de estatísticas de segunda ordem para diferentes conjuntos de dados. No entanto, esses métodos, bem como diferentes tipos de aumento, proporcionam um aumento muito pequeno em relação à solução básica, como observam muitos participantes.
Como solução básica, os autores prepararam uma modificação da solução mais bem-sucedida da competição original "Desafio de detecção de áudio de pássaros". O código, como sempre, está disponível no github .
Faixa 4. Detecção de eventos acústicos em casa usando um conjunto de dados com etiquetas fracas.
Na quarta faixa, o problema de detecção já está resolvido diretamente. Os participantes receberam um conjunto de dados relativamente pequeno de dados marcados - um total de 1578 gravações de áudio de 10 segundos cada, com apenas marcação de classe: sabe-se que o arquivo contém um ou mais eventos dessas classes, mas não há marcação temporária. Além disso, foram fornecidos dois grandes conjuntos de dados de dados não alocados - 14412 arquivos contendo eventos de destino das mesmas classes que nas amostras de treinamento e teste, além de 39999 arquivos contendo eventos arbitrários que não foram incluídos nos destinos. Todos os dados são um subconjunto do enorme conjunto de dados do audioset compilado pelo google .
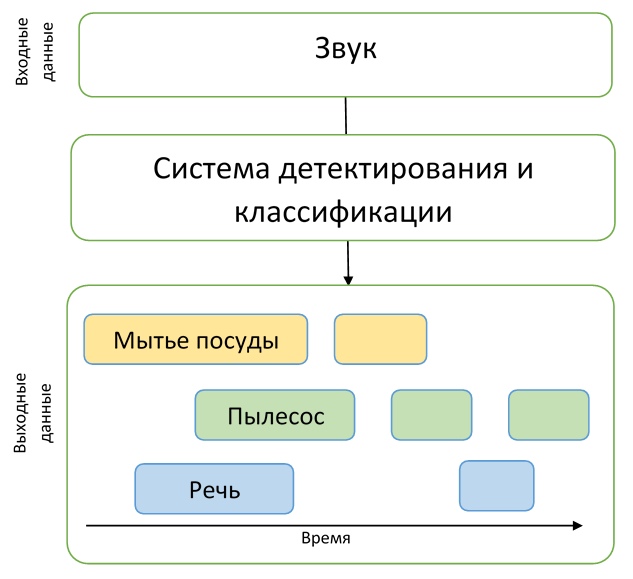
Assim, os participantes precisavam criar um modelo capaz de aprender com dados fracamente rotulados para encontrar registros de data e hora do início e final dos eventos (os eventos podem se sobrepor) e tentar aprimorá-lo com uma grande quantidade de dados adicionais não marcados. Além disso, vale a pena notar que uma métrica bastante rígida foi usada nessa faixa - era necessário prever os rótulos de tempo dos eventos com uma precisão de 200 ms. Em geral, os participantes tiveram que resolver uma tarefa bastante difícil de criar um modelo adequado, praticamente sem ter bons dados para o treinamento.
A maioria das soluções foi baseada em redes de recorrência convolucionais - uma arquitetura bastante popular no campo de detecção de eventos acústicos recentemente (um exemplo pode ser lido aqui ).
A solução básica dos autores, também em redes recursivas convolucionais, é baseada em dois modelos. Os modelos têm quase a mesma arquitetura: três camadas convolucionais e uma recursiva. A única diferença são as redes de saída. O primeiro modelo é treinado para marcar dados não alocados para expandir o conjunto de dados original - portanto, na saída, temos classes presentes no arquivo de evento. O segundo é para resolver o problema de detecção diretamente, ou seja, na saída, obtemos uma marcação temporária para o arquivo. Código para o link .
Faixa 5. Classificação da atividade doméstica na sala de acordo com a gravação multicanal.
A última faixa diferia das outras principalmente porque os participantes receberam gravações multicanais. A tarefa em si estava na classificação: é necessário prever a classe de eventos que ocorreram no registro. Diferentemente da faixa anterior, a tarefa é um pouco mais simples - sabe-se que há apenas um evento no registro.
O conjunto de dados é representado por aproximadamente 200 horas de gravações em um conjunto de microfones lineares de 4 microfones. Eventos são todos os tipos de atividades cotidianas - cozinhar, lavar a louça, atividade social (falar ao telefone, visitas e conversas pessoais), etc., também é destacada a classe de ausência de qualquer evento.
Os autores da faixa enfatizam que as condições da tarefa são relativamente simples, de modo que os participantes se concentram diretamente no uso de informações espaciais de gravações multicanal. Os participantes também tiveram a oportunidade de usar dados adicionais e modelos pré-treinados. A qualidade foi avaliada de acordo com a medida F1.
Como solução básica, os autores da faixa propuseram uma rede convolucional simples com duas camadas convolucionais. Em sua solução, as informações espaciais não foram usadas - os dados de quatro microfones foram usados para o treinamento de forma independente e as previsões foram calculadas em média durante o teste. Descrição e código estão disponíveis no link .
Conclusão
No artigo, tentamos falar brevemente sobre a detecção de eventos acústicos e sobre uma competição como o DCASE. Talvez eles tenham conseguido interessar alguém para participar de 2019 - a competição começa em março.