Olá Habr!
Em dezembro, nosso colega da Advanced Analytics, Leonid Sherstyuk, conquistou o primeiro lugar na competência Machine Learning e Big Data no 2º campeonato da indústria de DigitalSkills. Este é um ramo “digital” de concursos profissionais conhecidos, organizados pela WorldSkills Russia. No total, mais de 200 pessoas participaram do campeonato, competindo pela liderança em 25 competências digitais - proteção corporativa contra ameaças à segurança interna, marketing na Internet, desenvolvimento de jogos de computador e aplicativos multimídia, tecnologias quânticas, internet das coisas, design industrial, etc.

Como um caso de aprendizado de máquina, foi proposta a tarefa de monitorar e detectar defeitos em oleodutos de usinas nucleares, oleodutos e gasodutos usando um sistema de testes ultrassônicos semiautomáticos.
Leonid vai contar sobre o que estava na competição e como ele conseguiu vencer sob o corte.
A WorldSkills é uma organização internacional que organiza concursos de habilidades profissionais em todo o mundo. Tradicionalmente, representantes de empresas industriais e estudantes de universidades relevantes participavam dessas competições, demonstrando suas habilidades em especialidades de trabalho. Recentemente, começaram a aparecer indicações digitais na competição, onde jovens especialistas competem nas habilidades de robótica, desenvolvimento de aplicativos, segurança da informação e em outras profissões que você nem pode chamar de trabalhadores. Em uma dessas indicações - em Machine Learning e trabalhando com big data - participei de Kazan no concurso DigitalSkills, realizado sob os auspícios do WS.
Como a competência para a competição é nova, era difícil para mim imaginar o que esperar. Por precaução, repeti tudo o que sei sobre trabalhar com bancos de dados e computação distribuída, métricas e algoritmos de treinamento, critérios estatísticos e métodos de pré-processamento. Por estar familiarizado com os critérios de avaliação aproximados, não entendi como seria possível ajustar um trabalho completo com o Hadoop e criar um bot de bate-papo em 6 sessões curtas.
Toda a competição dura 3 dias, em 6 sessões. Cada sessão dura 3 horas com um intervalo, para o qual você precisa concluir várias tarefas que estão significativamente relacionadas uma à outra. A princípio, pode parecer que o tempo é suficiente, mas, na realidade, demorou um ritmo frenético para conseguir fazer tudo o que era concebido.
Na competição, esperava-se que não se trabalhasse com big data, e todo o conjunto de tarefas foi reduzido para analisar um conjunto de dados limitado.
De fato, fomos solicitados a repetir o caminho de um dos organizadores, para o qual os clientes vieram com seus problemas e dados e de quem esperavam uma oferta comercial dentro de algumas semanas.
Trabalhamos com os dados do PUZK (sistema de controle ultrassônico semiautomático). O sistema foi projetado para verificar as juntas na tubulação quanto a trincas e defeitos. A instalação em si viaja ao longo de um trilho montado no tubo e, em cada etapa, faz 16 medições. Sob condições ideais e na ausência de defeitos, alguns sensores devem dar o sinal máximo, outros - zero; na realidade, os dados eram muito barulhentos, e responder à pergunta se havia um defeito em um determinado local tornou-se uma tarefa não trivial.
 Instalação do sistema PUZK
Instalação do sistema PUZKO primeiro dia foi dedicado a conhecer os dados, limpá-los e compilar estatísticas descritivas. Recebemos informações mínimas básicas sobre a instalação e os tipos de sensores montados no dispositivo. Além do pré-processamento de dados, tivemos que estabelecer de que tipo os sensores pertencem e como eles estão localizados no dispositivo.
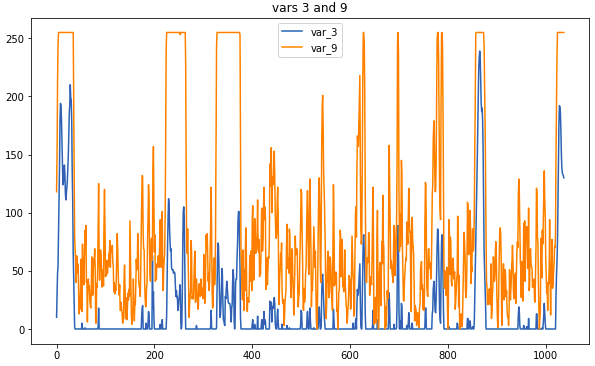 Dados de amostra: é assim que os sensores relacionados ficam
Dados de amostra: é assim que os sensores relacionados ficamA principal operação de pré-processamento está substituindo as medições por uma média móvel. Se a janela fosse muito grande, havia o risco de perder muitas informações, mas as correlações que ajudam a determinar o tipo seriam mais visuais. Algumas conexões eram visíveis sem pré-processamento; no entanto, não houve tempo para examinar cuidadosamente os dados brutos; portanto, o uso de correlogramas é indispensável.
