
As redes sociais são hoje um dos produtos mais populares da Internet e uma das principais fontes de dados para análise. Dentro das próprias redes sociais, a tarefa mais difícil e interessante no campo da ciência de dados é considerada a formação de um feed de notícias. De fato, para satisfazer as crescentes demandas do usuário pela qualidade e relevância do conteúdo, é necessário aprender a coletar informações de várias fontes, calcular a previsão da reação do usuário e equilibrar entre dezenas de métricas concorrentes no teste A / B. E grandes quantidades de dados, altas cargas de trabalho e requisitos rigorosos de velocidade de resposta tornam a tarefa ainda mais interessante.
Parece que hoje as tarefas de classificação já foram estudadas, mas se você olhar de perto, não é tão simples. O conteúdo do feed é muito heterogêneo - é uma foto de amigos, memorandos, vídeos virais, leituras longas e pop científico. Para reunir tudo, você precisa de conhecimento de vários campos: visão computacional, trabalho com textos, sistemas de recomendação e, sem falhas, ferramentas modernas de armazenamento e processamento de dados altamente carregadas. Encontrar uma pessoa com todas as habilidades é extremamente difícil hoje em dia, portanto, classificar a fita é realmente uma tarefa da equipe.
O Odnoklassniki começou a experimentar diferentes algoritmos de classificação de fitas em 2012 e, em 2014, o aprendizado de máquina também se juntou a esse processo. Isso foi possível, em primeiro lugar, graças ao progresso no campo das tecnologias para trabalhar com fluxos de dados. Começando a coletar exibições de objetos e seus atributos no
Kafka e agregando logs usando o
Samza , fomos capazes de criar um conjunto de dados para modelos de treinamento e
calcular os recursos mais "atraentes" : Objetos de Taxa de Cliques e previsões do sistema de recomendação "com base no"
trabalho de colegas do LinkedIn .

Logo ficou claro que o cavalo de batalha da regressão logística não pode retirar a fita sozinho, porque o usuário pode ter uma reação muito diversa: classe, comentário, clique, ocultação, etc., e o conteúdo pode ser muito diferente - foto um amigo, uma postagem em grupo ou um vidosik inscrito por um amigo. Cada reação para cada tipo de conteúdo tem sua própria especificidade e seu próprio valor comercial. Como resultado, chegamos ao conceito de uma “
matriz de regressões logísticas ”: um modelo separado é construído para cada tipo de conteúdo e cada reação e, em seguida, suas previsões são multiplicadas por uma matriz de peso formada por mãos com base nas prioridades atuais dos negócios.
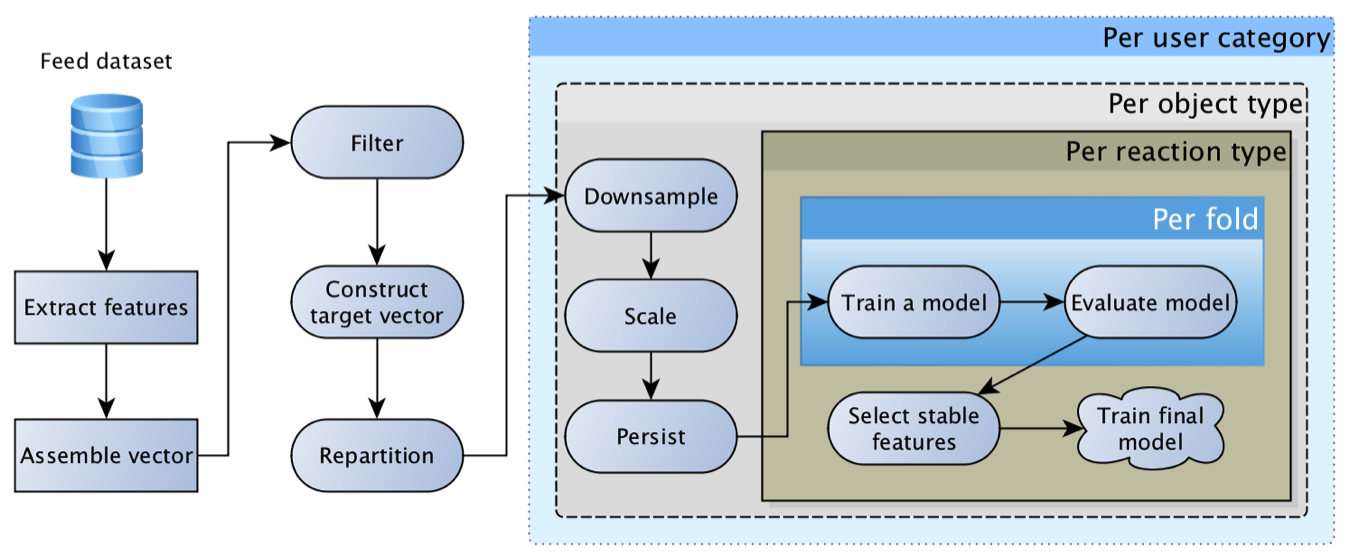
Este modelo era extremamente viável e por muito tempo foi o principal. Com o tempo, adquiriu recursos cada vez mais interessantes: para objetos, para usuários, para autores, para o relacionamento do usuário com o autor, para aqueles que interagiram com o objeto, etc. Como resultado, as primeiras tentativas de substituir a regressão por uma rede neural terminaram em tristes "recursos que temos porcaria demais, a malha não dá um impulso".
