Nos artigos anteriores, eles já escreveram sobre como nossa tecnologia de reconhecimento de texto funciona:
Até 2018, o reconhecimento de caracteres japoneses e chineses era organizado da mesma maneira: primeiro, usando classificadores raster e de recursos. Mas com o reconhecimento de hieróglifos, existem dificuldades:
- Um grande número de classes que precisam ser distinguidas.
- Caractere de dispositivo mais complexo como um todo.

É tão difícil dizer inequivocamente quantos caracteres o alfabeto chinês tem por escrito, como é preciso contar quantas palavras em russo. Mas na maioria das vezes, na escrita chinesa, são usados ~ 10.000 caracteres. Com eles, limitamos o número de classes usadas no reconhecimento.
Ambos os problemas descritos acima também levam ao fato de que, para obter alta qualidade, é necessário usar um grande número de sinais e esses sinais são calculados nas imagens dos personagens por mais tempo.
Para que esses problemas não levassem a lentidão severa em todo o sistema de reconhecimento, tive que usar muitas heurísticas, principalmente destinadas a eliminar rapidamente um número significativo de hieróglifos, com os quais essa imagem definitivamente não se parece. Ainda não ajudou até o fim, mas queríamos levar nossa tecnologia a um nível totalmente novo.
Começamos a estudar a aplicabilidade de redes neurais convolucionais, a fim de aumentar a qualidade e a velocidade do reconhecimento de hieróglifos. Eu queria substituir a unidade inteira por reconhecer um único caractere para esses idiomas com a ajuda de redes neurais. Neste artigo, descreveremos como finalmente obtivemos sucesso.
Uma abordagem simples: uma rede de convolução para reconhecer todos os hieróglifos
Em geral, o uso de redes convolucionais para o reconhecimento de caracteres não é uma idéia nova.
Historicamente, eles foram usados pela
primeira vez precisamente para essa tarefa em 1998. É verdade que não eram caracteres impressos, mas números e letras inglesas manuscritas.
Ao longo de 20 anos, a tecnologia no campo da aprendizagem profunda, é claro, avançou. Incluindo arquiteturas mais avançadas e novas abordagens para o aprendizado.
A arquitetura apresentada no diagrama acima (LeNet), de fato, e hoje é muito adequada para tarefas simples como reconhecimento de texto impresso. “Simples” eu chamo isso em comparação com outras tarefas da visão computacional, como busca e reconhecimento de rostos.
Parece que a solução não está em lugar nenhum mais simples. Pegamos uma rede neural, uma amostra de hieróglifos rotulados e a treinamos para o problema de classificação. Infelizmente, descobriu-se que nem tudo é tão simples. Todas as modificações possíveis do LeNet para a tarefa de classificar 10.000 hieróglifos não forneceram qualidade suficiente (pelo menos comparável ao sistema de reconhecimento que já possuímos).
Para alcançar a qualidade exigida, tivemos que considerar arquiteturas mais profundas e mais complexas: WideResNet, SqueezeNet etc. Com a ajuda deles, foi possível atingir o nível de qualidade exigido, mas eles causaram uma forte redução na velocidade - 3-5 vezes em comparação com o algoritmo básico na CPU.
Alguém pode perguntar: “Qual é o sentido de medir a velocidade da rede na CPU, se funcionar muito mais rápido no processador gráfico (GPU)”? Aqui vale a pena fazer uma observação sobre o fato de que a velocidade do algoritmo na CPU é principalmente importante para nós. Estamos desenvolvendo tecnologia para a grande linha de produtos de reconhecimento da ABBYY. No maior número de cenários, o reconhecimento é feito no lado do cliente e não podemos saber se ele possui uma GPU.
Então, no final, chegamos ao seguinte problema: uma rede neural para reconhecer todos os caracteres, dependendo da escolha da arquitetura, funciona muito mal ou muito devagar.
Modelo de reconhecimento de hieróglifo de rede neural de dois níveis
Eu tive que procurar outro caminho. Ao mesmo tempo, não queria abandonar as redes neurais. Parecia que o maior problema era um grande número de classes, por causa das quais era necessário construir redes de arquitetura complexa. Portanto, decidimos que não treinaríamos uma rede para um grande número de classes, ou seja, para todo o alfabeto, mas, em vez disso, treinaríamos muitas redes para um pequeno número de classes (subconjuntos do alfabeto).