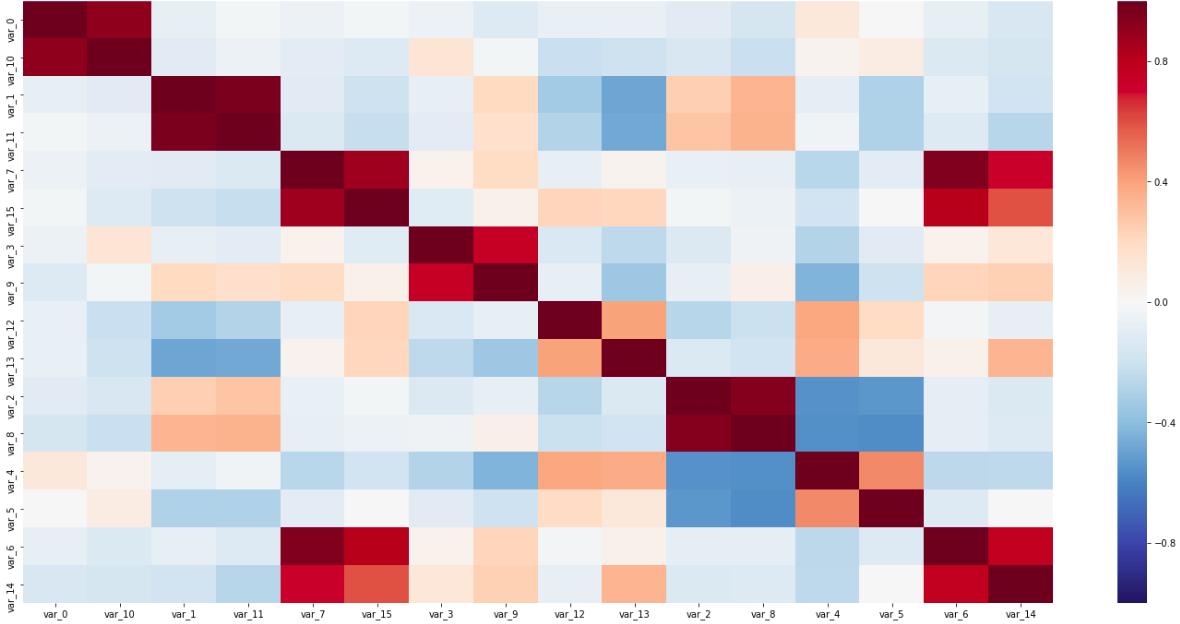 Matriz de correlação
Matriz de correlaçãoNesta matriz, ambos os pares de sensores ao longo da diagonal, intimamente conectados entre si, e variáveis inversamente correlacionadas são visíveis; Tudo isso ajudou a determinar os tipos de sensores.
O último item obrigatório foi reduzir os sensores para uma coordenada. Como o dispositivo de medição era significativamente mais do que uma etapa de medição e os sensores estavam espaçados em todo o dispositivo, essa era uma etapa obrigatória antes do uso adicional de dados para treinamento.
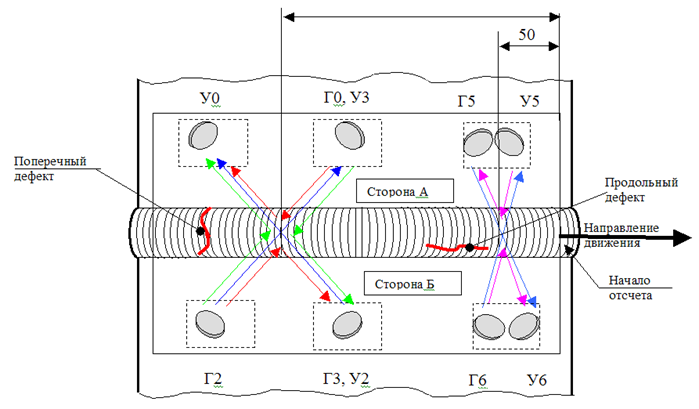
\
Arranjo de sensores na instalaçãoO diagrama da instalação dos sensores no dispositivo mostra que precisamos encontrar as distâncias entre os três grupos de sensores. A maneira mais fácil e rápida aqui é estabelecer em qual segmento do dispositivo cada sensor deve estar e, em seguida, procurar a correlação máxima, deslocando parte das medições em uma etapa.
