
Nota do tradutor
A maioria dos produtos de software modernos não é monolítica, mas consiste em muitas partes que interagem entre si. Nessa situação, é necessário que a comunicação das partes em interação do sistema ocorra em um idioma (apesar do fato de que essas partes podem ser escritas em diferentes linguagens de programação e executadas em máquinas diferentes). Simplificar a solução para esse problema ajuda o gRPC - framework de código aberto do Google, lançado em 2015. Ele resolve imediatamente vários problemas, permitindo:
- use a linguagem Buffers de Protocolo para descrever a interação de serviços;
- gerar código de programa com base no protocolo descrito para 11 idiomas diferentes para a parte do cliente e a parte do servidor;
- implementar autorização entre componentes em interação;
- use a interação síncrona e assíncrona.
O gRPC me pareceu uma estrutura bastante interessante, e eu estava interessado em aprender sobre a experiência real do Dropbox na construção de um sistema baseado nele. O artigo possui muitos detalhes relacionados ao uso da criptografia, criando um sistema confiável, observável e produtivo, o processo de migração da solução RPC antiga para a nova.
Isenção de responsabilidadeO artigo original não contém uma descrição do gRPC e alguns pontos podem não lhe parecer claros. Se você não estiver familiarizado com o gRPC ou outras estruturas semelhantes (por exemplo, Apache Thrift), recomendo que você se familiarize primeiro com as idéias principais (será suficiente ler dois pequenos artigos no site oficial:
“O que é gRPC?” E
“gRPC Concepts” ).
Agradecemos a Aleksey Ivanov, também conhecido como
SaveTheRbtz, por escrever o artigo original e ajudar na tradução de lugares difíceis.
O Dropbox gerencia muitos serviços escritos em diferentes idiomas e atende a milhões de solicitações por segundo. No centro de nossa arquitetura orientada a serviços está o Courier, uma estrutura RPC baseada em gPC. No processo de desenvolvimento, aprendemos muito sobre extensibilidade do gRPC, otimização de desempenho e transição do sistema RPC anterior.
Nota: a postagem contém trechos de código para Python e Go. Também usamos Rust e Java.Caminho para o gRPC
O Courier não é o primeiro framework RPC do Dropbox. Mesmo antes de começarmos a dividir o sistema monolítico Python em serviços separados, precisávamos de uma base confiável para a troca de dados entre serviços - especialmente porque a escolha de uma estrutura teria consequências a longo prazo.
Antes disso, o Dropbox experimentou diferentes estruturas de RPC. Primeiro, tínhamos um protocolo individual para serialização e desserialização manual. Alguns serviços, como o
log baseado em
Scribe , usavam o
Apache Thrift . Ao mesmo tempo, nossa estrutura principal de RPC era um protocolo HTTP / 1.1 com mensagens serializadas usando o Protobuf.
Criando uma estrutura, escolhemos entre várias opções. Poderíamos introduzir o Swagger (agora conhecido como
OpenAPI ) na antiga estrutura RPC,
introduzir um novo padrão ou criar uma estrutura baseada em Thrift ou gRPC. O principal argumento a favor do gRPC foi a possibilidade de usar protobufs pré-existentes. Além disso, HTTP / 2 multiplex e transferência de dados bidirecional foram úteis para nossas tarefas.
Nota: se fbthrift existisse naquele momento, provavelmente examinaríamos melhor as soluções Thrift.O que o Courier traz para o gRPC
Courier não é um protocolo RPC; é um meio de integrar o gRPC em uma infraestrutura existente. A estrutura deveria ser compatível com nossas ferramentas de autenticação, autorização e descoberta de serviços, bem como coleta, registro e rastreamento de estatísticas. Então criamos o Courier.
