Olá Habr! Meu nome é Sergey Lezhnin, sou arquiteto sênior em Sbertekh. Uma das direções do meu trabalho é o Sistema Frontal Unificado. Este sistema possui um serviço de gerenciamento de parâmetros de configuração. É usado por muitos usuários, serviços e aplicativos, o que requer alto desempenho. Neste post, mostrarei como esse serviço evoluiu da primeira, mais simples, para sua versão atual e por que finalmente implantamos toda a arquitetura em 180 graus.

Foi aqui que começamos - esta é a primeira implementação do serviço de gerenciamento de parâmetros:
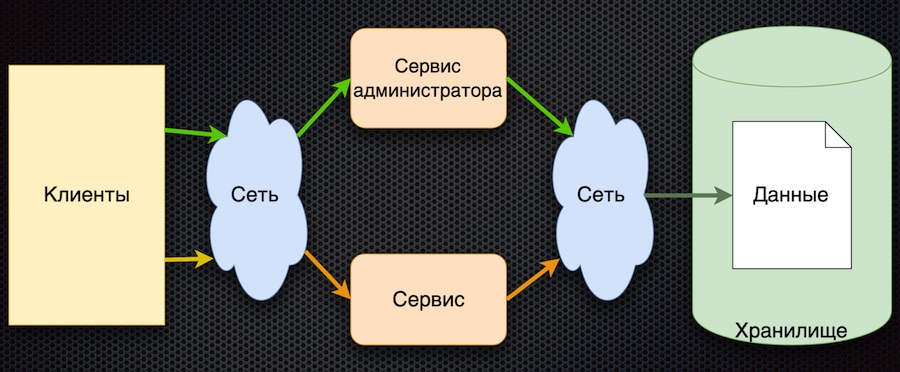
O cliente solicita parâmetros de configuração do serviço. O serviço converte a solicitação no banco de dados, recebe uma resposta e a retorna ao cliente. Ao mesmo tempo, os administradores podem gerenciar parâmetros usando seu serviço separado: adicionar novos valores, alterar os atuais.
Essa abordagem tem uma vantagem - simplicidade. Existem mais desvantagens, embora todas estejam relacionadas:
- acesso frequente ao armazenamento pela rede,
- alta competição pelo acesso ao banco de dados (nós o localizamos em um nó),
- desempenho ruim.
Para passar no teste de carga, essa arquitetura precisava fornecer a carga não mais do que aquela que vem através do acesso direto ao banco de dados. Como resultado, o teste de carga deste circuito não passou.
A segunda etapa: decidimos armazenar em cache os dados no lado do serviço.

