Olá novamente!
Colegas, no último dia de janeiro, estamos lançando o curso
"MS SQL Server Developer" , em conexão com o qual tivemos uma lição temática em aberto. Nele, falamos sobre como o MS SQL Server executa uma consulta SELECT, discutimos em que ordem e o que é analisado, e também mergulhamos um pouco na leitura do plano de consulta.
Palestrante -
Kristina Kucherova , arquiteta de modelo de dados no Sberbank da Rússia.
Objetivos e rota do seminário on-lineOs seguintes objetivos foram definidos no início do webinar:
- Veja como o servidor executa a solicitação e por que isso acontece dessa maneira
- Aprendendo a ler um plano de consulta.
Para alcançá-los, o professor preparou uma rota simples, mas eficaz:
 Por que preciso de um plano de consulta?
Por que preciso de um plano de consulta?O plano de consulta é uma ferramenta muito útil que, infelizmente, muitos desenvolvedores não usam. À primeira vista, pode parecer que não é necessário conhecer a mecânica da solicitação. No entanto, se você entender o que está acontecendo no SQL Server, poderá escrever uma consulta mais eficiente. E isso ajudará muito, por exemplo, durante a otimização.
Como vemos uma consulta SELECT?Vamos ver como é a consulta SELECT:
SELECT [campo1], [campo2] ...
| Quais campos nós escolhemos?
|
FROM [tabela]
| De onde
|
ONDE [condições]
| Onde estão as condições
|
GRUPO POR [campo1]
| Agrupar por campos
|
TENDO [condições]
| Tendo tais e tais condições
|
PEDIDO POR [campo1]
| Ordenação (classificação)
|
Como entender para onde ir para dados?A primeira coisa que o servidor tenta entender quando chega uma solicitação é para onde ir para os dados. O comando FROM responde a essa pergunta, porque é aqui que teremos uma lista de tabelas (ou o nome de uma tabela).
Para maior clareza, vamos imaginar que nosso servidor é uma espécie de mordomo, a quem pedimos para nos coletar nas férias. Assim, o mordomo começa a pensar, mas em que armário estão as coisas necessárias (em qual tabela você precisa levar os dados)? E para que nosso mordomo possa concluir facilmente sua tarefa, usamos FROM.
 Como entender quais dados levar?
Como entender quais dados levar?Digamos que o mordomo encontrou o armário certo e o abriu. Mas que coisas levar? Talvez nós estamos indo para uma estação de esqui? Ou talvez em uma praia ensolarada e quente? Para fazer com que nossas coisas correspondam ao clima, o comando WHERE é útil para nós, que define as condições, ou seja, permite filtrar os dados. Se estiver quente, pegamos ardósias, camisas e roupas de banho, se estiver frio - luvas, meias de malha, blusas)).
O próximo passo é anexar esses dados a grupos, o que acontece com GROUP BY (camisetas separadamente, meias separadamente). De acordo com os resultados do agrupamento, mais uma condição pode ser imposta usando HAVING (por exemplo, eliminando coisas não pareadas). No final, adicionamos tudo usando ORDER BY, obtendo a mala finalizada das coisas na saída, ou melhor, um bloco de dados ordenados.

