Bill Kennedy disse em uma palestra em seu maravilhoso curso de
programação Ultimate Go :
Muitos desenvolvedores procuram otimizar seu código. Eles pegam uma linha e a reescrevem, dizendo que isso se tornará mais rápido. Precisa parar. Dizer que esse ou aquele código é mais rápido só é possível depois que é criado o perfil e feitos os benchmarks. A previsão do futuro não é a abordagem correta para escrever código.
Há muito tempo, queria demonstrar com um exemplo prático como isso pode funcionar. E outro dia, minha atenção foi atraída para o código a seguir, que poderia ser usado apenas como exemplo:
builds := store.Instance.GetBuildsFromNumberToNumber(stageBuild.BuildNumber, lastBuild.BuildNumber) tempList := model.BuildsList{} for i := len(builds) - 1; i >= 0; i-- { b := builds[i] b.PatchURLs = b.ReversePatchURLs b.ExtractedSize = b.RPatchExtractedSize tempList = append(tempList, b) }
Aqui, em todos os elementos da fatia de
compilações retornados do banco de dados,
PatchURLs é substituído por
ReversePatchURLs ,
ExtractedSize por
RPatchExtractedSize e reverse - a ordem dos elementos é alterada para que o último elemento se torne o primeiro e o último por último.
Na minha opinião, o código fonte é um pouco complicado de ler e pode ser otimizado. Esse código executa um algoritmo simples que consiste em duas partes lógicas: alterando elementos de fatia e classificação. Mas para o programador isolar esses dois componentes, levará tempo.
Apesar de ambas as partes serem importantes, o código reverso não é tão enfatizado quanto gostaríamos. Ele está espalhado por três linhas separadas: inicializando uma nova fatia, iterando uma fatia existente na ordem inversa, adicionando um elemento ao final de uma nova fatia. No entanto, não se pode ignorar as vantagens indubitáveis desse código: o código está funcionando e testado, e falando objetivamente, é bastante adequado. A percepção subjetiva do código por um desenvolvedor individual não pode ser uma desculpa para reescrevê-lo. Infelizmente ou felizmente, não reescrevemos o código apenas porque simplesmente não gostamos (ou, como costuma acontecer, simplesmente porque não é nosso, veja
falha fatal ).
Mas e se conseguirmos não apenas melhorar a percepção do código, mas também acelerá-lo significativamente? Esta é uma questão completamente diferente. Você pode oferecer vários algoritmos alternativos que executam a funcionalidade incorporada no código.
Primeira opção: iterando sobre todos os elementos em um loop de
intervalo ; Para reverter a fatia original em cada iteração, adicione um elemento ao início da matriz final. Para que pudéssemos nos livrar do incômodo
para , variável
i , usar a função
len , é difícil perceber a iteração sobre os elementos do final e também reduzir a quantidade de código em duas linhas (de sete linhas para cinco), e quanto menor o código, menor a probabilidade de permitir isso um erro.
var tempList []*store.Build for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize tempList = append([]*store.Build{build}, tempList...) }
Depois de remover a enumeração de fatia do final, distinguimos claramente entre as operações de alteração de elementos (terceira linha) e o inverso da matriz original (quarta linha).
A idéia principal da segunda opção é explodir ainda mais a variação de elementos e a classificação. Primeiro, classificamos os elementos e os alteramos e, em seguida, classificamos a fatia por uma operação separada. Esse método exigirá implementação adicional da interface de classificação da fatia, mas aumentará a legibilidade e separará e isolará completamente o reverso dos elementos alterados, e o método
Reverse indicará definitivamente ao leitor o resultado desejado.
var tempList []*store.Build for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Sort(sort.Reverse(sort.IntSlice(keys)))
A terceira opção é quase uma repetição da segunda, mas
sort.Slice é usada para classificação, o que aumenta a quantidade de código em uma linha, mas evita a implementação adicional da interface de classificação.
for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Slice(builds, func(i int, j int) bool { return builds[i].Id > builds[j].Id })
À primeira vista, em termos de complexidade interna, número de iterações, funções aplicadas, o código inicial e o primeiro algoritmo estão próximos; as segunda e terceira opções podem parecer mais difíceis, mas é impossível dizer inequivocamente qual das quatro opções é a ideal.
Portanto, nos proibimos de tomar decisões baseadas em suposições não suportadas por evidências, mas é óbvio que o mais interessante aqui é como a função append se comporta ao adicionar um elemento ao final e ao início da fatia. Afinal, de fato, essa função não é tão simples quanto parece.