Nesse caso, geralmente o aprimoramento mais tangível do ponto de vista da atividade do usuário foi fornecido por melhorias técnicas, e não algorítmicas: obtenha mais candidatos para classificação, rastreie com mais precisão os fatos do programa, otimize a velocidade de resposta do algoritmo e aprimore o histórico de navegação. Essas melhorias geralmente geram unidades e, às vezes, até dezenas de por cento aumentam de atividade, enquanto a atualização do modelo e a adição de um recurso geralmente geram décimos de aumento percentual.

Uma dificuldade separada nos experimentos com a atualização do modelo estava criando um reequilíbrio de conteúdo - a distribuição de previsões do "novo" modelo muitas vezes podia diferir significativamente de seu antecessor, o que levou a uma redistribuição de tráfego e feedback. Como resultado, é difícil avaliar a qualidade do novo modelo, pois primeiro você precisa calibrar o balanço do conteúdo (repita o processo de definir os pesos da matriz para fins comerciais). Depois de estudar a
experiência de colegas do Facebook , percebemos que o modelo
precisa ser calibrado , e a regressão isotônica foi adicionada sobre a regressão logística :).
Freqüentemente, no processo de preparação de novos atributos de conteúdo, sentimos frustração - um modelo simples usando técnicas colaborativas básicas pode gerar 80%, ou até 90% do resultado, enquanto uma rede neural na moda, treinada por uma semana em GPUs super caras, detecta perfeitamente gatos e carros, mas aumenta métricas apenas no terceiro dígito. Um efeito semelhante geralmente pode ser visto ao implementar modelos temáticos, fastText e outros incorporamentos. Conseguimos superar a frustração olhando a validação do ângulo certo: o desempenho dos algoritmos colaborativos melhora significativamente à medida que as informações sobre o objeto se acumulam, enquanto para os objetos "novos" os atributos de conteúdo dão um impulso tangível.