Embora em alguns casos usemos o Bandaid como um proxy gRPC, a maioria dos nossos serviços se comunica diretamente entre si para minimizar o impacto do RPC na latência.Era importante para nós reduzir a quantidade de código de rotina que precisa ser gravado. Como o Courier serve como uma estrutura geral para o desenvolvimento de serviços, ele contém recursos que todos precisam. A maioria deles é ativada por padrão e pode ser controlada por argumentos de linha de comando, e alguns são marcados com uma caixa de seleção.
Segurança: identidade de serviço e autenticação mútua TLS
O Courier implementa nosso mecanismo de identificação de serviço padrão. Cada servidor e cliente recebe um certificado TLS individual emitido por nossa própria autoridade de certificação. O identificador pessoal codificado por certificado, usado para autenticação mútua - o servidor verifica o cliente, o cliente verifica o servidor.
No TLS, onde controlamos os dois lados da conexão, introduzimos restrições estritas. Todos os RPCs internos exigem criptografia
PFS . A versão exigida do TLS é 1.2 e superior. Também limitamos o número de algoritmos simétricos e assimétricos, preferindo
ECDHE-ECDSA-AES128-GCM-SHA256 .
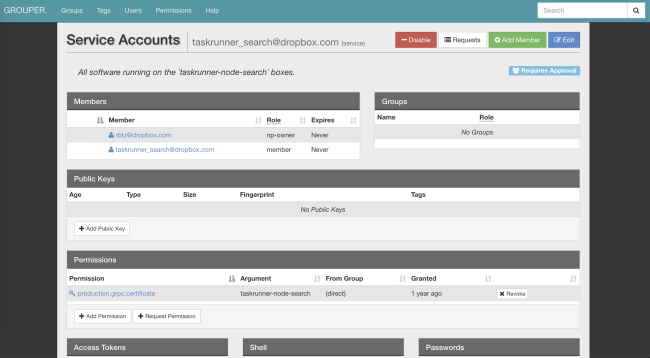
Após passar pela identificação e descriptografia da solicitação, o servidor verifica se o cliente tem as permissões necessárias. As listas de controle de acesso (ACLs) e os limites de velocidade podem ser configurados para serviços em geral e para métodos individuais. Seus parâmetros também podem ser alterados através do nosso sistema de arquivos distribuídos (AFS). Graças a isso, os proprietários do serviço podem diminuir a carga em segundos, sem nem mesmo reiniciar os processos. O Courier se encarregará de assinar as notificações e atualizar a configuração.
O serviço de identidade é um identificador global para ACLs, limites de velocidade, estatísticas, etc. Além disso, é criptograficamente seguro.Aqui está um exemplo da configuração da ACL e do limite de velocidade usado em nosso
serviço de reconhecimento de padrão óptico :
limits: dropbox_engine_ocr: # All RPC methods. default: max_concurrency: 32 queue_timeout_ms: 1000 rate_acls: # OCR clients are unlimited. ocr: -1 # Nobody else gets to talk to us. authenticated: 0 unauthenticated: 0
 Estamos considerando a possibilidade de mudar para o formato SVID (documento criptograficamente verificado SPIFFE ), que ajudará a combinar nossa estrutura com muitos projetos de código aberto.
Estamos considerando a possibilidade de mudar para o formato SVID (documento criptograficamente verificado SPIFFE ), que ajudará a combinar nossa estrutura com muitos projetos de código aberto.Observabilidade: estatísticas e rastreamento
Com apenas um identificador, você pode encontrar facilmente logs, estatísticas, arquivos de rastreamento e outros dados sobre o Courier.
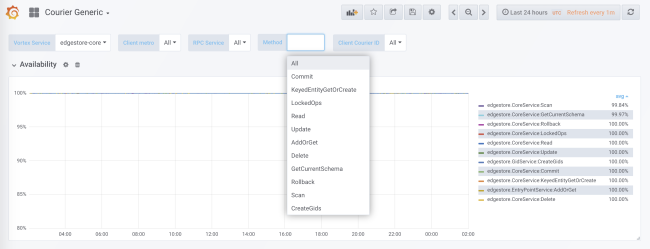
Durante a geração do código, a coleção de estatísticas é adicionada para cada serviço e cada método no lado do cliente e no lado do servidor. As estatísticas do servidor são divididas pelo ID do cliente. Na configuração padrão, você receberá dados detalhados sobre a carga, erros e tempo de atraso de cada serviço usando o Courier.