A propósito, há uma nuance, mas consiste no fato de que há uma diferença de quais condições devem ser escritas em WHERE e quais em HAVING. Mas isso é melhor ver no vídeo.
Nós continuamos. O caminho de execução da solicitação é salvo
como um plano de solicitação no cache, ou seja, nosso mordomo anota tudo, porque ele é um bom mordomo - e se você quiser repetir seu pedido no próximo ano? E tais planos, em princípio, podem ser muitos.
Tipos de conexões no plano de consultaExistem três conexões que você pode encontrar em termos de consulta:
- Loop aninhado.
- Mesclar junção.
- Hash join.
Antes de abordar cada um deles com mais detalhes, vamos resumir por que deveríamos ler o plano de consulta. Isso é realmente muito útil, pois você aprenderá:
- qual índice é usado;
- em que ordem se juntam;
- o que é selecionado no buffer;
- quanto o servidor gasta recursos na operação;
- qual é a diferença entre um plano hipotético e um real?
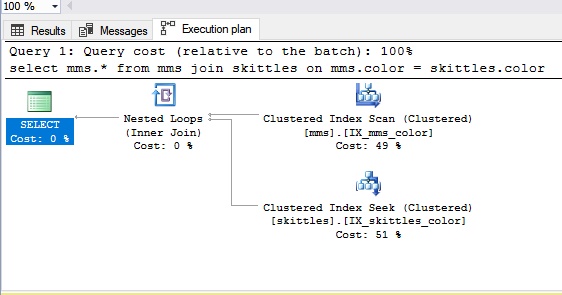
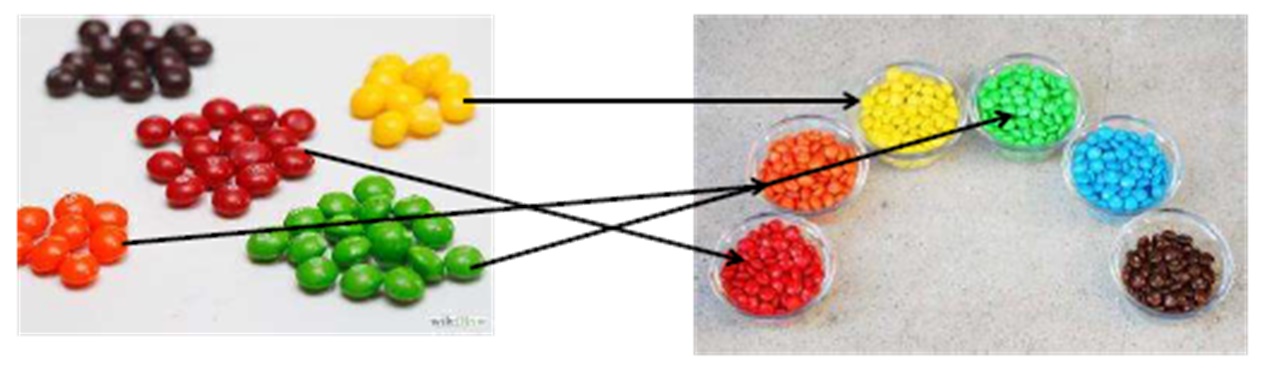
Loop aninhadoDigamos que precisamos unir dados de tabelas diferentes. Vamos apresentar essas tabelas como ... uma pequena quantidade de chocolates Skittles e a embalagem completa da M&M.

Ao conectar um tipo Nested Loop, pegamos o doce Skittles e depois pegamos o doce cego do pacote da M&M. Se não encontrarmos um doce da mesma cor (essa é a nossa condição), obtemos o próximo, ou seja, há um busto comum. Como resultado, podemos dizer que a conexão Nested Loop é mais adequada para pequenas quantidades de dados. Obviamente, se houver muitos dados, interromper não é a melhor opção.

Vamos ver como fica no painel SQL:
 Mesclar junção
Mesclar junçãoUma conexão é usada para grandes quantidades de dados. Quando você tem uma junção de mesclagem, as duas tabelas têm um índice pelo qual elas podem ser unidas. No caso dos doces, é como se os tivéssemos organizado previamente por cor.
É assim:

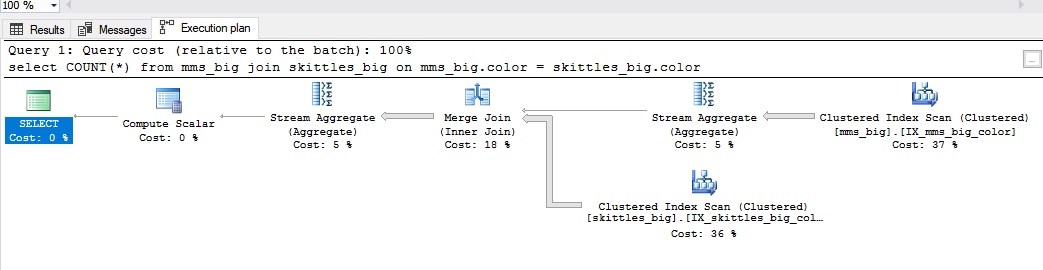
A junção de mesclagem é boa nos seguintes casos:
- grandes conjuntos de dados;
- os mesmos campos de conexão do mesmo tipo;
- os campos de conexão possuem índices.
Hash joinA junção de hash é usada para grandes quantidades de dados não classificadas. Para ingressar nas tabelas nesse caso, você precisa criar algo que imite o índice.
Exemplo de junção de hash:
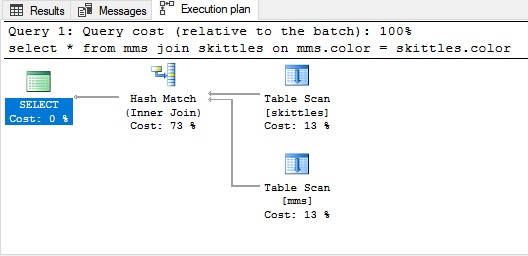
Para maior clareza, lembramos nossos doces:

O uso da junção Hash envolve 2 fases de ação:
- Compilar - uma tabela de hash é criada na menor tabela. Para cada valor na tabela nº 1, um hash é considerado. O valor é armazenado em uma tabela de hash e o hash calculado é usado como uma chave.
- Sonda. Para cada linha da tabela nº 2, o valor do hash é calculado para os campos especificados em junção (operador =). Um hash é pesquisado na tabela de hash, os valores do campo são verificados.
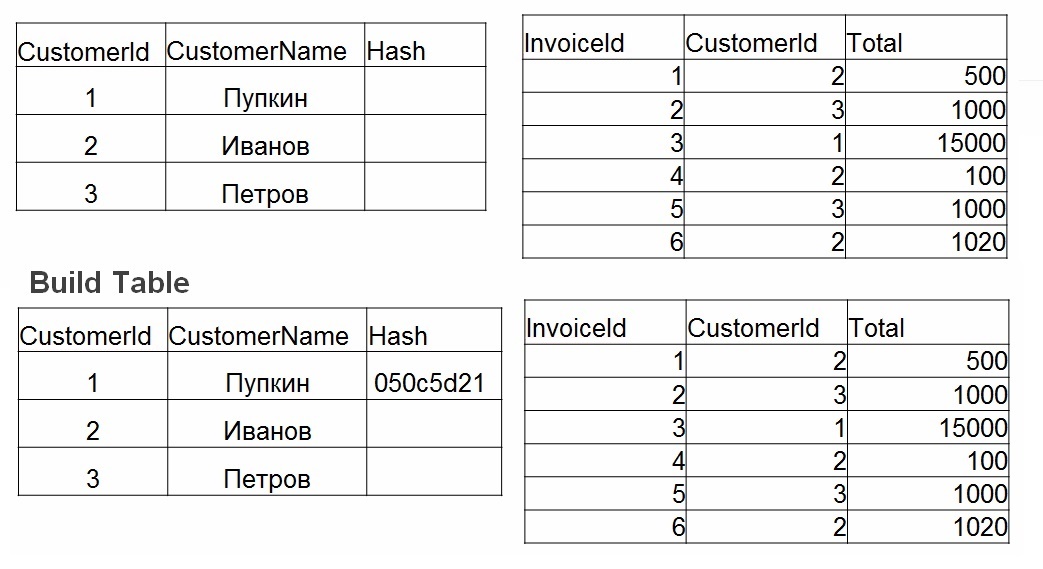
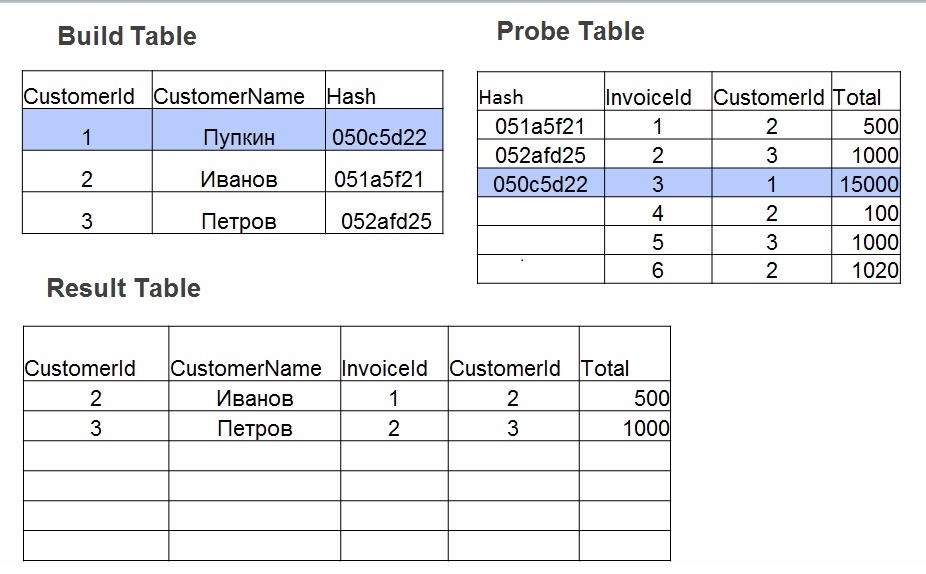
Quando a junção de hash é boa:
- grande conjunto de dados;
- sem índices marginais.
Um ponto importante: se não houver memória suficiente, a gravação irá para tempdb - para disco.
Amigos, além do exposto, a lição aberta também incluiu outros pontos interessantes, que são melhor visualizados ao assistir ao vídeo. Sugerimos visitar o
dia aberto do curso "MS SQL Server Developer", onde você pode fazer ao professor todas as suas perguntas.
A professora do PS
Kristina Kucherova agradece a Jes Schultz Borland por sua
apresentação com os Planos de Execução do PASS Summitt: O Segredo para o Sucesso do Ajuste de Consultas, que foi usado na preparação da lição aberta.