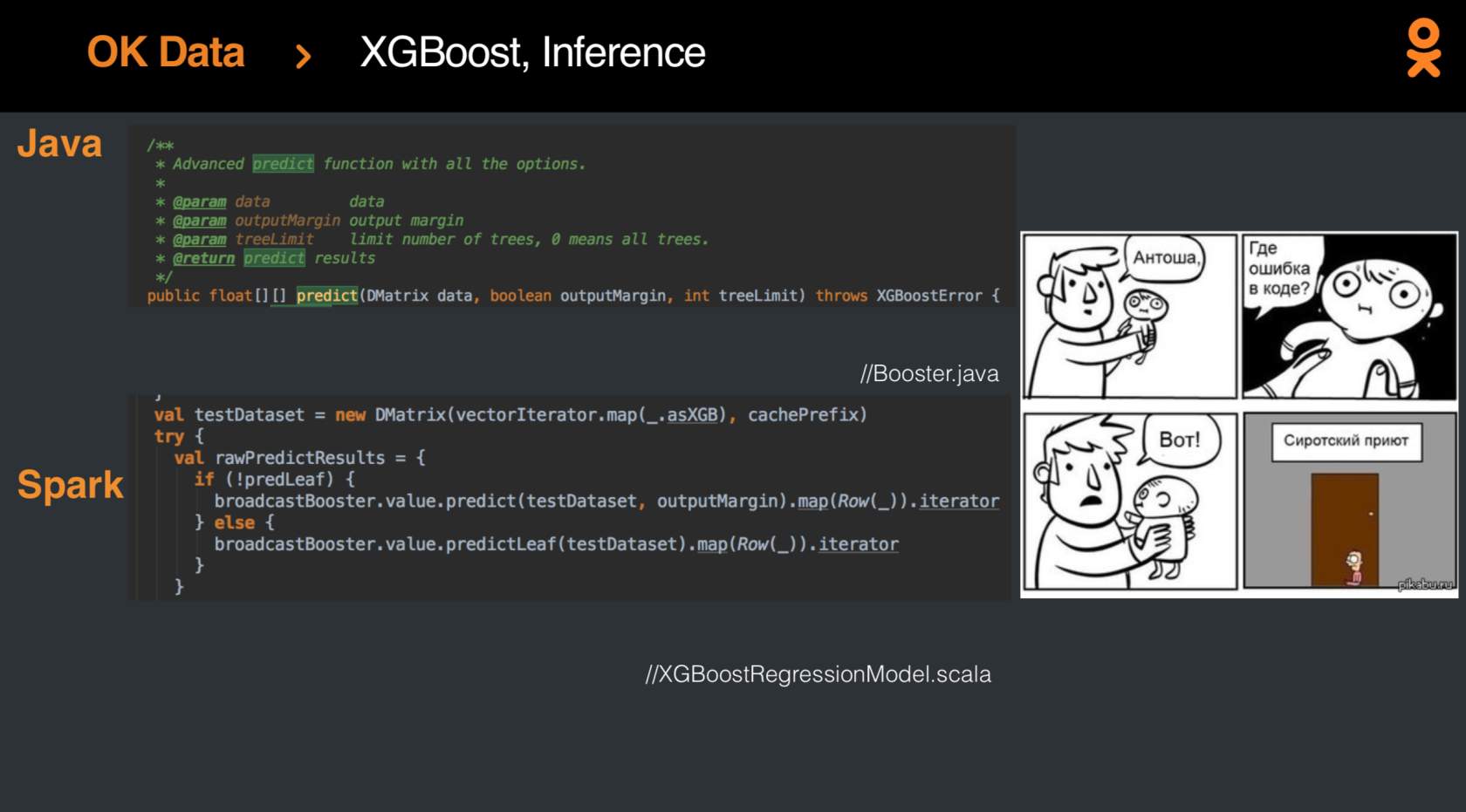
Mas, é claro, um dia os resultados da regressão logística deveriam ser aprimorados, e o progresso foi alcançado com a aplicação do
XGBoost-Spark, lançado recentemente. A integração
não foi fácil , mas no final, o modelo finalmente se tornou moda e jovem, e as métricas cresceram em porcentagem.
Certamente, muito mais conhecimento pode ser extraído dos dados e o ranking da fita pode ser trazido a um novo patamar - e hoje todos têm a oportunidade de tentar sua mão nessa tarefa não trivial da competição
SNA Hackathon 2019 . A competição ocorre em duas etapas: de 7 de fevereiro a 15 de março, faça o download da solução para uma das três tarefas. Após 15 de março, os resultados intermediários serão resumidos e 15 pessoas do topo da tabela de classificação para cada tarefa receberão convites para o segundo estágio, que será realizado de 30 de março a 1 de abril no escritório de Moscou do Mail.ru Group. Além disso, o convite para a segunda etapa receberá três pessoas que lideram a classificação no final de 23 de fevereiro.
Por que existem três tarefas? Como parte da fase on-line, oferecemos três conjuntos de dados, cada um dos quais apresenta apenas um dos aspectos: imagem, texto ou informações sobre uma variedade de atributos de colaboração. E somente no segundo estágio, quando especialistas em diferentes campos se reunirem, o conjunto de dados geral será revelado, permitindo encontrar pontos para a sinergia de diferentes métodos.
Interessado em uma tarefa? Junte-se ao
SNA Hackathon :)