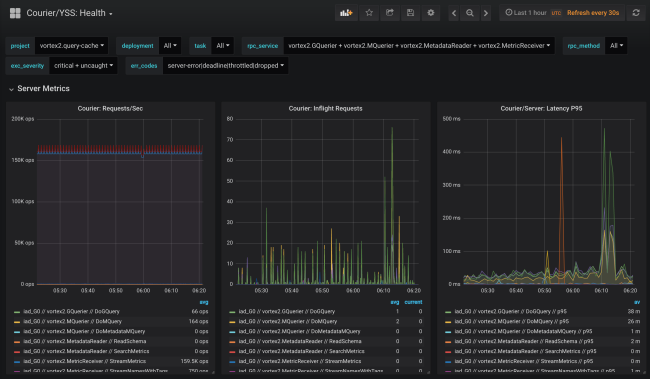
As estatísticas do correio incluem dados sobre disponibilidade e latência no lado do cliente, bem como sobre o número de solicitações e o tamanho da fila no lado do servidor. Existem outros gráficos úteis, em particular histogramas de tempo de resposta para cada método e o tempo de handshakes TLS para cada cliente.
Uma das vantagens de nossa geração de código é a possibilidade de inicialização estática de estruturas de dados, como histogramas e gráficos de rastreamento. Isso minimiza o impacto no desempenho.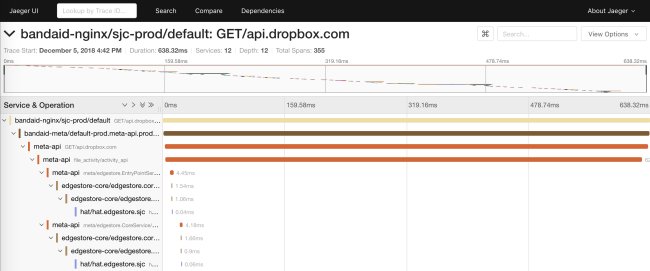
O sistema RPC antigo distribuiu apenas
request_id pela API. Isso tornou possível combinar dados dos logs de diferentes serviços. Na Courier, introduzimos uma API baseada em um subconjunto das especificações do
OpenTracing . Criamos nossas próprias bibliotecas no lado do cliente e, no lado do servidor, implementamos uma solução baseada em Cassandra e
Jaeger .

O rastreamento permite gerar diagramas de dependência de um serviço em tempo de execução. Isso ajuda os engenheiros a ver todas as dependências transitivas de um serviço específico. Além disso, a função é útil para rastrear dependências indesejadas após a implantação.
Confiabilidade: prazos e desconexão
O Courier fornece um local central para implementar funções comuns do cliente (por exemplo, tempos limite) em diferentes idiomas. Gradualmente, adicionamos vários recursos, geralmente baseados nos resultados de uma análise "póstuma" de problemas emergentes.
Prazos
Cada solicitação de gRPC tem um prazo indicando o tempo limite do cliente. Como os stubs Courier distribuem automaticamente os metadados conhecidos, o prazo final da solicitação é até transferido para fora da API. Dentro do processo, os prazos recebem uma exibição nativa. Por exemplo, no Go, eles são representados pelo resultado de
context.Context do método
WithDeadline .
De fato, conseguimos consertar classes inteiras de problemas de confiabilidade forçando os engenheiros a estabelecer prazos na definição dos serviços apropriados.
Essa abordagem vai além do RPC. Por exemplo, nosso ORM MySQL serializa um contexto RPC junto com um prazo em um comentário de consulta SQL. Nosso proxy SQL pode analisar comentários e "matar" consultas quando o prazo ocorre. E como bônus ao depurar chamadas de banco de dados, temos uma ligação de consulta SQL a uma consulta RPC específica.