Esse estágio foi complicado pelo fato de minhas suposições sobre o tipo de sensores não serem garantidas; portanto, tive que examinar todas as correlações, tipos, esquema e vincular isso a um único sistema consistente.
No segundo dia, tivemos que preparar os dados para treinamento e realizar o agrupamento de pontos e, em seguida, criar um classificador.
Durante a preparação dos dados, removi leituras correlativas demais e, como recurso sintético, adicionei a média móvel, derivada e escore z. Sem dúvida, a síntese de novas variáveis poderia ser bastante ampla, mas o tempo impôs suas limitações.
O agrupamento pode ajudar a separar os pontos defeituosos de todos os outros. Eu tentei 3 métodos: k-means, Birch e DBScan, mas, infelizmente, nenhum deles deu um bom resultado.
Para o algoritmo preditivo, recebemos total liberdade; somente o formato que deve ser obtido na saída foi especificado. O algoritmo deveria fornecer uma tabela (ou dados redutíveis), na qual uma linha corresponde a uma trinca e às colunas suas características (como comprimento, largura, tipo e lado). Pareceu-me a opção mais simples, na qual fazemos uma previsão para cada ponto da amostra de teste e depois combinamos os vizinhos em uma única fenda. Como resultado, fiz 3 classificadores que responderam às seguintes perguntas: de que lado da costura está o defeito, qual a profundidade e qual o tipo (longitudinal ou transversal).
Aqui, a profundidade que deve ser prevista pela regressão é impressionante; no entanto, na amostra rotulada, encontrei apenas 5 profundidades únicas e achei essa simplificação aceitável.
 Métricas de Avaliação de Algoritmos
Métricas de Avaliação de AlgoritmosDe todos os algoritmos (consegui tentar regressão logística, árvore decisiva e aumento de gradiente), o aumento, como esperado, foi o melhor. As métricas são, sem dúvida, muito agradáveis, mas é bastante difícil avaliar a operação dos algoritmos sem resultados em um novo conjunto de testes. Os organizadores nunca retornaram com métricas específicas, limitando-se a um comentário geral de que ninguém fez o teste nem a uma amostra atrasada.
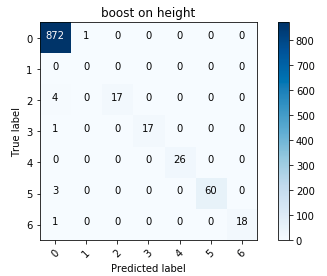 Matriz de erro para aumentar
Matriz de erro para aumentarEm geral, fiquei satisfeito com os resultados; em particular, reduzir a altura a uma variável categórica valida a pena.
No último dia, tivemos que agrupar os algoritmos treinados em um produto que um cliente em potencial poderia usar e preparar uma apresentação de nossa solução pronta para a empresa.
Aqui, o perfeccionismo me ajudou a escrever um código relativamente limpo, que não desapareceu nem em um tempo limitado. A partir dos códigos prontos, o protótipo se desenvolveu rapidamente e tive tempo para depurar os erros. Ao contrário dos estágios anteriores, aqui o desempenho da solução desempenhou um papel mais importante, em vez de atender aos critérios formais.
 Produto acabado - Utilitário CLI
Produto acabado - Utilitário CLINo final da sessão, recebi um utilitário CLI que aceita uma pasta de origem como entrada e retorna tabelas com resultados de previsão de uma forma conveniente para o tecnólogo.
Na fase final, tive a oportunidade de conversar sobre meus sucessos e ver o que outros participantes obtiveram. Mesmo sob critérios rigorosos, nossas decisões eram completamente diferentes - alguém agrupado com sucesso, outros usavam habilmente métodos lineares. Durante as apresentações, os concorrentes concentraram-se em seus pontos fortes - alguns dedicados à venda do produto, outros mais profundamente imersos em detalhes técnicos; Havia belos gráficos e interfaces de solução adaptáveis.
 A principal vantagem da minha solução se encaixa em um slide
A principal vantagem da minha solução se encaixa em um slideE a competição em geral?
Competições desse tipo são uma excelente oportunidade para descobrir com que rapidez você é capaz de executar tarefas típicas de sua especialidade. Os critérios foram compilados de forma que quem obtém os melhores resultados (como, por exemplo, no Kaggle) obtém mais pontos, mas quem provavelmente executa operações típicas do trabalho diário na indústria. Na minha opinião, a participação e a vitória em tais competições podem dizer a um potencial empregador nada menos que a experiência na indústria, na hackathons e na Kaggle.
Lenonid Sherstyuk,
Analista de dados, análise avançada, SIBUR