Em detalhes gerais, o sistema ideal foi apresentado da seguinte forma: o alfabeto é dividido em grupos de caracteres semelhantes. A rede de primeiro nível classifica a qual grupo de caracteres uma determinada imagem pertence. Para cada grupo, por sua vez, é treinada uma rede de segundo nível, que produz a classificação final dentro de cada grupo.
Imagem clicável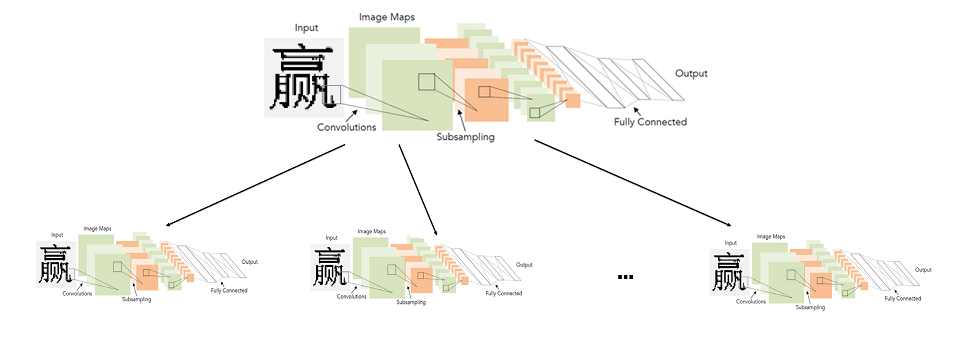
Assim, fazemos a classificação final lançando duas redes: a primeira determina qual rede de segundo nível lançar e a segunda já faz a classificação final.
Na verdade, o ponto fundamental aqui é como dividir os personagens em grupos, para que a rede de primeiro nível seja precisa e rápida.
Construindo um classificador de primeiro nível
Para entender quais símbolos de rede são mais fáceis de distinguir e quais são mais difíceis, é mais fácil observar quais sinais se destacam para símbolos específicos. Para fazer isso, pegamos uma rede classificadora treinada para distinguir todos os caracteres do alfabeto com boa qualidade e analisamos as estatísticas de ativação da penúltima camada dessa rede - começamos a examinar as representações finais dos recursos que a rede recebe para todos os caracteres.
Ao mesmo tempo, sabíamos que a imagem deveria ter algo como o seguinte:
Este é um exemplo simples para o caso de classificar uma seleção de dígitos manuscritos (MNIST) em 10 classes. Na penúltima camada oculta, anterior à classificação, existem apenas 2 neurônios, o que facilita a exibição das estatísticas de ativação no avião. Cada ponto no gráfico corresponde a algum exemplo da amostra de teste. A cor de um ponto corresponde a uma classe específica.
No nosso caso, a dimensão do espaço de feição era maior que 128 no exemplo.Rodamos um grupo de imagens de uma amostra de teste e recebemos um vetor de feição para cada imagem. Depois disso, eles foram normalizados (divididos por comprimento). Na foto acima, é óbvio por que vale a pena fazer isso. Agrupamos os vetores normalizados pelo método KMeans. Nós dividimos a amostra em grupos de imagens semelhantes (do ponto de vista da rede).
Mas, no final, precisamos dividir uma partição do alfabeto em grupos, e não uma partição da amostra de teste. Mas não é difícil obter o primeiro do segundo: basta atribuir cada rótulo de classe ao cluster que contém mais imagens dessa classe. Na maioria das situações, é claro, a classe inteira terminará dentro de um cluster.
Bem, é tudo, dividimos o alfabeto inteiro em grupos de caracteres semelhantes. Resta então escolher uma arquitetura simples e treinar o classificador para distinguir entre esses grupos.
Aqui está um exemplo de 6 grupos aleatórios que são obtidos dividindo o alfabeto de origem inteiro em 500 clusters:
Construção de classificadores de segundo nível
Em seguida, você precisa decidir quais conjuntos de caracteres de destino os classificadores de segundo nível aprenderão. A resposta parece ser óbvia - esses devem ser grupos de caracteres obtidos na etapa anterior. Isso funcionará, mas nem sempre com boa qualidade.
O fato é que o classificador do primeiro nível comete erros em qualquer caso e eles podem ser parcialmente compensados pela construção de conjuntos do segundo nível da seguinte maneira:
- Fixamos uma certa amostra separada de imagens de símbolo (não participando nem de treinamento nem de teste);
- Executamos essa amostra por meio de um classificador treinado de primeiro nível, marcando cada imagem com o rótulo desse classificador (rótulo do grupo);
- Para cada símbolo, consideramos todos os grupos possíveis aos quais o classificador do primeiro nível pertence às imagens desse símbolo;
- Adicione esse símbolo a todos os grupos até que o grau de cobertura exigido T_acc seja atingido;
- Consideramos os grupos finais de símbolos como conjuntos de metas do segundo nível, nos quais os classificadores serão treinados.