Desconectar
Outro problema comum que os clientes do sistema RPC anterior enfrentavam era a implementação do algoritmo de atraso e flutuações exponenciais individuais, mediante solicitação repetida.
Tentamos encontrar uma solução inteligente para o problema de desconexão no Courier, começando com a implementação do buffer LIFO (último a entrar, primeiro a sair) entre o serviço e o conjunto de tarefas.
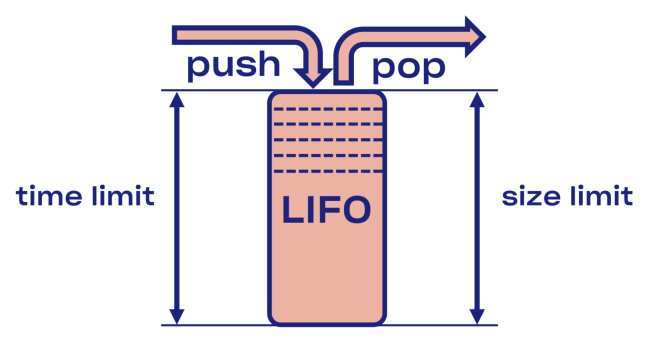
Em caso de sobrecarga, o LIFO será desconectado automaticamente. A fila, que é importante, é limitada não apenas pelo tamanho, mas também
pelo tempo (a solicitação pode passar na fila apenas um determinado tempo).
Menos LIFO - alterando a ordem dos pedidos de processamento. Se você deseja manter o pedido original, use o CoDel . Também existe a possibilidade de desconectar, e a ordem dos pedidos de processamento permanecerá a mesma.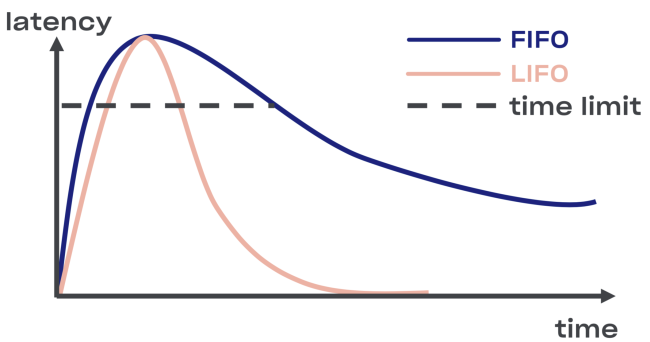
Introspecção: pontos de extremidade de depuração
Embora os pontos de extremidade de depuração não façam parte diretamente do Courier, eles são amplamente usados no Dropbox e são úteis demais para não serem mencionados.
Por motivos de segurança, você pode abri-los em uma porta separada ou em um soquete Unix (para controlar o acesso usando permissões de arquivo). Você também deve considerar a autenticação TLS mútua, com a qual os desenvolvedores terão que fornecer seus certificados para acesso aos pontos de extremidade (principalmente não somente leitura).Execução
A capacidade de analisar o status de um serviço durante sua operação é muito útil para depuração. Por exemplo,
perfis dinâmicos de memória e CPU podem ser acessados através de pontos de extremidade HTTP ou gRPC .
Planejamos usar essa oportunidade no procedimento de verificação de canário - para automatizar a busca pela diferença entre as versões antiga e nova do código.Os pontos de extremidade tornam possível modificar o estado de um serviço em tempo de execução. Em particular, os serviços baseados em Golang podem configurar dinamicamente o
GCPercent .
A biblioteca
A exportação automática de dados específicos da biblioteca como um terminal RPC pode ser útil para desenvolvedores de bibliotecas. Por exemplo, a biblioteca
malloc pode despejar estatísticas internas em um despejo . Outro exemplo: um ponto de extremidade de depuração pode alterar o nível de log de serviço em tempo real.
