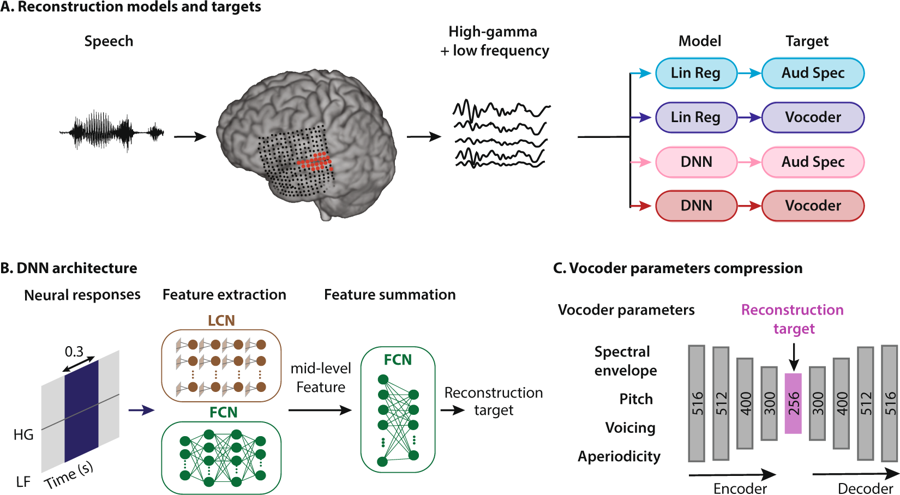
 Esquema do método de reconstrução da fala. Uma pessoa ouve palavras, como resultado, os neurônios de seu córtex auditivo são ativados. Os dados são interpretados de quatro maneiras: combinando dois tipos de modelos de regressão e dois tipos de representações de fala, eles entram no sistema de rede neural para extrair recursos que são subsequentemente usados para configurar os parâmetros do codificador de voz.
Esquema do método de reconstrução da fala. Uma pessoa ouve palavras, como resultado, os neurônios de seu córtex auditivo são ativados. Os dados são interpretados de quatro maneiras: combinando dois tipos de modelos de regressão e dois tipos de representações de fala, eles entram no sistema de rede neural para extrair recursos que são subsequentemente usados para configurar os parâmetros do codificador de voz.Os neuroengenheiros da Columbia University (EUA) foram os primeiros do mundo a
criar um sistema que traduz pensamentos humanos em discursos compreensíveis e distinguíveis. Aqui está a
gravação sonora de palavras (mp3) sintetizadas pela atividade cerebral.
Ao observar a atividade no córtex auditivo, o sistema restaura as palavras que uma pessoa ouve com clareza sem precedentes. Obviamente, essa não é a pontuação de pensamentos no sentido literal da palavra, mas um passo importante foi dado nessa direção. De fato, padrões semelhantes de atividade cerebral ocorrem no córtex cerebral quando uma pessoa imagina que está ouvindo a fala ou quando fala mentalmente palavras.
Esse avanço científico usando tecnologias de inteligência artificial nos aproxima da criação de interfaces neurais eficazes que conectam o computador diretamente ao cérebro. Também ajudará as pessoas que não podem falar e as que se recuperam de um derrame ou por algum outro motivo que são temporariamente ou constantemente incapazes de falar palavras para se comunicar.
Décadas de pesquisa provaram que, no processo de falar ou mesmo de palavras mentais, os padrões de controle da atividade aparecem no cérebro. Além disso, um padrão de sinal distinto (e reconhecível) surge quando ouvimos alguém ou imaginamos que estamos ouvindo. Os especialistas há muito tempo tentam registrar e decifrar esses padrões para "libertar" os pensamentos de uma pessoa do crânio - e traduzi-los automaticamente para a forma oral.
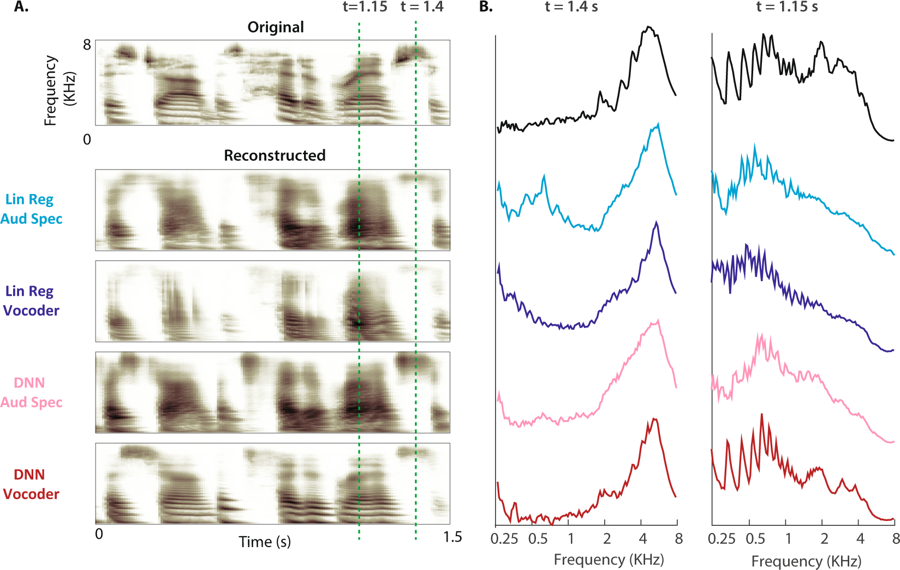 (A) O espectrograma original de uma amostra de fala é mostrado acima. Os espectrogramas auditivos reconstruídos dos quatro modelos são mostrados abaixo. (B) A potência de magnitude das bandas de frequência durante as vozes não sonorizadas (t = 1,4 s) e sonora (t = 1,15 s: o intervalo é mostrado por linhas tracejadas para o espectrograma original e quatro reconstruções)