O acréscimo funciona da
seguinte maneira : ele adiciona um novo elemento à fatia existente se sua capacidade é maior que o comprimento total ou reserva na memória um local para uma nova fatia, copiando dados da primeira fatia para ela, adicionando os dados da segunda fatia e adicionando os dados da segunda e retornando uma nova como resultado fatia.
A nuance mais interessante no trabalho dessa função é o algoritmo usado para reservar memória para uma nova matriz. Como a operação mais cara é alocar uma nova parte da memória, os desenvolvedores do Go fizeram um pequeno truque para tornar a operação de
acréscimo mais barata. Inicialmente, para não reservar a memória novamente cada vez que um elemento é adicionado, a quantidade de memória é alocada com uma certa margem - duas vezes a original, mas depois de um certo número de elementos, o tamanho da seção de memória recém-reservada se torna não mais que duas vezes, mas em 25%.
Dada a nova compreensão da função
anexar, a resposta à pergunta: "O que será mais rápido: adicione um elemento ao final de uma fatia existente ou adicione uma fatia existente a uma fatia de um elemento?" - já é mais transparente. Pode-se supor que no segundo caso, comparado ao primeiro, haverá mais alocações de memória, o que afetará diretamente a velocidade do trabalho.
Então, nós nos aproximamos suavemente dos benchmarks. Com a ajuda de benchmarks, você pode avaliar a carga do algoritmo nos recursos mais críticos, como tempo de execução e RAM.
Vamos escrever uma referência para avaliar todos os quatro de nossos algoritmos. Ao mesmo tempo, avaliaremos qual crescimento pode nos dar a rejeição da classificação (para entender quanto tempo total é gasto na classificação). Código de referência:
package services import ( "testing" "sort" ) type Build struct { Id int ExtractedSize int64 PatchUrls string ReversePatchUrls string RPatchExtractedSize int64 } type Builds []*Build func (a Builds) Len() int { return len(a) } func (a Builds) Swap(i, j int) { a[i], a[j] = a[j], a[i] } func (a Builds) Less(i, j int) bool { return a[i].Id < a[j].Id } func prepare() Builds { var builds Builds for i := 0; i < 100000; i++ { builds = append(builds, &Build{Id: i}) } return builds } func BenchmarkF1(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { var tempList Builds copy(builds, data) for i := len(builds) - 1; i >= 0; i-- { b := builds[i] b.PatchUrls, b.ExtractedSize = b.ReversePatchUrls, b.RPatchExtractedSize tempList = append(tempList, b) } } } func BenchmarkF2(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { var tempList Builds copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize tempList = append([]*Build{build}, tempList...) } } } func BenchmarkF3(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Sort(sort.Reverse(builds)) } } func BenchmarkF4(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Slice(builds, func(i int, j int) bool { return builds[i].Id > builds[j].Id }) } } func BenchmarkF5(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } } }
Inicie o benchmark com o comando
go test -bench =. -benchmem .
Os resultados do cálculo para as fatias 10, 100, 1000, 10 000 e 100 000 elementos são apresentados no gráfico abaixo, onde F1 é o algoritmo inicial, F2 é a adição do elemento ao início da matriz, F3 é o uso de
ordenação.Reverso à ordenação, F4 é o uso de
ordenação.Slice , F5 - rejeição da classificação.
Tempo de operação Número de alocações de memória
Número de alocações de memória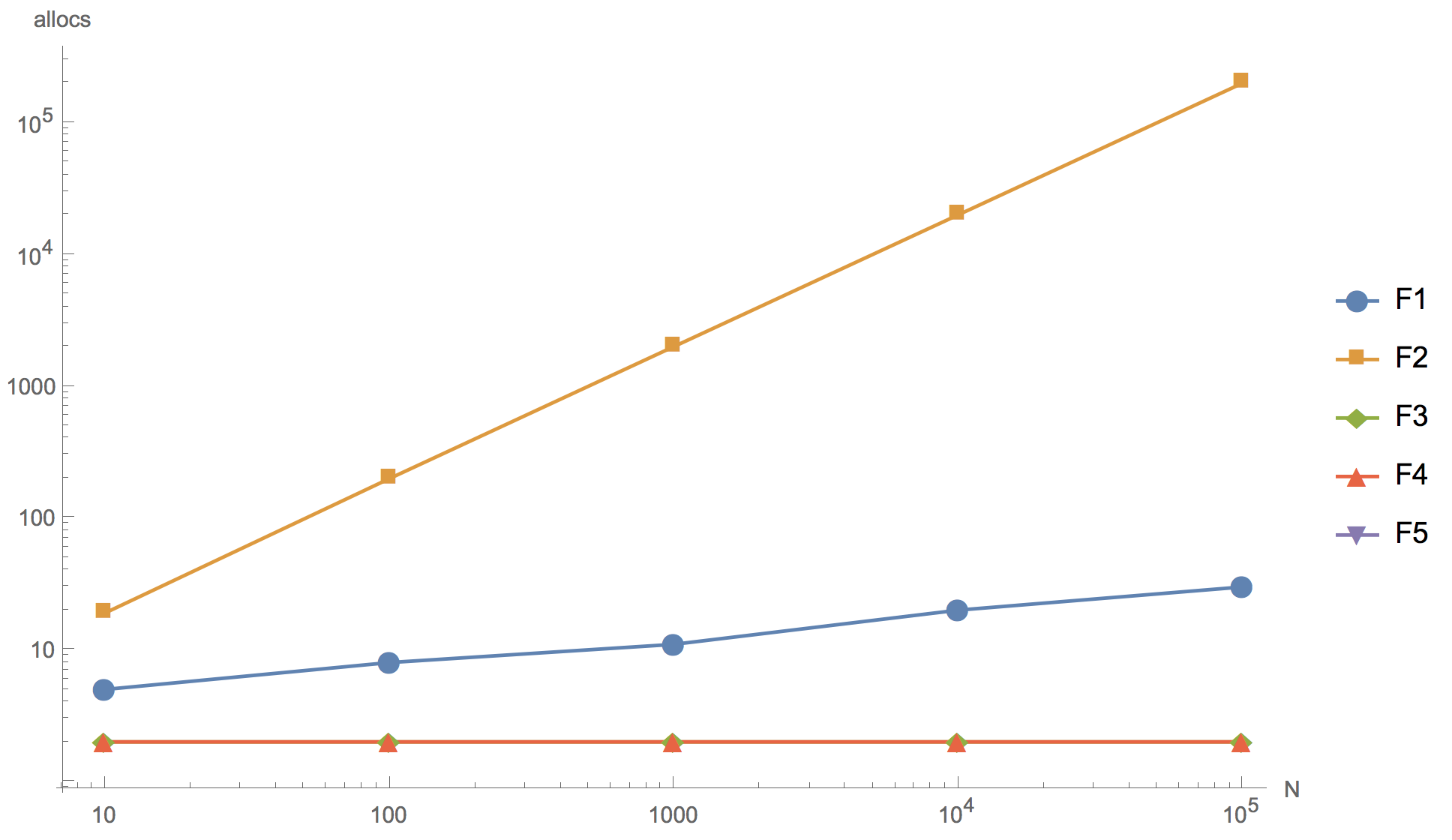
Como você pode ver no gráfico, você pode aumentar a matriz, mas o resultado final já é, em princípio, distinguível em uma fatia de 10 elementos.
Nenhum dos algoritmos alternativos propostos (F2, F3, F4) poderia exceder o algoritmo original (F1) em velocidade. Mesmo apesar de todos, com exceção de F2, terem menos alocações de memória que o original. O primeiro algoritmo (F2), com a adição de um elemento no início da fatia, mostrou-se o mais ineficaz: como esperado, ele possui muitas alocações de memória, tanto que é absolutamente impossível usá-lo no desenvolvimento de produtos. Um algoritmo usando a função de classificação reversa interna (F3) é significativamente mais lento que o original. O
algoritmo de classificação
Slice é comparável em velocidade ao algoritmo original, mas é ligeiramente inferior a ele.
Você também pode perceber que recusar a classificação (F5) fornece uma aceleração significativa. Portanto, se você realmente deseja reescrever o código, pode seguir nessa direção, por exemplo, aumentando a fatia de
compilações iniciais do banco de dados, use a classificação por id DESC em vez de ASC na solicitação. Mas, ao mesmo tempo, somos forçados a ir além dos limites da seção de código considerada, o que implica o risco de introduzir várias alterações.
Conclusões
Escreva benchmarks.
Não faz muito sentido gastar seu tempo pensando se um código específico será mais rápido. Informações da Internet, julgamentos de colegas e outras pessoas, por mais autoritárias que sejam, podem servir como argumentos auxiliares, mas o papel do juiz principal, decidindo se é ou não um novo algoritmo, deve permanecer com os parâmetros de referência.
Go é, à primeira vista, uma linguagem bastante simples. A regra abrangente 80⁄20 se aplica aqui. Esses 20% representam as sutilezas da estrutura interna da linguagem, cujo conhecimento distingue o iniciante do desenvolvedor experiente. A prática de escrever referências para resolver suas perguntas é uma das maneiras mais baratas e eficazes de obter uma resposta e uma compreensão mais profunda da estrutura interna e dos princípios da linguagem Go.