Rpc
Obviamente, a solução de problemas em protocolos criptografados e codificados não é fácil. Portanto, a introdução de tantas ferramentas quanto possível no nível de RPC é uma boa idéia. Um exemplo dessa API introspectiva
é a solução Channelz .
Nível de aplicação
Ser capaz de aprender as opções no nível do aplicativo também pode ser útil. Um bom exemplo é um terminal com informações gerais sobre o aplicativo (com um hash de arquivos de origem ou montagem, uma linha de comando etc.). Ele pode ser usado por um sistema de orquestração para verificar a integridade ao implantar um serviço.
Otimização de desempenho
Ao expandir nossa estrutura de gRPC para a escala necessária, encontramos vários gargalos específicos ao Dropbox.
Consumo de recursos do TLS Handshakes
Em serviços que atendem a muitos relacionamentos, como resultado de handshakes TLS, a carga combinada da CPU pode ser bastante séria (especialmente ao reiniciar um serviço popular).
Para melhorar o desempenho ao assinar, substituímos os pares de chaves RSA-2048 pelo ECDSA P-256. Aqui estão exemplos de seu desempenho (nota: com o RSA, a verificação de assinatura é mais rápida).
RSA: ~/c0d3/boringssl bazel run -- //:bssl speed -filter 'RSA 2048' Did ... RSA 2048 signing operations in .............. (1527.9 ops/sec) Did ... RSA 2048 verify (same key) operations in .... (37066.4 ops/sec) Did ... RSA 2048 verify (fresh key) operations in ... (25887.6 ops/sec)
ECDSA: ~/c0d3/boringssl bazel run -- //:bssl speed -filter 'ECDSA P-256' Did ... ECDSA P-256 signing operations in ... (40410.9 ops/sec) Did ... ECDSA P-256 verify operations in .... (17037.5 ops/sec)
Como a verificação com o RSA-2048 é cerca de três vezes mais rápida que com o ECDSA P-256, você pode escolher o RSA para certificados raiz e finais para aumentar a velocidade da operação. Mas, do ponto de vista da segurança, nem tudo é tão simples: você criará cadeias de várias primitivas criptográficas e, portanto, o nível dos parâmetros de segurança resultantes será o mais baixo. E se você deseja melhorar o desempenho, não recomendamos o uso de certificados da versão RSA-4096 (e superior) como certificados raiz e final.
Também descobrimos que a escolha de uma biblioteca TLS (e sinalizadores de compilação) tem um impacto significativo no desempenho e na segurança. Compare, por exemplo, o LibreSSL desenvolvido no macOS X Mojave com o OpenSSL auto-escrito no mesmo hardware.
LibreSSL 2.6.4: ~ openssl speed rsa2048 LibreSSL 2.6.4 ... sign verify sign/s verify/s rsa 2048 bits 0.032491s 0.001505s 30.8 664.3
OpenSSL 1.1.1a: ~ openssl speed rsa2048 OpenSSL 1.1.1a 20 Nov 2018 ... sign verify sign/s verify/s rsa 2048 bits 0.000992s 0.000029s 1208.0 34454.8
No entanto, a maneira mais rápida de criar um handshake TLS é não criá-lo! Incluímos suporte para o reinício da sessão no gRPC-core e no gRPC-python, reduzindo assim a carga na CPU durante a implantação.
A criptografia é barata
Muitos acreditam erroneamente que a criptografia é cara. De fato, mesmo os computadores modernos mais simples executam criptografia simétrica quase instantaneamente. Um processador padrão é capaz de criptografar e autenticar dados a uma velocidade de 40 Gb / s por núcleo:
~/c0d3/boringssl bazel run -- //:bssl speed -filter 'AES' Did ... AES-128-GCM (8192 bytes) seal operations in ... 4534.4 MB/s
No entanto, ainda tivemos que configurar o gRPC para nossos blocos de memória, operando a uma velocidade de 50 Gb / s. Descobrimos que, se a velocidade de criptografia é aproximadamente igual à velocidade da cópia, é importante minimizar o número de operações com
memória incorreta. Além disso, fizemos algumas alterações no próprio gRPC.