Por exemplo, as imagens do símbolo “A” foram atribuídas pelo classificador de primeiro nível 980 vezes ao 5º grupo, 19 vezes ao 2º grupo e 1 vez ao 6º grupo. No total, temos 1000 imagens deste símbolo.
Em seguida, podemos adicionar o símbolo "A" ao 5º grupo e obter 98% de cobertura desse símbolo. Podemos atribuí-lo ao 5º e 2º grupo e obter cobertura de 99,9%. E podemos atribuí-lo imediatamente a grupos (5, 2, 6) e obter 100% de cobertura.
Em essência, o T_acc estabelece um equilíbrio entre velocidade e qualidade. Quanto maior for, maior será a qualidade final da classificação, mas quanto maior os conjuntos de metas do segundo nível e mais difícil a classificação no segundo nível.
A prática mostra que, mesmo com T_acc = 1, o aumento no tamanho dos conjuntos como resultado do procedimento de reabastecimento descrito acima não é tão significativo - em média, cerca de 2 vezes. Obviamente, isso dependerá diretamente da qualidade do classificador de primeiro nível treinado.
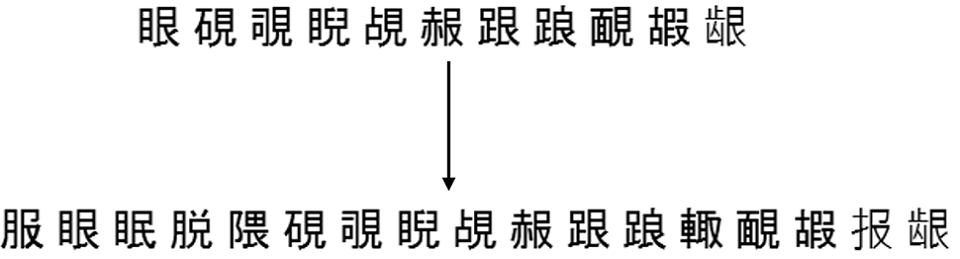
Aqui está um exemplo de como essa conclusão funciona para um dos conjuntos da mesma partição em 500 grupos, que foi maior:
Resultados de incorporação do modelo
Os modelos treinados de dois níveis finalmente trabalharam mais rápido e melhor do que os classificadores usados anteriormente. De fato, não era tão fácil “fazer amizade” com o mesmo gráfico de divisão linear (GLD). Para fazer isso, eu tive que ensinar separadamente o modelo para distinguir caracteres de erros de segmentação de linha e lixo a priori (para retornar baixa confiança nessas situações).
O resultado final da incorporação no algoritmo de reconhecimento de documento completo abaixo (obtido na coleção de documentos em chinês e japonês), a velocidade é indicada para o algoritmo completo:
Melhoramos a qualidade e aceleramos no modo normal e no modo rápido, enquanto transferimos todo o reconhecimento de caracteres para redes neurais.
Um pouco sobre o reconhecimento de ponta a ponta
Até o momento, a maioria dos sistemas de OCR conhecidos publicamente (o mesmo Tesseract do Google) usa a arquitetura de ponta a ponta das redes neurais para reconhecer cadeias ou seus fragmentos como um todo. Mas aqui usamos redes neurais precisamente como um substituto para um módulo de reconhecimento de caracteres únicos. Isso não é acidente.
O fato é que a segmentação de uma sequência em caracteres em chinês e japonês impressos não é um grande problema devido à impressão
monoespaçada . Nesse sentido, o uso do reconhecimento de ponta a ponta para esses idiomas não melhora muito a qualidade, mas é muito mais lento (pelo menos na CPU). Em geral, não está claro como usar a abordagem de dois níveis proposta no contexto de ponta a ponta.
Pelo contrário, existem idiomas para os quais a divisão linear em caracteres é um problema-chave. Exemplos explícitos são árabe, hindi. Para o árabe, por exemplo, as soluções de ponta a ponta já estão sendo estudadas ativamente conosco. Mas esta é uma história completamente diferente.
Alexey Zhuravlev, Chefe do OCR New Technologies Group