(A) O espectrograma original de uma amostra de fala é mostrado acima. Os espectrogramas auditivos reconstruídos dos quatro modelos são mostrados abaixo. (B) A potência de magnitude das bandas de frequência durante as vozes não sonorizadas (t = 1,4 s) e sonora (t = 1,15 s: o intervalo é mostrado por linhas tracejadas para o espectrograma original e quatro reconstruções)"Essa é a mesma tecnologia que o Amazon Echo e o Apple Siri usam para responder verbalmente às nossas perguntas",
explica o Dr. Nima Mesgarani, principal autor do artigo. Para ensinar o vocoder a interpretar a atividade cerebral, os especialistas encontraram cinco pacientes com epilepsia que já haviam sido submetidos a cirurgia cerebral. Eles foram convidados a ouvir sentenças feitas por pessoas diferentes, enquanto os eletrodos mediam a atividade cerebral, que era processada por quatro modelos. Esses padrões neurais ensinavam vocoder. Os pesquisadores então pediram aos mesmos pacientes para ouvir como os falantes pronunciam números de 0 a 9, registrando sinais cerebrais que poderiam ser transmitidos pelo codificador de voz. O som produzido pelo codificador de voz em resposta a esses sinais é analisado e apagado por várias redes neurais.
Como resultado do processamento na saída da rede neural, foi recebida uma voz de robô que pronunciava uma sequência de números. Para testar a precisão do reconhecimento, as pessoas foram dadas a ouvir sons sintetizados por sua própria atividade cerebral: "Descobrimos que as pessoas podem entender e repetir sons em 75% dos casos, o que é muito maior e excede qualquer tentativa anterior", disse o Dr. Mesgarani.
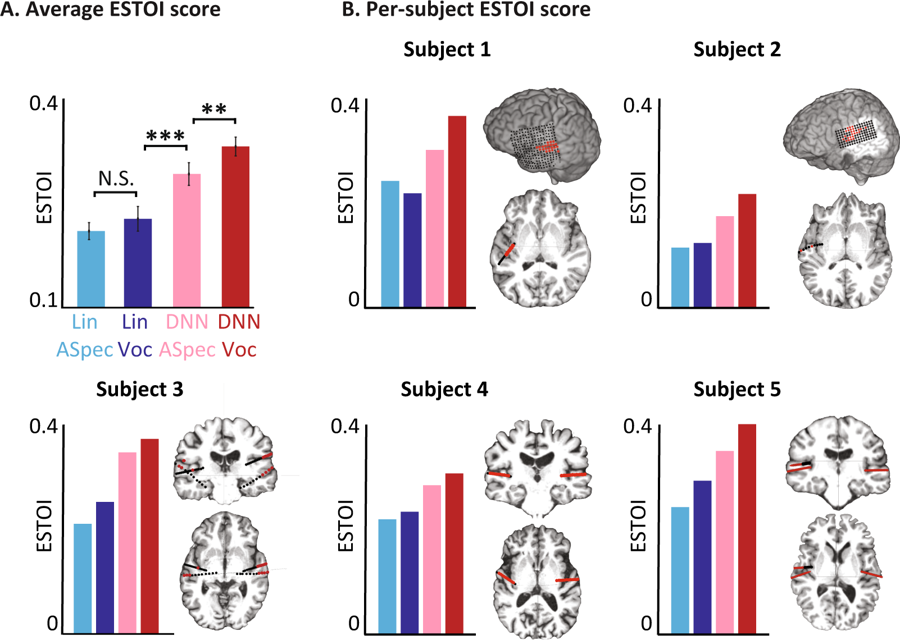 Avaliações objetivas para diferentes modelos. (A) Escore médio do ESTOI para todos os sujeitos dos quatro modelos. B) A cobertura e localização dos eletrodos e a pontuação ESTOI para cada uma das cinco pessoas. Todo mundo tem uma pontuação ESTOI mais alta para o DNN vocoder do que outros modelos.
Avaliações objetivas para diferentes modelos. (A) Escore médio do ESTOI para todos os sujeitos dos quatro modelos. B) A cobertura e localização dos eletrodos e a pontuação ESTOI para cada uma das cinco pessoas. Todo mundo tem uma pontuação ESTOI mais alta para o DNN vocoder do que outros modelos.Agora, os cientistas planejam repetir o experimento com palavras e frases mais complexas. Além disso, os mesmos testes serão executados quanto a sinais cerebrais quando uma pessoa imaginar o que está dizendo. Por fim, eles esperam que o sistema se torne parte do implante, o que traduz os pensamentos do usuário diretamente em palavras.
O artigo científico foi
publicado em 29 de janeiro de 2019 em domínio público na revista
Scientific Reports (doi: 10.1038 / s41598-018-37359-z).
O código do programa para realizar uma análise fonêmica, calcular amplitudes de alta frequência e reconstruir um espectrograma auditivo
está disponível para acesso público .