Protocolos autenticados e criptografados evitaram muitos problemas desagradáveis (por exemplo, corrupção de dados pelo processador, DMA ou na rede). Mesmo se você não usar o gRPC, recomendamos o uso do TLS para contatos internos.Canais de dados de alta latência (BDP)
Nota do tradutor: a legenda original usava o termo
produto de atraso de largura de banda , que não possui uma tradução estabelecida para o russo.
A rede de backbone do Dropbox inclui muitos data centers . Às vezes, os nós localizados em diferentes regiões precisam se comunicar via RPC, por exemplo, para replicação. Ao usar o TCP, o kernel do sistema é responsável por limitar a quantidade de dados transmitidos em uma conexão específica (em /
proc / sys / net / ipv4 / tcp_ {r, w} mem ), embora o gRPC baseado no HTTP / 2 tenha sua própria ferramenta controle de fluxo. O limite superior do BDP
no grpc-go é estritamente limitado a 16 MB , o que pode desencadear um gargalo.
net.Server Golang ou grpc.Server
Inicialmente, em nosso código Go, suportamos HTTP / 1.1 e gRPC com um único
net.Server . A solução fazia sentido em termos de manutenção do código do programa, mas não funcionava perfeitamente. Distribuir HTTP / 1.1 e gRPC entre servidores e migrar o gRPC para grpc.Server melhorou significativamente a largura de banda do Courier e o uso de memória.
golang / protobuf ou gogo / protobuf
Mudar para o gRPC pode aumentar o custo de empacotamento e descompactação. Para o código Go, conseguimos reduzir significativamente a carga da CPU nos servidores Courier, mudando para
gogo / protobuf .
Como sempre, a transição para o gogo / protobuf foi acompanhada de algumas preocupações , mas se você limitar razoavelmente a funcionalidade, não haverá problemas.Detalhes da implementação
Nesta seção, abordaremos mais profundamente o dispositivo Courier, consideraremos esquemas de protobuf e exemplos de stubs de vários idiomas. Todos os exemplos são retirados do serviço de Teste, que usamos durante o teste de integração do Courier.
Descrição do Serviço
Veja um trecho da definição de serviço de Teste:
service Test { option (rpc_core.service_default_deadline_ms) = 1000; rpc UnaryUnary(TestRequest) returns (TestResponse) { option (rpc_core.method_default_deadline_ms) = 5000; } rpc UnaryStream(TestRequest) returns (stream TestResponse) { option (rpc_core.method_no_deadline) = true; } ... }
Como mencionado acima, é necessário um prazo para todos os métodos Courier. Usando a opção a seguir, você pode definir o prazo para todo o serviço:
option (rpc_core.service_default_deadline_ms) = 1000;
Ao mesmo tempo, cada método pode ser definido com seu próprio prazo, cancelando o prazo de todo o serviço (se houver):
option (rpc_core.method_default_deadline_ms) = 5000;
Em casos raros, quando o prazo não faz sentido (por exemplo, ao rastrear um recurso), o desenvolvedor pode desativá-lo:
option (rpc_core.method_no_deadline) = true;
Além disso, a descrição do serviço deve conter documentação detalhada da API, possivelmente com exemplos de uso.
Geração Stub
Para fornecer maior flexibilidade, o Courier gera seus próprios stubs sem depender da funcionalidade do interceptador fornecida pelo gRPC (com exceção do Java, no qual a API do interceptador tem energia suficiente). Vamos comparar nossos stubs com os stubs Golang padrão.