Aqui, os dados na solicitação são inicialmente carregados no cache compartilhado e retornados do cache nas próximas solicitações. O administrador do serviço não apenas gerencia os dados, mas também os marca no cache para que, quando eles mudem, eles sejam atualizados.
Então reduzimos o número de acessos ao repositório. Ao mesmo tempo, a sincronização de dados acabou sendo simples, pois o serviço de administrador tem acesso ao cache na memória e controla a redefinição. Por outro lado, se ocorrer uma falha na rede, o cliente não poderá receber dados. E, em geral, a lógica da obtenção de dados é complicada: se não houver dados no cache, você precisará obtê-los do banco de dados, colocá-los no cache e somente então devolvê-los. Precisa se desenvolver ainda mais.
O terceiro estágio do desenvolvimento é o cache de dados do lado do cliente:
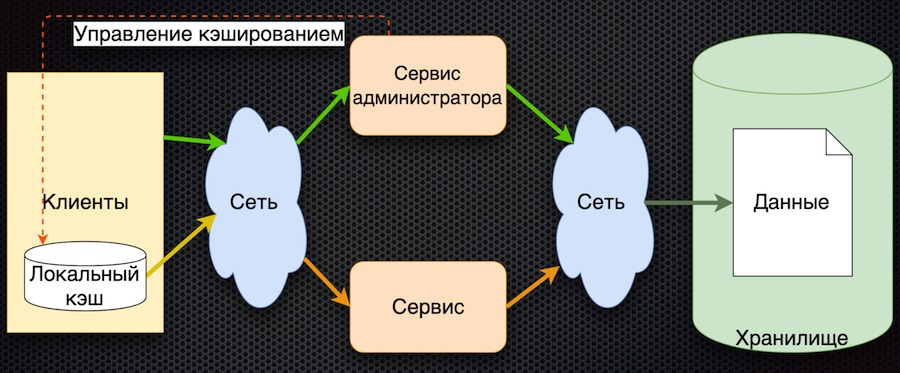
O cliente possui um shell para acessar o serviço (o "módulo cliente"), que oculta o cache de dados local. Se os dados solicitados não estiverem no cache ao solicitar, o serviço será chamado. O serviço solicita parâmetros do banco de dados e os retorna. Comparado ao esquema anterior, o gerenciamento de cache é complicado aqui. Para redefinir os parâmetros, o serviço deve notificar os clientes que esses parâmetros foram alterados.
Nesta arquitetura, reduzimos o número de chamadas para o serviço e para o banco de dados. Agora, se o parâmetro já for solicitado, ele retornará ao cliente sem acessar a rede, mesmo que o serviço ou banco de dados esteja indisponível. Por outro lado, o grande ponto negativo é que a lógica da troca de dados com o cliente é complicada; é necessário notificá-lo adicionalmente através de algum serviço - por exemplo, fila de mensagens. O cliente deve assinar o tópico, receber notificações sobre a alteração de parâmetros e, em seu cache, o cliente deve redefini-los para obter novos valores. Esquema bastante complicado.
Finalmente, chegamos à última etapa no momento. Nisto fomos ajudados pelos princípios básicos formulados no Manifesto Reativo.
- Responsivo: O sistema responde o mais rápido possível.
- Resiliente: o sistema continua a responder mesmo em caso de falha.
- Elástico: o sistema utiliza recursos de acordo com a carga.
- Orientado a Mensagens: fornece assincronia e mensagens gratuitas entre os componentes do sistema.
O esquema correspondente a essa abordagem acabou sendo bastante simples:
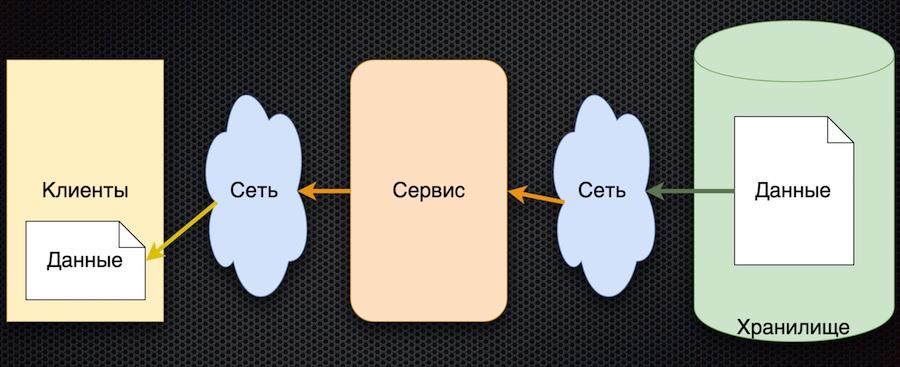
O princípio geral é o seguinte: o cliente assina o parâmetro de configuração e, quando seus valores mudam, o servidor notifica o cliente sobre isso. O esquema acima é um pouco simplificado: não reflete que, quando um cliente se inscreve, ele precisa inicializar e obter o valor inicial. Mas há o principal: as setas mudaram de direção. Anteriormente, um cliente ou cache solicitava ativamente um serviço para alterações de dados, mas agora o próprio serviço envia eventos sobre alterações de dados e eles são atualizados pelo cliente.
Essa arquitetura tem várias vantagens importantes. O número de chamadas para o serviço e armazenamento é reduzido, porque o cliente não solicita ativamente. De fato, a apelação para cada parâmetro desejado ocorre apenas uma vez, ao se inscrever nele. Em seguida, o cliente simplesmente recebe um fluxo de alterações. A disponibilidade dos dados está aumentando porque o cliente sempre tem um valor - ele é armazenado em cache. E, em geral, esse esquema de troca de parâmetros é bastante simples.
A única desvantagem dessa arquitetura é a incerteza na inicialização dos dados. Até a primeira atualização por assinatura, o valor do parâmetro permanece indefinido. Mas isso pode ser resolvido definindo os valores dos parâmetros padrão do cliente, que são substituídos pelos reais durante a primeira atualização.
Seleção de tecnologia
Após a aprovação do esquema, iniciamos a busca de produtos para sua implementação.
Escolha entre
Vertx.io ,
Akka.io e
Spring Boot .

A tabela resume as características que nos interessam. Vertx e Akka têm atores, e o Sping Boot possui uma biblioteca de microsserviços que é essencialmente próxima dos atores. Da mesma forma com a reatividade: o Spring Boot possui sua própria biblioteca WebFlux que implementa os mesmos recursos. Estimamos a luminosidade aproximadamente dentro da tabela. Quanto aos idiomas, das três opções, o Vertx é considerado um poliglota: suporta Java, Scala, Kotlin e JavaScript. Akka tem Scala e Java; Provavelmente o Kotlin também pode ser usado, mas não há suporte direto. O Spring possui Java, Kotlin e Groovy.
Como resultado, a Vertx venceu. A propósito, eles conversaram muito sobre ele na conferência JUG, e de fato muitas empresas o utilizam. Aqui está uma captura de tela do site do desenvolvedor:

No Vertx.io, o esquema de implementação de nossa solução é o seguinte:

Decidimos armazenar os parâmetros não no banco de dados, mas no repositório Git. Podemos usar muito bem essa fonte de dados relativamente lenta devido ao fato de o cliente não solicitar parâmetros ativamente e o número de ocorrências ser reduzido.
Um leitor (verticle) lê dados do repositório Git na memória do aplicativo para acelerar o acesso do usuário aos dados. Isso é importante, por exemplo, ao assinar parâmetros. Além disso, o leitor processa atualizações - relê e marca os dados, substitui os dados antigos por novos.
O barramento de eventos é um serviço Vertx que envia eventos entre verticais e também através de pontes. Inclusive através da ponte do websocket, que é usada neste caso. Quando os eventos de alteração de parâmetro chegam, o barramento de eventos os envia ao cliente.
Finalmente, no lado do cliente, um simples cliente da Web é implementado aqui, que assina eventos (alterações de parâmetro) e exibe essas alterações nas páginas.
Como isso funciona
Mostramos como tudo funciona através de um aplicativo da web.
Iniciamos a página do aplicativo no navegador. Assinamos as principais alterações de dados. Em seguida, vamos para a página do projeto no GitLab local, alteramos os dados no formato JSON e os salvamos no repositório. O aplicativo exibe a alteração correspondente, necessária.
Só isso. Você pode encontrar o código fonte da demonstração no meu
repositório git e fazer perguntas nos comentários.