É assim que os stubs padrão do servidor gRPC se parecem:
func _Test_UnaryUnary_Handler(srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) (interface{}, error) { in := new(TestRequest) if err := dec(in); err != nil { return nil, err } if interceptor == nil { return srv.(TestServer).UnaryUnary(ctx, in) } info := &grpc.UnaryServerInfo{ Server: srv, FullMethod: "/test.Test/UnaryUnary", } handler := func(ctx context.Context, req interface{}) (interface{}, error) { return srv.(TestServer).UnaryUnary(ctx, req.(*TestRequest)) } return interceptor(ctx, in, info, handler) }
Todo o processamento ocorre dentro: decodificação do protobuf, iniciando interceptores (consulte a variável
interceptor no código), iniciando o manipulador UnaryUnary.
Agora, dê uma olhada nos stubs Courier:
func _Test_UnaryUnary_dbxHandler( srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) ( interface{}, error) { defer processor.PanicHandler() impl := srv.(*dbxTestServerImpl) metadata := impl.testUnaryUnaryMetadata ctx = metadata.SetupContext(ctx) clientId = client_info.ClientId(ctx) stats := metadata.StatsMap.GetOrCreatePerClientStats(clientId) stats.TotalCount.Inc() req := &processor.UnaryUnaryRequest{ Srv: srv, Ctx: ctx, Dec: dec, Interceptor: interceptor, RpcStats: stats, Metadata: metadata, FullMethodPath: "/test.Test/UnaryUnary", Req: &test.TestRequest{}, Handler: impl._UnaryUnary_internalHandler, ClientId: clientId, EnqueueTime: time.Now(), } metadata.WorkPool.Process(req).Wait() return req.Resp, req.Err }
Há um pouco de código aqui, então vamos analisá-lo.
Primeiro, adiamos a chamada para o manipulador de pânico, responsável por coletar erros automaticamente. Isso nos permitirá coletar todas as exceções não capturadas no repositório central para posterior agregação e geração de relatórios:
defer processor.PanicHandler()
Outra razão pela qual executamos nosso próprio manipulador de pânico é garantir que o aplicativo falhe se ocorrer um erro. O manipulador HTTP golang / net padrão, nesse caso, ignorará o problema e continuará a atender novas solicitações (mesmo danificadas e inconsistentes).
Em seguida, transmitimos o contexto, redefinindo os valores com base nos metadados da solicitação recebida:
ctx = metadata.SetupContext(ctx) clientId = client_info.ClientId(ctx)
Também criamos (e armazenamos em cache para aumentar a eficiência) as estatísticas do cliente do lado do servidor para agregação mais detalhada:
stats := metadata.StatsMap.GetOrCreatePerClientStats(clientId)
Essa linha cria estatísticas para cada cliente (ou seja, um identificador TLS) durante a execução. Também temos estatísticas sobre todos os métodos para cada serviço. Como o gerador de stub tem acesso a todos os métodos durante a geração do código, podemos criá-los estaticamente de antemão, evitando a lentidão do programa.
Depois disso, criamos uma estrutura de solicitação, transferimos para o conjunto de tarefas e aguardamos a execução:
req := &processor.UnaryUnaryRequest{ Srv: srv, Ctx: ctx, Dec: dec, Interceptor: interceptor, RpcStats: stats, Metadata: metadata, ... } metadata.WorkPool.Process(req).Wait()
Observe que, neste ponto, não decodificamos o protobuf nem lançamos o interceptador. Antes disso, o pool de acesso, a priorização e a limitação do número de solicitações executadas devem passar pelo pool de tarefas.
Observe que a biblioteca gRPC suporta a interface TAP, que permite interceptar solicitações a uma velocidade tremenda. A interface fornece a infraestrutura para a construção de limitadores de velocidade efetivos com consumo mínimo de recursos.Códigos de erro específicos para diferentes aplicações
Nosso gerador de stub também permite que os desenvolvedores atribuam códigos de erro específicos de aplicativos usando opções especiais:
enum ErrorCode { option (rpc_core.rpc_error) = true; UNKNOWN = 0; NOT_FOUND = 1 [(rpc_core.grpc_code)="NOT_FOUND"]; ALREADY_EXISTS = 2 [(rpc_core.grpc_code)="ALREADY_EXISTS"]; ... STALE_READ = 7 [(rpc_core.grpc_code)="UNAVAILABLE"]; SHUTTING_DOWN = 8 [(rpc_core.grpc_code)="CANCELLED"]; }
Os erros de gRPC e de aplicativo se propagam dentro do serviço e, na borda da API, todos os erros são substituídos por DESCONHECIDO. Graças a isso, podemos evitar a transferência do problema para outros serviços, o que pode resultar em uma alteração na semântica.
Alterações no Python
Os stubs do Python adicionam um parâmetro de contexto explícito a todos os manipuladores do Courier:
from dropbox.context import Context from dropbox.proto.test.service_pb2 import ( TestRequest, TestResponse, ) from typing_extensions import Protocol class TestCourierClient(Protocol): def UnaryUnary( self, ctx, # type: Context request, # type: TestRequest ):
No começo, parecia estranho, mas com o tempo, os desenvolvedores se acostumaram ao
ctx explícito, como costumavam fazer.
Observe que nossos stubs são totalmente digitados para
mypy , que é compensado durante a refatoração importante. Além disso, a integração com alguns IDEs (por exemplo, PyCharm) é simplificada.
Continuando a seguir a tendência para a digitação estática, adicionamos anotações mypy aos próprios protocolos:
class TestMessage(Message): field: int def __init__(self, field : Optional[int] = ..., ) -> None: ... @staticmethod def FromString(s: bytes) -> TestMessage: ...
Essas anotações evitarão muitos erros comuns, como atribuir um valor
Nenhum a um campo do tipo
string , por exemplo
.Este código
está disponível aqui .
Processo de migração
Criar uma nova pilha RPC não é uma tarefa fácil, mas não fica nem ao lado do processo de uma transição completa para ela, se você observar do ponto de vista da complexidade operacional. Portanto, tentamos facilitar ao máximo a mudança dos desenvolvedores do RPC antigo para o Courier. Como a migração geralmente é acompanhada de erros, decidimos implementá-la em etapas.
Etapa 0: congelar o RPC antigo
Antes de tudo, congelamos o antigo RPC para não atirar em um alvo em movimento. Isso também levou as pessoas a mudarem para o Courier, porque todos os novos recursos, como rastreamento, estavam disponíveis apenas nos serviços do Courier.
Etapa 1: interface comum para RPC e Courier antigos
Começamos definindo uma interface comum para o antigo RPC e Courier. Nossa geração de código deveria garantir que ambas as versões dos stubs correspondessem a esta interface:
type TestServer interface { UnaryUnary( ctx context.Context, req *test.TestRequest) ( *test.TestResponse, error) ... }
Etapa 2: migrar para a nova interface
Depois disso, começamos a mudar cada serviço para uma nova interface, enquanto continuamos usando o RPC antigo. Freqüentemente, as alterações de código eram uma grande diferença, afetando todos os métodos do serviço e seus clientes. Como esse estágio é o mais problemático, queríamos eliminar completamente o risco alterando apenas uma coisa de cada vez.
Serviços simples com um pequeno número de métodos e o direito de cometer erros podem ser migrados simultaneamente, sem prestar atenção aos nossos avisos.Etapa 3: migrar clientes para o RPC Courier
Durante o processo de migração, começamos a lançar simultaneamente servidores antigos e novos em portas diferentes da mesma máquina. A mudança da implementação de RPC do lado do cliente foi feita alterando uma linha:
class MyClient(object): def __init__(self): - self.client = LegacyRPCClient('myservice') + self.client = CourierRPCClient('myservice')
Observe que, com este modelo, você pode transferir um cliente por vez, começando com aqueles com um nível mais baixo de SLA.
Etapa 4: limpeza
, , RPC ( ). — .
Conclusões
, Courier — RPC-, , Dropbox.
, Courier:
- — . .
- — , .
- , . Codegen.
- . , , . , : .
- RPC- — , . . .
Courier, gRPC , , , .
gRPC Python , C++ Python Rust . ALTS TLS- (, ).